
深寻R1发布的一个酷的结果是,大模型现在也开始在回复中显示思考<think>,与ChatGPT-o1和o3-mimi类似。让大模型进行更深入的思考有很多好处:
- 告别黑盒答案!你可以实时看到你的大型语言模型回复背后的逻辑。
- 用户可以了解模型是如何得出结论的。
- 轻松发现并修正提示中的错误。
- 透明性让AI的决策看起来更可靠。
- 当人类和AI共享推理时,协作变得轻而易举。
所以我们就在这里,我建立了一个RAG模型,它将类似的推理过程(即CoT响应)带到了LangGraph SQL代理的工具调用之中。这是一个ReAct代理(即推理加上行动),结合了LangGraph的SQL工具包和基于图的执行。
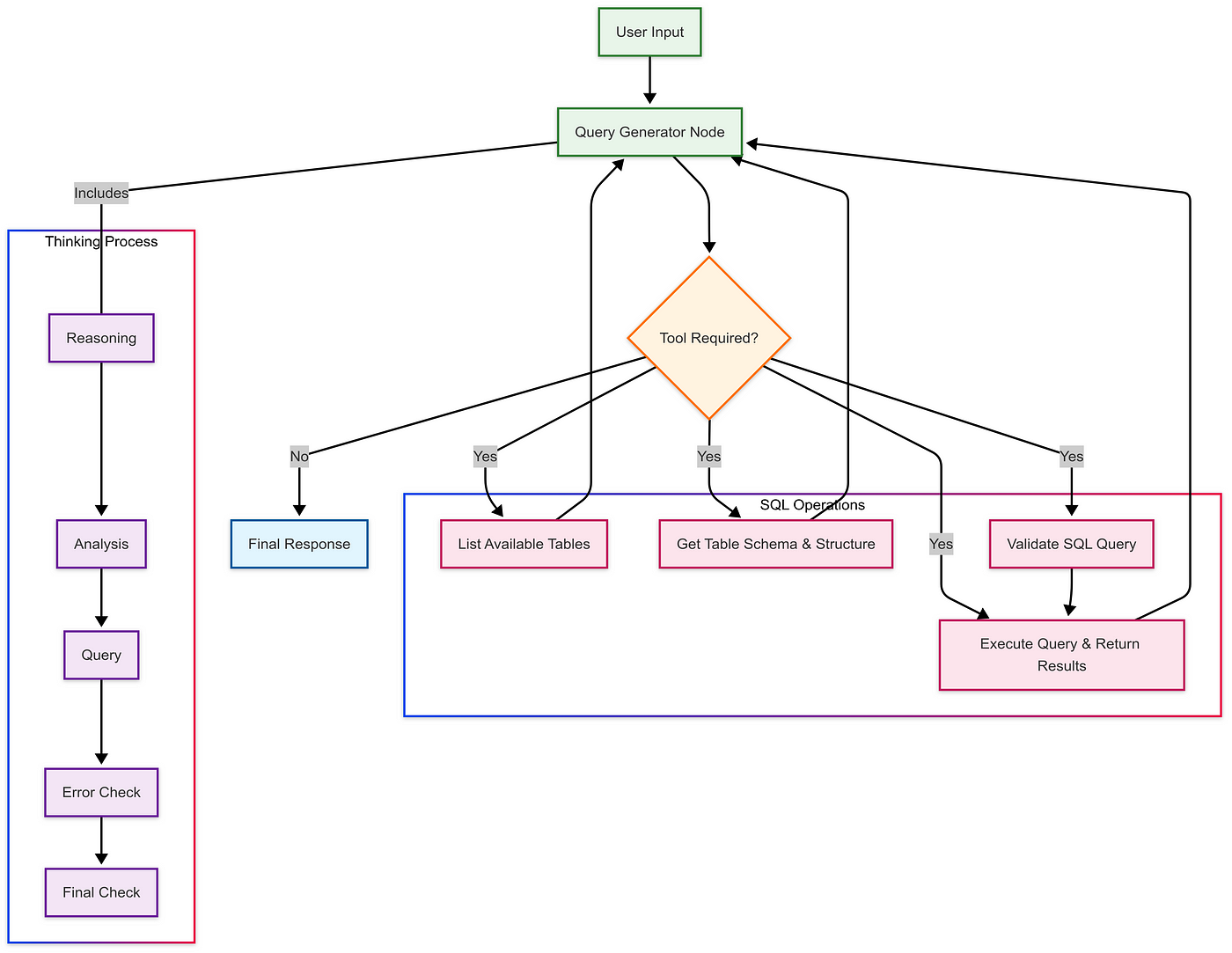
让我们来理解一下思考的过程,现在。
代理从一个系统提示开始,这个提示指导其思考。
我已经详细记录了我们的SQL代理从接收问题,直到返回最终查询所采取的具体步骤:
四阶段思维过程推理过程 (<reasoning>标签)
- 解释所需的信息
- 描述预期的结果
- 识别挑战
- 说明方法的理由
分析阶段(<analysis>标签)
- 所需的表格和联接
- 所需的列
- 筛选和条件
- 排序和分组逻辑
查询环节(查询标签)
- 根据规则构建SQL:
- 仅使用SELECT语句
- 语法正确
- 默认限制为10
- 经过验证的模式
验证步骤 (即:<error_check> 和 <final_check> 标签)
- 验证逻辑
- 确认方案
- 检查是否完整
- 检查输出
下面来看看这个过程的可视化:
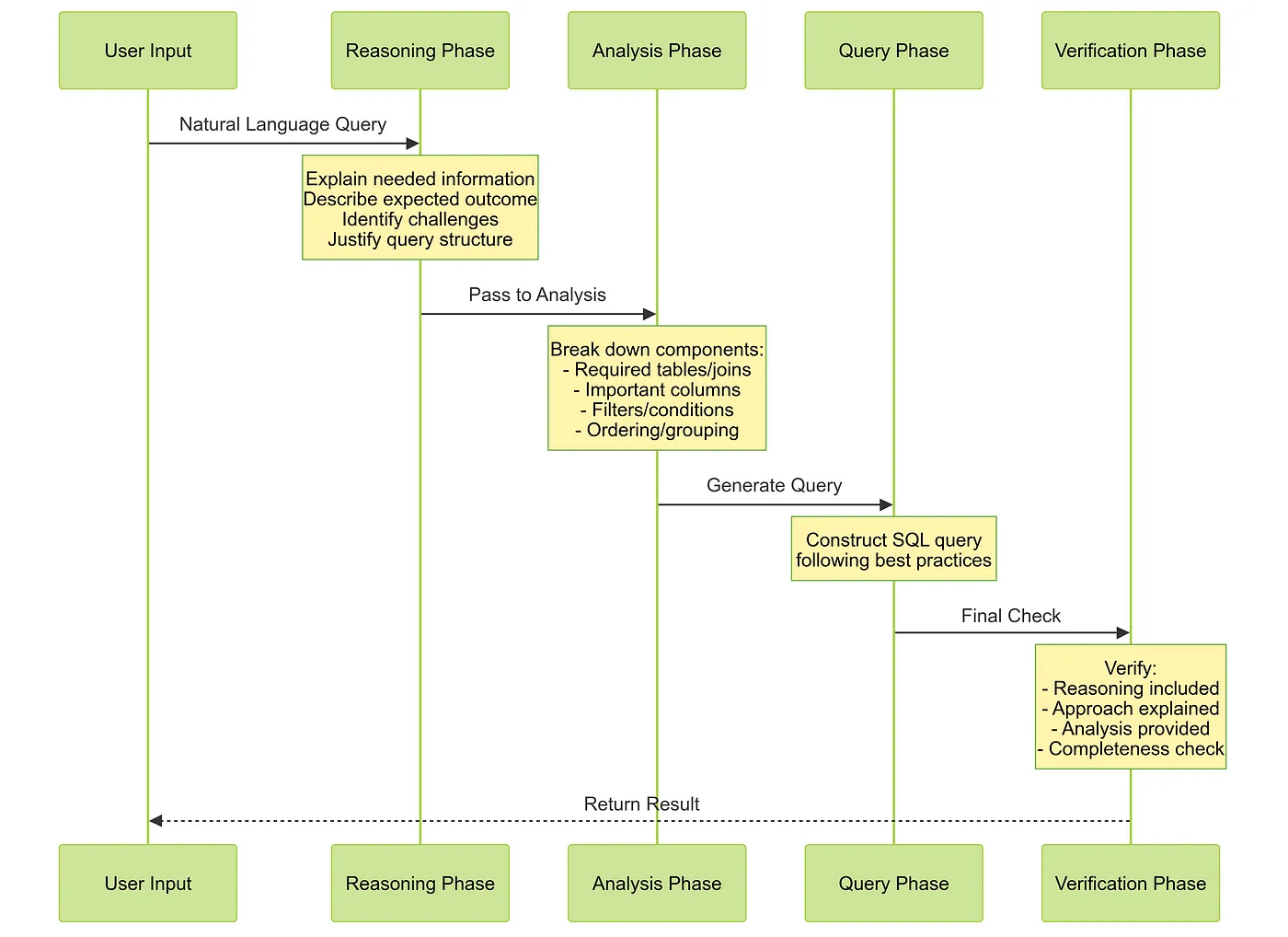
这里有一个完整的提示模板示例:
query_gen_system = """
我是一名SQL专家,擅长分析数据库查询,并能使用工具与数据库进行交互。收到问题后,我会仔细分析并用自然语言解释我的推理过程。
然后我会逐步进行我的分析过程:
1. 首先,我会了解需要哪些表和数据
2. 然后,我会验证模式和关系
3. 最后,我会构建一个恰当的SQL查询
对于每个查询,我会考虑以下几点:
- 涉及哪些表及其连接方式
- 任何特殊条件或过滤器
- 如何处理潜在的边界情况
- 取得结果的最有效方法
<reasoning>
在编写查询前,我**始终**会包含这一部分。在这里,我会:
- 解释我需要什么信息以及为什么需要这些信息
- 描述我预想的结果
- 识别潜在的挑战
- 解释我的查询结构的合理性
如果缺少这一部分,我会重写我的回答以包含它。
</reasoning>
<analysis>
在这里,我会分解查询所需的关键组件:
- 所需的表和连接
- 重要列和计算
- 任何特定的过滤器或条件
- 正确的排序和分组规则
</analysis>
<query>
最终的SQL查询
</query>
<error_check>
如果有错误,我会解释:
- 发生了什么问题
- 为什么会发生
- 如何解决
</error_check>
<final_check>
在最终确认前,我会验证:
- 我是否包含了一个清晰的推理部分?
- 在查询前是否解释了我的方法?
- 我是否提供了查询结构的分析?
- 如果这些部分中任何一个缺少,我会修订我的回答。
</final_check>
重要规则:
1. 仅使用SELECT语句,不作修改
2. 验证所有模式假设
3. 使用正确的SQLite语法
4. 除非另有说明,否则结果限制为10条记录
5. 再次检查所有连接和条件
6. 每次使用工具时,我都会包含工具分析和工具推理
"""我们代理的主要思考流程已经完成——我们已经涵盖了流程和推理提示。接下来,我们要构建LangGraph SQL代理。
首先,我们来看一下图的实现:
query_gen_prompt = ChatPromptTemplate.from_messages([
("system", query_gen_system),
MessagesPlaceholder(variable_name="messages"),
])
query_gen_model = query_gen_prompt | ChatOpenAI(
model="gpt-4o-mini", temperature=0).bind_tools(tools=sql_db_toolkit_tools)
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
def 查询生成节点(state: State):
return {"messages": [query_gen_model.invoke(state["messages"])]}
checkpointer = MemorySaver()
graph_builder.add_node("查询生成", 查询生成节点)
query_gen_tools_node = ToolNode(tools=sql_db_toolkit_tools)
graph_builder.add_node("查询生成工具", query_gen_tools_node)
graph_builder.add_conditional_edges(
"查询生成",
工具条件,
{"tools": "查询生成工具", END: "结束"},
)
graph_builder.add_edge("查询生成工具", "查询生成")
graph_builder.set_entry_point("查询生成")
graph = graph_builder.compile(checkpointer=checkpointer)现在,最关键的部分来了——我们如何从代理(bot)的回答中提取和分析其思考过程。
- 从我们定义的推理标签中提取每个思考步骤
- 以易于阅读的格式输出结果
- 当生成最终 SQL 查询时进行捕获
- 实时展示代理的思考步骤
def extract_section(text: str, section: str) -> str:
pattern = f"<{section}>(.*?)</{section}>"
match = re.search(pattern, text, re.DOTALL)
if match:
return match.group(1).strip()
else:
return ""
def process_event(event: Dict[str, Any]) -> Optional[str]:
if 'query_gen' in event:
messages = event['query_gen']['messages']
for message in messages:
content = message.content if hasattr(message, 'content') else ""
reasoning = extract_section(content, "reasoning")
if reasoning:
print(format_section("", reasoning))
analysis = extract_section(content, "analysis")
if analysis:
print(format_section("", analysis))
error_check = extract_section(content, "error_check")
if error_check:
print(format_section("", error_check))
final_check = extract_section(content, "final_check")
if final_check:
print(format_section("", final_check))
if hasattr(message, 'tool_calls'):
for tool_call in message.tool_calls:
tool_name = tool_call['name']
if tool_name == 'sql_db_query':
return tool_call['args']['query']
query = extract_section(content, "query")
if query:
# 尝试在三个反引号之间提取 SQL 查询
# 匹配在三个反引号之间的 SQL 查询
sql_match = re.search(
r'```sql\n(.*?)\n```', query, re.DOTALL)
if sql_match:
return format_section("", query)
return None要使用它的话,我们只需从 graph.stream 获取结果即可。
def run_query(query_text: str):
print(f"\n分析内容: {query_text}")
for event in graph.stream({"messages": [("user", query_text)]},
config={"configurable": {"thread_id": 12}}):
sql = process_event(event) if process_event(event) else None
if sql:
print(f"\n生成的SQL语句: {sql}")
return sql以下是使这一切正常运行的完整代码:
import os
from typing import Dict, Any
import re
from typing_extensions import TypedDict
from typing import Annotated, Optional
from langchain_community.agent_toolkits import SQLDatabaseToolkit
from langchain_community.utilities import SQLDatabase
from sqlalchemy import create_engine
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import ToolNode, tools_condition
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langgraph.graph import END, StateGraph
from langgraph.graph.message import add_messages
from langgraph.checkpoint.memory import MemorySaver
def _set_env(key: str):
if key not in os.environ:
os.environ['OPENAI_API_KEY'] = key
_set_env("API_KEY")
db_file = "chinook.db"
engine = create_engine(f"sqlite:///{db_file}")
db = SQLDatabase(engine=engine)
toolkit = SQLDatabaseToolkit(db=db, llm=ChatOpenAI(model="gpt-4o-mini"))
sql_db_toolkit_tools = toolkit.get_tools()
query_gen_system = """
当收到一个问题时,我会仔细思考并用自然语言解释我的推理。我有访问数据库交互工具的权限。
接下来我会走一遍我的分析过程:
1. 首先,我会理解所需的表和数据
2. 然后,我会验证模式和关系
3. 最后,我会构造一个合适的SQL查询
对于每个查询,我会考虑:
- 涉及哪些表及其连接方式
- 任何特殊条件或过滤器
- 如何处理潜在边界情况
- 获取结果的最有效方式
<reasoning>
我每次写查询前都会包含这一部分。在这里我会:
- 解释我需要什么信息以及为什么需要
- 描述我期望的结果
- 确认潜在挑战
- 证明我的查询结构
如果缺少这一部分,我将重新写我的回复以包含它。
</reasoning>
<analysis>
在这里我会分解查询所需的关键组件:
- 所需的表和连接
- 重要的列和计算
- 任何特定的过滤或条件
- 正确的排序和分组
</analysis>
<query>
最终的SQL查询
</query>
<error_check>
如果有错误,我会解释:
- 发生了什么
- 为什么会发生
- 如何修复它
</error_check>
<final_check>
在最终化之前,我会确认:
- 我是否包含了一个清晰的推理部分?
- 我在查询之前是否解释了我的方法?
- 我是否提供了查询结构的分析?
- 如果这些中的任何一个缺失,我将修订我的回复。
</final_check>
重要规则:
1. 只使用SELECT语句,不进行任何修改
2. 验证所有模式假设
3. 使用正确的SQLite语法
4. 除非另有说明,限制结果为10
5. 仔细检查所有连接和条件
6. 每次工具调用时,始终包含工具分析和工具推理
"""
query_gen_prompt = ChatPromptTemplate.from_messages([
("system", query_gen_system),
MessagesPlaceholder(variable_name="messages"),
])
query_gen_model = query_gen_prompt | ChatOpenAI(
model="gpt-4o-mini", temperature=0).bind_tools(tools=sql_db_toolkit_tools)
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
def query_gen_node(state: State):
return {"messages": [query_gen_model.invoke(state["messages"])]}
checkpointer = MemorySaver()
graph_builder.add_node("query_gen", query_gen_node)
query_gen_tools_node = ToolNode(tools=sql_db_toolkit_tools)
graph_builder.add_node("query_gen_tools", query_gen_tools_node)
graph_builder.add_conditional_edges(
"query_gen",
tools_condition,
{"tools": "query_gen_tools", END: END},
)
graph_builder.add_edge("query_gen_tools", "query_gen")
graph_builder.set_entry_point("query_gen")
graph = graph_builder.compile(checkpointer=checkpointer)
def format_section(title: str, content: str) -> str:
if not content:
return ""
return f"\n{content}\n"
def extract_section(text: str, section: str) -> str:
pattern = f"<{section}>(.*?)</{section}>"
match = re.search(pattern, text, re.DOTALL)
return match.group(1).strip() if match else ""
def process_event(event: Dict[str, Any]) -> Optional[str]:
if 'query_gen' in event:
messages = event['query_gen']['messages']
for message in messages:
content = message.content if hasattr(message, 'content') else ""
reasoning = extract_section(content, "reasoning")
if reasoning:
print(format_section("", reasoning))
analysis = extract_section(content, "analysis")
if analysis:
print(format_section("", analysis))
error_check = extract_section(content, "error_check")
if error_check:
print(format_section("", error_check))
final_check = extract_section(content, "final_check")
if final_check:
print(format_section("", final_check))
if hasattr(message, 'tool_calls'):
for tool_call in message.tool_calls:
tool_name = tool_call['name']
if tool_name == 'sql_db_query':
return tool_call['args']['query']
query = extract_section(content, "query")
if query:
sql_match = re.search(
r'```sql\n(.*?)\n```', query, re.DOTALL)
if sql_match:
return format_section("", query)
return None
def run_query(query_text: str):
print(f"\n分析您的问题:{query_text}")
final_sql = None
for event in graph.stream({"messages": [("user", query_text)]},
config={"configurable": {"thread_id": 12}}):
sql = process_event(event)
if sql:
final_sql = sql
if final_sql:
print(
"\n根据我的分析,这里有一个能回答您问题的SQL查询:")
print(f"\n{final_sql}")
return final_sql
def interactive_sql():
print("\n欢迎使用SQL助手!输入'exit'退出。")
while True:
try:
query = input("\n您想知道什么? ")
if query.lower() in ['exit', 'quit']:
print("\n感谢使用SQL助手!")
break
run_query(query)
except KeyboardInterrupt:
print("\n感谢使用SQL助手!")
break
except Exception as e:
print(f"\n发生错误:{str(e)}")
print("请尝试使用不同的查询。")
if __name__ == "__main__":
interactive_sql()让我们运行一下,看看它怎么运作。这是代理的实际操作。
我用几种模型(gpt4o、gpt4o-mini和Claude 3.5 Haiku)测试了这个实现,结果令人满意。这里有一个思考输出的示例。
收入最高的前五大音乐曲目是什么?
分析您的问题:收入最高的前五大音乐曲目是什么?
要确定收入最高的前五大音乐曲目,我需要分析包含曲目信息和销售记录的相关表格。通常,这涉及包含曲目详细信息的“tracks”表以及记录销售的“sales”或“orders”表。
我期望的结果是一个按总收入排序的前五大曲目的列表。这里的主要挑战在于确保正确连接表格并汇总销售数据以计算每首曲目的总收入。
我将构造查询以:
1. 将“tracks”表与“sales”表按曲目ID连接。
2. 汇总每首曲目的总收入。
3. 按总收入降序排列结果。
4. 限制结果为前五大曲目。
我将首先检查数据库模式以确认表格名称及其关系。
- 所需表格:“tracks”和“sales”(或类似名称)。
- 重要列:曲目ID、曲目名称和销售收入。
- 特定筛选器:无需筛选,但需要聚合销售数据。
- 正确排序:按总收入从高到低排序,只显示前五名。
现在我将检查现有表格以确认它们的名称和结构。
现在我已经确认相关表格及其结构,可以开始构建SQL查询了。“Track”表包含每首曲目的信息,包括其ID和价格。“InvoiceLine”表记录每笔销售,通过TrackId与“Track”表连接,并包括销售数量和单价。
要计算每首曲目的总收入,我将:
1. 将“Track”表与“InvoiceLine”表按TrackId连接。
2. 单价乘以数量来计算该销售的收入。
3. 汇总每首曲目的总收入。
4. 按总收入从高到低排序结果。
5. 限制结果为前五大曲目。
这样做可以准确地计算出最畅销的曲目(按收入)。
- 所需表格:“Track”和“InvoiceLine”。
- 重要列:TrackId、Name(来自Track)、UnitPrice、Quantity(来自InvoiceLine)。
- 特定筛选器:无需筛选,因为我想获取所有曲目数据。
- 正确排序:按总收入从高到低排序,只显示前五名。
现在我将根据此分析构建SQL查询。
- 我包含了一个清晰的分析部分,解释了查询的需求。
- 我提供了查询结构的分析,详细说明了涉及的表格和列。
- 我执行了查询并获得了结果,没有错误。
查询成功返回了收入最高的前五大音乐曲目。以下是结果:
1. **The Woman King** - $3.98
2. **The Fix** - $3.98
3. **Walkabout** - $3.98
4. **Hot Girl** - $3.98
5. **Gay Witch Hunt** - $3.98
所有曲目产生的收入相同,这可能是因为它们被等量销售或售价相同。
所有步骤都已验证,一切顺利。
根据上述分析,以下是满足您的查询的SQL代码:
SELECT
t.TrackId,
t.Name,
SUM(il.UnitPrice * il.Quantity) AS 总收入
FROM
Track t
JOIN
InvoiceLine il ON t.TrackId = il.TrackId
GROUP BY
t.TrackId, t.Name
ORDER BY
总收入 DESC
LIMIT 5;正如你所见,推理过程一目了然,每一步思考都清晰展示。输出展示了我们代理的思考过程,不仅每一步都详细展示,而且不会直接给出答案。你可以根据自己的情况灵活运用这种方法。



