
让我们来探索一下Kafka,一个用于高吞吐量、低延迟数据流的强大消息代理。我们将看看如何将Kafka与FastAPI集成,来处理大规模的消息。
这张图片是由ChatGPT(OpenAI)生成的
卡夫卡(一名著名的捷克作家)
Kafka 是一个开源的实时消息传递和数据流处理平台。它被设计用来快速可靠地处理大量数据。Kafka 常用于构建数据管道和实时处理信息流数据。
它通过在日志中存储数据来运行,这使其能够提供持久性存储和扩展性,意味着它可以轻松处理大量数据并轻松扩展,以适应需求。Kafka具有容错性,即使出现问题也不会丢失数据。
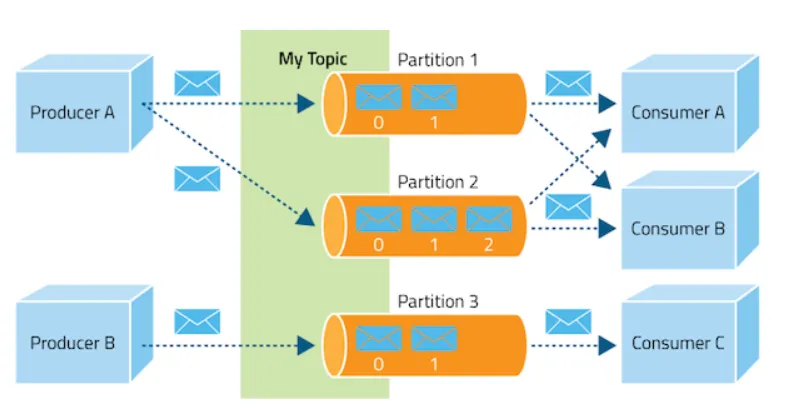
来源:"Apache Kafka中的数据流"https://www.researchgate.net/figure/Data-flow-in-Apache-Kafka_fig2_358882502
Kafka的架构体系:
Kafka架构基于以下组件:
- 主题 :在 Kafka 中,一个主题是一个类别或消息发布的订阅源。生产者将数据写入主题,消费者从主题读取数据。
- 代理 :代理是 Kafka 服务的实例。每个代理处理分区中的消息存储和检索。多个代理组成一个 Kafka 集群。
- 生产者 :生产者是发布数据到主题的应用。它们负责将消息发送到代理。
- 消费者 :消费者是从主题读取数据的应用。它们负责从代理读取消息并进行处理。
- 分区 :每个主题被划分为多个分区。Kafka 将这些分区分布在不同的代理中,以确保高可用性和负载均衡。分区是一个有序记录序列,并且 Kafka 保证分区内的有序性。
- 偏移量 :每个分区中的消息都有一个唯一的偏移量,用于标识该消息。消费者使用偏移量来追踪它们在分区中的进度。
要在你的系统上启动Kafka,你可以直接使用这个Docker镜像:
docker run bashj79/kafka-kraft运行docker容器,将9092端口映射到主机,并在后台运行bashj79/kafka-kraft镜像。我使用了Python的Kafka客户端库 aiokafka,可以通过以下命令进行安装。
在你的终端里执行这行命令:
pip install aiokafka让我们从 FastAPI 项目的搭建开始,建立与上一篇博客中相同的目录结构。同时,在虚拟环境中安装这些依赖。
pip install fastapi pydantic-settings uvicorn # 安装fastapi, pydantic-settings和uvicorn ├── README.md
├── app.py
├── config
│ ├── __init__.py
│ └── config.py
├── logger
│ ├── __init__.py
│ └── logger.py
├── requirements.txt
├── run.py
├── .env
└── src
├── __init__.py
├── api
│ └── v1
│ ├── __init__.py
│ ├── services
│ │ ├── __init__.py
│ │ └── kafka
│ │ ├── __init__.py
│ │ └── kafka.py
│ └── views
│ ├── __init__.py
│ └── order.py
└── route
├── __init__.py
└── router.py创建一个 .env 文件,并在里面添加以下变量。
KAFKA_SERVER_URL=localhost:9092 # Kafka服务URL
KAFKA_TOPIC_NAME=send_notification # Kafka主题名称
KAFKA_GROUP_NAME=notif_group # Kafka分组名称(通知组)现在,让我们配置 config.py 文件以定义环境变量,使程序适应不同的运行环境
from functools import lru_cache
from pydantic_settings import BaseSettings, SettingsConfigDict
class ConfigSetting(BaseSettings):
model_config = SettingsConfigDict(env_file=".env")
调试模式: bool
Kafka服务器URL: str
Kafka主题名称: str
Kafka分组名称: str
@lru_cache
def 获取设置():
return ConfigSetting()
settings = 获取设置()接下来,我们将设置FastAPI的app.py文件,让它在Uvicorn上运行。
# app.py 中的代码
import asyncio
from contextlib import asynccontextmanager
from fastapi import FastAPI
from config.config import settings # 配置
from src.api.v1.services.kafka.kafka import kafka_consumer # kafka消费者
from src.route.router import router # 路由
@asynccontextmanager
async def lifespan(app: FastAPI):
"""生命周期函数"""
asyncio.create_task(kafka_consumer(settings.KAFKA_TOPIC_NAME, settings.KAFKA_GROUP_NAME))
yield
app = FastAPI(lifespan=lifespan)
app.include_router(router)
# run.py 代码
import uvicorn # 使用uvicorn启动应用
if __name__ == "__main__":
uvicorn.run("app:app", host="0.0.0.0", port=8000) # 主函数入口在这一步里,我们配置了 kafka_consumer() 函数,使其能够持续监听发布的主题。这个任务将在 FastAPI 的生命周期内作为一个异步I/O任务来定义。
要开始这个项目,你需要做的是运行 run.py。
接下来要做的,我们将创建或配置 kafka.py 文件,在文件中定义了这两个函数:Producer 和 Consumer。
import json
import aiokafka
from config.config import settings
async def kafka_consumer(topic: str, group_id: str):
while True:
consumer = None
try:
consumer = aiokafka.AIOKafkaConsumer(
topic,
bootstrap_servers=settings.KAFKA_SERVER_URL,
group_id=group_id,
enable_auto_commit=True,
# 如果设置为False,则需要使用consumer.commit()方法手动提交。
auto_commit_interval_ms=1000, # 每秒自动提交
auto_offset_reset="earliest",
)
await consumer.start()
logger.info(f"Kafka 消费者: 已开始")
async for message in consumer:
logger.info(f"Kafka 消费者: 键: {message.key} - 值: {message.value}")
# await consumer.commit() # 如果enable_auto_commit=False,则使用此行。
except Exception as e:
logger.error(f"异常: Kafka 消费者: {str(e)}")
finally:
await consumer.stop()
async def kafka_producer(topic: str, data: dict):
producer = aiokafka.AIOKafkaProducer(bootstrap_servers=settings.KAFKA_SERVER_URL)
await producer.start()
try:
data = json.dumps({"data": data})
logger.info(f"Kafka 生产者: 数据:{data}")
await producer.send_and_wait(topic, data.encode("utf-8"))
except Exception as e:
logger.error(f"异常: Kafka 生产者: {str(e)}")
finally:
await producer.stop()我们来理解为Kafka服务的消费者和生产者开发的上述代码。
- topics:参数
topics,就像频道一样,用于发送和接收消息,帮助组织数据并允许进行可扩展和分布式的处理。例如:KAFKA_TOPIC_NAME=send_notification - bootstrap_servers:指定Kafka服务运行的代理URL(例如,本地主机的9092端口)。例如:
KAFKA_SERVER_URL=localhost:9092 - group_id: 消费者组名称。同一组中的多个消费者将共享处理消息的工作量。主题和group_id之间的区别在于,Kafka中的主题是发送消息的地方,而group_id用于标识从主题读取消息的消费者组。例如:
KAFKA_GROUP_NAME=notif_group - enable_auto_commit=True:如果设置为True,Kafka会在消费者消费消息后自动提交其偏移量(即在主题中的位置)。
- auto_commit_interval_ms=1000: 自动提交间隔(以毫秒为单位)。这意味着每秒自动提交一次偏移量。
- auto_offset_reset="earliest":如果没有存储消费者组的偏移量,这定义了消费者开始消费消息时的行为:“earliest”将从最早的可用消息开始。“latest”将从最新的可用消息开始。
现在创建一个端点,它将执行相同类型的操作,并将数据或消息发送至队列,该队列最终会被消费者读取。
# 下面是 order.py 的代码
from fastapi import APIRouter as APIRouter
from config.config import settings
from src.api.v1.services.kafka.kafka import kafka_producer
router = APIRouter(prefix="/order")
@router.post("/send-message")
async def send_message(email: str, message: str):
data = {"email": email, "message": message}
await kafka_producer(settings.KAFKA_TOPIC_NAME, data)
return {"message": "Success"}
# 下面是 router.py 的代码
from fastapi import APIRouter as APIRouter
from src.api.v1.views import order
router = APIRouter(prefix="/api/v1")
router.include_router(order.router, tags=["订单 API"])这就是在FastAPI中实现Kafka所需的全部代码配置。你可以定义多个主题,并使用不同的组ID来处理来自不同消费者的各个消息。
FastAPI 的 Swagger UI 用于上述 API
特点:
- 高吞吐量:Kafka每秒可以处理数百万条消息,非常适合大规模数据流处理和实时处理。
- 持久性和持久化存储:Kafka安全地存储消息,确保即使服务器故障也不会丢失消息。消息会被写入磁盘并在多个服务器上进行备份。
- 容错性:即使某些部分出现故障,Kafka仍然可以继续运行。它会在不同的服务器上备份消息,确保数据始终安全。
- 消息保留和回放:Kafka会保留消息一段时间,允许消费者在需要时重新读取过去的任何消息。
- 分区:Kafka将数据拆分为多个分区,分散在不同的服务器上,通过允许并行处理,提高处理速度和系统的可扩展性。
- 消费者组功能:多个消费者可以共享阅读主题数据的任务。每个消费者从不同的分区读取,允许消息并行处理。
- 实时流数据处理:Kafka设计用于处理实时数据,非常适合需要实时处理数据的应用,例如监控或分析。
限制条件:
- 延迟:Kafka 优化用于高吞吐量,但相比 Redis 等系统,它可能会有更高的延迟(处理时间更慢),对于需要极低延迟的实时应用来说这可能是个问题。
- 存储开销:长时间存储大量数据在 Kafka 中会需要大量的存储空间,因此你需要注意管理保留设置。
- 没有内置的确认机制:Kafka 使用基于偏移量的确认机制,消费者需要手动提交进度,以避免在出现故障时重新处理。
这些消息队列(Redis、RabbitMQ 和 Kafka)之间的区别是:
-
类型 :
- Redis : Redis 是一个内存数据存储系统,它将数据直接存储在内存中,使其非常快。
- RabbitMQ : RabbitMQ 是一个使用 AMQP(高级消息队列协议)发送和接收消息的消息代理。它支持可靠的消息传递和路由。
- Kafka : Kafka 是一个分布式事件流处理平台,适用于高吞吐量和实时数据处理。它可以处理大量的数据流。 -
消息持久性 :
- Redis : Redis 提供可选的持久化,但数据可能会在崩溃时丢失。
- RabbitMQ : RabbitMQ 提供消息持久化,确保即使 RabbitMQ 崩溃,消息也不会丢失。
- Kafka : Kafka 提供很高的数据持久性。它将消息存储在磁盘并跨多个代理进行复制。即使某个节点或代理失败,数据也是安全的,并且可以恢复。 -
性能 :
- Redis : Redis 提供极低的延迟,因为它完全在内存中操作。
- RabbitMQ : RabbitMQ 由于将消息存储在磁盘上(为了持久性),因此会引入一些延迟。
- Kafka : Kafka 的延迟虽然低,但仍然高于 Redis。它优化了批处理和高吞吐量。 - 消息路由 :
- Redis : Redis 提供简单的发布/订阅消息机制,客户端可以订阅频道并接收消息。
- RabbitMQ : 它支持不同类型的交换(如 direct、fanout、topic 和 headers),基于内容或路由键将消息路由到不同的队列。
- Kafka : Kafka 使用主题和分区来进行消息路由。
关于消息代理的介绍就到这里!我们讨论了 Redis、RabbitMQ 和 Kafka,探讨了它们如何与 FastAPI 集成以及它们处理消息的不同方式。每个消息代理都有其独特的优点,适用于不同的应用场景。
感谢您的陪伴,祝您编程愉快,使用消息系统时!🎉





