

AWS 在 2024 年的 re:Invent 大会上推出了 S3 Tables,这对我来说真是太及时了。
S3 表实际上是一个由 Apache Iceberg 管理的表。Iceberg 是一种表格式,可以存储在各种后端文件或类文件存储中,其中就包括 S3。
我在做一个项目,该项目将一堆物联网事件存入S3,实际上要管理查询相当麻烦,因为需要处理分区的管理和创建等。Iceberg可能提供一个更有效的查询选项,让我只需为实际使用付费,分区可以作为表定义的一部分来设置,所以在设置完成后维护工作应该是最少的。不过,Iceberg格式本身也存在其他需要维护的地方,所以当AWS宣布S3 Tables作为一种内置maintenance jobs的托管Iceberg格式后,我非常感兴趣,现在我有了一些空闲时间来尝试一下。
请注意,截至目前为止,S3 表格只有 三个可用区域。
遗憾的是,公告博客文章 和 入门教程 都讲得不够详细……而且,我只是想试用一下,并不想为了这个搭建一个 Amazon EMR 集群!
我引用如下:
为了进行测试,我安装了 Apache Spark,然后通过命令行参数调用了 Spark shell 命令,以使用 Amazon S3 Tables Catalog for Apache Iceberg 插件,并将
mytablebucket设置为我的表的 ARN。
如果你不熟悉 Apache Spark,那上面这句话有很多需要解释的地方。
我以前用过Spark,为了帮助回忆,我打算在我的本地笔记本上运行Spark。这意味着我需要找到一个Spark的Docker容器,并且传递我的AWS凭证信息,找到合适的Spark jar包进行安装。这主要是为了我自己以后能参考,也希望能对其他人有所帮助。
现在在我深入研究S3 Tables路径之前,我只是想从我的笔记本电脑上建立一个简单的与Spark的连接,以便读取S3桶中的一个JSON Lines格式的文件。为此我花了整整一天的时间。令人惊讶的是,我并没有找到太多相关的参考资料。但请放心,亲爱的读者,我已经成功了,下面我会告诉你具体怎么做。如果你想直接跳到S3 Tables的内容,只需跳到文章末尾的第四步即可。
第一步:选择正确的Docker容器显然,Apache Spark 的容器似乎已被废弃。因此,看起来我们应该使用 “官方”Docker 镜像。我选择了版本 3.5.3,因为它相对较新。此外,这个镜像也预装了 pyspark。
完成这项工作只需要两个依赖项。Hadoop-aws 和 aws-java-sdk-v1。让人困惑的是,所有版本的Spark自带的是Hadoop API的 v3.3.4 版本,而该版本存在不少安全漏洞。这个版本只需要AWS SDK的 v1 版本。如果您使用 v3.4.0 版本的,需要 AWS SDK 的 v2 版本,但目前无法在任何版本的Spark上运行。最初我以为我需要 v3.4.0 的 hadoop-aws 依赖。
java.lang.NoClassDefFoundError: software/amazon/awssdk/transfer/s3/progress/TransferListener这是一个Java运行时错误,表示Java虚拟机(JVM)在运行时找不到指定的类。具体来说,NoClassDefFoundError错误通常发生在JVM能够找到类的定义,但在运行时却无法找到相应的类文件。这里的错误是由于无法找到software/amazon/awssdk/transfer/s3/progress/TransferListener这个类导致的。
原来 software/amazon/awssdk 指的是 AWS SDK 的第二版(v2)。所以我添加了那个依赖后,却遇到了另一种错误:
这是Java中的一个技术错误消息,表示找不到指定的类:java.lang.NoClassDefFoundError: org/apache/hadoop/fs/impl/prefetch/PrefetchingStatistics
ChatGPT 友善地告诉我,我可能用的是 hadoop-aws 的错误版本号。
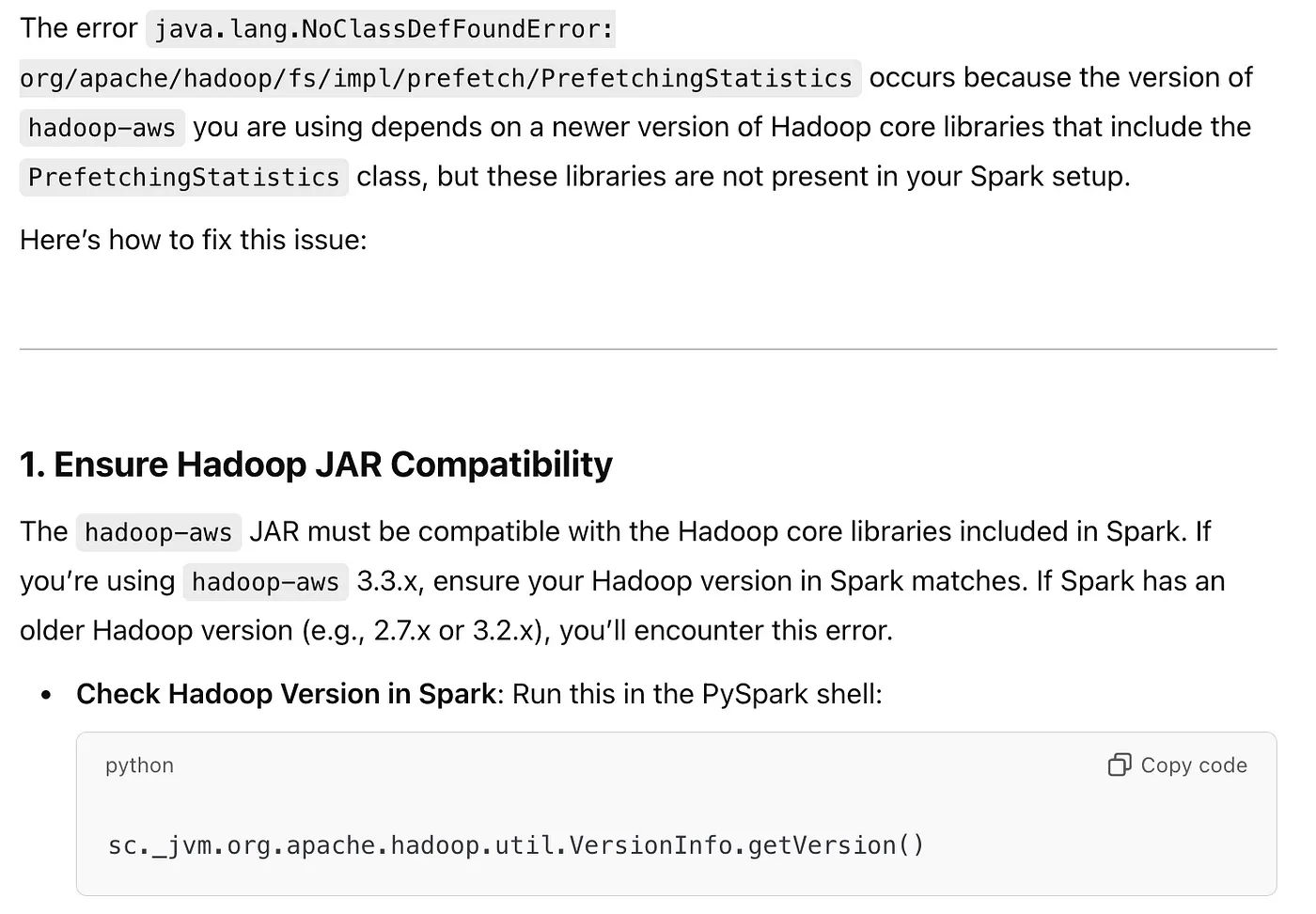
果然,sc._jvm.org.apache.hadoop.util.VersionInfo getVersion() 显示我需要 3.3.4。
欢迎来到
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_\
/__ / .__/\_,_/_/ /_/\_\ 版本 3.5.3.
/_/
使用 Python 版本 3.8.10 (默认, 2024年9月11日 16:02:53)
Spark 界面 Web UI 可访问于 http://1e1bfeb13ac6:4040
Spark 上下文可用,标识为 'sc' (master = local[*], app id = local-1734921751593)。
SparkSession 可用,标识为 'spark'。
>>> sc._jvm.org.apache.hadoop.util.VersionInfo.getVersion()
'3.3.4'
>>>最后我需要一些AWS凭证才能实际读取我的S3桶。我用Granted来管理我的AWS凭证,非常推荐!这意味着将凭证传递给我的Docker容器非常简单,我只需将它们直接粘贴到.env文件中,使用这个命令assume <我的角色> -env,然后传递过去。为了更安全,你可以运行这个命令chmod 700 .env。是的,这可以——它们是暂时的,之后会过期。要特别感谢我的朋友Josh——我也看到他在这里使用Granted了。
下面是你最终需要的Docker命令:
docker run -it \
-v ./custom-jars:/custom-jars \ (将本地文件夹挂载到容器中)
-v ./app:/app \ (将本地应用程序文件夹挂载到容器中)
--env-file ./.env \ (使用环境文件来设置环境变量)
spark:3.5.3 \
/opt/spark/bin/pyspark \ (启动Spark的PySpark脚本)
--jars "/custom-jars/aws-java-sdk-bundle-1.12.661.jar,/custom-jars/hadoop-aws-3.3.4.jar" \ (指定自定义JAR文件)
--conf "spark.hadoop.fs.s3a.impl=org.apache.hadoop.fs.s3a.S3AFileSystem" (配置Spark使用S3A文件系统)(启动Docker容器并运行Spark PySpark脚本,同时挂载自定义JAR文件和应用程序文件夹)
步骤 3:将样本数据加载到 Spark 中我成功加载了数据。
>>> df = spark.read.json(f"s3a://xxxxx-ss-test-data/movies.ndjson")
24/12/23 02:56:42 WARN MetricsConfig: 无法找到配置:已尝试 hadoop-metrics2-s3a-file-system.properties 和 hadoop-metrics2.properties
>>> df.show()
+----------------+--------------------+--------------------+--------------------+--------------------+----------------+---------------+--------------------+----+
| 演员阵容| 提取| 类型| 链接| 缩略图|缩略图高度|缩略图宽度| 标题|年份|
+----------------+--------------------+--------------------+--------------------+--------------------+----------------+---------------+--------------------+----+
| []| NULL| []| NULL| NULL| NULL| NULL|After Dark in Cen...|1900|
| []| NULL| []| NULL| NULL| NULL| NULL|Boarding School G...|1900|
| []| NULL| []| NULL| NULL| NULL| NULL|Buffalo Bill's Wi...|1900|
| []| NULL| []| NULL| NULL| NULL| NULL| Caught|1900|
| []|Clowns Spinning H...|[短片, 无声]|Clowns_Spinning_Hats| NULL| NULL| NULL|Clowns Spinning Hats|1900|
| []|Capture of Boer B...|[短片, 纪录片]|Capture_of_Boer_B...|https://upload.wi...| 240| 320|Capture of Boer B...|1900|
| []|The Enchanted Dra...|[无声]|The_Enchanted_Dra...|https://upload.wi...| 240| 320|The Enchanted Dra...|1900|
| [Paul Boyton]|Feeding Sea Lions...|[短片, 无声]| Feeding_Sea_Lions| NULL| NULL| NULL| Feeding Sea Lions|1900|
| []| NULL|[喜剧]| NULL| NULL| NULL| NULL|How to Make a Fat...|1900|
| []| NULL| []| NULL| NULL| NULL| NULL| New Life Rescue|1900|
| []| NULL| []| NULL| NULL| NULL| NULL| New Morning Bath|1900|
| []|Searching Ruins o...|[无声]|Searching_Ruins_o...|https://upload.wi...| 240| 320|Searching Ruins o...|1900|
| []|Sherlock Holmes B...|[短片, 无声]|Sherlock_Holmes_B...|https://upload.wi...| 256| 320|Sherlock Holmes B...|1900|
| []| NULL| []| NULL| NULL| NULL| NULL|The Tribulations ...|1900|
| []| NULL|[喜剧]| NULL| NULL| NULL| NULL|Trouble in Hogan'...|1900|
| []| NULL|[短片]| NULL| NULL| NULL| NULL| Two Old Sparks|1900|
|[Ching Ling Foo]| NULL|[短片]| NULL| NULL| NULL| NULL|The Wonder, Ching...|1900|
| []| NULL|[短片]| NULL| NULL| NULL| NULL| Watermelon Contest|1900|
| []| NULL| []| NULL| NULL| NULL| NULL| Acrobats in Cairo|1901|
| []|Affair of Honor i...|[无声]| An_Affair_of_Honor| NULL| NULL| NULL| An Affair of Honor|1901|
+----------------+--------------------+--------------------+--------------------+--------------------+----------------+---------------+--------------------+----+
仅显示前20行数据希望你克隆并运行 make spark-test。这应该会提交一个 Spark 作业,生成过去大约 100 年的最流行的电影类型 ASCII 艺术图:
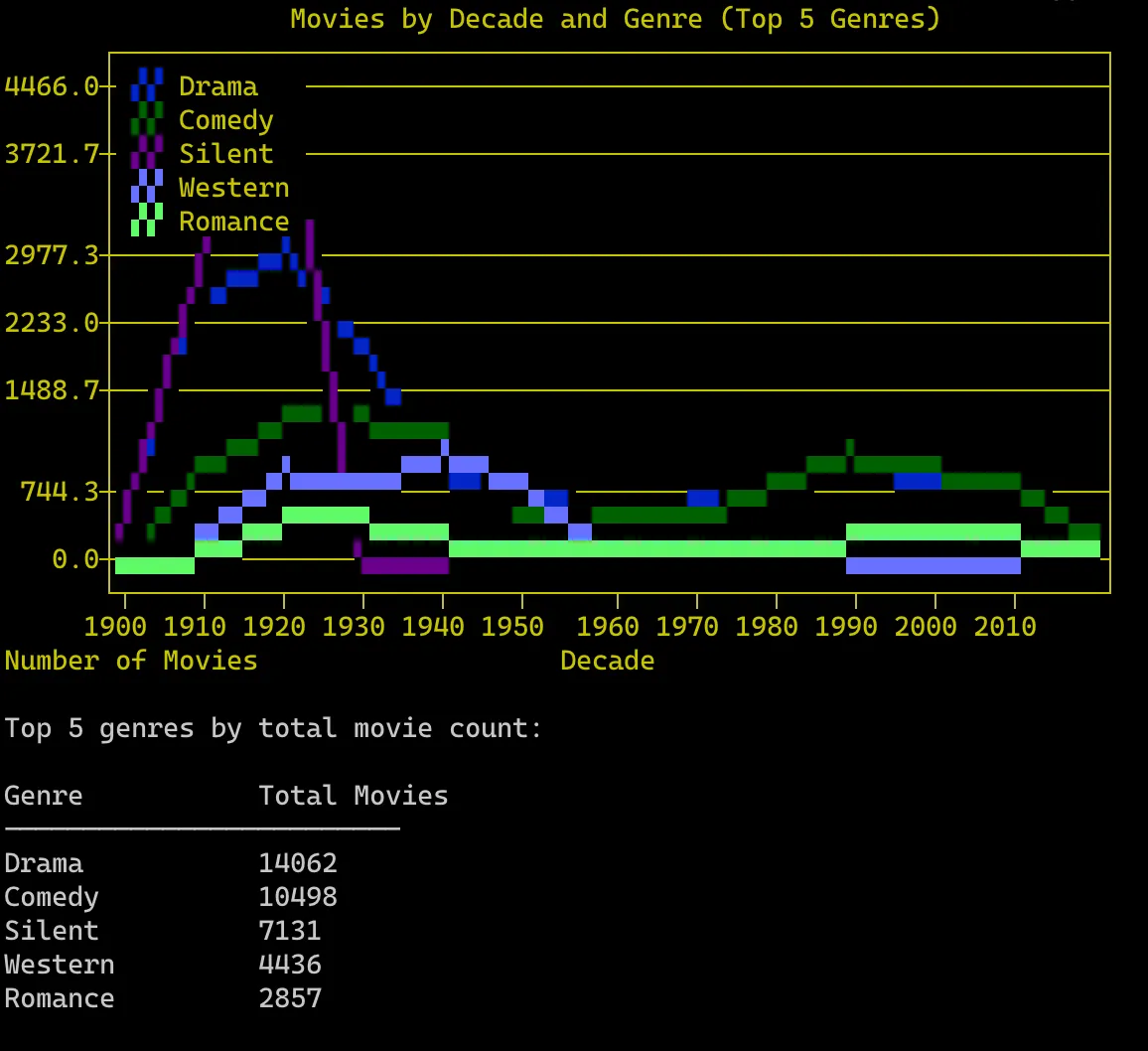
好了!这个让我花了一个周末的离题就到此为止吧!
你是为了能够在本地开发你的Spark脚本程序,但使用S3表格作为后端是这样吗?
最后一步 4:设置本地 Spark 以便访问到 AWS 上的 S3 表格实际上,我真正需要的关键线索实际上是在官方指南中,它告诉我应该使用Amazon EMR,但我没太在意,这让我折腾了一阵子,但也因此学到了不少东西:)。
spark-shell \
--packages software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3 \
--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \
--conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-east-1:111122223333:bucket/amzn-s3-demo-table-bucket \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions 所以我需要 [s3-tables-catalog-for-iceberg](https://mvnrepository.com/artifact/software.amazon.s3tables/s3-tables-catalog-for-iceberg/0.1.3),这挺合理的。我还得假设我需要 [iceberg-spark-runtime](https://mvnrepository.com/artifact/org.apache.iceberg/iceberg-spark-runtime-3.5_2.12/1.6.1)。其他的依赖项在Maven的运行时依赖列表里也都有。
- caffeine
- Apache commons configuration
- 虽然它比我需要的大些,但我还是拿了 AWS SDK v2 bundle 这个包。
我得确保我的区域支持 S3 Tables,所以我先选了 us-west-2。然后我按照 AWS 教程里的配置,用了同样的 s3 表格参数。我还得在我的 .env 文件里把 AWS_REGION 设置对。
首先,我先创建了我的存储空间,然后运行了Docker中的Spark环境,之后按照AWS的教程步骤操作就可以顺利运行了。
# 在 docker 命令中的 spark 配置中替换你的表桶ARN: spark.sql.catalog.s3tablesbucket.warehouse
$ export AWS_REGION=us-west-2
$ aws s3tables create-table-bucket --region us-west-2 --name test
{
"arn": "arn:aws:s3tables:us-west-2:xxx:bucket/test"
}
$ docker run -it \
-v ./custom-jars:/custom-jars \
-v ./app:/app \
--env-file ./.env \
spark:3.5.3 \
/opt/spark/bin/pyspark \
--jars "/custom-jars/bundle-2.29.38.jar,/custom-jars/s3-tables-catalog-for-iceberg-0.1.3.jar,/custom-jars/iceberg-spark-runtime-3.5_2.12-1.6.1.jar,/custom-jars/commons-configuration2-2.11.0.jar,/custom-jars/caffeine-3.1.8.jar" \
--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \
--conf spark.sql.catalog.s3tablesbucket.warehouse=arn:aws:s3tables:us-west-2:xxx:bucket/test \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
Python 3.8.10 (default, Sep 11 2024, 16:02:53)
[GCC 9.4.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
24/12/23 03:22:17 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
默认的日志级别已设置为 'WARN'。 若要调整日志级别,请使用 sc.setLogLevel(newLevel)。 对于 SparkR 用户,请使用 setLogLevel(newLevel)。
欢迎使用
____
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ 版本 3.5.3
/_/
使用 Python 版本 3.8.10 (default, Sep 11 2024 16:02:53)
Spark 环境的 Web UI 可在 http://f01567776a4e:4040 访问。
Spark 上下文 'sc' 可用(master = local[*], app id = local-1734924138281)。
SparkSession 可用为 'spark'。
>>> spark.sql("CREATE NAMESPACE IF NOT EXISTS s3tablesbucket.example_namespace")
数据框[]
>>> spark.sql(
""" CREATE TABLE IF NOT EXISTS s3tablesbucket.example_namespace.`example_table` (
id INT,
name STRING,
value INT
)
USING iceberg """)
数据框[]
>>> spark.sql(
"""
INSERT INTO s3tablesbucket.example_namespace.example_table
VALUES
(1, 'ABC', 100),
(2, 'XYZ', 200)
""")
数据框[]
>>> spark.sql("""
SELECT *
FROM s3tablesbucket.example_namespace.`example_table`
""").show()
查询结果如下:
+---+----+-----+
| id|name|value|
+---+----+-----+
| 1 | ABC| 100 |
| 2 | XYZ| 200 |
+---+----+-----+我终于在本地机器上运行,并成功地远程连接上了我的AWS账户,最终实现了我的目标。
本文中的所有代码都在此 repo 中。包括一个 Makefile,其中包含了所有内容等。
make test 命令会检查你的连接性并上传电影测试数据到你配置的 AWS 账户中的一个测试存储桶。
运行 make spark-test 会执行电影测试任务(也会构建一个新的 Docker 容器,包含所需的 Python 依赖项)。
make spark-int 会启动交互式 pyspark 会话。
运行命令 make spark-s3tables AWS_REGION=us-west-2 将启动一个带有 Iceberg 和 S3 表依赖项的交互式 pyspark 环境,准备好使用。
Makefile 相当于简单粗暴,不适合直接上线等,具体效果因人而异,并且它硬编码了 granted 凭证的设置。但是你可以根据需要轻松地修改它以适应你的环境,通过修改 prepare-env 目标来生成你自己的 .env 文件。
我将更多地介绍S3 Tables,因为我现在可以针对我的用例进行测试了,希望它能尽快在悉尼推出。




