

DALL-E,生成的图片
不久后,大型语言模型(LLM)流行起来,我们意识到它们在将自然语言翻译成如SQL和Cypher这样的数据库查询方面表现不错。为了让你的特定数据库定制查询,你需要提供该数据库的结构,以及可选的一些示例查询。有了这些信息,LLM就能根据自然语言生成相应的数据库查询。
虽然大语言模型在将自然语言转化为数据库查询方面展现出了巨大潜力,但它们仍然存在很多不足。因此,了解它们的表现如何,通过评估过程至关重要。幸运的是,生成SQL语句的过程已经在学术界得到了研究,如Spider等研究。我们将使用以下指标来评估这些模型生成Cypher的能力。
- Jaro-Winkler:这是一种基于编辑距离的文本相似度指标。我们将生成的Cypher查询与正确的Cypher查询进行比较,比较字符串之间的差异,即需要对一个查询进行多少编辑才能使它与另一个查询相同。
- Pass@1: 如果生成的查询从数据库返回的结果与正确的Cypher查询返回的结果相同,则该得分为1.0,否则得分为0.0。
- Pass@3: 与Pass@1类似,但生成3个查询而不是1个查询。如果有任何一个查询返回的结果与正确的查询相同,则得分为1.0,否则得分为0.0。
- Jaccard相似度: 它衡量生成的Cypher与正确Cypher返回的响应之间的Jaccard相似度。此度量用于捕捉模型可能返回接近正确结果的情况。
代码可在 GitHub 上获取,这是与 Adam Schill Collberg 合作开发的成果。
正如你所见,重点在于评估从数据库中获取的回复,而不是实际的Cypher语句本身。原因之一是,可以用多种方式编写Cypher语句来检索相同的信息。我们并不在意LLM偏好的语法风格;我们只关心它能否给出正确的回复。此外,我们对LLM在回复中命名列的方式也没有严格的规定,因此我们不想评估它的列命名能力等。
测试数据测试数据集包含问题与相应的Cypher语句,Cypher是一种特定的技术术语。
你可以使用大型语言模型(LLM,large language model的简称)来为测试数据集生成建议。但是,你需要手动验证这些例子,因为LLM会犯错,并且不是100%可靠。如果它们是可靠的,我们也就没有必要进行测试了。因为我们评估的是数据库的结果,而不是Cypher语句本身,所以需要有一个运行中的数据库,其中包含相关的信息。在这篇博客文章中,我们将使用Neo4j Sandbox中的推荐项目。推荐项目使用了MovieLens数据集,该数据集包含电影、演员、评分等信息。推荐项目也可以在演示服务器上以只读访问的形式获取,这意味着你无需创建新的数据库实例,可以直接使用。

推荐项目图谱结构。这张图是由作者绘制的。
在这个例子中,我使用GPT-4为训练数据集提供建议,然后审查并修正了建议。我们仅使用27个测试对。实际上,你可能希望至少使用几百个示例。
data = [
{
"question": "在1995年发布了多少部电影?",
"cypher": "MATCH (m:Movie) WHERE m.Year = 1995 RETURN count(*) AS result",
},
{
"question": "《盗梦空间》这部电影是谁导演的?",
"cypher": "MATCH (m:Movie {title: 'Inception'})<-[:DIRECTED]-(d) RETURN d.name",
},
{
"question": "《赌城风云》这部电影有哪些演员参演?",
"cypher": "MATCH (m:Movie {title: 'Casino'})<-[:ACTED_IN]-(a) RETURN a.name",
},
{
"question": "汤姆·汉克斯演过多少部电影?",
"cypher": "MATCH (a:Actor {name: 'Tom Hanks'})-[:ACTED_IN]->(m:Movie) RETURN count(m)",
},
{
"question": "《辛德勒的名单》这部电影有哪些类型?",
"cypher": "MATCH (m:Movie {title: 'Schindler\'s List'})-[:IN_GENRE]->(g:Genre) RETURN g.name",
},
...
]我们将使用LangChain来生成Cypher语句。LangChain中的Neo4jGraph对象负责建立与Neo4j的连接并获取其模式信息。
graph = Neo4jGraph()
print(graph.schema)
# Movie 节点属性:
# {posterEmbedding: 列表, url: 字符串, runtime: 整数, revenue: 整数, budget: 整数, plotEmbedding: 列表, imdbRating: 浮点数, released: 字符串, countries: 列表, languages: 列表, plot: 字符串, imdbVotes: 整数, imdbId: 字符串, year: 整数, poster: 字符串, movieId: 字符串, tmdbId: 字符串, title: 字符串}
# Genre 节点属性:
# {name: 字符串}
# User 节点属性:
# {userId: 字符串, name: 字符串}
# Actor 节点属性:
# {url: 字符串, bornIn: 字符串, bio: 字符串, died: 日期型, born: 日期型, imdbId: 字符串, name: 字符串, poster: 字符串, tmdbId: 字符串}
# Director 节点属性:
# {url: 字符串, bornIn: 字符串, born: 日期型, died: 日期型, tmdbId: 字符串, imdbId: 字符串, name: 字符串, poster: 字符串, bio: 字符串}
# Person 节点属性:
# {url: 字符串, bornIn: 字符串, bio: 字符串, died: 日期型, born: 日期型, imdbId: 字符串, name: 字符串, poster: 字符串, tmdbId: 字符串}
# 关系属性:
# 评价 {rating: 评分(浮点型), timestamp: 时间戳(整型)}
# 参演 {role: 字符串}
# 导演 {role: 字符串}
# 关系:
# 表示该电影属于该类型:(:Movie)-[:IN_GENRE]->(:Genre)
# 表示该用户对电影进行了评价:(:User)-[:RATED]->(:Movie)
# 表示该演员参演了该电影:(:Actor)-[:ACTED_IN]->(:Movie)
# 表示该演员导演了该电影:(:Actor)-[:DIRECTED]->(:Movie)
# 表示该导演导演了该电影:(:Director)-[:DIRECTED]->(:Movie)
# 表示该导演参演了该电影:(:Director)-[:ACTED_IN]->(:Movie)
# 表示该人员参演了该电影:(:Person)-[:ACTED_IN]->(:Movie)
# 表示该人员导演了该电影:(:Person)-[:DIRECTED]->(:Movie)该架构包含节点标签、属性以及相关的关系。接下来,我们将使用LangChain表达语言来定义给LLM的指令,要求其将自然语言转换成Cypher语句,以便回答相关问题。更多关于LangChain表达语言的信息,请访问官方文档。
cypher_template = """基于下面的Neo4j图模式,
编写一个Cypher查询以回答用户的问题。
仅返回Cypher语句,不加反引号,不加其他任何内容。
{schema}
问题: {question}
Cypher查询:""" # noqa: E501
cypher_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"给定一个输入问题,将其转换为Cypher查询。不加任何前言。",
),
("human", cypher_template),
]
)
cypher_chain = (
RunnablePassthrough.assign(
schema=lambda _: graph.get_schema,
)
| cypher_prompt
| llm.bind(stop=["\nCypher结果:"])
| StrOutputParser()
)如果你熟悉对话型LLM,你应该能识别出系统和人类的消息定义。如你所见,我们将图模式以及用户问题都放在了人类消息中。精确的提示工程指令以生成Cypher语句尚未完全解决,这意味着这里还有改进的空间。通过评估过程,你可以找到最适合特定LLM的方法。在这个例子中,我们使用的是gpt-4-turbo这款模型。
我们可以通过以下示例来测试Cypher(Cypher)生成过程:
response = cypher_chain.invoke(
{
"question": "标题中有'love'这个词且时长少于2小时的电影有多少部?"
}
)
print(response) gpt-4-turbo在把自然语言翻译成Cypher语句方面还算可以。我们现在来定义一下评估流程。
# 使用 tqdm 遍历每一行,以显示进度条
for index, row in tqdm(df.iterrows(), total=df.shape[0]):
# 根据测试 Cypher 语句获取数据
true_data = graph.query(row["cypher"])
# 生成 3 个 Cypher 语句并获取数据
example_generated_cyphers = []
example_eval_datas = []
for _ in range(3):
cypher = cypher_chain.invoke({"question": row["question"]})
example_generated_cyphers.append(cypher)
# 根据生成的 Cypher 语句获取数据
try:
example_eval_datas.append(graph.query(cypher))
except ValueError: # 处理语法错误的情况
example_eval_datas.append([{"id": "Cypher 语法错误"}])
# 这些指标只需第一个 Cypher 语句和响应
jaro_winkler = get_jw_distance(row["cypher"], example_generated_cyphers[0])
pass_1 = (
1
if df_sim_pair(
(row["cypher"], true_data),
(example_generated_cyphers[0], example_eval_datas[0]),
)
== 1
else 0
)
jaccard = df_sim_pair(
(row["cypher"], true_data),
(example_generated_cyphers[0], example_eval_datas[0]),
)
# 检查所有 3 个响应
pass_3 = 1 if any(
df_sim_pair((row["cypher"], true_data), (gen_cypher, eval_data)) == 1
for gen_cypher, eval_data in zip(example_generated_cyphers, example_eval_datas)
) else 0
# 将结果添加到各自的列表
generated_cyphers.append(example_generated_cyphers)
true_datas.append(true_data)
eval_datas.append(example_eval_datas)
jaro_winklers.append(jaro_winkler)
pass_1s.append(pass_1)
pass_3s.append(pass_3)
jaccards.append(jaccard)运行这段代码大约需要5分钟时间,因为我们需要生成81个响应数据来计算pass@3指标值。
代码略长,但核心内容很简单。我们遍历存储测试样本的数据框中的每一行。接着,为每个测试样本生成三个Cypher查询,并从数据库中检索相应数据。然后计算相关指标,并将它们存储在列表中,以便我们可以进行评估和可视化。我认为,由于审查每个度量的代码实现并不相关,所以在博客文章中没有包含辅助函数和代码实现。不过,所有这些函数和代码实现都在notebook中有提供。
我们现在来看看这些结果。
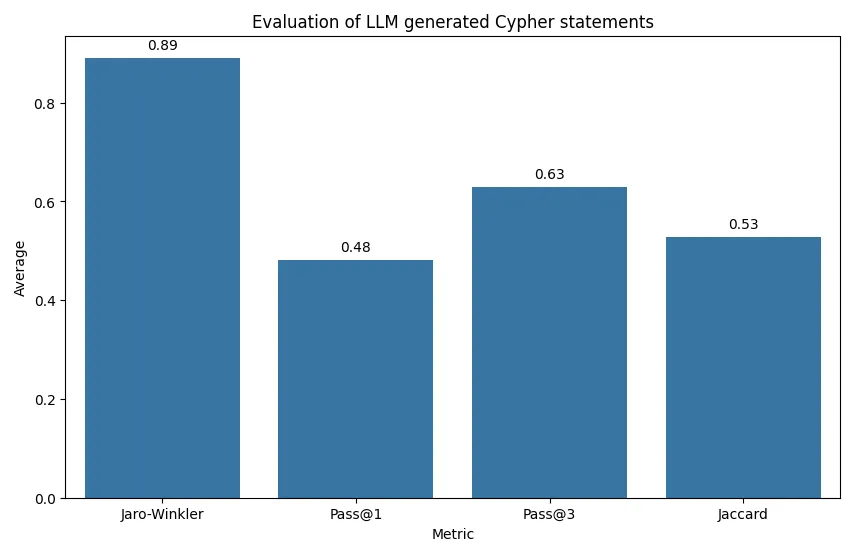
对LLM生成的Cypher语句进行评估,作者提供图片。
这里有四个不同的标准作为评估依据:
- Jaro-Winkler:此度量显示平均值为0.89,表明生成的Cypher查询在字符串层面与正确的Cypher查询非常接近。
- Pass@1:这里的平均分为0.48,表明大约一半的生成Cypher查询在独立评估时与正确查询返回了相同的结果集。
- Pass@3:平均分为0.63,这一度量表明相较于Pass@1有所改善。这说明尽管LLM可能在第一次尝试时无法完全正确生成查询,但在三次尝试内通常可以生成正确的查询。
- Jaccard相似度:平均分为0.53,是所有度量中最低的,但仍表明大约一半的时间,由LLM生成的Cypher查询结果集与正确查询的结果集有超过一半的相同元素。
总的来说,这些指标表明,LLM 生成的 Cypher 查询与正确答案很接近,并且通常会产生功能上等效的结果,尤其是在进行多次尝试时。然而,仍然有改进的空间,特别是在首次尝试就生成正确查询方面。此外,在评估过程中也有改进的余地。我们来看一个例子吧。
row = df.iloc[24]
# 输出所需信息
print("问题:", row["question"], "\n")
print("真实Cypher:", row["cypher"], "\n")
print("生成的Cypher:", row["generated_cypher"][0], "\n")
# 问题:哪些导演从来没有评分低于6.0的电影?
# 真实Cypher:
# MATCH (d:Director)-[:DIRECTED]->(m:电影)
# WITH d, MIN(m.imdbRating) AS lowestRating WHERE lowestRating >= 6.0
# RETURN d.name, lowestRating
# 生成的Cypher
# MATCH (d:Director)-[:DIRECTED]->(m:电影)
# WHERE NOT EXISTS {
# MATCH (d)-[:DIRECTED]->(m2:电影)
# WHERE m2.imdbRating < 6.0
# }
# RETURN DISTINCT d.name 关于哪些导演从未有评分低于6.0的电影的问题,LLM很好地完成了结果的获取。它采用了不同于测试数据集的方法,但这不是问题,因为它应得出相同的结果。然而,我们在测试数据中返回了电影的标题及其评分。而LLM仅生成了标题,未包含评分。我们不能责怪它,因为它只是遵循了指令。不过,你需要注意,在这个例子中,pass@1得分为0,而Jaccard相似度仅为0.5。因此,你得非常小心地构建测试数据集,不仅要定义提示,还要定义相应的Cypher查询。
LLM的另一个特点是每次运行你都可能得到不同的结果。我们现在连续运行三次评估。评估大约要花15分钟左右。
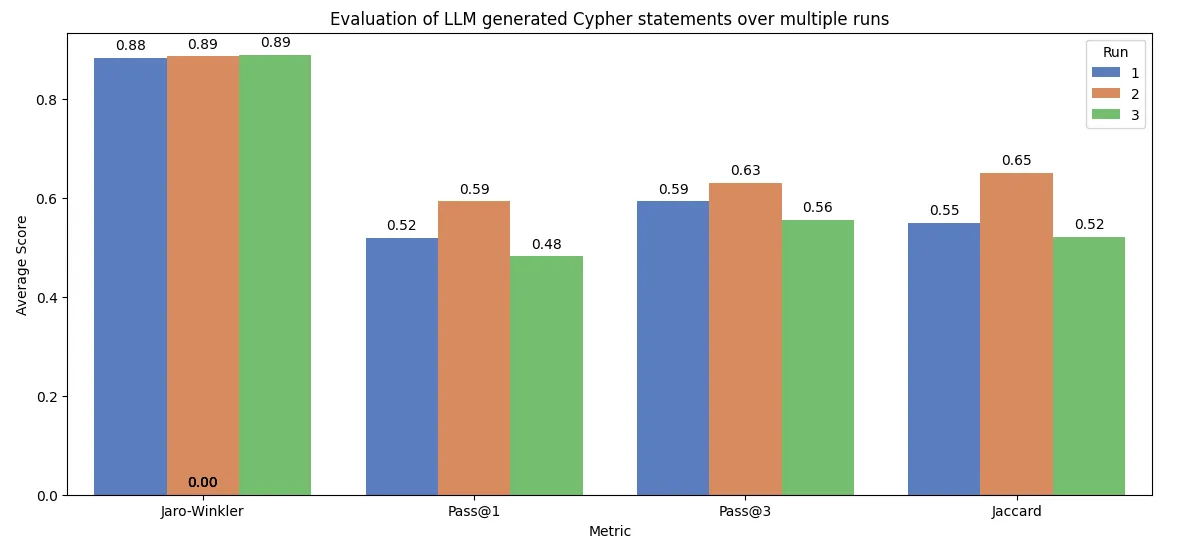
对LLM生成的Cypher语句的评估。图片由作者提供。
条形图强调了LLM的非确定性的特性。Jaro-Winkler分数在所有运行中都保持在较高水平,波动在0.88到0.89之间,显示生成查询的字符串相似度较为稳定。然而,对于Pass@1,首次运行得分为0.52,而接下来的运行得分分别为0.59和0.48。Pass@3的得分大约在0.56到0.63之间波动,表明多次尝试可以得到较为一致的正确结果。
结尾:在这篇博客文章中,我们了解到像GPT-4这样的大型语言模型能够生成Cypher查询,但该技术仍存在不足之处。提出的评估框架提供了对LLM性能的详细定量分析,帮助您持续实验并优化提示工程等关键步骤,以生成准确有效的Cypher语句。此外,它还展示了LLM的非确定性特性如何影响每次评估的性能。因此,在实际应用中,您可能会遇到类似的情况。
代码可在Github上查阅。
数据集F. Maxwell Harper 和 Joseph A. Konstan (2015). MovieLens 数据集的历史与背景. ACM 交互智能系统杂志 (TiiS) 5, 4: 19:1–19:19. https://doi.org/10.1145/2827872





