

在本文中,我们将讨论论文《大型自监督模型作为强大的半监督学习者的作用》(它被称为SimCLRv2,是SimCLR的一个改进版本)的主要贡献。
SimCLR 的重大更新
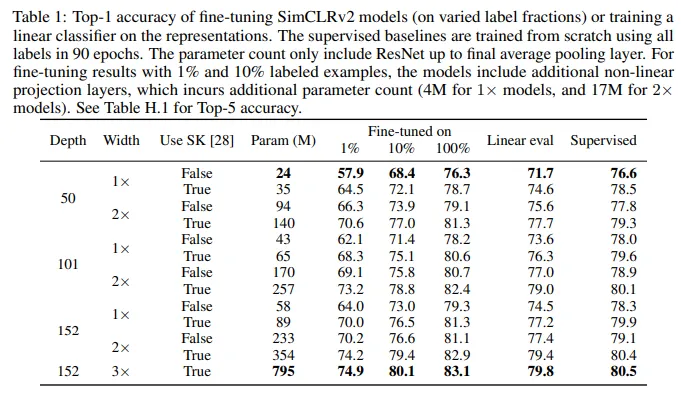
- Larger ResNet models:在SimCLR中使用的最大模型是ResNet50(x4)。在SimCLRv2中,作者使用了带有和不带选择性核卷积层的ResNet152(x3)进行预训练。
- Increase capacity of Projection layer:非线性网络g(·)(也称为投影头网络)的容量也增加了,通过增加其深度。此外,与SimCLR中完全丢弃g(·)不同,作者在预训练后从中间层开始微调。这一小改动对于线性评估和仅使用少量标注样本进行的微调都有显著改进。
- Memory Bank:作者还引入了MoCo中的内存机制,即设置一个内存网络(使用权重的移动平均值来稳定模型),其输出将作为负样本进行缓存。然而,这一增加对线性评估性能的提升不大(约1%)。
主要结果
- 更大的自监督模型更节省标签:实验证据表明,在通过利用不依赖特定任务的未标注数据进行半监督学习中,标签越少,越有可能从更大的模型中获益。更大的自监督模型更节省标签,在仅用少量标注样本进行微调时表现更好,尽管它们有可能过拟合。
- 多余的容量不一定必要:虽然大模型对于学习通用(视觉)表示很重要,但在特定任务上使用未标注数据时,多余的容量可能并不必要。因此,通过特定任务上的未标注数据使用,模型的预测性能可以进一步提高并转移到更小的网络中。
- 更大的/更深的投影头改善表示学习:更深的投影头不仅提高了线性评估中的表示质量,而且在从投影头的中间层进行微调时,也提高了半监督性能。
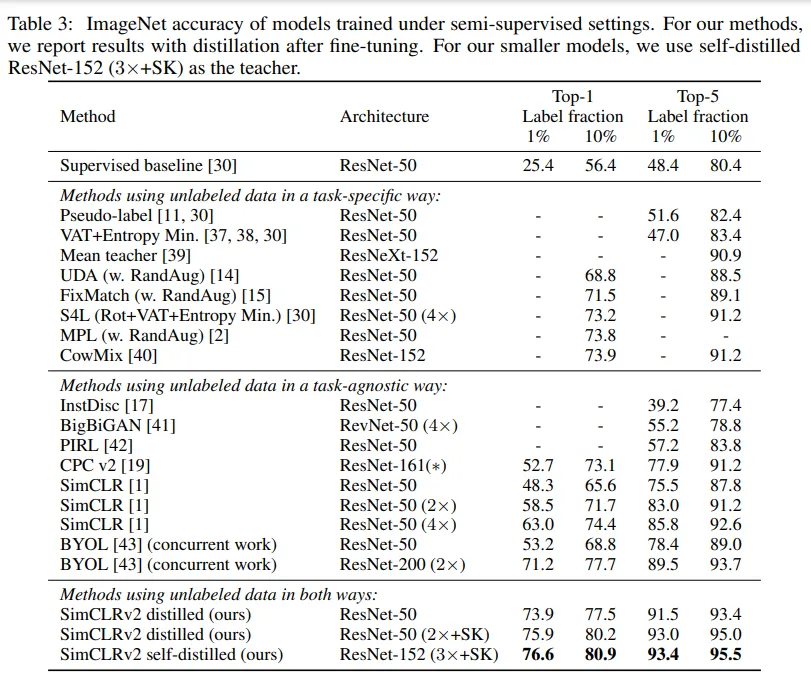
- 使用未标注数据的蒸馏改进半监督学习:使用未标注示例的蒸馏从两个方面改善了微调模型:(1) 当学生模型的架构比教师模型更小时,通过将特定任务的知识传递给学生模型,从而提高了模型效率,(2) 即使学生模型的架构与教师模型相同(排除ResNet编码器后的投影头),自蒸馏仍然可以显著提高半监督学习性能。为了获得更小的ResNet的最佳性能,大的模型会先进行自蒸馏,然后再蒸馏到更小的模型中,从而在半监督学习性能上获得显著提升。
实验的发现
一些GitHub开源项目的实现示例:
张量流:
-
https://github.com/google-research/simclr (谷歌研究的SimCLR仓库)
- https://github.com/manmeet3/Medical-SSL-SimCLRv2 (manmeet3的医学SimCLRv2仓库)
第二点:Keras
链接如下:https://github.com/travishsu/keras-simCLRv2
3. PyTorch:
- https://github.com/kaipak/SimCLRv2-PyTorch (基于PyTorch的SimCLRv2实现)
- https://github.com/qnguyen3/simclr_v2 (SimCLRv2的实现)
请在评论中指出,如果读者认为遗漏了任何要点。





