
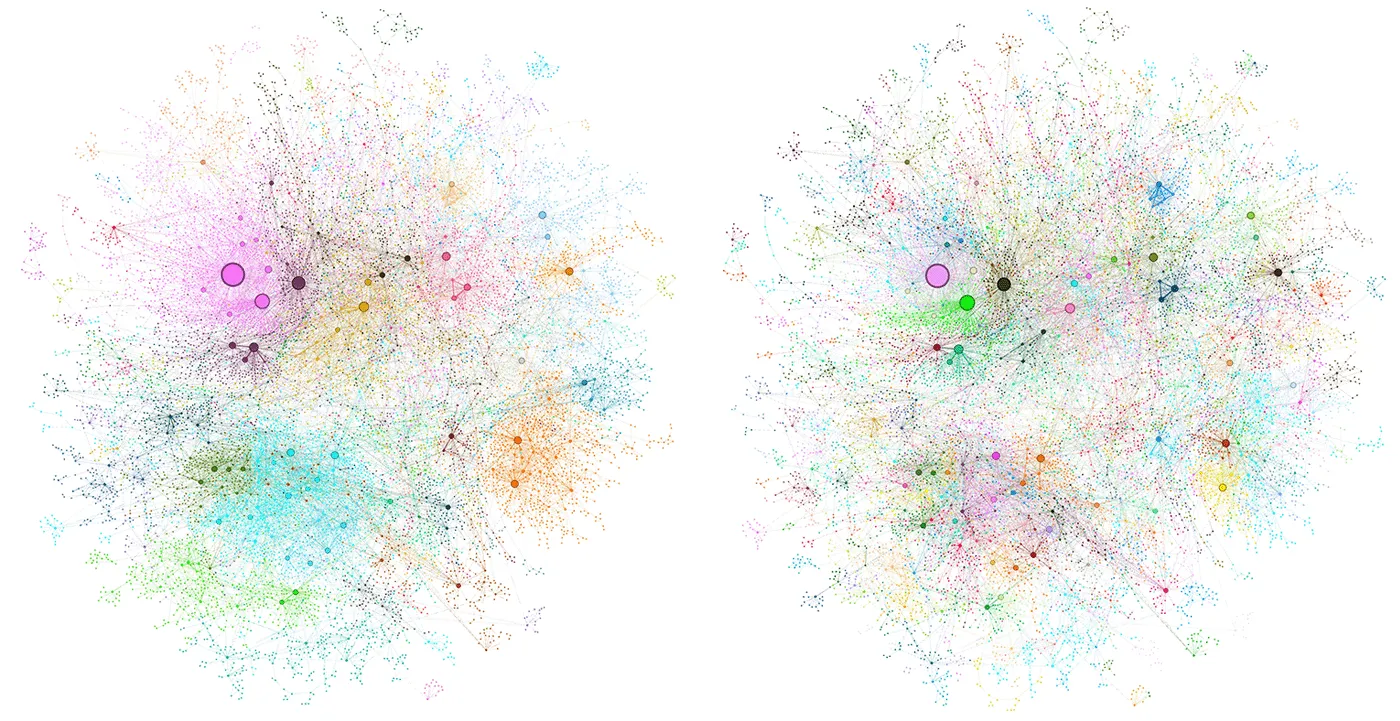
传统的RAG方法主要依赖于语义相似度搜索,当遇到需要连接分散信息或理解大规模数据集整体背景的复杂问题时,往往表现不佳。这时,GraphRAG这种新方法出现了,它利用知识图谱的潜力来克服这些限制并增强RAG系统的功能。
理解:Baseline RAG的问题所在尽管基准的RAG系统对于简单的问答任务很有用,但在综合不同来源的信息或理解数据集的整体主题时会遇到困难。例如,如果你问一个基准的RAG系统“根据这个研究数据集,气候变化的主要原因是什么?”,它可能难以提供一个全面的答案,因为它无法将数据集中分散的有关气候变化的信息联系起来。这表明需要一种更结构化和智能的方式来处理RAG。
一个利用知识图谱的解决方案GraphRAG 通过利用大语言模型从原始文本数据中提取知识图谱,GraphRAG 满足了这一需求。这个知识图谱将信息表示为实体和关系的相互连接网络,相比简单的文本片段,知识图谱提供了更丰富的信息表示。这种结构化的表示让 GraphRAG 在回答复杂问题时表现出色,这些问题需要推理和连接不同信息片段。
GraphRAG 结构GraphRAG 的架构包括几个关键组件。GraphRAG 知识模型定义了一个标准化的数据模型,用于表示文档、TextUnits、实体、关系和社区报告等。基于 DataShaper 库的数据塑形工作流使声明式数据处理成为可能,从而使管道更加灵活和可定制。基于 LLM 的工作流步骤将 LLM 集成到索引过程中,使用自定义动词执行任务如实体提取和总结。
深度解析GraphRAG过程GraphRAG过程包含两个主要步骤:索引和查询。
索引工作:
在索引时,输入文本会被划分为称为TextUnits的可管理的单元。LLMs从这些TextUnits中提取实体、关系和声明,形成知识图。
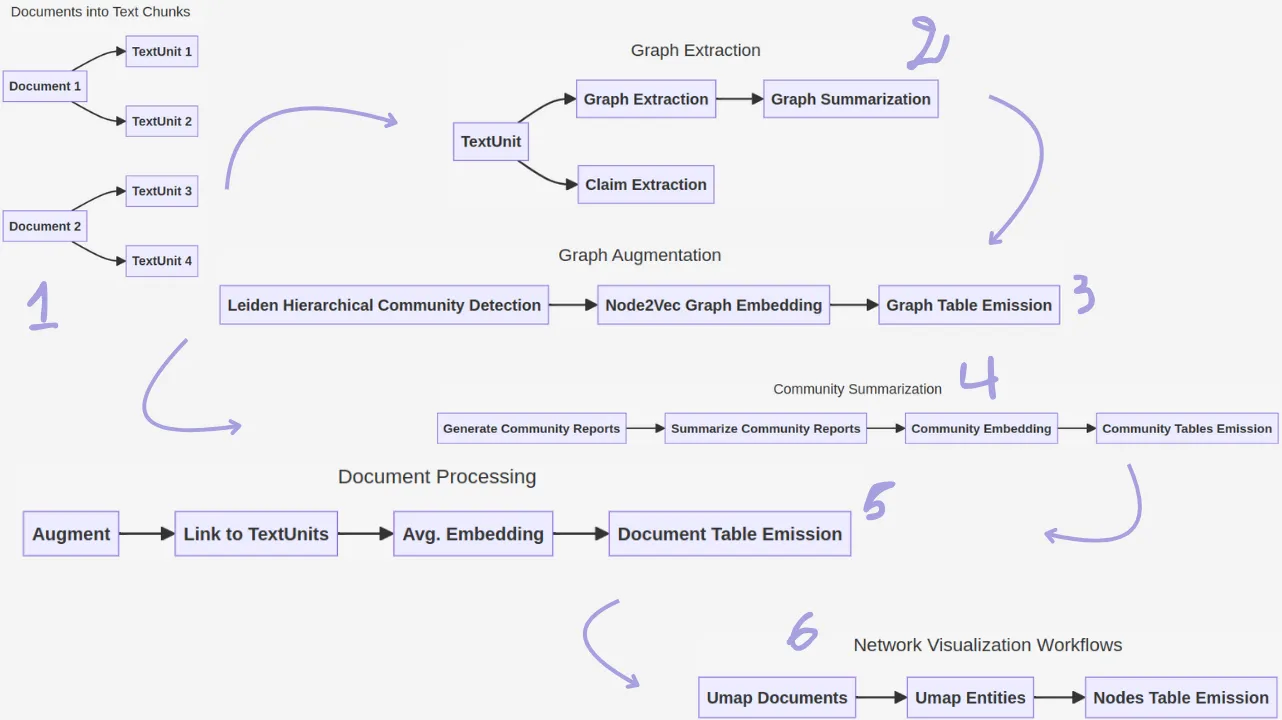
此外,一个称为“社区发现过程”的方法识别出相关的实体群组,并为每个这样的群组生成摘要,提供这些群组内不同主题的高层次概述。
查一下吧:
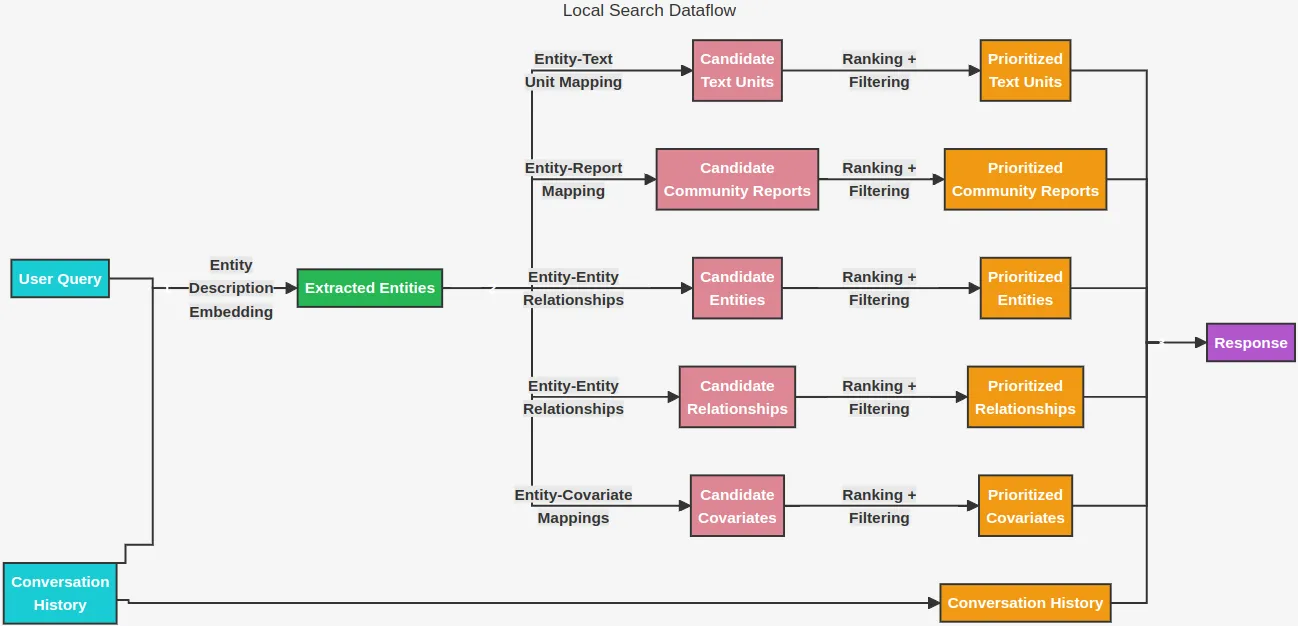
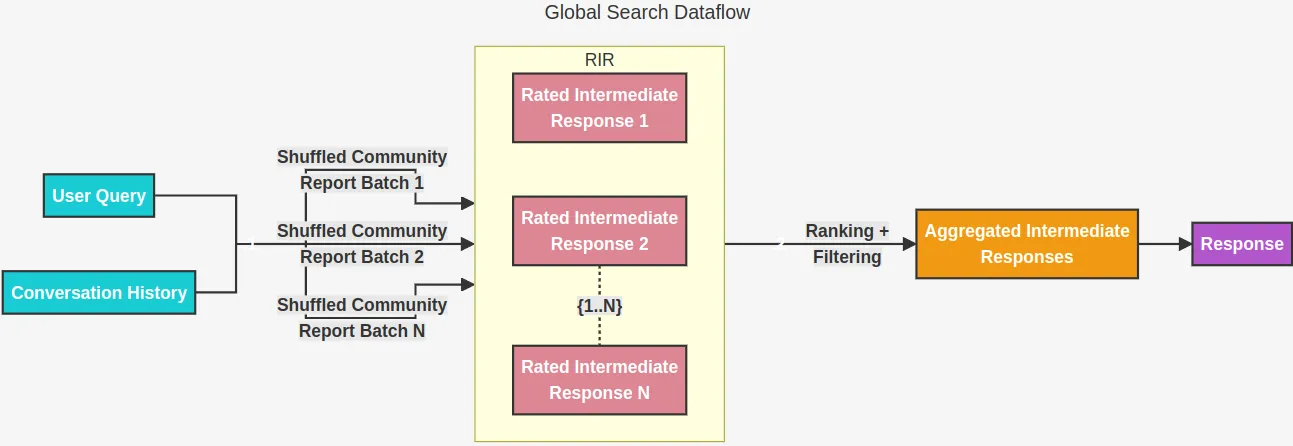
当用户提交查询后,GraphRAG 利用知识图谱检索相关的信息。它提供了两种主要的搜索方式:本地搜索和全局搜索。
本地搜索功能专注于回答关于特定实体的相关问题,探索它们之间的关系,相关声明以及文本片段。
全球搜索则处理需要理解整个数据集内容的更广泛问题范围。它分析社区摘要以识别总体主题并从数据集的各个部分汇总信息。
通过使用知识图谱,GraphRAG 在基线 RAG 上提供了显著的优势。它通过使系统能够连接分散的信息片段并生成新的见解,从而增强了推理能力。它通过将信息组织成有意义的集群并为每个集群提供摘要说明,从而提供了对数据集的全面理解。此外,它还改进了 RAG 的整体性能,尤其是在处理复杂问题时。
应用案例GraphRAG的应用非常广泛,涵盖了多个领域。在研究领域,它可以借助从大量科学论文数据集中综合信息的能力,来解答复杂的研究问题。在企业环境中,GraphRAG还能支持对话式AI系统,这些系统能够对特定领域(例如客户支持或内部知识库等)进行推理。此外,GraphRAG还可以用于创建知识探索工具,帮助用户通过互动探索大规模数据集,理解不同概念之间的关系,并发现新的洞察。
代码片段首先安装 Ollama,一个本地运行大型的语言模型的工具,并启动服务器。
运行此命令以从ollama.com下载并安装脚本: curl -fsSL https://ollama.com/install.sh | sh
启动一下服务器,
ollama serve(命令或函数名)我们然后下载这两个模型,一个是 llama3.1 用于生成文本,另一个是 bge-large 用于生成嵌入。
ollama pull llama3.1 // 拉取模型
ollama pull bge-large // 拉取模型我们来拉取这两个模型:
你可以用 Docker 使用 ollama。
docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama (这个命令用来在后台运行 ollama 容器,并映射端口,同时指定容器名称为 ollama)
接下来,使用以下命令从仓库拉取 llama3.1 模型:
docker exec -it ollama ollama pull llama3.1
接下来,使用以下命令从仓库拉取 bge-large 模型:
docker exec -it ollama ollama pull bge-large接下来,我们来安装GraphRAG库。
在终端中运行以下命令来安装graphrag包:
pip install graphrag我们为项目创建了一个文件夹,并在其中创建了一个子文件夹来存放输入数据。
创建目录及其父目录: `mkdir -p ./rag_graph/input`一个样本故事被保存为输入文件夹内的一个文本文件。
text = """
在名为诺沃斯的城市中,一位名叫艾丽丝的著名建筑师正在忙于她的最新项目。艾丽丝设计建筑已有15多年,她与她的导师、也是著名建筑师罗伯特·李的合作非常出名。罗伯特教会了艾丽丝所有她所知道的东西,他们仍然是亲密的朋友。
艾丽丝的丈夫大卫是一名在TechCorp工作的软件工程师。大卫对他的工作充满热情,经常与他的同事艾米丽合作,艾米丽是一名数据科学家。艾米丽也是艾丽丝在大学时最好的朋友,两人曾经一起学习。艾米丽经常访问艾丽丝和大卫的家,他们常常在晚餐时讨论各自的工作。
艾丽丝和大卫有一个8岁的女儿索菲,她喜欢和她的祖父母约翰和玛丽一起度过时光。约翰是大卫的父亲,一位退休的教授,玛丽是一名退休的护士。他们住在邻近的城镇格林维尔,每个周末都会来诺沃斯看望家人。
有一天,艾丽丝收到了来自诺沃斯市议会的邀请,让她展示她的最新建筑设计。她兴奋地想要展示她的设计,并立即联系了罗伯特·李来审查她的计划。罗伯特很高兴能帮忙,因为他一直都很欣赏艾丽丝的才能。同时,大卫在TechCorp忙于一个新的人工智能项目,他的同事艾米丽也在该项目中工作,这个项目由他们的经理迈克尔·布朗领导。
随着展示日的临近,艾丽丝在罗伯特的指导下准备她的设计。大卫和索菲也来参加活动支持艾丽丝。诺沃斯市议会对她的工作印象深刻,并决定批准这个项目,这标志着艾丽丝的又一次成功。活动结束后,一家人到他们常去的绿橄榄餐厅庆祝,艾米丽和罗伯特也加入了他们。
"""
with open("./rag_graph/input/story.txt", "w") as f:
f.write(text)在项目目录中,我们先初始化GraphRAG,并生成所需的配置文件。
使用以下命令初始化索引并将根目录设置为 ./rag_graph:
python -m graphrag.index --init --root ./rag_graph在 .env 文件中,你可以包含任何必要的 API 密钥,例如:GRAPHRAG_API_KEY=EMPTY。
settings.yaml 文件被修改为指定之前下载的模型(llama2.1 和 bge-large),它们各自的本地服务器地址,以及其他参数,比如最大令牌数和并发量。这些设置配置 GraphRAG 使用 Ollama 来进行文本生成和嵌入。
LLMS:
- 模型:llama3.1
- 最大token数:2000
- api_base: http://127.0.0.1:11434/v1 (ollama 服务器端点)
- 最大重试数:1
- 并发请求数:1
- 注释掉这一行代码
model_supports_json: true
词嵌入:
- 模型: bge-large:latest
- api_base: http://127.0.0.1:11434/v1
- 重试次数上限: 1
- 并发请求数: 1
- 批次大小: 1
- 每个批次的最大令牌数: 8191
settings.yaml 设置文件:
encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_chat # 或 azure_openai_chat
model: llama3.1
# model_supports_json: true # 如果可用,建议启用此选项
max_tokens: 2000
# request_timeout: 180.0
api_base: http://127.0.0.1:11434/v1
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # 设置漏桶速率限制
# requests_per_minute: 10_000 # 设置漏桶速率限制
max_retries: 1
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # 如果 Azure 建议等待时间,则暂停
concurrent_requests: 1 # 可以同时发出的并行请求数量
parallelization:
stagger: 0.3
# num_threads: 50 # 并行处理时使用的线程数
async_mode: threaded # 或 asyncio
embeddings:
## parallelization: 为嵌入覆盖全局并行化设置
async_mode: threaded # 或 asyncio
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # 或 azure_openai_embedding
model: bge-large:latest
api_base: http://127.0.0.1:11434/v1
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # 设置漏桶速率限制
# requests_per_minute: 10_000 # 设置漏桶速率限制
max_retries: 1
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # 如果 Azure 建议等待时间,则暂停
concurrent_requests: 1 # 可以同时发出的并行请求数量
batch_size: 1 # 每次请求发送的文档数量
batch_max_tokens: 8191 # 每次请求中发送的最大 token 数量
# target: required # 或 optional
chunks:
size: 300
overlap: 100
group_by_columns: [id] # 默认情况下,不允许片段跨越文档
input:
type: file # 或 blob
file_type: text # 或 csv
base_dir: "input"
file_encoding: utf-8
file_pattern: ".*\\.txt$"
cache:
type: file # 或 blob
base_dir: "cache"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
storage:
type: file # 或 blob
base_dir: "output/${timestamp}/artifacts"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
reporting:
type: file # 或 console, blob
base_dir: "output/${timestamp}/reports"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
entity_extraction:
## llm: 为该任务覆盖全局 llm 设置
## parallelization: 为该任务覆盖全局并行化设置
## async_mode: 为该任务覆盖全局异步模式设置
prompt: "prompts/entity_extraction.txt"
entity_types: [organization,person,geo,event]
max_gleanings: 0
summarize_descriptions:
## llm: 为该任务覆盖全局 llm 设置
## parallelization: 为该任务覆盖全局并行化设置
## async_mode: 为该任务覆盖全局异步模式设置
prompt: "prompts/summarize_descriptions.txt"
max_length: 500
claim_extraction:
## llm: 为该任务覆盖全局 llm 设置
## parallelization: 为该任务覆盖全局并行化设置
## async_mode: 为该任务覆盖全局异步模式设置
# enabled: true
prompt: "prompts/claim_extraction.txt"
description: "任何可能与信息发现相关的主张或事实。"
max_gleanings: 0
community_report:
## llm: 为该任务覆盖全局 llm 设置
## parallelization: 为该任务覆盖全局并行化设置
## async_mode: 为该任务覆盖全局异步模式设置
prompt: "prompts/community_report.txt"
max_length: 2000
max_input_length: 7000
cluster_graph:
max_cluster_size: 10
embed_graph:
enabled: false # 如果为 true,则将为节点生成 node2vec 嵌入
# num_walks: 10
# walk_length: 40
# window_size: 2
# iterations: 3
# random_seed: 597832
umap:
enabled: false # 如果为 true,则将为节点生成 UMAP 嵌入
snapshots:
graphml: false
raw_entities: false
top_level_nodes: false
local_search:
# text_unit_prop: 0.5
# community_prop: 0.1
# conversation_history_max_turns: 5
# top_k_mapped_entities: 10
# top_k_relationships: 10
# max_tokens: 12000
global_search:
# max_tokens: 12000
# data_max_tokens: 12000
# map_max_tokens: 1000
# reduce_max_tokens: 2000
# concurrency: 32启动索引管道:
图谱RAG索引流程被执行,处理故事文本。这包括生成文本单元,并提取实体和关系,构建社区层级结构,并生成摘要内容。生成的知识图谱及相关数据会被保存到指定的输出目录中。
python -m graphrag.index --root ./rag_graph
# 这是一个用于索引的命令最后,我们可以使用全局搜索或本地搜索来查询索引数据。全局搜索适合询问整个故事的大致情况(“哪些是最主要的主题……?”),而本地搜索则适用于询问特定的人物或事物的问题(“谁是斯克鲁奇……?”)。所选的搜索方法会从知识图里找相关信息,并根据你的问题给出相应的回答。
使用命令行进行全局搜索
python -m graphrag.query --root ./rag_graph --method global 这个故事里的主要主题有哪些?使用命令行进行本地查找:
python -m graphrag.query --root ./rag_graph --method local "谁是斯克鲁奇,他的主要关系是什么?"(例如)
全局搜索技术通过在所有AI生成的社区报告上采用 map-reduce 方式搜索来生成答案。这需要大量资源的方法,但通常对于需要对整个数据集有整体理解的问题(比如:这本笔记本中提到的草药有哪些最重要的数值?)会给出很好的回应。
1. 导入所需的库并设置大规模语言模型:
我们首先导入所需的库,包括用于数据处理的pandas,用于分词的tiktoken,以及来自graphrag库的查询执行组件。
import os
import pandas as pd
import tiktoken
from graphrag.query.indexer_adapters import read_indexer_entities, read_indexer_reports
from graphrag.query.llm.oai.chat_openai import ChatOpenAI
from graphrag.query.llm.oai.typing import OpenaiApiType
from graphrag.query.structured_search.global_search.community_context import (
GlobalCommunityContext,
)
from graphrag.query.structured_search.global_search.search import GlobalSearch 我们然后初始化一个 ChatOpenAI 实例,配置它使用本地通过 Ollama 托管的 llama3.1 模型。
api_key = "EMPTY"
llm_model = "llama3.1"
llm = ChatOpenAI(
api_base="http://127.0.0.1:11434/v1",
api_key=api_key,
model=llm_model,
api_type=OpenaiApiType.OpenAI,
max_retries=20,
)
token_encoder = tiktoken.get_encoding("cl100k_base")一次基本的测试确保LLM端点(LLM端点)正常工作。
# 用户的消息列表
messages = [
{
"role": "user",
"content": "Hi"
}
]
# 生成响应的模型
response = llm.generate(messages=messages)
# 打印响应
print(response)2. 加载数据并构建上下文:
接下来,我们加载在索引阶段生成的社区报告和实体数据。这些报告以分层组织,代表了数据集的不同方面。我们通过指定 COMMUNITY_LEVEL 来确定所用报告的粒度。
# 由索引管道生成的Parquet文件
INPUT_DIR = "./output/run-id" # 请将 run-id 替换为创建的编号
COMMUNITY_REPORT_TABLE = "artifacts/create_final_community_reports"
ENTITY_TABLE = "artifacts/create_final_nodes"
ENTITY_EMBEDDING_TABLE = "artifacts/create_final_entities"
# 从Leiden社区层次结构中的哪个层次加载社区报告
# 数值越高表示使用更细粒度的社区报告(代价是更高的计算开销)
COMMUNITY_LEVEL = 2
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet") # 读取实体数据
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet") # 读取社区报告数据
entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")
reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL) # 读取索引报告数据
entities = read_indexer_entities(entity_df, entity_embedding_df, COMMUNITY_LEVEL) # 读取索引实体数据
# 基于社区报告构建全局上下文环境
context_builder = GlobalCommunityContext(
community_reports=reports,
entities=entities, # 社区权重用于排序时可设为 None
token_encoder=token_encoder,
)全球社区上下文 接着进行初始化,负责选择和格式化相关社区报告作为大型语言模型的上下文信息。
3. 设置全局搜索:
我们为全局搜索的上下文构建、映射和缩减步骤定义了一些参数。这些参数控制上下文大小、报告重新排序、是否包含社区排名和权重,以及每个步骤的LLM参数(如大语言模型参数)。
context_builder_params = {
"use_community_summary": False, # False 表示使用完整的社区报告。True 表示使用社区简短摘要。
"shuffle_data": True,
"include_community_rank": True,
"min_community_rank": 0,
"community_rank_name": "rank",
"include_community_weight": True,
"community_weight_name": "出现次数权重",
"normalize_community_weight": True,
"max_tokens": 1000, # 根据你所使用模型的 token 限制调整此值(如果你使用的是具有 8k 限制的模型,一个好的设置可能是 5000)
"context_name": "报告",
}
map_llm_params = {
"max_tokens": 1000,
"temperature": 0.0,
"response_format": {"type": "json_object"},
}
reduce_llm_params = {
"max_tokens": 2000, # 根据你所使用模型的 token 限制调整此值(如果你使用的是具有 8k 限制的模型,一个好的设置可能是 1000-1500)
"temperature": 0.0,
}
search_engine = GlobalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
max_data_tokens=1000, # 根据你所使用模型的 token 限制调整此值(如果你使用的是具有 8k 限制的模型,一个好的设置可能是 5000)
map_llm_params=map_llm_params,
reduce_llm_params=reduce_llm_params,
allow_general_knowledge=False, # 若设置为 True,将添加指令鼓励 LLM 在响应中加入一般知识,这可能会增加幻觉,但在某些用例中可能有用。
json_mode=True, # 如果你的 LLM 模型不支持 JSON 模式,请将其设置为 False。
context_builder_params=context_builder_params,
concurrent_coroutines=32,
response_type="多个段落的自由格式文本", # 自由格式文本描述响应类型和格式,可以是任何内容,例如优先列表项、单段落文本、多个段落的文本、多页报告
)然后我们建立 GlobalSearch 引擎,传递 LLM 实例、上下文构建器、分词工具以及其它配置参数。
4. 进行全局搜索:
我们使用 asearch 方法执行全球搜索,查询的内容是 "谁与 Alice Johnson ,在任何项目上一起工作过?"。
// 查询与Alice Johnson合作过的人员
result = await search_engine.asearch(
"谁和Alice Johnson在任何项目上合作过?"
)
print(result['response'])搜索引擎检索与之相关的社区报告,提取关键点并汇总,根据汇总的信息生成最后的回答。
打印 llms 调用次数和 token 数:
print(f"LLM 调用次数:{result.llm_calls}。LLM 令牌数量:{result.prompt_tokens}")或者
本地搜索示例
1. 导入所需的依赖库并设置环境:
我们从导入必要的库开始,包括来自graphrag库的组件,用于处理查询过程中的各个方面。我们为本地搜索做准备,它特别适合回答需要特定实体详细信息的问题。
import os # 导入操作系统模块
import pandas as pd # 导入pandas数据处理库
import tiktoken # 导入tiktoken库
from graphrag.query.context_builder.entity_extraction import EntityVectorStoreKey # 导入实体提取类
from graphrag.query.indexer_adapters import (
read_indexer_covariates, # 读取索引协变量
read_indexer_entities, # 读取索引实体
read_indexer_relationships, # 读取索引关系
read_indexer_reports, # 读取索引报告
read_indexer_text_units, # 读取索引文本单元
)
from graphrag.query.input.loaders.dfs import (
store_entity_semantic_embeddings, # 存储实体语义嵌入
)
from graphrag.query.llm.oai.chat_openai import ChatOpenAI # 导入ChatOpenAI聊天模型
from graphrag.query.llm.oai.embedding import OpenAIEmbedding # 导入OpenAIEmbedding嵌入模型
from graphrag.query.llm.oai.typing import OpenaiApiType # 导入OpenaiApiType类型定义
from graphrag.query.question_gen.local_gen import LocalQuestionGen # 导入本地问题生成器
from graphrag.query.structured_search.local_search.mixed_context import (
LocalSearchMixedContext, # 导入混合上下文本地搜索类
)
from graphrag.query.structured_search.local_search.search import LocalSearch # 导入本地搜索类
from graphrag.vector_stores.lancedb import LanceDBVectorStore # 导入LanceDB向量存储库2. 加载数据并建立上下文:
我们会从索引管道输出的数据中加载信息,包括实体、关系、社区报告以及文本单元。这些数据来源为我们提供了索引信息的全面视角。
# 加载表格到数据帧
INPUT_DIR = "./output/run-id" # 请用生成的run id替换
LANCEDB_URI = f"{INPUT_DIR}/lancedb"
COMMUNITY_REPORT_TABLE = "artifacts/create_final_community_reports"
ENTITY_TABLE = "artifacts/create_final_nodes"
ENTITY_EMBEDDING_TABLE = "artifacts/create_final_entities"
RELATIONSHIP_TABLE = "artifacts/create_final_relationships"
COVARIATE_TABLE = "artifacts/create_final_covariates"
TEXT_UNIT_TABLE = "artifacts/create_final_text_units"
COMMUNITY_LEVEL = 2
# 读取实体
# 读取节点表以获取社区和度数据
entity_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_TABLE}.parquet")
entity_embedding_df = pd.read_parquet(f"{INPUT_DIR}/{ENTITY_EMBEDDING_TABLE}.parquet")
entities = read_indexer_entities(entity_df, entity_embedding_df, COMMUNITY_LEVEL)
# 将描述嵌入加载到内存中的lancedb向量存储中
# 若要连接到远程数据库服务器,请指定url和端口值。
description_embedding_store = LanceDBVectorStore(
collection_name="entity_description_embeddings",
)
description_embedding_store.connect(db_uri=LANCEDB_URI)
entity_description_embeddings = store_entity_semantic_embeddings(
entities=entities, vectorstore=description_embedding_store
)
# 读取关系
relationship_df = pd.read_parquet(f"{INPUT_DIR}/{RELATIONSHIP_TABLE}.parquet")
relationships = read_indexer_relationships(relationship_df)
# 注意:默认情况下,协变量是关闭的,因为它们通常需要微调才能变得有价值
# 请参阅GRAPHRAG_CLAIM_*配置
# covariate_df = pd.read_parquet(f"{INPUT_DIR}/{COVARIATE_TABLE}.parquet")
# claims = read_indexer_covariates(covariate_df)
report_df = pd.read_parquet(f"{INPUT_DIR}/{COMMUNITY_REPORT_TABLE}.parquet")
reports = read_indexer_reports(report_df, entity_df, COMMUNITY_LEVEL)
# 读取文本单元
text_unit_df = pd.read_parquet(f"{INPUT_DIR}/{TEXT_UNIT_TABLE}.parquet")
text_units = read_indexer_text_units(text_unit_df)我们利用LanceDB这一向量数据库来存储和高效检索实体的嵌入,这对于识别与用户查询相关的实体,非常重要。
3. 配置词嵌入模型的步骤:
我们初始化一个 OpenAIEmbedding 实例,配置它使用本地通过 Ollama 提供的 bge-large 模型。此模型将用于生成文本的嵌入向量,从而使我们在搜索过程中能够找到语义相似的实体和文本片段。
embedding_model = "bge-large:latest" # 嵌入模型名称
text_embedder = OpenAIEmbedding( # OpenAI嵌入模型封装
api_key=api_key,
api_base="http://127.0.0.1:11434/v1",
api_type=OpenaiApiType.OpenAI, # API类型为OpenAI
model=embedding_model,
deployment_name=embedding_model, # 部署名称
max_retries=20, # 最大重试次数
)4. 创建本地搜索上下文构建器:
我们创建一个 LocalSearchMixedContext 实例,为其提供访问已加载的数据(实体、关系、报告、文本单元(text units))和嵌入模型的权限。这个上下文构建器(Context Builder)负责根据用户的查询选择并格式化相关的信息。
context_builder = LocalSearchMixedContext(
community_reports=reports,
text_units=text_units,
entities=entities,
relationships=relationships,
# 如果索引时未运行协变量,则设为 None
covariates=None,
entity_text_embeddings=description_embedding_store,
embedding_vectorstore_key=EntityVectorStoreKey.ID, # 如果向量存储使用实体标题作为ID,则设为 EntityVectorStoreKey.TITLE
text_embedder=text_embedder,
token_encoder=token_encoder,
)5. 创建本地搜索引擎:
我们启动 LocalSearch 引擎,提供 LLM、上下文构建器、分词器和搜索相关的参数。这些参数决定了上下文窗口中不同类型数据的比例分配,例如,文本单元和社区报告。此外,这些参数还决定了检索的相关实体数量和最大上下文窗口大小。
text_unit_prop: 上下文窗口中分配给相关文本单位的比例community_prop: 上下文窗口中分配给社区报告的比例。其余部分用于实体和关系。text_unit_prop和community_prop之和不超过1。conversation_history_max_turns: 对话历史中包含的最大对话轮数。conversation_history_user_turns_only: 如果为 True,则仅包含用户查询。top_k_mapped_entities: 从实体描述存储中检索出的相关实体数量。top_k_relationships: 控制从外部拉入上下文窗口的关系数量。include_entity_rank: 如果为 True,则在上下文窗口的实体表中包含实体排名。默认实体排名 = 节点度。include_relationship_weight: 如果为 True,则在上下文窗口中包含关系权重。include_community_rank: 如果为 True,则在上下文窗口中包含社区排名。return_candidate_context: 如果为 True,则返回包含所有可能相关候选实体、关系和协变量记录的数据框集合。数据框中的“in_context”列表明该记录是否包含在上下文窗口中。max_tokens: 用于上下文窗口的最大标记数。
local_context_params = {
"text_unit_prop": 0.5,
"community_prop": 0.1,
"conversation_history_max_turns": 5,
"conversation_history_user_turns_only": True,
"top_k_mapped_entities": 10,
"top_k_relationships": 10,
"include_entity_rank": True,
"include_relationship_weight": True,
"include_community_rank": False,
"return_candidate_context": False,
"embedding_vectorstore_key": EntityVectorStoreKey.ID, # 如果向量存储使用实体标题作为ID,则设置为EntityVectorStoreKey.TITLE
"max_tokens": 12_000, # 根据你的模型的token限制调整这个值(如果你使用的是8k限制的模型,一个好的设置可能是5000)
}
llm_params = {
"max_tokens": 2_000, # 根据你的模型的token限制调整这个值(如果你使用的是8k限制的模型,一个好的设置可能是1000-1500)
"temperature": 0.0,
}
search_engine = LocalSearch(
llm=llm,
context_builder=context_builder,
token_encoder=token_encoder,
llm_params=llm_params,
context_builder_params=local_context_params,
response_type="比如多个段落", # 自由形式的文字描述响应类型和格式,可以是任何格式,例如优先列表、单段落、多个段落或多页报告
)6. 运行本地搜索功能:
最后,我们使用 asearch 方法执行本地搜索,查询“关于 Alice Johnson 的信息”。搜索引擎找到相关实体(在这种情况下是 Alice Johnson),从各种数据源获取相关信息,并根据这些信息生成全面的回答。
question = "跟我讲讲Alice Johnson"
result = await search_engine.asearch(question)
print(result.response)GraphRAG 在检索增强生成领域取得了重大进展。通过运用知识图谱,它克服了传统 RAG 方法的局限性,使大型语言模型能够更有效地进行推理,全面理解复杂的数据库,并为各种问题提供更准确、更有见地的答案。随着这一领域研究和开发的继续,我们可以期待 GraphRAG 在未来 AI 驱动的知识检索和探索领域发挥越来越重要的作用。
我的领英个人资料 : https://www.linkedin.com/in/ayoub-kirouane3
我的HuggingFace(一个机器学习平台)https://huggingface.co/ayoubkirouane





