
具有混合搜索功能的搜索栏
最近,随着检索增强生成(RAG)管道的兴趣增加,开发人员已经开始讨论构建具有生产就绪性能的RAG管道时遇到的挑战。就像在生活中许多方面一样,帕累托原则在RAG管道中同样适用:达到最初的80%是比较容易的,但要达到剩下的20%,以实现生产就绪,却颇具挑战。
一个常见的主题是通过混合搜索来提升RAG管道中的检索部分。
已经有经验构建RAG流程的开发人员已经开始分享他们的经验(详情请参阅https://medium.com/towards-data-science/the-untold-side-of-rag-addressing-its-challenges-in-domain-specific-searches-808956e3ecc8)。一个常见的点是通过混合搜索来优化RAG流程中的检索部分。
这篇文章介绍了混合搜索是什么,说明了它如何帮助你通过检索更多相关结果来提升RAG流程的性能,以及何时应该使用它。
- 什么是混合搜索
- 混合搜索的工作原理是什么?
- 混合搜索如何提高你的RAG管道性能?
- 什么时候适合使用混合搜索?
- 总结
混合搜索是一种结合两种或多种搜索算法来提升搜索结果相关性的搜索技术。虽然并没有具体说明会使用哪些算法,但混合搜索通常指的是传统的基于关键词的搜索与现代向量搜索技术相结合。
传统上,基于关键词的搜索是搜索引擎的显而易见的选择之一。但随着机器学习(ML)算法的兴起,向量嵌入使我们能够采用一种新的搜索技术——称为向量或语义搜索,这种技术允许我们以语义的方式在数据中进行搜索。然而,这两种搜索技术都有需要权衡的重要考量。
- 基于关键词的搜索: 尽管其精确的关键词匹配功能对于特定术语(如产品名称或行业术语)非常有益,但对拼写错误和同义词的敏感性会导致它错过重要的上下文信息。
- 基于向量或语义的搜索: 尽管其语义搜索功能允许基于数据语义的跨语言和跨模态搜索,并且对拼写错误具有鲁棒性,从而能够更好地处理数据,但它可能会错过重要的关键词或短语。此外,它依赖于生成的向量嵌入的质量,并且对领域外的术语很敏感,需要依赖高质量的向量嵌入。
将关键词搜索和向量搜索结合成一种混合搜索,可以让你利用这两种搜索技术的优势来提升搜索结果的相关性,特别是在文本搜索中。
例如,搜索查询“如何使用.concat()合并两个Pandas DataFrame?”。关键词搜索可以帮助找到关于.concat()方法的相关结果。然而,由于“合并”有同义词,比如“结合”,“连接”,“串联”等,如果能利用语义搜索的上下文理解,将会非常有用。
有兴趣的话,你可以尝试使用不同的关键词、语义以及混合搜索查询来搜索这个实时演示(有关实现的详细说明请参阅这篇文章)。
混合搜索是怎么工作的?混合搜索技术将基于关键词和向量搜索的技术结合起来,通过融合它们的搜索结果并重新排序。
关键词搜索在混合搜索的环境中,关键词搜索通常使用一种称为稀疏表示的表示方法,这也是为什么它也被称为稀疏向量搜索。稀疏表示是向量大多数位置的值为零,只有少数位置的值不为零。
[0, 0, 0, 0, 0, 1, 0, 0, 0, 24, 3, 0, 0, 0, 0, ...]这段代码表示一个数字序列,其中包含了一些特定的数值。例如,可以看到第六个位置的值为1,第十个位置的值为24,第十一个位置的值为3。这样的序列通常在编程或数据分析中用来表示某些特定的状态或数据点。
稀疏嵌入可以通过多种算法生成。通常最常用的稀疏嵌入算法是BM25,它在TF-IDF(词频-逆文档频率)基础上进行了改进。简单来说,BM25 通过分析词语在文档中的出现频率以及在整个文档集中的出现频率来突出其重要性。
基于向量的搜索向量搜索是一种随着机器学习的进步而出现的现代搜索技术。现代机器学习算法,如Transformers,可以生成各种形式(如文本、图像等)的数据对象的表示,称为向量嵌入。
这些向量嵌入通常包含大量信息,并主要包含非零值(稠密向量),如下面的例子所示。因此,向量搜索也被称为稠密向量搜索。
[0.634, 0.234, 0.867, 0.042, 0.249, 0.093, 0.029, 0.123, 0.234, ...]搜索查询被嵌入到与数据对象相同的向量空间里。然后,利用其向量嵌入根据指定的相似度指标(如余弦相似度)计算出与查询最相似的数据对象。返回的搜索结果按与查询的相似度进行排序并列出最接近的数据。
关键词搜索和向量搜索结果的融合基于关键词的搜索和向量搜索都会各自返回一组独立的结果,通常会根据计算的相关性对搜索结果进行排序,形成列表。这些独立的结果集必须合并在一起。
有许多种不同的方法可以将两个列表的排序后的结果合并成一个单一的排名,如Benham和Culpepper([1])在他们的一篇文章中提到的。
一般来说,搜索结果通常会先进行打分。这些打分可以依据某个指定的指标,比如余弦相似度,或者仅仅是它们在搜索结果中的位置。
接着,计算出的分数会用参数 alpha 加权,该参数决定了每个算法的权重,并影响结果的重新排序。
混合分数 = (1 - α) × 稀疏分数 + α × 密集分数通常,alpha 的值在 0 和 1 之间。
alpha = 1:纯向量;alpha = 0:纯关键词
以下是一个最小示例,展示了关键词搜索和向量搜索的融合,以及基于排名评分的 alpha = 0.5 的评分权重。
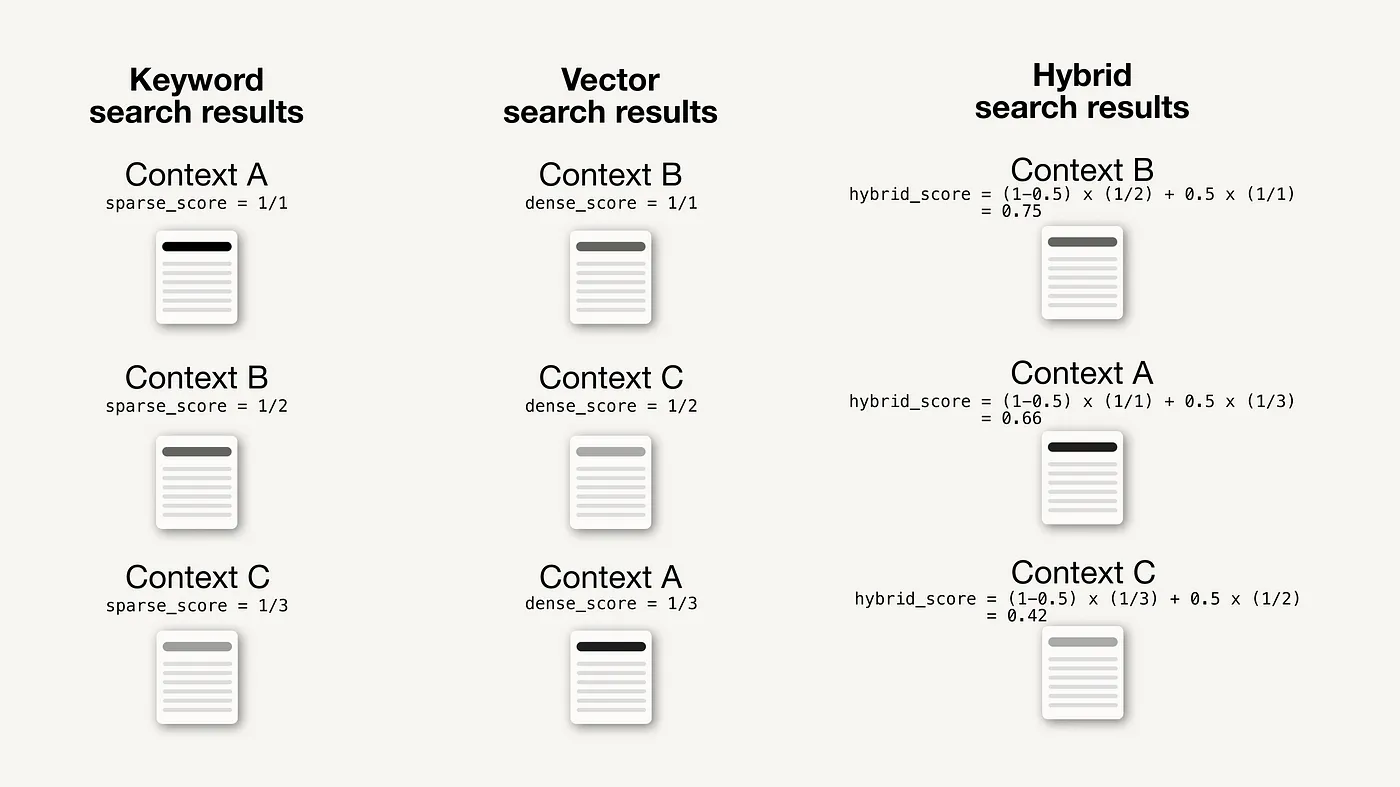
一个基于排名和alpha为0.5的评分的混合搜索中,关键词和向量搜索结果如何结合的最简单例子。(作者的图片,灵感来自混合搜索的解释)
混合搜索如何提高你RAG系统的性能呢?
RAG管道有许多可以调整的参数来提升其性能表现。其中一个参数是提高检索上下文的相关性,因为如果检索到的上下文与某个问题无关,LLM也无法给出相关的回答。
根据您的上下文类型和查询,您需要确定哪种搜索技术对您的RAG应用程序最有益。因此,参数alpha,控制关键词搜索和语义搜索之间的权重,可以被视为一个需要调优的超参数。
在常见的使用LangChain的RAG管道中,定义检索器组件时,会将所使用的vectorstore组件设置为检索器,方法是调用.as_retriever(),如下所示:
# 定义并向向量存储中填充数据
# 详情请参阅此处 https://towardsdatascience.com/retrieval-augmented-generation-rag-from-theory-to-langchain-implementation-4e9bd5f6a4f2
vectorstore = ...
# 将向量存储用作检索器
retriever = vectorstore.as_retriever()然而,这种方法仅支持语义搜索功能。如果你想在LangChain中启用混合搜索功能,你需要定义一个具有混合搜索功能的retriever。例如,可以使用[WeaviateHybridSearchRetriever](https://python.langchain.com/docs/integrations/retrievers)这样的retriever来实现这个功能。
from langchain.retrievers.weaviate_hybrid_search import WeaviateHybridSearchRetriever
retriever = WeaviateHybridSearchRetriever(
alpha = 0.5, # 默认为 0.5,表示关键词搜索和语义搜索的权重相同
client = client, # 传递给 Weaviate 客户端的参数值
index_name = "LangChain", # 索引名称为
text_key = "text", # 文本键为
attributes = [], # 要返回的属性
)其余的标准 RAG pipeline 会保持原样。
这个小的代码变更让你可以试验关键词搜索和向量搜索之间的不同权重。请注意,设置 alpha = 1 等同于完全的语义检索,这相当于直接从 vectorstore 定义检索器 (retriever = vectorstore.as_retriever())。
混合搜索非常适合于需要想要启用语义搜索功能以提供更接近人类的搜索体验,但同时还需要对特定术语(如产品名称或序列号)进行精确短语搜索的用例。
一个很好的例子是平台Stack Overflow,它最近通过结合语义搜索和混合型搜索,增强了其搜索功能。
[像人一样提问:实现 Stack Overflow 的语义搜索语义搜索允许用户用自然语言搜索,而不是通过复杂的关键词语法。](https://stackoverflow.blog/2023/07/31/ask-like-a-human-implementing-semantic-search-on-stack-overflow/?source=post_page-----c75203c2f2f5--------------------------------)
最初,Stack Overflow 使用 TF-IDF 算法来匹配关键词和文档 [2]。然而,描述你试图解决的编程问题可能很困难,这可能导致不同的搜索结果。你用来描述问题的词语可能会导致不同的搜索结果(例如,结合两个 Pandas DataFrame 可以通过合并、连接或拼接等多种方式实现)。因此,对于这种情况下,使用更了解上下文的搜索方法,如语义搜索,会更加有益。
然而,另一方面是,Stack Overflow 的一个常见用例是复制粘贴错误信息。对于这种情况,精确的关键词搜索是首选的方法。此外,你也需要精确的关键词匹配功能来匹配方法和参数名(比如,Pandas 中的 .read_csv())。
正如你可能猜到的,许多类似的现实应用场景可以从基于上下文的语义搜索中获益,但仍依赖于严格的关键词匹配。这些场景可以通过引入混合搜索组件来显著受益。
摘要这篇文章介绍了混合搜索作为一种结合了关键词和向量搜索的方法。混合搜索将各个独立的搜索算法的结果合并后,根据相关性重新排序搜索结果。
在混合搜索里,参数 alpha 控制基于关键词搜索和语义检索之间的权重比例。此参数 alpha 可被视为 RAG 流程中的一个超参数,用于调整以优化搜索结果的准确性。
通过Stack Overflow [2] 的案例研究,我们展示了在语义搜索能提升搜索体验的场景下,混合搜索是非常有用的。然而,当某些特定术语很常见时,精确的关键词匹配仍然必不可少。
瑞典你享受这个故事吗?点击这里免费订阅 以便在有新文章时收到通知.
每当 Leonie Monigatti 发布新内容时,你都会收到邮件通知。通过订阅,你将自动创建一个 Medium 账号(如果你还没有的话)……medium.com可以在我LinkedIn,Twitter和Kaggle找我!
注意: 声明一下
我目前在 Weaviate 担任开发者支持专员,Weaviate 是一个开源的向量数据库项目。说这番话的时候。
参考文献
文学这块[1] Benham R., Culpepper J. S. (2017) 在《2017年第22届澳大利亚和新西兰文档计算研讨会论文集》中发表的《等级融合中的风险与收益权衡》(第1-8页).
[2] Haney, D. & Gibson, D. 在 Stack Overflow 博客上。像人一样提问:在 Stack Overflow 上实现语义搜索 (访问日期:2023 年 11 月 24 日)。
图片如果没有特别说明,所有图片均由作者制作。





