
LLaVA(或大型语言和视觉助手),一个开源的大型多模态模型。当前的版本1.16在几个月后发布的1.5版本的基础上做了一些改进,包括
- 将输入图像的分辨率提高到原来的 4倍,这能使图像捕捉到更多的视觉细节。支持三种宽高比,最高分辨率为 672 x 672 , 336 x 1344 , 1344 x 336。
- 提高了视觉推理能力和改进后的视觉指令调整数据混合,从而提高了 光学字符识别(OCR) 功能。
- 适用于更多场景的更好视觉对话,涵盖不同的应用。提升了对世界的认知和逻辑推理能力。
- 借助 SGLang 实现高效部署和推理。
LLAVA 1.6 今年一月发布的,距离1.5版本仅3到4个月。这让人们产生了疑问:这么短的时间内能有多少改进?
两者都在Ollama上,所以我决定用一些图片试试,看看它们的效果如何。
但是首先,LLaVA模型是什么呢?
LLaVA 是一个先进的LLM,具有增强的图像识别和问题回答能力。由微软开发,它展现了出色的多模态能力,有时甚至能像 GPT-4 这样的先进模型一样功能强大。
设计用于通用目的,LLaVA 可以根据文本和视觉输入理解并生成响应。这使其特别适合需要对视觉内容有细微理解的应用场景,例如回答关于图像的问题或在对话中解释视觉数据。
LLaVA — 介绍
在 LLaVA-1.6 中的一个重要升级是引入了动态高分辨率特性。通过将输入图像的分辨率提升至原来的四倍,如下所述,该模型现在支持这些分辨率规格的三种不同宽高比的图像,分别为 672 x 672 、 336 x 1344 和 1344 x 336 。这一改进使模型能够捕捉到更多细节,这对于需要精细视觉理解的任务来说非常重要。
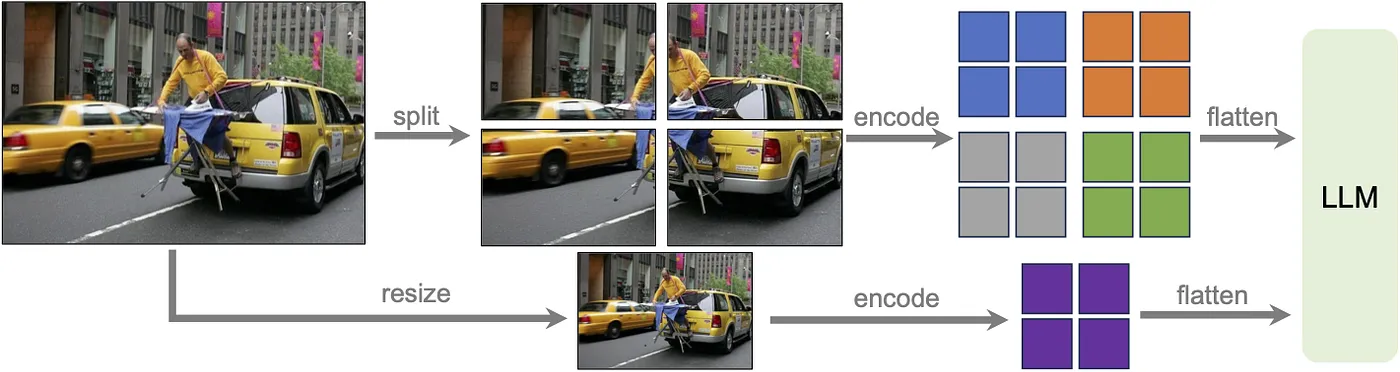
如这里和这里所示,这种先进的技术应用使得模型能够高效地处理各种高分辨率图像,并利用网格配置有效平衡了性能与运营成本,从而提高了处理效率。这种方法大大减少了模型在低分辨率图像中误判或错误解读视觉内容的倾向,从而提升了准确性和可靠性。
LlaVA-1.6 受益于一个旨在提升视觉指令跟随和对话能力的数据混合。该模型利用高质量的用户指令数据,这些数据强调任务指令的多样性和响应质量的优秀。该数据混合包括现有的 GPT-V 数据源,例如LAION-GPT-V 和ShareGPT-4V,以及一个新的由 15K 来自 LLaVA 演示的真实用户请求组成的视觉指令微调数据集。该数据集经过精心筛选,以解决隐私问题并消除潜在的危害,确保模型的响应既相关又安全,从而提高用户体验。
实施步骤
- 在本地下载 Ollama __ 并按以下说明和代码进行操作
# 1. 在这个项目中,我使用了 Python 3.10。
# 2. 创建并激活虚拟环境。
"""
python -m venv env
source env/Scripts/activate # 适用于 Windows(使用 Git Bash),source env/bin/activate # 适用于 Linux 和 macOS
"""
# 3. 安装依赖
"""
pip install ollama
"""
# 4. 使用 ollama 拉取 LLaVA 模型
"""
ollama pull llava # LLaVA 1.6
ollama pull llava:7b-v1.5-q4_0 # LLaVA 1.5
"""
# 5. 运行以下代码示例:
# llava.py
import ollama
from pathlib import Path
from base64 import b64encode
def load_image_as_base64(image_path):
with open(image_path, "rb") as img_file:
image_bytes = img_file.read()
return b64encode(image_bytes).decode('utf-8')
def generate_image_description(model, prompt, image_base64):
stream = ollama.generate(
model=model,
prompt=prompt,
images=[image_base64],
stream=True # 允许流式传输
)
response = ""
for chunk in stream: # 遍历流中的每个块
response += chunk['response']
return response
def main():
models = ["llava:7b-v1.5-q4_0", "llava"]
img_name = "falcon.png"
image_path = os.path.join("images", img_name)
image_path = Path(image_path)
image_base64 = load_image_as_base64(image_path)
prompt = "请详细描述这张图片的内容。"
for model in models:
print(f"模型: {model}") # 打印模型名称
print("=" * 30)
response = generate_image_description(model, prompt, image_base64)
print(response, flush=True) # 打印响应并刷新输出
print("\n")
if __name__ == "__main__":
main()确保你的图片名为 ./images/your_image.png,该文件夹与本脚本在同一目录下(例如,我使用了下面的图片)。

根据提供的提示,使用上面的脚本,我得到了如下的结果。
模型: llava:7b-v1.5-q4_0
==============================
图像中有一只细节丰富的大型鹰,它的喙和眼睛都是黄色的。它是画面的主要焦点。鹰周围有许多其他元素,如火焰,可能是代表它的羽毛或翅膀在运动时的样子。
此外,画面左侧还有一人似乎正在观察这幅画。也可能解释为那个人的脸是画的一部分。
模型: llava:v1.6
==============================
这是一幅描绘一只正在飞翔的猎鹰的数字插图,猎鹰的翅膀完全展开。猎鹰有着金黄色的眼睛,细节描绘得非常精细,展示了它有质感的羽毛和锐利的喙。它的身体上覆盖着火焰般的纹路,以黄色、橙色和红色为主,这些颜色似乎是从猎鹰的胸部发出的。背景是中性色,使猎鹰作为画作的主要主题更加突出。猎鹰微微向左看。图片中没有文字或其他物体,完全突出了猎鹰的形象。参考资料





