
在 Netflix,我们使用亚马逊网络服务(AWS)来满足我们的云基础设施需求,比如计算、存储和网络服务。我们的生态系统使工程团队能够运行应用程序和服务,利用开源和专有技术的混合解决方案。反过来,我们的自助服务平台允许团队更高效地创建和部署工作负载,有时是定制的工作负载。这种多样化的技术环境生成了大量丰富数据,这些数据来自各种基础设施实体。数据工程师和分析师合作提供可行的洞察给工程组织,形成一个持续的反馈循环,从而最终提升业务表现。
我们通过使精心筛选的数据来源更加民主化来做到这一点,这些数据来源透明地展示了Netflix各项服务和团队中的使用情况和成本模式。数据与洞察团队与我们的工程团队紧密合作,分享关键的效率指标信息,帮助内部人员做出明智的商业决策。
数据至关重要这里是我们DSE(数据科学工程)团队的作用,帮助我们的工程合作伙伴了解正在使用的资源,他们如何有效使用这些资源,以及这些资源使用的成本。我们希望下游用户在使用我们的数据集时能够做出有成本意识的决策。
为了以灵活扩展的方式解决这些各种各样的分析需求,我们开发了一套两组件的解决方案。
- 基础平台数据(FPD),:此组件提供了一个一致的数据模型和标准化的数据处理方法的集中式平台数据层。
- 云效率分析(CEA),:基于FPD构建,此组件提供了数据分析层,提供跨各种业务用例的时间序列效率数据。

基础平台数据(FPD),其中FPD代表“基础平台数据”
我们与不同的平台数据提供商合作以获取各个平台的 库存 , 所有权 和 使用情况 数据。以下是此框架在 Apache Spark 平台上的应用示例。FPD 与生产者建立 数据协议(数据合同),以确保数据的质量和可靠性;这些 数据协议 使团队能够利用共同的数据模型,以处理 所有权 数据。标准化的数据模型和处理流程促进了系统的可扩展性和一致性。

云效能分析(CEA 数据集)
一旦基础数据准备就绪,CEA 就会利用库存、所有权和使用数据,并应用适当的业务规则来生成不同层次的“成本”和“所有权归属”。CEA 的数据模型方法是将数据模块化并保持透明;我们希望下游用户能够理解为什么某些资源会出现在他们的名字或组织名下,以及这些成本是如何计算出来的。这种方法的另一个好处是,当新的或更改的业务逻辑被引入时,能够快速调整适应。
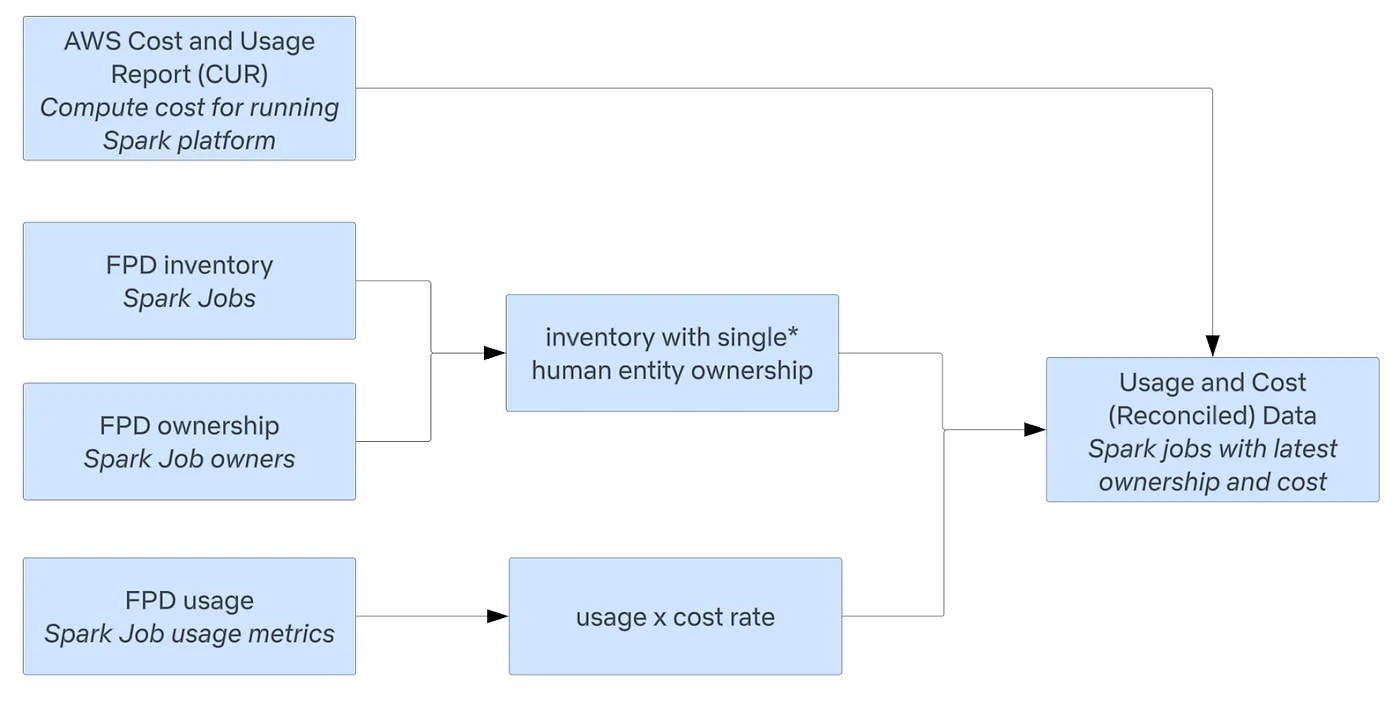
- 为了成本核算的需要,我们将资产指定给单一所有者,或者当资产为多租户时分摊成本。然而,我们也为不同的用户提供不同级别的使用量和成本聚合数据。
作为效率指标的权威来源,我们团队的原则是提供准确、可靠且易于获取的数据,并通过详尽的文档帮助理解效率领域的复杂性。我们还通过明确定义的服务级别协议(SLAs)在延迟、停机或变更期间,与下游使用者设定预期。
尽管所有权和成本似乎清晰明了,由于业务基础设施和平台特定功能的广度和范围,数据集的复杂性相当高。服务可能被多个所有者拥有,每个平台的成本估算方法都不相同,基础设施数据的规模也非常庞大。随着我们将基础设施扩展到业务的所有垂直领域,我们面临着一系列独特的挑战:
适合大多数人的几个尺码
尽管存在数据合同和将上游平台数据转换为FPD和CEA的标准数据模型,通常仍会有一些特定平台独有的定制需求。“作为单一事实来源”,我们总是在处理负担放在何处的问题上感到压力重重。决策过程包括与数据生产者和消费者进行持续透明的对话,频繁的优先级检查,以及作为该领域的知情人士,我们努力确保与业务需求保持一致。
数据保障
为了确保数据的准确性和可靠性,我们每个层级都需要进行审计,并且能看到健康指标,以便快速查明问题并找到异常的根本原因。由于上游延迟和所需的数据转换,使得数据准备好被使用变得具有挑战性。保持数据的完整性和正确性变得更具挑战性。我们不断迭代审计并整合反馈,以优化并满足我们的服务水平协议(SLA)。
抽象层次
我们重视[人而非流程],请参阅文化页面了解更多信息。工程团队为公司其他部门创建定制的SaaS解决方案是很常见的事。虽然这能促进创新并加快开发速度,但在理解使用模式并根据业务和最终用户的需求合理分配成本方面可能会遇到一些麻烦。通过FPD提供的清晰的库存、所有权和使用数据,以及分析层中的精准归因,我们希望无论用户是否使用内部平台或直接使用AWS资源,都能为他们提供衡量指标。
展望未来展望未来,我们旨在继续引入平台到FPD和CEA,力求在接下来的一年内实现接近完整的成本洞察覆盖。从长远来看,我们打算将FPD的应用范围扩展到业务的其他领域,比如安全和可用性。我们将通过预测分析和机器学习等技术,朝着主动优化使用情况并识别成本异常的方向迈进。
我们希望最终,我们的目标是让工程团队在构建和维护众多支持我们享受Netflix流媒体服务的服务时,能够做出效率优先的决策。
致谢词没有这些出色的同事跨职能的贡献和我们团队的辛勤工作,FPD和CEA的数据资产是不可能构建完成的。
—
关于作者们的介绍:
JHan喜欢大自然,阅读奇幻小说,并寻找最好吃的巧克力芯片饼干和肉桂面包卷。她在SQL选择语句前加逗号。
帕拉维喜欢音乐、旅行,还喜欢看天体物理学的纪录片。她在数据工作领域有超过15年的经验,觉得一点点数据分析加上一杯咖啡会让一切变得更好!




