

感谢Luis Tosta拍摄的照片,来自Unsplash
自2022年底ChatGPT出现以来,我们已经进入了生成式AI的时代,而“LLMs”这一概念已成为大家生活中不可或缺的一部分。
不过最近,你可能也听说了,一些“科技大佬”提到大规模语言模型的增长似乎已经放缓。
那么,接下来呢?Meta公司有答案了
最近,Meta 推出了大型概念模型(LCMs),这可能是下一步的重大飞跃,对大型语言模型(LLMs)进行了一次重要更新。
订阅 Gumroad 上的 datasciencepocket,致力于让每个人都能学习 AI! 访问 datasciencepocket.gumroad.com 大规模概念模型Meta的大规模概念模型(LCMs)代表了一种新的语言建模方法,它在更高层次的抽象层面上进行操作,与传统的大型语言模型(LLMs)相比。
相比起在词元级处理文本,LCM 以 概念 为基础进行工作,这些概念不依赖于特定的语言或模态,而是表示高层次的想法或动作。
在 Meta 的 LCM 框架中,概念 被定义为一个抽象的基本概念。实践中,一个概念通常对应于文本中的一个句子或等同的语音表述。这使模型能够在更高的语义层面上进行推理,独立于特定的语言或模态(例如,文本、语音或图像)。
这什么意思啊?咱们来看一个例子
传统的语言模型(LLMs):逐词预测想象你在写一个故事,使用的是传统类型的语言模型,比如ChatGPT。它的工作原理是根据你已输入的词语来预测下一个词语。比如说:
它的工作原理是根据你已输入的词语来预测下一个词语。
你写的是:“猫坐在……”
模型接着说:垫子上。
这种方法虽然有效,但非常专注在单个词语上,却未必会考虑到整个句子的意思或更宏观的语境。
Meta的大型概念模型(LCMs,即Large Concept Models):逐字想法预测现在想象一下,模型不是预测下一个单词,而是预测下一个念头或概念。一个概念是一个完整的句子或想法,而不仅仅是一个单词。例如
你写道:“猫坐在垫子上。”那是一个晴朗的日子。突然……发生了什么?
模型接着预测到:“厨房里突然传来了一个巨大的声响。”
这里,模型不只是猜下一个词,而是在思考接下来整个想法。它像是在构思故事的下一个部分,而不是一个词一个词地考虑。
这也真是疯了!
这酷在哪里?语言无关:
模型不在乎输入是英语、法语还是其他任何语言,它只关注句子的意思,而不是具体的单词。例如
英语:猫饿了。
法语:Le chat a faim.
- 两句意思相同,所以模型会将它们视为同一个概念。
多模态的(如文本、语音等):
该模型也可以处理语音或甚至图像。例如:
如果你说“猫饿了”,或者展示一张饥饿的猫咪的照片,模型理解的是同样的意思:“猫咪需要吃东西。”
更适合写长文章:
建筑设计在写长篇故事或文章时,模型可以规划想法的流动,而不是不必纠结于单个词语。例如:
如果你在写一篇研究论文,模型可以帮助你列出主要论点(概念),然后再进行扩展。
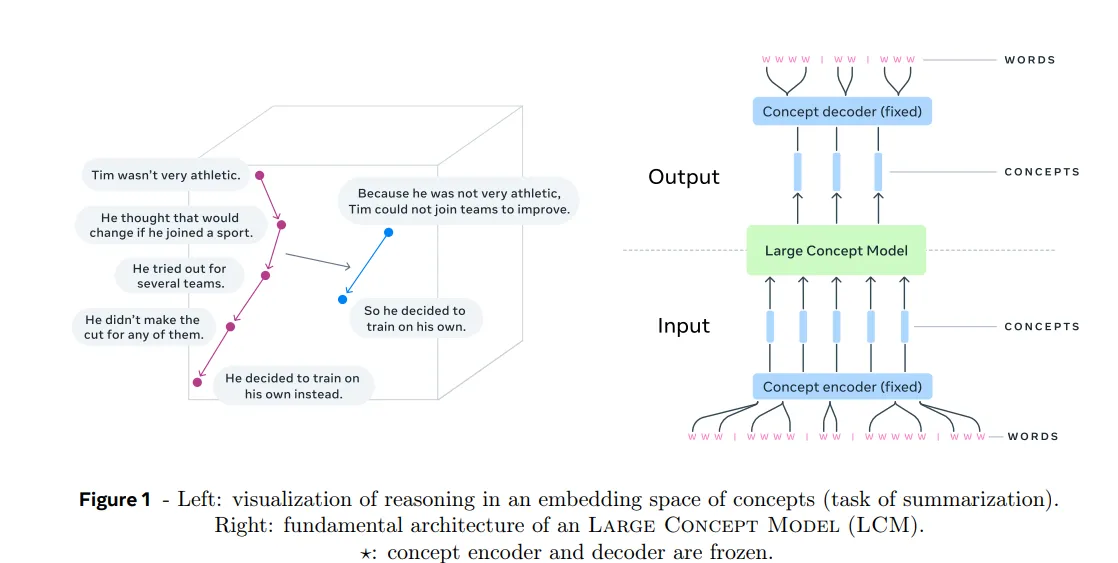
输入处理:
- 输入文本首先被分割成句子,每个句子使用预训练的句子编码器(例如,SONAR)编码为一个固定大小的向量。SONAR 支持多达200种语言,能够处理文本和语音输入。
- 这些嵌入表示输入文本中的概念。
大概念模型(LCM):
- LCM处理概念嵌入序列,并进行自回归预测以预测序列中的下一个概念。该模型经过训练能够进行自回归预测。
- LCM的输出为一系列概念嵌入,这些嵌入序列可以通过SONAR解码器转换回文本或语音。
生成:
- 生成的概念嵌入被解码为文本或语音,产生最终输出结果。由于LCM在概念层面上操作,相同的推理过程可以适用于不同的语言或模态,而无需重新训练。
- LCM支持零样本学习,意味着它可以应用于它未明确训练的语言或模态,只要SONAR编码器和解码器支持这些语言或模态即可。
这里有几个重要的地方需要注意一下:
声纳嵌入空间技术 :
SONAR 是一个多语言多模态的句子嵌入空间,支持 200 种语言的文本和 76 种语言的语音功能。
SONAR 的嵌入是固定长度的向量,能够捕捉句子的语义信息,使其适合进行概念层面的推理分析。
基于扩散模型和量化生成模型:
LCM 和 LLMs 1. 抽象级别Meta 探索了多种方法来训练 LCM,包括 基于扩散的生成。扩散模型用于通过学习连续嵌入空间的条件概率分布来预测下一个概念嵌入。
另一种方法是这样的,将 SONAR 嵌入离散化,并训练 LCM 来预测下一个量化概念。这样的方法可以实现更可控的生成和采样,就像大语言模型从词汇表中采样 token 一样。
- LLM :在词元层面工作,预测序列中的下一个词或次词。
- LCM :在概念层面工作,预测序列中的下一个句子或概念。
- LLM:处理特定语言中的单个词元(单词或子词)。
- LCM:处理句子的嵌入(概念),这些嵌入不依赖于语言和模态。
- LLM :逐字生成文本内容,更加注重局部连贯性。
- LCM :逐句生成文本内容,更加注重全局连贯性和高层次逻辑。
- LLM:通常是为了特定语言和模态(如文本)而训练的。不过,多模态的LLM也可以支持多种模态。
- LCM:设计为通过共享的概念空间来处理多种语言和模态(如文本、语音、图像)。
- LLM:训练来最小化概念预测错误(例如,嵌入空间的均方误差)。
- LCM:训练来最小化概念预测错误(例如,嵌入空间的均方误差)。
-
LLM :隐式地学会了层次推理,但局部地(逐词地)操作。
- LCM :显式地构建层次推理,在句子或思想层面上做规划。
注:零样本推广可能不是通用术语,此处使用以更符合中文技术语境的表达。
- LLM:在没见过的语言或模态上,LLM 在处理 零样本任务 时会遇到麻烦。
- LCM:由于其基于概念的方法,LCM 在跨语言和模态的 零样本泛化 方面表现出色。
- LLM:由于注意力机制的二次复杂性,在处理长文本时会感到吃力。
- LCM:处理长文本时更高效,因为它处理的是句子嵌入序列(即较短的句子表示序列),这些序列比标记序列要短。
- LLM :最适合词级任务,如文本补全(completion)、翻译和问答(QA)。
- LCM :最适合句级任务,如摘要(summarization)、故事生成和多模态理解。
- LLM:仅限于文本相关任务,需要重新训练以支持新语言或模态。
- LCM:凭借其概念驱动的设计,能够灵活应对各种语言和模态,无需重新训练。
总之,Meta的大型概念模型(LCM)在语言建模方面取得了重大进展。通过在概念层面操作,LCMs提供了更抽象、语言无关且多模态的推理与生成方式。虽然大型语言模型(LLMs)在词对词的任务上表现出色,但LCMs在摘要生成、故事创作和跨模态理解等高层次应用中更加出色。随着AI的不断发展,LCMs有可能为更加直观、人性化的机器交互铺平道路,从教育到娱乐等各个行业都将因此发生变革。
AI的未来不仅关乎预测下一个词,更是理解下一个概念。





