
昨天,DeepSeek 发布了一系列非常强大的语言模型,包括 DeepSeek R1 以及基于 Qwen 和 Llama 架构的多个较小模型。这些模型因其出色的性能和推理能力,尤其是它们的开源 MIT 许可证,在 AI 社区中引起了轰动。
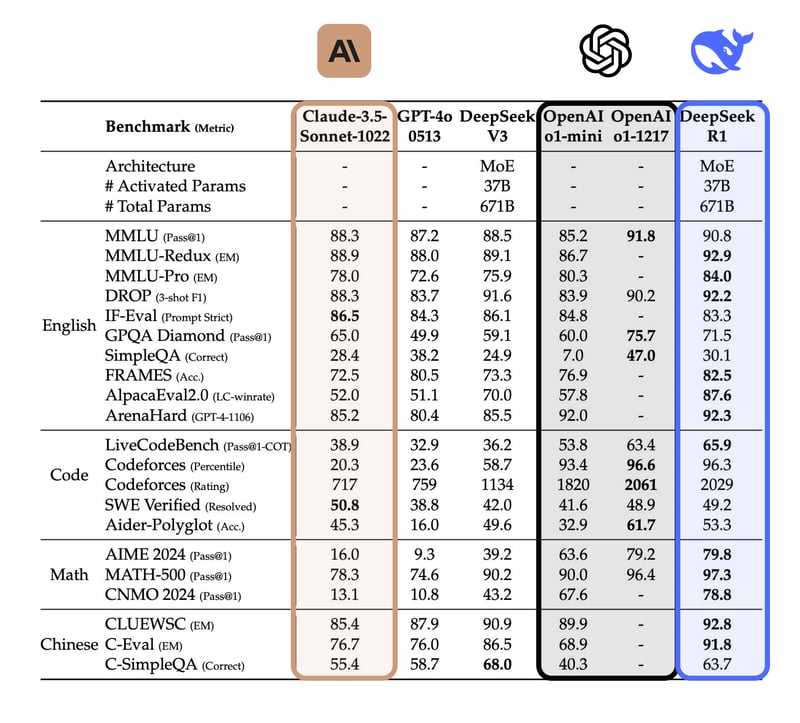
我一直通过它们的API进行测试,并且也在我的MacBook Pro上进行了本地测试。不得不说,即使是较小的模型,比如8B和14B模型,性能都非常出色。这里有一个基准测试,将DeepSeek R1与来自OpenAI和Anthropic的其他顶级模型进行比较。
在这篇指南里,我将教你如何设置好 Ollama 并在自己的电脑里运行 DeepSeek 最新的 R1 模型。但, 在开始之前,让我们先来了解一下这些模型。
深度搜索R1DeepSeek R1 是一个专注于推理的大规模语言模型,它能够处理需要多步问题解决和逻辑思维的各种任务。该模型采用了一种特别侧重于强化学习(RL)而非监督微调(SFT)的训练方法。这种方法有助于模型更好地自己找出答案。
该模型是开源的,这意味着其权重可以在MIT许可证下获取。这允许人们将其用于商业用途,对其进行修改,以及基于此创建新版本。这与许多其他封闭源代码的大型语言模型不同。
精简模型:更小但依然强大DeepSeek AI 还发布了该模型的较小的版本。这些模型有不同大小的版本,如1.5B、7B、8B、14B、32B和70B参数的模型。这些模型基于Qwen和Llama架构。这些较小的模型保留了大型模型的大部分推理能力,但体积更小,并且更易于在个人计算机上使用。
尤其是8B或更小的模型,这些模型更小,可以在配备CPU、GPU或Apple Silicon的普通电脑上运行。这让人们可以轻松地在家里尝试。
Ollama是什么?Ollama 是一个工具,它让你可以在自己的电脑上运行和管理大型语言模型(LLMs),使这个过程变得简单。它使下载、运行和使用这些模型变得更容易,而无需强大的服务器。Ollama 支持多种操作系统,包括 macOS、Linux 和 Windows。它设计简单易用,提供基本命令来下载、运行和管理模型。
Ollama 还提供了一种通过 API 使用这些模型的方法,这使得你可以把这些模型集成到其他应用程序中。重要的是,Ollama 提供了一个与 OpenAI API 兼容的实验性兼容层。这意味着你通常可以使用为 OpenAI 设计的现有应用程序和工具与你的本地 Ollama 服务器一起工作。它可以配置为使用 GPU,从而加快处理速度,并提供自定义模型创建和共享等功能。Ollama 是一个探索和使用 LLM 而无需依赖云服务的好方法。
来安装 Ollama 软件吧在使用DeepSeek模型之前,需要安装Ollama。以下是在不同操作系统上的安装方法:
macOS
- 访问 Ollama 网站 并下载 macOS 安装包。
- 打开下载的文件,将 Ollama 应用程序拖到“应用程序”文件夹里。
- 启动 Ollama 应用程序。它将在后台运行,并在系统托盘中显示。
- 打开终端并输入
ollama -v来检查安装是否成功。
Linux
- 打开终端(或命令行),运行以下命令来安装Ollama:
运行此命令以安装OLLAMA工具。
``` curl -fsSL https://ollama.com/install.sh | sh
2. 如果你更想手动安装,可以从[Ollama网站](https://ollama.com/download/)下载正确的`.tgz`文件。然后,使用这些命令将文件解压到`/usr`:
```bash
# 根据实际情况调整命令
tar -xvf 下载的.tgz -C /usr根据实际情况调整命令
使用 `curl` 命令下载 Ollama 的 Linux 版本:
```curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz```
然后使用 `tar` 命令解压并安装到 `/usr` 目录下:
```sudo tar -C /usr -xzf ollama-linux-amd64.tgz```-
要启动Ollama,请在终端中输入
ollama serve。您还可以在另一个终端中输入ollama -v来检查它是否正常运行。 - 为了使设置更可靠,创建一个systemd服务:首先,让我们为Ollama创建一个用户和组。
使用sudo命令添加名为ollama的用户并设置其属性,以及将当前用户添加到ollama组中。
- 然后,在
/etc/systemd/system/目录下创建名为ollama.service的服务文件,内容如下所示:
[Unit]
Description=Ollama 服务 # 描述服务的用途
After=network-online.target # 网络在线后执行
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3 # 服务重启间隔3秒
[Install]
WantedBy=default.target # 默认启动目标最后,开启并运行服务:
sudo systemctl daemon-reload
重新加载所有系统管理配置。
sudo systemctl enable ollama
启用ollama服务。
sudo systemctl start ollama
启动ollama服务。
sudo systemctl status ollama
检查ollama服务的状态。接下来我们将会执行一些系统命令来启动和检查ollama服务。
Windows
- 访问 Ollama 网站 并下载 Windows 安装程序 (
OllamaSetup.exe)。 - 运行安装程序。Ollama 将会被安装到您的用户配置文件中。
- Ollama 会以后台运行,并在托盘栏中显示图标。
- 打开命令提示符或 PowerShell,输入
ollama -v,查看是否安装成功。
Ollama 使用简单的命令来管理模型的。以下是一些你需要的关键命令:
ollama -v:查看已安装的 Ollama 版本。ollama pull <model_name>:<tag>:从 Ollama 库下载模型。ollama run <model_name>:<tag>:运行模型并开始交互式对话。ollama create <model_name> -f <Modelfile>:通过 Modelfile 创建自定义模型。ollama show <model_name>:显示模型详情。ollama ps:列出正在运行的模型。ollama stop <model_name>:从内存卸载模型。ollama cp <source_model> <destination_model>:复制模型文件。ollama delete <model_name>:删除模型。ollama push <model_name>:<tag>:将模型上传至模型库。
DeepSeek 模型可以在 Ollama 库中找到,有不同大小和类型。以下是一些明细:
- 模型尺寸: 模型有不同的尺寸,例如1.5b、7b、8b、14b、32b、70b和671b。这里的“b”表示十亿参数。较大的模型通常性能更好,但需要更多的资源,
- 量化版本: 一些模型有量化版本(例如,
q4_K_M,q8_0)。这些版本占用的内存较少,运行速度更快,但可能在质量上略有损失。 - 蒸馏版本: 深索也提供蒸馏版本(例如,
qwen-distill,llama-distill)。这些是较小的模型,经过训练以模仿较大的模型,平衡了性能和资源的使用。 - 标签: 每个模型都有一个
latest标签和其他特定标签来显示大小、量化和蒸馏方法。
这里是如何使用DeepSeek模型搭配Ollama。
加载模型
要下载 DeepSeek 模型,请使用命令:
运行以下命令来拉取模型:```
ollama pull deepseek-r1:<模型标签>
进入全屏和退出全屏
将 <model_tag> 替换为你想要使用的模型的特定标签。例如:
下载最新7B模型:
ollama pull deepseek-r1:7b <!-- 拉取 deepseek-r1:7b 仓库的命令 -->- 具有
q4_K_M量化参数的 14B 版本的 Qwen 蒸馏模型:
下载此模型。
ollama pull deepseek-r1:14b-qwen-distill-q4_K_M 下载带有 fp16 精度的 70B 参数的 Llama 精炼模型:
运行命令:ollama pull deepseek-r1:70b-llama-distill-fp16
这里有一些你可以用的标签,比如:
最新1.5B(十亿)7B(七十亿)8B(八十亿)14B(十四亿)32B(三十二亿)70B(七十亿)671B(六百七十一亿)1.5B-qwen-蒸馏-fp161.5B-qwen-蒸馏-q4_K_M1.5B-qwen-蒸馏-q8_014B-qwen-蒸馏-fp1614B-qwen-蒸馏-q4_K_M14B-qwen-蒸馏-q8_032B-qwen-蒸馏-fp1632B-qwen-蒸馏-q4_K_M32B-qwen-蒸馏-q8_070B-llama-蒸馏-fp16(70B-拉玛-蒸馏-fp16)70B-llama-蒸馏-q4_K_M(70B-拉玛-蒸馏-q4_K_M)70B-llama-蒸馏-q8_0(70B-拉玛-蒸馏-q8_0)7B-qwen-蒸馏-fp167B-qwen-蒸馏-q4_K_M7B-qwen-蒸馏-q8_08B-llama-蒸馏-fp16(8B-拉玛-蒸馏-fp16)8B-llama-蒸馏-q4_K_M(8B-拉玛-蒸馏-q4_K_M)8B-llama-蒸馏-q8_0(8B-拉玛-蒸馏-q8_0)
跑一个模型
下载了一个模型之后,你可以运行它时可以使用如下命令。
ollama run deepseek-r1:<标签>全屏模式里进入,退出全屏模式
比如说:
- 想要运行最新的7B模型,可以这样做:
运行命令 ollama deepseek-r1:7b (特定模型或版本名称)要运行14B Qwen的q4_K_M量化版本,可以这样做:
运行 ollama deepseek-r1:14b-qwen-distill-q4_K_M.
- 运行具有
fp16精度的 70B 参数的 Llama 精炼模型。
运行 ollama deepseek-r1:70b-llamma-distill-fp16 (这是一个命令)这将启动一个互动聊天过程,在这里你可以向模型提问或聊天。(注:此处保留了 'session',可以翻译为 '会话',但这里保持英文术语更符合原文表达。)
使用 API 的方法:
您也可以用Ollama API与DeepSeek模型配合使用。这里有个使用curl的例子:
curl http://localhost:11434/api/generate -d '{
"model": "deepseek-r1:7b",
"prompt": "写一首简短的关于星星的诗。"
}'进入全屏 / 退出全屏
对于聊天对话:
curl http://localhost:11434/api/chat -d '{
"model": "deepseek-r1:7b",
"messages": [
{
"role": "user",
"content": "写一首简短的诗关于星星"
}
]
}'切换到全屏 退出全屏
使用适用于OpenAI的APIOllama 提供了一个实验性的兼容层,使部分 OpenAI API 能够与之兼容。这可以让您使用原本为 OpenAI 设计的应用程序和工具,直接与您本地的 Ollama 服务器连接。
关键概念:
- API终端点: Ollama提供的与OpenAI兼容的API位于
http://localhost:11434/v1。 - 身份验证: 对于本地使用,Ollama的API不需要API密钥。您通常可以使用类似
"ollama"这样的占位符作为api_key参数。 - 部分兼容: Ollama的兼容性是实验性的且尚不完整。并非OpenAI API的所有功能都得到支持,并且在行为上可能有所不同。
- 专注于核心功能: Ollama主要致力于支持OpenAI API的核心功能,比如聊天完成、文本完成、模型列表和嵌入功能。
支持的接口和特性
这里是对支持的端点及其功能的概述:
/v1/chat/completions
- 目的: 生成对话风格的回复。
-
支持的功能:
-
多轮对话聊天(多轮对话)。
-
流式响应(实时输出)。
-
JSON模式(结构化的JSON输出)。
-
可复现的输出(使用
seed)。 -
视觉功能(处理图片的多模态模型,如
llava)。 - 工具(函数调用)。
-
支持的请求字段:
-
model: 要使用的Ollama模型的名称。 -
messages: 消息对象数组,每个对象包含一个role(system、user、assistant或tool)和content(文本或图片)。 -
frequency_penalty,presence_penalty: 控制重复。 -
response_format: 指定输出格式(例如json)。 -
seed: 用于可复现的输出。 -
stop: 生成停止序列。 -
stream: 启用/禁用流式输出。 -
stream_options: 流式输出的其他选项。 -
include_usage: 在流中包含使用信息。 -
temperature: 控制随机性程度。 -
top_p: 控制多样性程度。 -
max_tokens: 生成的最大标记数。 -
tools: 模型可以使用的工具列表。
API路径:/v1/completions -
目的: 生成文本生成。
-
支持的功能:
-
文本生成(单轮次生成)。
-
流式回复。
-
JSON 模式
-
可复现的输出。
-
支持的请求字段:
-
model: Ollama 模型的名称。 -
prompt: 输入文本。 -
frequency_penalty,presence_penalty: 避免重复。 -
seed: 用于可复现的输出。 -
stop: 停止序列。 -
stream: 开启/关闭流式回复。 -
stream_options: 流式回复的额外选项。 -
include_usage: 包含流式回复中的使用信息。 -
temperature: 控制随机程度。 -
top_p: 控制多样性程度。 -
max_tokens: 生成的最大 token 数。 suffix: 模型响应后的附加内容
-
/v1/models -
/v1/models/{模型名} - /v1/向量表示
如何在 OpenAI 客户端中使用 Ollama
如何配置流行的OpenAI客户端以与Ollama配合使用
- OpenAI的Python库:
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1/',
api_key='ollama', # 虽然忽略但必需
)
# 比如说这是一个测试消息
chat_completion = client.chat.completions.create(
messages=[
{'role': 'user', 'content': '比如说这是一个测试'},
],
model='deepseek-r1:7b',
)
# 比如说这是一个文本完成
completion = client.completions.create(
model="deepseek-r1:7b",
prompt="比如说这是一个测试",
)
# 列出示例模型
list_completion = client.models.list()
# 获取示例模型信息
model = client.models.retrieve("deepseek-r1:7b")
- OpenAI的JavaScript库:
导入 OpenAI 模块 from 'openai';
const openai = new OpenAI({
baseURL: 'http://localhost:11434/v1/',
apiKey: 'ollama', // 忽略,但必需填入
});
// 聊天完成示例
const chatCompletion = await openai.chat.completions.create({
messages: [{ role: 'user', content: '说这是个测试' }],
model: 'deepseek-r1:7b',
});
// 文本完成示例
const completion = await openai.completions.create({
model: "deepseek-r1:7b",
prompt: "说这是个测试。",
});
// 列出模型示例
const listCompletion = await openai.models.list()
// 获取模型信息示例
const model = await openai.models.retrieve("deepseek-r1:7b")curl直接使用 API:
# 聊天会话
curl http://localhost:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-r1:7b",
"messages": [
{
"role": "user",
"content": "Hello!"
}
]
}'
# 文本生成
curl http://localhost:11434/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek-r1:7b",
"prompt": "Say this is a test"
}'
# 列出模型
curl http://localhost:11434/v1/models
# 获取模型详情
curl http://localhost:11434/v1/models/deepseek-r1:7b
# 文本嵌入
curl http://localhost:11434/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"model": "all-minilm",
"输入": ["为什么天空是蓝色的?", "为什么草是绿色的?"]
}'
在选择DeepSeek模型时,请考虑以下因素:
- 大小: 较大的模型通常表现更好,但需要更多的资源。如果你资源有限,建议从较小的模型开始。
- 量化: 量化模型用的内存少一些,但可能稍微影响质量。
- 蒸馏: 蒸馏模型在性能和资源使用之间找到了不错的平衡。
试一下不同的模型,看看哪个最合你的胃口。
一些额外的小技巧- 请随时检查Ollama库,获取最新的模型和标签。
- 使用
ollama ps来监控模型的资源使用情况。 - 您可以调整如
temperature、top_p和num_ctx这样的参数来优化模型的输出。
如果有任何问题,请查看Ollama的日志:
- 在 macOS 上:
~/.ollama/logs/server.log - 在 Linux 上, 使用
journalctl -u ollama --no-pager查看日志 (其中journalctl用于查看系统日志) - 在 Windows 上:
%LOCALAPPDATA%\Ollama\server.log,其中%LOCALAPPDATA%是本地应用数据文件夹
你也可以使用 OLLAMA_DEBUG=1 环境变量设置来查看更详细的日志。
当然,本地运行这些模型只是第一步。你可以通过API把这些模型集成到你自己的应用中,构建诸如聊天机器人,带有检索增强生成(RAG)的研究工具等自定义应用,等等,还有很多其他可能的应用。
我已经写了好几篇关于如何更深入地探索这些模型的指南,例如
-
使用 Docker 搭建 Postgres 和 pgvector 以构建 RAG 应用 - 学习如何使用 Docker 搭建 Postgres 和 pgvector 以构建 RAG(检索增强生成)应用的一步一步指南。
-
深入了解Postgres和pgvector中的向量相似度搜索 - 让向量相似度搜索在Postgres中更简单。了解如何创建索引、查询向量等。点击此处阅读更多关于如何使用pgvector的详细教程。
-
使用AI SDK在Node中创建AI - 了解如何在Node中使用AI SDK创建AI,以自动化工作流程及任务。
- 如何使用LLM和网络爬虫丰富客户数据 - 学习如何使用LLM和Puppeteer爬取客户网站,从而丰富其数据,为您的SaaS产品所用。
希望这份指南已经对你有所帮助,展示在您自己的电脑上轻松上手Ollama并运行这些最先进的语言模型是多么简单。请记得,您不仅限于使用DeepSeek的模型,您还可以使用Ollama上任何可用的模型,甚至直接使用其他平台如Hugging Face上的模型。
如果你有任何问题或意见,请在下面的评论中告诉我。








