
Deepseek的新多头潜在注意力与MHA(多头注意力)、MQA和GQA的对比分析。

在Transformer解码器中,每个标记的注意力都依赖于前面的标记,所以无需重新计算之前的上下文,而是将前面标记的Keys和Values缓存起来。这可以显著加快推理的速度,但随着序列长度和模型的维度的增长,可能会带来昂贵的内存开销。
在这个背景下,已经引入了多种注意力机制:
- 多头注意力机制
- 多查询注意力机制
- 分组查询注意力机制
- 多头潜在注意力机制
MHA机制为每个注意力头分别计算查询、键和值矩阵。
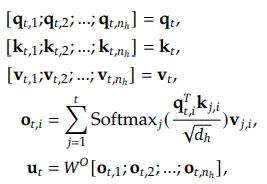
其中 O_ti 是第 i 个注意力头的输出。在推理阶段,所有键值都被缓存以加速推理,但这种大量的 KV 缓存是一个主要瓶颈,可能限制最大的序列长度和批量大小。
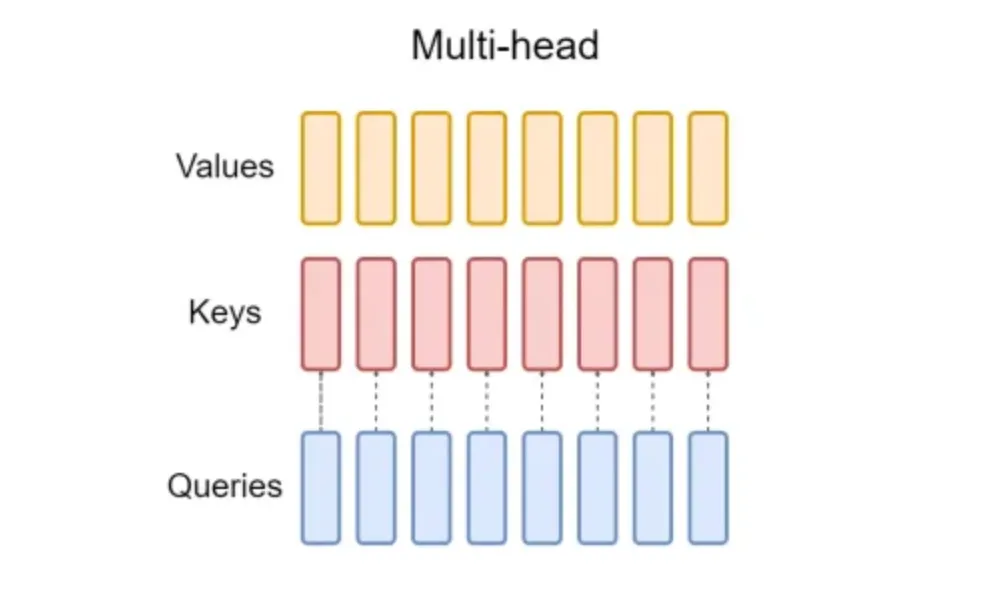
为了减少MHA中的KV缓存瓶颈,Shazeer, 2019 引入了多查询注意力机制(MQA),其中keys和values在所有注意力头之间共享,也就是说,不同头之间共享一组keys和values,与MHA相比,唯一的区别在于这一点。这需要轻量级的KV缓存,从而极大地加快了解码器的推断速度。然而,MQA会导致质量下降和训练不稳定。
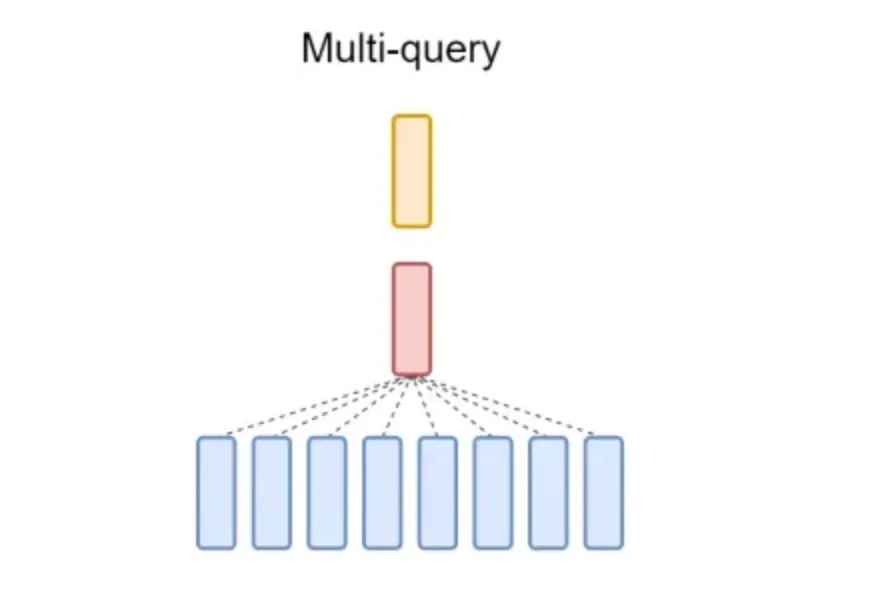
组查询注意力(GQA)是在MHA和MQA之间的一种插值方式,通过引入少于注意力头总数的若干查询头子组,并且每个子组只有一个键头和一个值头。与MQA不同,GQA在模型大小增加时保持了相同的内存带宽和容量的等比例降低。适当的子组数量可以生成一个比MQA质量更高但比MHA更快的插值模型。很明显,当GQA只有一个子组时,它等同于MQA。
这个 Attention 类动态地实现了三种注意力机制,也就是说,如下基于 self.num_kv_heads 和 self.num_heads。
self.num_kv_heads = 0会实现MHAself.num_kv_heads = 4会实现GQAself.num_kv_heads = 8会实现MQA
class Attention(nn.Module):
def __init__(self, model_args: MOEConfig):
super().__init__()
d_model = model_args.d_model
self.num_heads = model_args.num_heads
self.head_dim = model_args.d_model // model_args.num_heads
self.num_kv_heads = (
model_args.num_heads if model_args.num_kv_heads == 0 else model_args.num_kv_heads
)
assert self.num_heads % self.num_kv_heads == 0
self.num_queries_per_kv = self.num_heads // self.num_kv_heads
self.key = nn.Linear(d_model, self.head_dim * self.num_heads)
self.query = nn.Linear(d_model, self.head_dim * self.num_kv_heads)
self.value = nn.Linear(d_model, self.head_dim * self.num_kv_heads)
self.proj = nn.Linear(d_model, d_model, model_args.bias)
self.attn_dropout = nn.Dropout(model_args.dropout)
self.res_dropout = nn.Dropout(model_args.dropout)
self.flash_attn = hasattr(torch.nn.functional, "scaled_dot_product_attention")
def forward(self, x: torch.Tensor, mask: torch.Tensor, freqs_cis) -> torch.Tensor:
batch, seq_len, d_model = x.shape
k: torch.Tensor # 类型提示,用于lsp
q: torch.Tensor # 忽略类型提示
v: torch.Tensor
k = self.key(x)
q = self.query(x)
v = self.value(x)
k = k.view(
batch, seq_len, -1, self.head_dim
) # 形状为 (B, seq_len, num_heads, head_dim)
q = q.view(batch, seq_len, -1, self.head_dim)
v = v.view(batch, seq_len, -1, self.head_dim)
print(q.shape)
print(k.shape)
q, k = apply_rope(q, k, freqs_cis)
# 分组查询注意力机制
if self.num_kv_heads != self.num_heads:
k = torch.repeat_interleave(k, self.num_queries_per_kv, dim=2)
v = torch.repeat_interleave(v, self.num_queries_per_kv, dim=2)
k = k.transpose(1, 2) # 形状为 (B, num_heads, seq_len, head_dim)
q = q.transpose(1, 2)
v = v.transpose(1, 2)
print("q.shape", q.shape)
print("k.shape", k.shape)
output = F.scaled_dot_product_attention(
q,
k,
v, # 顺序很重要
attn_mask=None,
dropout_p=self.attn_dropout.p if self.training else 0.0,
is_causal=True,
)
# else:
# attn_mtx = torch.matmul(q, k.transpose(2, 3)) / math.sqrt(self.head_dim)
# attn_mtx = attn_mtx + mask[:, :, :seq_len, :seq_len]
# attn_mtx = F.softmax(attn_mtx.float(), dim=-1).type_as(k)
# attn_mtx = self.attn_dropout(attn_mtx)
# output = torch.matmul(attn_mtx, v) # (batch, n_head, seq_len, head_dim)
# 恢复时间维度为批量维度并合并头
print("v.shape", v.shape)
print("output.shape", output.shape)
output = output.transpose(1, 2).contiguous().view(batch, seq_len, d_model)
# 最终投影到残差流
output = self.proj(output)
output = self.res_dropout(output)
return output多头隐式注意力(MLA)性能优于MHA,并且显著减少了KV缓存,从而提高了推理效率。不同于MQA和GQA减少KV头的做法,MLA将Key和Value共同压缩成一个隐式向量。
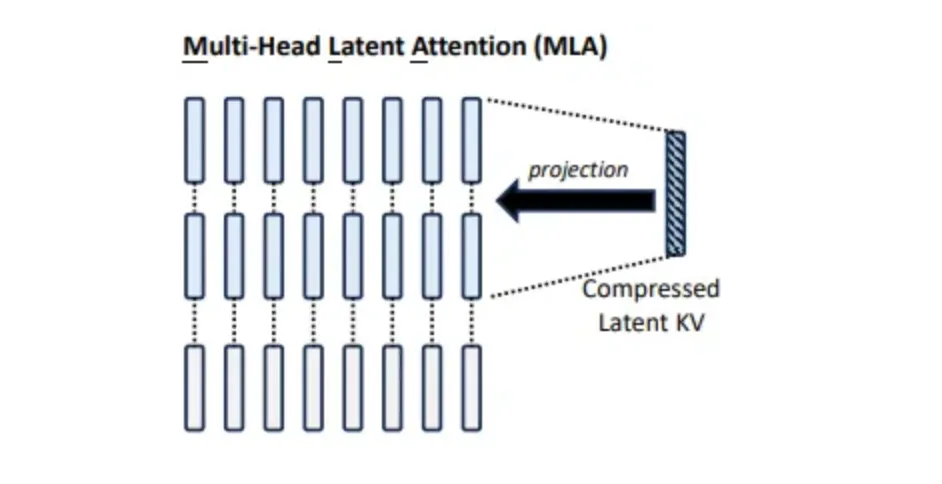
вместо кэширования матриц Key和Value,MLA将其共同压缩为低秩的向量,这使得可以缓存更少的条目,因为压缩后的维度远小于MHA输出投影矩阵的维度。
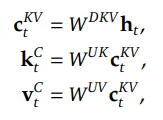
以下 Attention 类实现了 MLA 功能。
class Attention(nn.Module):
def __init__(self, model_args: MOEConfig):
super().__init__()
d_model = model_args.d_model
self.num_heads = model_args.num_heads
self.head_dim = model_args.d_model // model_args.num_heads
self.attn_dropout = nn.Dropout(model_args.dropout)
self.res_dropout = nn.Dropout(model_args.dropout)
self.flash_attn = hasattr(torch.nn.functional, "scaled_dot_product_attention")
self.q_lora_rank = model_args.q_lora_rank
self.qk_rope_head_dim = model_args.qk_rope_head_dim
self.kv_lora_rank = model_args.kv_lora_rank
self.v_head_dim = model_args.v_head_dim
self.qk_nope_head_dim = model_args.qk_nope_head_dim
self.q_head_dim = model_args.qk_nope_head_dim + model_args.qk_rope_head_dim
self.q_a_proj = nn.Linear(d_model, model_args.q_lora_rank, bias=False)
self.q_a_layernorm = RMSNorm(model_args.q_lora_rank)
self.q_b_proj = nn.Linear(model_args.q_lora_rank, self.num_heads * self.q_head_dim, bias=False)
self.kv_a_proj_with_mqa = nn.Linear(d_model,model_args.kv_lora_rank + model_args.qk_rope_head_dim,bias=False,)
self.kv_a_layernorm = RMSNorm(model_args.kv_lora_rank)
self.kv_b_proj = nn.Linear(model_args.kv_lora_rank,self.num_heads * (self.q_head_dim - self.qk_rope_head_dim +
self.v_head_dim),bias=False,)
self.o_proj = nn.Linear(self.num_heads * self.v_head_dim,d_model, bias=False,)
def forward(self, x: torch.Tensor, mask: torch.Tensor, freqs_cis) -> torch.Tensor:
batch, seq_len, d_model = x.shape
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(x)))
q = q.view(batch, seq_len, self.num_heads, self.q_head_dim).transpose(1, 2)
q_nope, q_pe = torch.split(q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1)
compressed_kv = self.kv_a_proj_with_mqa(x)
compressed_kv, k_pe = torch.split(compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1)
k_pe = k_pe.view(batch, seq_len, 1, self.qk_rope_head_dim).transpose(1, 2)
kv = (self.kv_b_proj(self.kv_a_layernorm(compressed_kv))
.view(batch, seq_len, self.num_heads, self.qk_nope_head_dim + self.v_head_dim)
.transpose(1, 2))
k_nope, value_states = torch.split(kv, [self.qk_nope_head_dim, self.v_head_dim], dim=-1)
kv_seq_len = value_states.shape[-2]
q_pe, k_pe = apply_rope(q_pe, k_pe, freqs_cis)
k_pe = k_pe.transpose(2, 1)
q_pe = q_pe.transpose(2, 1)
query_states = k_pe.new_empty(batch, self.num_heads, seq_len, self.q_head_dim)
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
key_states = k_pe.new_empty(batch, self.num_heads, seq_len, self.q_head_dim)
key_states[:, :, :, : self.qk_nope_head_dim] = k_nope
key_states[:, :, :, self.qk_nope_head_dim :] = k_pe
attn_mtx = torch.matmul(query_states, key_states.transpose(2, 3)) / math.sqrt(self.head_dim)
attn_mtx = attn_mtx + mask[:, :, :seq_len, :seq_len]
attn_mtx = F.softmax(attn_mtx.float(), dim=-1).type_as(key_states)
attn_mtx = self.attn_dropout(attn_mtx)
output = torch.matmul(attn_mtx, value_states) # (batch, n_head, seq_len, head_dim)
output = output.transpose(1, 2).contiguous().view(batch, seq_len, self.num_heads * self.v_head_dim)
# 最终投影到残差流
output = self.o_proj(output)
output = self.res_dropout(output)
return output关于MLA实现细节的一些笔记:


MHA 在推理时可能更快,但其 KV 缓存的开销使得 MHA 难以扩展到更大规模的模型。MQA 显著减少了 KV 缓存,但随着模型规模的扩大,其输出质量会下降。GQA 在 KV 缓存和内存带宽方面介于 MHA 和 MQA 之间。MLA 需要的 KV 缓存显著较少,但在输出质量上却优于 MHA。
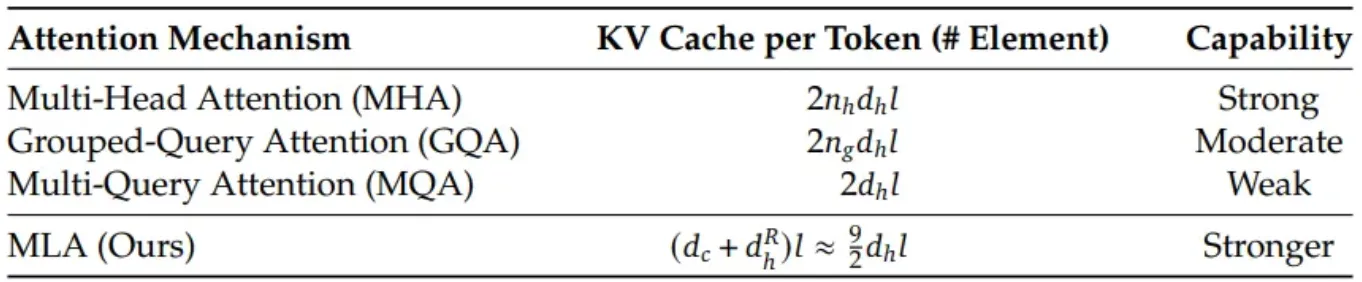
其中 _nh 是头数,_dh 是每个头的维度,l 是层数,_ng 是 GQA 中的子组数,_dc 是压缩维度数。
特别感谢QueryLoopAI支持这些实验的计算。
也可以随时给我发消息或留言至12345678@qq.com:
- 在LinkedIn上联系和关注我 LinkedIn 和 Twitter
- 关注我在 📚 Medium 的内容
- 订阅我的 📢 每周 AI newsletter 吧!
- 查看我在 🤗 Hugging Face 的作品或项目


