
一个典型的RAG应用程序主要包括两个部分:
索引化: 一个从源头导入数据并对其进行索引的流程。这通常是在离线状态下完成的。
检索和生成: 实际的RAG链过程在运行时获取用户查询,从索引中检索相关数据后,然后将这些数据传递给模型进行处理。
从原始数据到最后得出答案的最典型过程如下:
创建索引- 加载: 首先我们需要加载数据。我们可以通过DocumentLoaders来完成这个步骤。
- 分割: 文本拆分器将大
Documents分割成更小的块。这在索引数据和将其传递给模型时都很有用,因为大块文本更难以搜索,而且不会适应模型的有限上下文窗口。 - 存储: 我们需要一个地方来存储和索引分割后的数据,以便后续可以进行搜索。这通常通过VectorStore和Embeddings来完成。

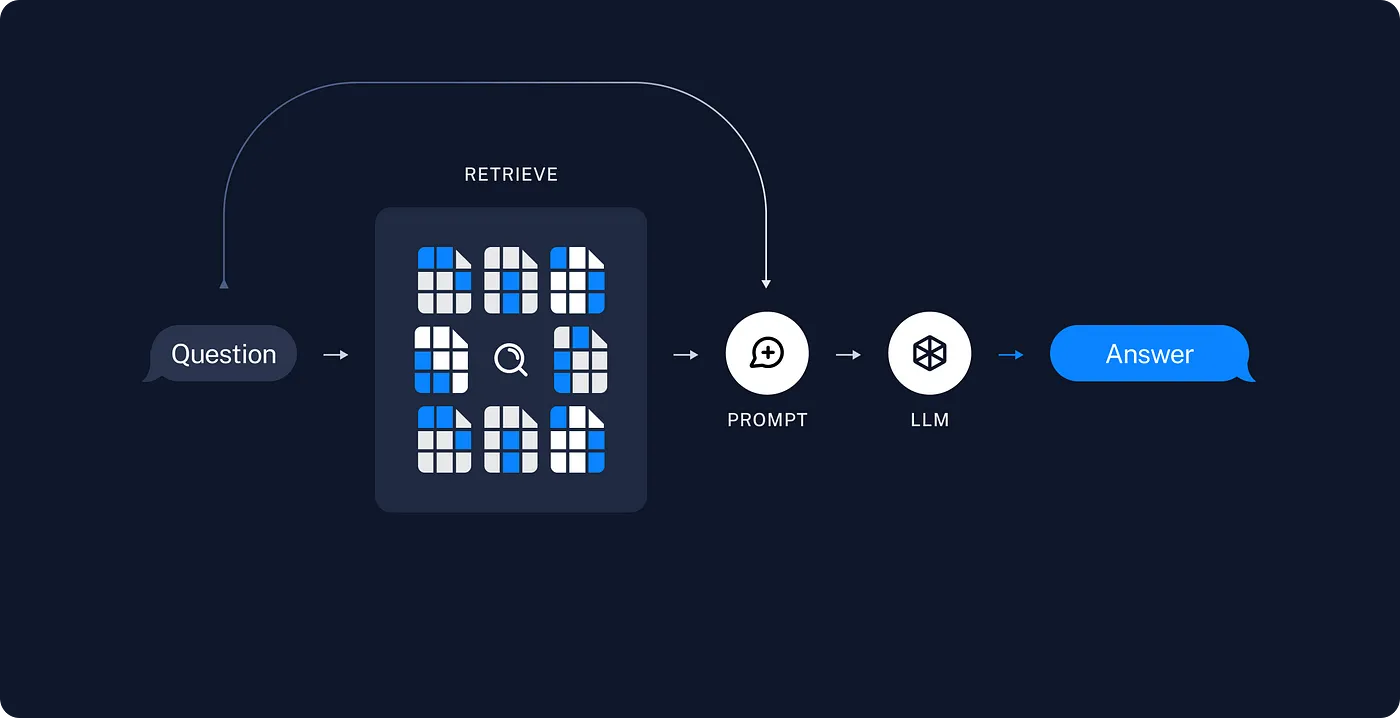
这里是一个RAG架构的例子。(RAG:检索、检索到的内容生成)
一次性的问题:
这里有一个示例代码,其中包含一个一次性提问,我们在这里问一个问题,并要求LLM仅根据提供的文档作答。如果文档中找不到答案,请回复“我不确定”。
import os
from dotenv import load_dotenv
from langchain_community.vectorstores import Chroma
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# 加载环境变量
load_dotenv()
# 定义持久目录
current_dir = os.path.dirname(os.path.abspath(__file__))
persistent_directory = os.path.join(
current_dir, "db", "chroma_db_with_metadata")
# 定义嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 加载包含嵌入功能的现有向量存储
db = Chroma(persist_directory=persistent_directory,
embedding_function=embeddings)
# 定义用户的查询
query = "如何了解更多关于LangChain的信息?"
# 根据查询检索相关的文档
retriever = db.as_retriever(
search_type="similarity",
search_kwargs={"k": 1},
)
relevant_docs = retriever.invoke(query)
# 显示带有元数据的相关文档
print("\n--- 相关文档 ---")
for i, doc in enumerate(relevant_docs, 1):
print(f"文档 {i}:\n{doc.page_content}\n")
# 结合查询和相关文档内容
combined_input = (
"这里有一些文档可能对回答这个问题有所帮助: "
+ query
+ "\n\n相关文档:\n"
+ "\n\n".join([doc.page_content for doc in relevant_docs])
+ "\n\n请仅依据提供的文档给出答案。如果在文档中找不到答案,请回答“我不确定”。"
)
# 创建ChatOpenAI模型
model = ChatOpenAI(model="gpt-4o-mini")
# 定义模型的信息
messages = [
SystemMessage(content="你是一个乐于助人的助手。"),
HumanMessage(content=combined_input),
]
# 使用结合的输入调用模型
result = model.invoke(messages)
# 显示生成的答案和内容
print("\n--- 生成的答案 ---")
print("内容如下:")
print(result.content)下面显示了上述代码的输出以及生成的回复。
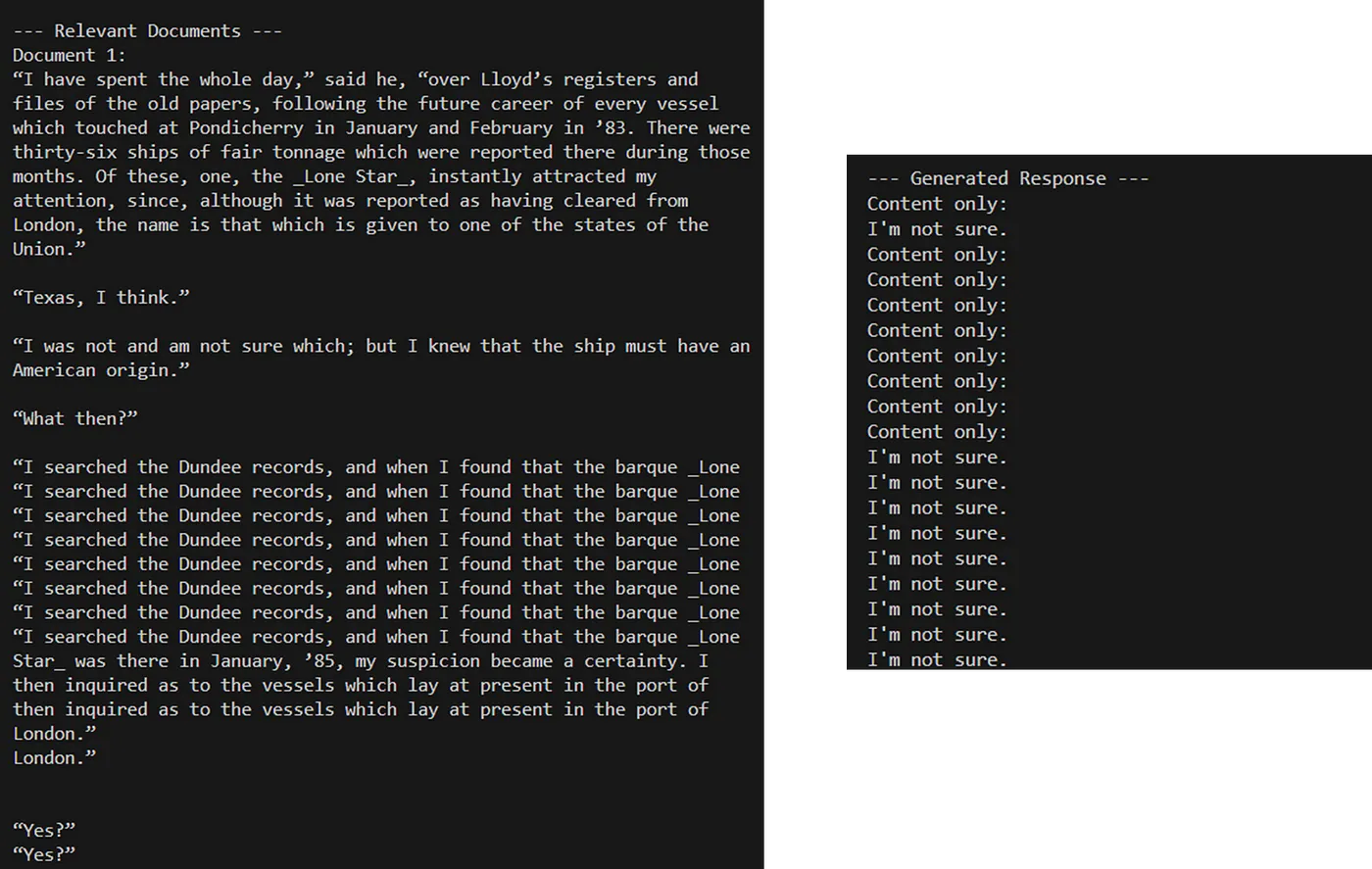
聊天:

如果我们想要一个聊天记录可以存储的应用程序,下面我们就来看看一些实用的存储命令吧。
# 上下文化问题提示
# 此系统提示帮助AI理解它应该根据聊天历史来重新表达问题,
# 让它成为一个不需要参考聊天历史就能理解的问题
contextualize_q_system_prompt = (
"根据聊天历史和最新的用户提问,该问题可能涉及聊天历史的内容,"
"重新表达一个可以独立理解的问题,如果有必要,请重新表述问题,"
"否则直接返回原问题。"
)定义AI的提示语。此系统提示让AI在处理对话历史中的问题时,知道如何应对。它要求AI将用户的提问独立出来,形成一个新的问题。AI在此不应回答问题,只需准备好以便后续处理。
# 创建一个用于上下文化问题的提示模板:
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{用户输入}"),
]
)目的:这会创建一个基于 contextualize_q_system_prompt 的 AI 提示模板。
功能如下:ChatPromptTemplate 对象配置为:如下
- 系统消息:包含
contextualize_q_system_prompt,解释如何重新表述问题。 - 消息占位符(聊天历史):一个用于填充聊天历史的占位符,在执行时会被替换。
- 用户消息:一个用于最新用户输入问题的占位符。
# 创建一个历史感知型检索器
# 它利用大模型根据聊天历史重述问题
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)意图:这将创建一个检索工具,在重新表述问题时参考聊天历史。
功能描述:create_history_aware_retriever 函数的作用是:
- 语言模型(LLM):根据聊天历史重述问题。
- 检索器:负责找相关文档的组件。
- 上下文提示模板:指导如何重述问题的模板。
# 回答问题提示
# 这个系统提示帮助AI理解,应该根据检索到的上下文提供简洁的答案,并在不知道答案时说明这一点。
qa_system_prompt = (
"你是一个用于问答任务的助手。使用以下检索到的上下文来回答问题。如果你不知道答案,就直接说你不知道。尽量用三句话以内,并保持答案简洁。\n\n{context}"
)目的:这个提示指导AI怎么做,利用检索到的上下文来生成回答。
作用:它让AI去做某事。
- 根据提供的信息来回答。
- 如果不确定答案或无法得出,回答说“我不知道。”
- 尽量保持回答简短,最好在三句话以内。
# 创建一个用于回答问题的提示模板:
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"), # 会话历史占位符
("human", "{input}"), # 用户输入
]
)目的:这创建了一个基于qa_system_prompt生成答案的模板,用于生成回答。
功能:配置了 ChatPromptTemplate 对象
- 系统信息:包含
qa_system_prompt,指示如何根据上下文回答问题。 - 消息占位符(用于存放聊天历史):在执行时用于存放聊天历史的占位符。
- 人类问题:需要回答的问题的占位符。
请参阅下方代码,以查看完整的代码设置。
import os
from dotenv import load_dotenv
from langchain.chains import create_history_aware_retriever, create_retrieval_chain
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_community.vectorstores import Chroma
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# 加载环境变量
load_dotenv()
# 定义持久化目录
current_dir = os.path.dirname(os.path.abspath(__file__))
persistent_directory = os.path.join(current_dir, "db", "chroma_db_with_metadata")
# 定义嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
# 加载现有的向量存储
db = Chroma(persist_directory=persistent_directory, embedding_function=embeddings)
# 创建检索器以查询向量存储
# `search_type` 指定搜索的类型(例如,相似性)
# `search_kwargs` 包含搜索的额外参数(例如,返回结果的数量)
retriever = db.as_retriever(
search_type="similarity",
search_kwargs={"k": 3},
)
# 创建 ChatOpenAI 模型
llm = ChatOpenAI(model="gpt-4o-mini")
# 上下文化问题提示
# 这个系统提示帮助 AI 理解它应该根据聊天历史重新表述问题
# 使其成为一个独立的问题,使其在没有聊天历史的情况下也可以理解。如果不需要重新表述,则直接返回原问题。
contextualize_q_system_prompt = (
"给定一个聊天历史和最新的用户问题,该问题可能引用了聊天历史中的上下文,"
"将其重新表述为一个独立的问题,使其在没有聊天历史的情况下也可以理解。"
"如果不需要重新表述,则直接返回原问题。"
)
# 创建上下文化问题的提示模板
contextualize_q_prompt = ChatPromptTemplate.from_messages(
[
("system", contextualize_q_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
# 创建一个基于历史的检索器
# 这个检索器使用 LLM 来帮助根据聊天历史重新表述问题
history_aware_retriever = create_history_aware_retriever(
llm, retriever, contextualize_q_prompt
)
# 回答问题的提示
# 这个系统提示帮助 AI 理解它应该根据检索到的上下文提供简洁的回答
# 并指示在不知道答案的情况下应该做什么
qa_system_prompt = (
"你是一个问答任务的助手。使用以下检索到的上下文来回答问题。"
"如果不知道答案,请直接说明不知道。答案要简洁明了,最多三句话。"
"\n\n"
"{context}"
)
# 创建一个回答问题的提示模板
qa_prompt = ChatPromptTemplate.from_messages(
[
("system", qa_system_prompt),
MessagesPlaceholder("chat_history"),
("human", "{input}"),
]
)
# 创建一个链来组合文档以进行问答
# `create_stuff_documents_chain` 将所有检索到的上下文传入 LLM
question_answer_chain = create_stuff_documents_chain(llm, qa_prompt)
# 创建一个结合基于历史检索器和问答链的检索链
rag_chain = create_retrieval_chain(history_aware_retriever, question_answer_chain)
# 函数用于模拟持续聊天
def continual_chat():
print("开始和 AI 聊天吧!输入 'exit' 结束对话。")
chat_history = [] # 在这里收集聊天历史(一系列消息)
while True:
query = input("你: ")
if query.lower() == "exit":
break
# 对用户的问题进行处理,通过检索链
result = rag_chain.invoke({"input": query, "chat_history": chat_history})
# 显示 AI 的回答
print(f"AI: {result['answer']}")
# 更新聊天历史
chat_history.append(HumanMessage(content=query))
chat_history.append(SystemMessage(content=result["answer"]))
# 主函数用于启动持续聊天
if __name__ == "__main__":
continual_chat()总之,这些代码片段定义了如何根据聊天记录重新表述问题以及如何利用提供的上下文信息生成答案。
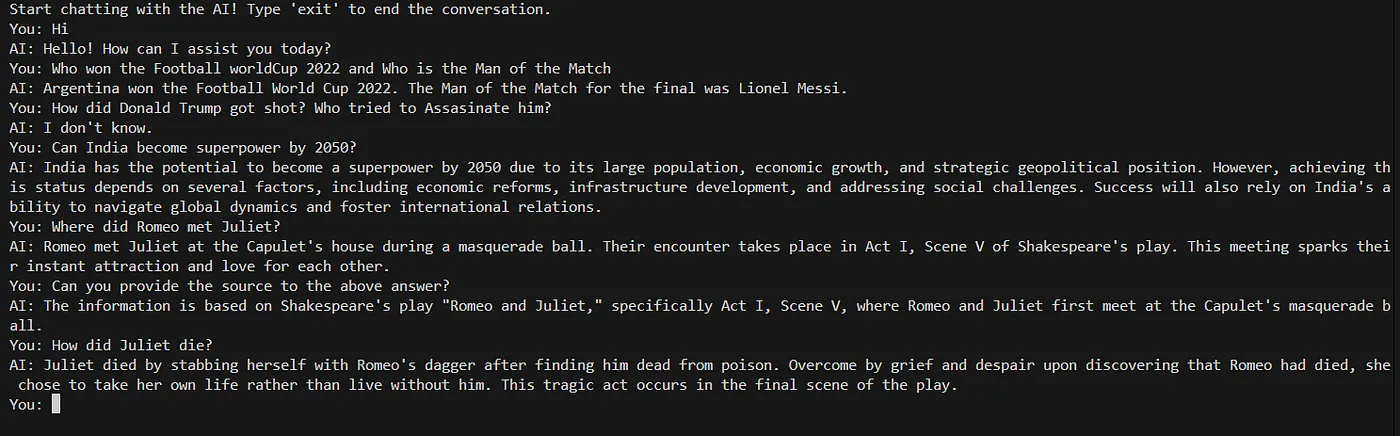
我检查了一些问题的输出结果。
参考:
1。 https://python.langchain.com/v0.1/docs/use_cases/question_answering/
2。 https://python.langchain.com/v0.1/docs/modules/data_connection/document_transformers/?source=post_page-----3225af44e7ea--------------------------------
-
https://python.langchain.com/v0.1/docs/modules/data_connection/text_embedding/?source=post_page-----3225af44e7ea-------------------------------- 文本嵌入模块的文档。请点击这里查看文本嵌入模块的文档。
-
这里是链接: https://python.langchain.com/v0.2/docs/integrations/chat/
- https://brandonhancock.io/langchain-master-class 布兰登·汉考克的语言链大师课程页面
6. https://platform.openai.com/docs/guides/embeddings/关于嵌入表示的指南
- 查看这里: https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/ (7. 查看这里: [链接])





