
机器学习(ML)项目常常涉及众多依赖项、复杂的模型管理流程,以及频繁更新的组件,如数据集、模型参数和生成的成果。因此,有效部署和管理这些项目既必要又颇具挑战性。随着团队采用微服务架构和模型变得越来越复杂,传统的部署方法往往显得力不从心。
为了解决这些问题,本文展示了如何使用Argo CD,一个Kubernetes持续集成和交付(CI/CD)工具,来简化部署过程,并让机器学习工程师和数据科学家改变他们实施项目的方式。您还将学会如何利用KitOps有效打包并无缝共享您的机器学习项目:一款基于ModelKit的打包工具。
Argo CD 和 KitOps 的结合填补了 ML 领域的一大重要空白。虽然 Argo CD 让部署更顺畅,KitOps 则简化了 ML 项目的打包和共享。这种结合使团队能够保持标准化的部署和项目分发,从而增强 ML 工作流中的协作和可重复性。
Argo CDArgo CD 是一个声明性持续交付工具,用于 Kubernetes 环境,帮助部署和管理应用。与其他工具相比,Argo CD 通过自动同步和回滚功能支持 GitOps 实践。Argo CD 能够在多个 Kubernetes 集群中的多种应用和环境中进行管理,非常适合大规模机器学习项目的需要。Argo CD 的其他功能包括:
- 保持各环境配置的一致性。
- 直接从Git仓库自动化部署。
- 轻松回滚和版本控制。
- 减少人为错误和手动干预。
让我们来安装 Argo CD 并用它来本地部署一个 ML 演示项目。
安装 Argo CD:
1/ 在安装 Argo CD 之前,请确保安装了 Docker,minikube 和 kubectl。这些工具对于安装和使用 Argo CD 是必要的,并且它们的作用如下(依次为):
- Docker: 提供了构建和运行容器化应用的容器运行时环境,对于创建本地 Kubernetes 集群非常关键。
- Minikube: 用于搭建本地 Kubernetes 集群,用于部署和管理 Argo CD。
- kubectl: 用于与 Kubernetes 集群交互,安装、配置并管理 Argo CD。
你可以通过运行以下命令来创建一个新的命名空间:
例如:
请根据你的环境替换具体命令。启动minikube
# 启动minikube
kubectl create namespace argocd
# 创建名为argocd的命名空间
kubectl apply -n argocd -f https://raw.githubusercontent.com/argoproj/argo-cd/stable/manifests/install.yaml
# 应用Argo CD的安装文件点击全屏 点击退出全屏
3/ 用 brew 安装 Argo CD CLI(在 Mac、Linux 和 WSL 中使用 Homebrew):点击这里查看安装说明
使用Homebrew安装ArgoCD
brew install argocd点击进入全屏 点击退出全屏
默认情况下,Argo CD API 服务器不暴露外部 IP 地址。要访问 API 服务器,请执行以下操作:
使用kubectl将svc/argocd-server服务的443端口转发到本地的8080端口
kubectl port-forward svc/argocd-server -n argocd 8080:443进入全屏 退出全屏
可以通过https://localhost:8080访问API服务器。
5/ 通过 CLI 登录 Argo CD。默认用户名是 admin,可以通过运行以下命令来获取默认密码:
运行该命令来获取初始密码
argocd admin initial-password -n argocd进入全屏;退出全屏
然后,使用下面的命令来登录:
your_login_command请将 your_login_command 替换为您的实际登录命令。
在终端输入以下命令登录 ArgoCD:
argocd login 127.0.0.1:8080全屏模式, 退出全屏
6/ 最后,你需要创建一个集群来部署你的应用程序。你可以搭建一个本地集群。在执行以下命令之前,你需要确保Docker已经安装并运行:
kubectl config get-contexts -o name # 获取上下文名称
argocd cluster add docker-desktop # 添加 Docker Desktop 集群点击全屏按钮,然后再次点击退出全屏
现在,你已经准备好创建一个机器学习应用程序。
创建一个葡萄酒质量分级器安装好 Argo CD 并设置好集群后,下一步是训练一个可以部署的机器学习模型。还需要通过 API 提供训练完成的模型。按照以下步骤训练一个葡萄酒质量分类模型并通过其 FastAPI 端点提供服务。
1/ 从Kaggle下载葡萄酒质量数据集,并将文件保存为winequality.csv,并将其放在你工作目录的dataset文件夹中。
2/ 安装 pandas 和 scikit-learn,并通过执行以下命令来固定需求版本以保证可重复性,这些命令是:
安装pandas和scikit-learn库并将已安装的库冻结到requirements.txt文件中。
pip install pandas scikit-learn
pip freeze > requirements.txt进入全屏;退出全屏
3/ 创建一个名为 train.py 的新文件,用于训练模型并保存最终结果。
# 导入必要的库
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import joblib
# 加载数据集
file_path = 'dataset/winequality.csv' # 如果需要更新,请使用正确的文件路径
df = pd.read_csv(file_path)
# 数据预处理:拆分特征和目标
X = df.drop('quality', axis=1)
y = df['quality']
# 将数据划分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练一个随机森林分类器
model = RandomForestClassifier(random_state=42)
model.fit(X_train, y_train)
# 评估模型
y_pred = model.predict(X_test)
print("分类报告:")
print(classification_report(y_test, y_pred))
# 保存模型到文件
model_path = 'saved_model/wine_quality_model.pkl' # 指定保存模型的路径
joblib.dump(model, model_path)
print(f"模型已保存至 {model_path}")
点击进入全屏,按钮退出全屏
下面的代码使用了比如 pandas 和 scikit-learn 这样的库来加载数据并训练一个随机森林模型。训练完成后,代码将模型保存到名为 saved_model 的文件夹。
4/ 使用 python train.py 运行 train.py 脚本。你现在应该能在 saved_model 目录中看到保存的最终模型。
到这个时候,你的目录结构应该像这样等等。
.
├── dataset
│ └── winequality.csv
├── requirements.txt
├── saved_model
│ └── wine_quality_model.pkl
└── train.py # 训练脚本这是项目文件的结构。下面是你需要关注的文件。
全屏;退出
5/ 你还需要创建用于部署的API,所以安装FastAPI。因为你安装了一个新库,所以还需要固定依赖。
pip install "fastapi[standard]" # 安装 FastAPI 的标准依赖包
pip freeze > requirements.txt # 将当前环境的所有包及其版本信息写入 requirements.txt 文件进入全屏 退出全屏
在 main.py 文件中,加载你保存的模型,并为用户提供一个接口。
从 fastapi 导入 FastAPI 作为 app
导入 numpy 作为 np
导入 joblib
从 pydantic 导入 BaseModel
导入 starlette
从 typing 导入 List
app = FastAPI()
@app.get("/")
def read_main():
return {"message": "欢迎."}
class WineData(BaseModel):
fixed_acidity: float
volatile_acidity: float
citric_acid: float
residual_sugar: float
chlorides: float
free_sulfur_dioxide: float
total_sulfur_dioxide: float
density: float
pH: float
sulphates: float
alcohol: float
@app.post("/winequality/")
def analyze_wine_quality(wine_data: WineData):
print("数据为 \n")
print(wine_data)
predict_data = [
wine_data.fixed_acidity,
wine_data.volatile_acidity,
wine_data.citric_acid,
wine_data.residual_sugar,
wine_data.chlorides,
wine_data.free_sulfur_dioxide,
wine_data.total_sulfur_dioxide,
wine_data.density,
wine_data.pH,
wine_data.sulphates,
wine_data.alcohol,
]
predict_data = np.array(predict_data).reshape(1, -1)
prediction = classifier.predict(predict_data)
print("预测结果是")
print(prediction, type(prediction))
return_obj = {"quality": int(prediction)}
return return_obj进入全屏,退出全屏
在上面的代码中,你会看到函数 analyze_wine_quality(wine_data: WineData) 定义了路径为 @app.post("/winequality/")。该函数会加载保存的模型,并使用它来预测葡萄酒质量。
7/ 你现在可以发送一个API请求来检查葡萄酒的质量。应用程序在http://127.0.0.1:8000/winequality/提供了POST方法。可以使用Postman发送请求,如下图所示。
如下是示例API请求和响应: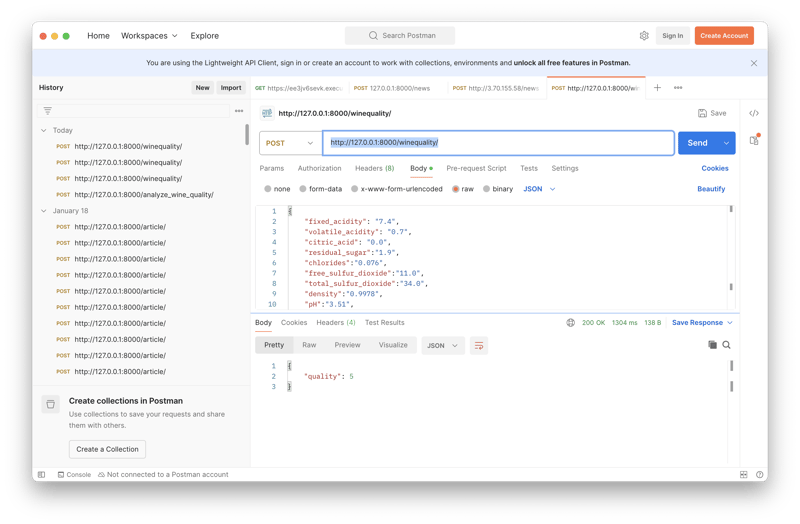
8/ 最后,你需要为你的应用创建一个 Docker 镜像,这样你就可以在 Argo CD 中注册它了。为此,创建一个包含以下内容的 Dockerfile:
# Use the official Python base image
FROM python:3.11-slim
# Set the working directory to /app
WORKDIR /app
# Copy the requirements.txt file into the container
COPY requirements.txt .
# Install Python dependencies
RUN pip install --upgrade pip
RUN pip install -r requirements.txt
# Copy the application code to the container
COPY . .
# Expose the default port 8000
EXPOSE 8000
# Use uvicorn command to run the FastAPI application
CMD ["uvicorn", "main:app", "--host", "0.0.0.0", "--port", "8000"]进入全屏模式,退出全屏
使用以下命令来创建 Docker 镜像:
运行此命令来构建名为 fastapi-app 的 Docker 镜像。
docker build -t fastapi-app .进入/退出全屏模式
你现在应该能看到一个新的镜像fastapi-app出现在你的Docker镜像列表里。

现在你可以回到 Argo CD 平台继续部署了。
将 API 部署到 Argo CD 集群在训练完机器学习模型并设置好API之后,下一步是使用Argo CD通过API来部署训练好的机器学习模型。为此,您需要按照以下步骤来做。
运行以下命令来更改当前命名空间为 argocd:
kubectl config set-context --current --namespace=argocd使用kubectl命令设置当前上下文的命名空间为argocd
全屏 退出全屏
2/ 创建 deployment.yaml 和 svc.yaml 文件。方便起见,你不需要单独创建它们,因为它们已经在 此仓库 的 fastapi 文件夹内为你创建好了。
3/ 使用以下命令来创建示例应用程序:
argocd app create fastapi --repo https://github.com/bhattbhuwan13/argocd-example-apps.git --path fastapi --dest-server https://kubernetes.default.svc --dest-namespace default 全屏,退出全屏。
要确认一下应用已经创建好了,查看一下它的状态。
argocd app get fastapi
名称: argocd/fastapi
项目: default
服务器: https://kubernetes.default.svc
命名空间: default
URL: https://127.0.0.1:8080/applications/fastapi
源:
- 仓库: https://github.com/bhattbhuwan13/argocd-example-apps.git
目标:
路径: fastapi
同步窗口: 同步窗口: 允许
同步策略: 手动
同步状态: 从 36a9d33 不同步
健康状态: 缺失
组: 类型: 命名空间: 名称: 状态: 健康: 钩子: 消息:
服务: default ml-api 不同步 缺失
apps: 部署: default ml-api 不同步 缺失
全屏 全屏退出
4/ 应用状态初始为 OutOfSync,因为应用尚未部署,且尚未创建任何 Kubernetes 资源。要部署应用,可以运行:
运行命令 `argocd app sync fastapi`全屏 全屏退出
5/ 现在你应该已经在UI中看到这个正常运行的FastAPI应用了,网址为https://localhost:8080/applications/argocd/fastapi。
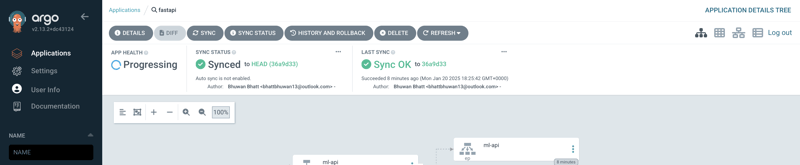
此时,你已经部署了一个训练好的模型在本地的 Kubernetes 集群上。如果你想与团队中的其他工程师分享你的代码和制品,该怎么做呢?那么,一个很棒的工具是 KitOps 工具。
KitOps 是一个开源项目,旨在增强 AI/ML 项目中各方参与者之间的协作。KitOps 的核心是 ModelKit,这是一种符合 OCI 标准的打包格式,能够让所有相关的 AI/ML 模型生命周期中的必要工件顺畅地共享。ModelKit 的主要优势包括:
-
版本控制和安全打包:
把所有项目资源打包成一个捆绑包,并使用版本号和SHA校验和来保证其完整性。 -
无缝集成:
支持OCI兼容的仓库(例如Docker Hub和Jozu Hub等),并能与常用的工具如HuggingFace,ZenML和Git等无缝对接。 - 轻松的依赖管理:
将依赖项和代码一起打包,实现轻松执行。
安装Kit
要安装Kit,你可以从这里安装Kit,按指示下载软件包,解压后将kit可执行文件移动到操作系统可以找到的位置。在Linux中,你可以运行以下命令:
wget https://example.com/path/to/kit.zip # 下载kit包
unzip kit.zip # 解压缩kit包
sudo mv kit /usr/local/bin/ # 将kit可执行文件移至系统路径wget https://github.com/jozu-ai/kitops/releases/latest/download/kitops-linux-x86_64.tar.gz # 下载最新的 kitops 发行版
tar -xzvf kitops-linux-x86_64.tar.gz # 解压下载的发行版
sudo mv kit /usr/local/bin/ # 将 kit 移动到 /usr/local/bin 目录全屏 退出全屏
如果你使用的是 Windows 或 MacOS,请访问我们的官方站点,该网站提供了详细的安装指南。
运行命令 kit version 来检查安装。
版本: 0.2.5-29dbdc4
提交哈希: 29dbdc48bf2b5f9ee801d6454974e0b8474e916b
构建日期: 2024-06-06T17:53:35Z,
Go 版本: go1.21.6,全屏切换,退出全屏
安装了Kit之后,你需要编写一个Kitfile来指定代码中需要打包的不同部分。你可以使用任何文本编辑器创建一个名为Kitfile的新文件(无需文件扩展名),并在文件中输入以下内容:
manifestVersion: "1.0"
package:
name: 葡萄酒分类
version: 0.0.1
authors: ["Bhuwan Bhatt"]
model:
name: 葡萄酒分类-v1
path: ./saved_model
description: 使用sklearn进行的葡萄酒分类
datasets:
- description: 葡萄酒质量数据集数据
name: 训练数据
path: ./dataset
code:
- description: 训练用代码
path: .你可以点击全屏按钮,想要退出时再点击一下。
上面的代码中有5个主要部分:
- manifestVersion: 指定 Kitfile 的版本号。
- package: 指定包的信息。
- model: 指定模型详情,包括模型名称、路径和描述。
- datasets: 指定数据集信息,包括路径、名称和描述。
- code: 指定包含需要打包的代码的文件夹。
一旦安装了Kit命令行工具并且Kitfile准备就绪,你需要登录到容器镜像仓库。在...之后,可以使用以下命令登录DockerHub。
运行 `kit login docker.io` # 然后输入用户名和密码,密码将被隐藏全屏模式 退出全屏
可以使用以下命令将资源打包整理到模型套件ModelKit中:
kit pack . -t docker.io/<USERNAME>/<CONTAINER_NAME>:<CONTAINER_TAG>
# 这行命令用于打包当前目录到指定的Docker镜像.
# 例如,如果你想打包名为`wine_classification`的容器,版本为`v1`,你可以使用命令`kit pack . -t docker.io/bhattbhuwan13/wine_classification:v1`。
# 其中,`<USERNAME>` 代表你的Docker用户名, `<CONTAINER_NAME>` 代表容器名称, `<CONTAINER_TAG>` 代表容器标签.全屏, 退出全屏
最后,你可以把ModelKit上传到远程仓库:
kit push docker.io/`<用户名>`/`<容器名称>`:`<容器标签>`
# 例如:可以这样使用 kit push docker.io/bhattbhuwan13/wine_classification:v1:切换到全屏模式,退出全屏
开发人员现在可以使用单个命令从ModelKit提取所需的组件或整个ModelKit。他们可以解包ModelKit中的特定组件。
kit unpack --datasets docker.io/<用户名>/<容器名>:<标签>
# 例如:kit unpack --datasets docker.io/bhattbhuwan13/wine_classification:v1切换到全屏模式,退出全屏
或者,他们可以将整个 ModelKit 解压到自己的实例中。
kit unpack docker.io/<USERNAME>/<CONTAINER_NAME>:<CONTAINER_TAG>
# 示例:kit unpack docker.io/用户名/容器名:标签全屏模式,退出全屏
在这一阶段,开发人员可以运行必要的测试以验证模型或代码是否按预期运行。测试成功后,他们可以通过调整集群位置或通过遵循此指南,用 Argo CD 将模型部署到生产服务器。
参与 KitOps 社区(一个专注于 KitOps 技术的社区)感谢社区的支持和反馈,KitOps 正快速进步。事实上,我们刚刚发布了 KitOps v1.0(已发布),并且正在积极寻找设计合作伙伴来帮助我们规划路线图。
想了解更多关于KitOps的信息,可以到我们的社区 Discord 联系我们。





