
最近在大型语言模型(LLMs)方面的进展开启了激动人心的复杂自然语言应用的可能性。这些模型,如ChatGPT、LLAMA和Mistral,正在改变我们与AI互动的方式,从生成类似人类的文本到驱动个性化的聊天对话。然而,一个主要的限制仍然存在:这些模型受限于它们训练时的知识,无法自行更新为新信息。这一限制使得它们难以及时回答新出现的问题或特定领域的查询。
这里就是检索增强生成(RAG)大显身手的地方。RAG使我们能够将实时上下文信息输入到大型语言模型中,从而让它们能够给出更相关和精确的答案。网站内容就是一种非常有用的上下文信息来源。
在这份指南中,我们将解释如何从网站提取内容并利用这些内容来改进LLM在RAG应用中的响应。我们将从网页抓取的基础知识到分块策略以及创建向量嵌入以高效检索,涵盖所有方面。让我们开始吧!
网页抓取入门
要把网站内容整合进RAG系统里,第一步叫做网页抓取。虽然一些网站提供了获取数据的API,但许多网站并没有提供。在这种情况下,网页抓取就显得非常有用。
几个流行的 Python 库可以帮助提取网络数据。在这种情形下,我们将使用 Beautiful Soup 来解析 HTML 内容,并发送 HTTP 请求。还可以使用 Selenium 处理动态内容,或使用 Scrapy 进行更大规模的数据抓取。
一个例子:获取维基百科的数据我们从利用BeautifulSoup工具从维基百科上抓取一个页面开始。
import requests
from bs4 import BeautifulSoup
# 发送一个请求到数据科学页
response = requests.get(
url="https://en.wikipedia.org/wiki/Data_science",
)
# 解析HTML
soup = BeautifulSoup(response.content, 'html.parser')
# 获取正文内容
content = soup.find(id="bodyContent")
print(content.text)这段代码向维基百科发送一个请求,从Data Science页面获取内容,并提取正文内容以便进一步处理。
分段:拆分内容
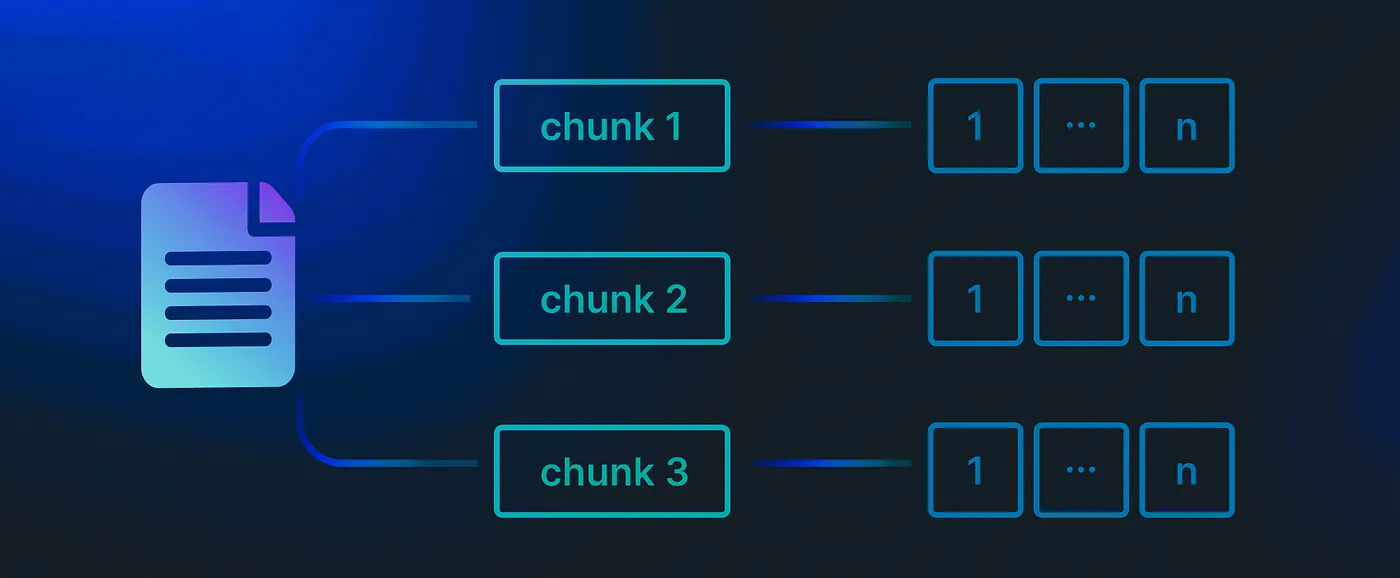
成功抓取了一些内容之后,下一步是将其分块。分块很重要,原因如下:
- 粒度性:将文本分解为更小的部分可以更容易地检索到最相关的信息。
- 改进的语义性:在整个文档中使用单一嵌入可能导致有意义的信息丢失。
- 效率:在嵌入过程中会更高效地计算。
最常见的分块方法是固定大小分块和基于上下文的分块。固定大小分块在预定义的间隔处分割文本,而基于上下文的分块则会根据句子或段落的边界来调整分块的大小。
在本指南中,我们将使用LangChain框架中的**RecursiveCharacterTextSplitter**进行分段,确保拆分在文本的逻辑点上进行。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512, # 将块大小设置为512个字符
length_function=len
)
chunked_text = text_splitter.split_text(content.text)这段代码将抓取到的文本分割成约512字符的块,在自然断点处调整分割位置。
从数据片段到向量(vector)嵌入表示一旦我们有了文本片段,下一步就是将它们转换为向量嵌入表示。这种表示能够捕捉到文本的语义信息,从而实现高效的相似性比较。
常见的嵌入类型主要有两种类型的嵌入表示。
- 密集嵌入:由深度学习模型生成,比如来自OpenAI或Sentence Transformers的模型。它们很好地捕捉语义相似性。
- 稀疏嵌入:由经典方法如TF-IDF或BM25。它们在基于关键词的相似性方面非常有效。
我们将使用Sentence Transformers的all-MiniLM-L6-v2模型生成的密集嵌入向量,应用于我们的RAG应用程序。
from langchain.embeddings import SentenceTransformerEmbeddings
# 加载嵌入模型
embeddings = SentenceTransformerEmbeddings(model_name="all-MiniLM-L6-v2")
# 为第三段文本创建嵌入
chunk_embedding = embeddings.embed_documents([chunked_text[3]])这段代码使用MiniLM-L6-v2模型将其中一个片段转换为密集嵌入。实际上,你需要为所有片段生成嵌入。
使用Milvus存储和检索嵌入一旦我们生成了嵌入向量,就需要将其存储在一个向量型数据库中以实现高效检索。Milvus 是一个开源的向量型数据库,专长于存储和查询嵌入。它与LangChain集成得非常好,是RAG应用的绝佳选择之一。
这里是如何在Milvus中存储你的词块嵌入:
from langchain.vectorstores.milvus import Milvus
# 将向量存储到Milvus中
vector_db = Milvus.from_texts(texts=chunked_text, embedding=embeddings, collection_name="rag_milvus")这段代码在Milvus中创建了一个collection,并存储了所有片段的嵌入,以供将来检索使用。
构建RAG流程在分块存储和嵌入向量准备就绪之后,现在是时候构建我们的RAG流程了。该流程将根据用户查询检索最相关的嵌入向量,并将这些嵌入向量传递给大型语言模型(LLM)以生成响应。
第一步:配置检索器我们首先需要设置一个检索器来,根据用户的查询从向量数据库中检索到最相关的嵌入。
retriever = vector_db.as_retriever() # 初始化检索器 (Initialize the retriever)然后,我们使用OpenAI的GPT-3.5-turbo启动我们的语言模型,
from langchain_openai import ChatOpenAI # 这行代码是从langchain_openai模块导入ChatOpenAI类。
llm = ChatOpenAI(model="gpt-3.5-turbo-0125") # 接下来的代码实例化了一个ChatOpenAI对象,指定了模型为'gpt-3.5-turbo-0125'。我们需要创建一个提示模板,来指导大型语言模型根据检索到的内容生成恰当的答案。
from langchain_core.prompts import PromptTemplate
template = """请根据以下信息回答最后的问题。
如果你不知道答案,请直接说“不知道”,不要编造答案。
请在三个句子以内回答,并尽量简洁明了。
请在回答最后说“谢谢提问!”。
{context}
问题:{question}
回答如下:"""
custom_rag_prompt = PromptTemplate.from_template(template)第四步:建立 RAG 链
最后,我们将创建RAG链路,以检索最相关的片段,将其传递给LLM进行处理,并输出生成的回复。
从langchain_core.runnables导入RunnablePassthrough
从langchain_core.output_parsers导入StrOutputParser
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| custom_rag_prompt
| llm
| StrOutputParser()
)设置好RAG链后,你现在可以向管道发送查询,根据网站内容得到回复。通过管道处理后,你将根据网站内容获得结果。注:RAG链是指检索和生成链。
for chunk in rag_chain.stream("什么是数据科学专家?"):
print(chunk, end="", flush=True)当然可以,这是重新写的文本:
在这篇指南里,我们介绍了从网站提取内容并利用这些内容来改进LLM响应的过程,特别是在RAG应用中提到的。我们讨论了网页抓取、文本切片、生成向量嵌入,并将它们存储在如Milvus这样的向量数据库(即向量搜索数据库)中。
通过使用这项技术,你可以开发出更知情晓意且更了解上下文的AI应用程序。不论是开发聊天机器人还是问答系统(RAG,即检索和生成),RAG都能提高生成回复的相关性和准确性。
记住,你的RAG管道的成功与否取决于你的数据质量和你如何组织分块、嵌入及检索过程。尝试不同的模型、分块大小和检索方法来完善你的系统。
祝你编程开心,谢谢阅读!
参考[1] Kotaemon:在本地机器上运行的开源GraphRAG用户界面
[2] 使用 FAISS 和 Langchain 构建知识库,结合 RAG(检索增广生成)和 Llama 3(具体版本号或者直接保留英文依据上下文)
3 建立简单的RAG管道:LlamaIndex与Chroma。
4 提高生成模型性能的RAG一些先进技术
[5] 使用 Haystack 2.x 构建强大的 RAG 应用
[OOP]: 面向对象编程 (OOP)
[CRUD]: 创建、读取、更新、删除 (CRUD)
[JVM]: Java 虚拟机 (JVM)
[SUT]: 被测系统 (SUT)





