
Note: 这可不是那种骗点击的;它真的超棒,我每天都用。悄悄说

你的可爱本地AI助手,能够提高生产力,生成于 Adobe Firefly.
– 引言
– 设置 Ollama 并拉取 Gemma 2 和 LLaVA 模型
– 利用本地 AI 提升生产力
−− 演示示例:代码审查
−− 演示示例:摘要
−− 演示示例:创建思维导图
−− 演示示例:分析图像
−− AI 脚本,你的小帮手
– 使用 Raycast 提升生产力
– 额外功能:使用 WebUI 进行网络搜索和其他功能
– 结论
简介
早上6点,闹钟响起。你迷迷糊糊地摸向手机,眯着眼睛盯着屏幕。一长串的通知映入眼帘——邮件、Slack消息、新闻更新。这是一堆数字信息,而你还没来得及喝咖啡。

数字过载,来自使用Adobe Firefly生成的文本。
当你滚动浏览无尽的信息流,发现自己被淹没在数据中,努力跟上进度。然后你突然想起昨晚同事发的那条超长Slack消息,当时把它放在稍后阅读里。哎呀,我们肯定都认识这种同事。
说实话,在我的工作中,这完全是我!所以,对我的同事们说,抱歉,希望这篇文章能给你们一些灵感,关于现代AI如何帮助你们应对我的这种冲动,来处理我写Slack文章的冲动。
而且谁知道那堆文字里藏着什么机密信息呢?你不能简单地将其复制粘贴到在线工具;你的公司严格禁止将敏感数据共享给外部服务。但是等等!想象一下:你复制文本,运行一个简单的快捷键,瞬间得到简洁摘要,全程都在你的机器上完成。不用担心隐私、成本或订阅限制。
我记得第一次在我的机器上运行AI模型时,感觉就像魔法一样!突然间,我有了一个免费的强大工具,可以随心所欲地使用。很快,编写这些小工具脚本就成了我的一种瘾头。
这一切都是本地的、安全的,并且在你的掌控之中。这就是本地AI的真正力量。这不仅仅关乎处理信息洪流;更是安全、私密且高效。这不是要取代你的智慧,而是增强你的智慧,在海量信息中提供一线生机,同时保护隐私。
在这篇文章中,我们将跳过炒作,深入探讨本地AI的世界,探索如何使用如Ollama这样的工具以及最先进的模型如Gemma 2和LLaVA来改变你的日常工作流程。我们会向你展示如何将复杂的任务简化为简单高效的流程。释放新的生产力,重新掌控你的数字生活,就像拿回了生活的控制权,同时确保你的敏感数据安全,这一切都发生在你还没有喝第一杯咖啡之前。
配置 Ollama 并下载 Gemma 2 模型和 LLaVA 模型作者注: 这当然是一种夸张了,当然,在喝第一杯咖啡之前,我从不运行任何脚本。好了,让我们正式开始吧!
我们先来准备一下环境。这些指令在macOS 15.2(已安装Homebrew)上测试过,但也可以适应其他系统,所以准备好,你可以从中得到很多灵感。首先,我们首先安装Ollama,启动Ollama服务器端,并用客户端下载Gemma 2和LLaVA模型。
brew install ollama
ollama serve # 启动服务
# 在另一个终端窗口中运行命令
ollama pull gemma2 # 拉取 gemma2
ollama pull llava # 拉取 llavaOllama 让您可以在本地机器上运行强大的 AI 模型,与封闭源代码的云解决方案相比,它不仅提供了更高级的透明度、控制权和个性化。
我必须承认一个缺点是,你需要在本地机器上存储和处理模型。虽然我的 MacBook 足够强大,可以运行 Gemma 2,而且大多数情况下表现得很不错。但是更先进的模型如 Llama 3.3 70B 处理请求会花一些时间。此外,Gemma 2 只需 5.3GB,而 Llama 3.3 占用 43GB 的空间。这意味着在使用 Ollama 进行实验时,你的磁盘很快就会被占满。当我看到 Mac 提示警告时,我感到很惊讶。😅
Ollama 由客户端和服务器两个主要部分组成。客户端是用户交互的界面,而服务器则是用 Go 语言实现的后端服务。
Ollama 包含模型文件,这些文件可以用来创建和分享模型。这些文件包含了重要的信息,比如基础模型、参数、提示模板和系统消息等。默认情况下,这些文件会被保存在 ~/.ollama 目录下。
以下命令保持英文原样,因为它们是技术术语,在中文环境中无需翻译:
tree ~/.ollama/models
du -shc ~/.ollama/models
Ollama 服务器和本地模型资源(作者提供)
我们主要使用了由 Google 开发的 Gemma 2 模型。Gemma 是一组由与 Gemini 模型相同的研究和技术开发的轻量级、前沿开放模型。它们在保证高质量的同时,对资源需求较低,从而实现了性能和资源利用之间的良好平衡。
此外,我们将用到具有火山岛象征意义的 LLaVA(大型语言和视觉助手模型),这是一个经过端到端训练的大型多模态模型,集成了视觉编码器和 Vicuna 语言模型,能够全面理解和处理视觉和语言信息。
金句:用本地 AI 提高生产力敢打个赌,读到这一段的每个人每天至少都会用一回 cmd+c (或 Ctrl+C)和 cmd+v (或 Ctrl+V)来复制和粘贴。
你也可以在 Mac 终端中使用 pbcopy 和 pbpaste 做同样的事情。pbcopy 命令可以让你直接把命令的输出复制到剪贴板。反过来,pbpaste 可以让你直接将剪贴板中的内容粘贴到终端中。
我经常用这个来写一些小的辅助Bash脚本工具。你可以把剪贴板通过管道传递给任何其他命令,例如
pbpaste | cat。这有很多用武之地。
可惜的是,pbcopy 和 pbpaste 命令只能在 Mac 上使用,但在 Linux 上你可以用 xsel 达到类似的效果。
我们将在这几个示例中使用 pbcopy 和 pbpaste。我们还将使用一个名为 glow 的命令工具。Glow 是一个基于终端的 Markdown 阅读器,允许你在命令行上直接阅读文档,可以通过以下方式安装:
使用 Homebrew 安装 glow 工具:
brew install glow这样一来,我们可以释放本地LLM和简单Bash脚本的魔力。
示范:代码审阅示例先注意一下,对于所有演示,请确认你的本地Ollama服务器已经启动并运行着。
启动ollama服务我们可以通过 ollama run <model> <prompt> 命令直接对本地的模型运行提示。
提示:当你把命令的输出通过管道传递给 ollama run 时,它会被追加到提示里。这个功能可以帮你实现很多效率超高的小技巧,接下来我们会带你看看这些技巧。
我们先来看一些代码。我们 cat 一个源文件,然后通过管道传递给 ollama run,接着用 glow 渲染出模型的 Markdown 响应:
cat ~/projects/biasight/biasight/parse.py | ollama 运行 gemma2 命令 "请简洁地审查以下代码并提出改进建议:" | glow -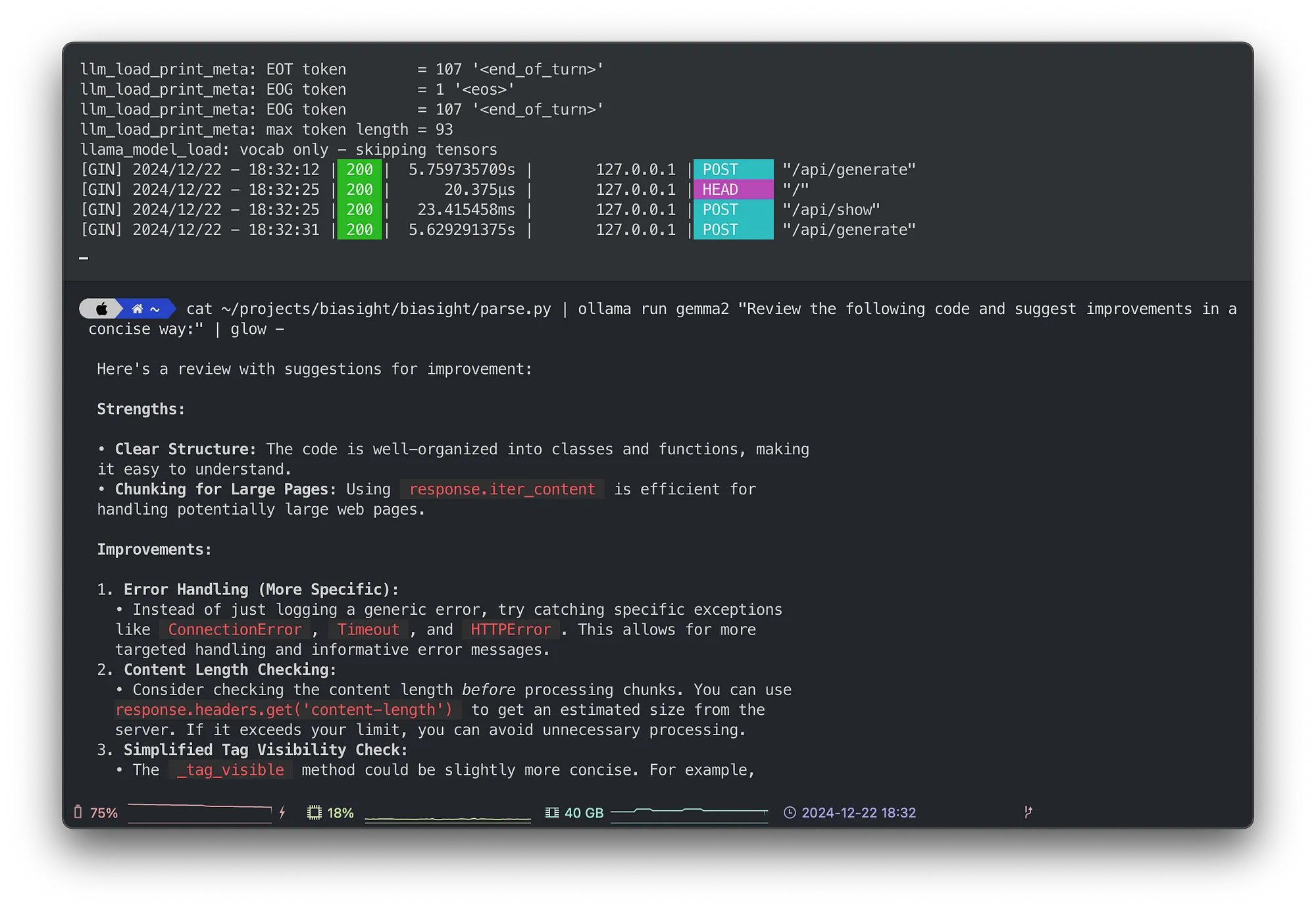
Ollama 服务器演示和代码审查示例,(作者提供)
使用 glow,模型建议的代码片段会有语法着色,即使是内部的关键代码,也能获得即时反馈,而且这些代码永远不会离开你的电脑。你可以免费查看这些机密代码。
当然,审核的质量取决于你选择的模型。尽管Gemma 2通常表现良好,但也有专门用于代码生成的模型,例如基于Gemma 2的CodeGemma模型。实验非常重要;可以去Ollama 模型库看看,那里有所有可用的模型。
示例:概括我们都遇到过这种情况:凌晨1点42分,你在一个包含200条回复的Slack聊天里发现藏有可以防止明天生产事故的关键信息。你不确定里面有没有保密信息,所以你不能直接复制粘贴到你最喜欢的在线LLM上。
使用以下代码段,你可以复制任何文本,例如长的Slack聊天记录,并用本地模型为你做摘要。所有内容都在你的本地机器上处理,流程简单——只需复制并按下回车。
pbpaste | ollama run gemma2 "提供给定文本的简洁全面摘要" | glow -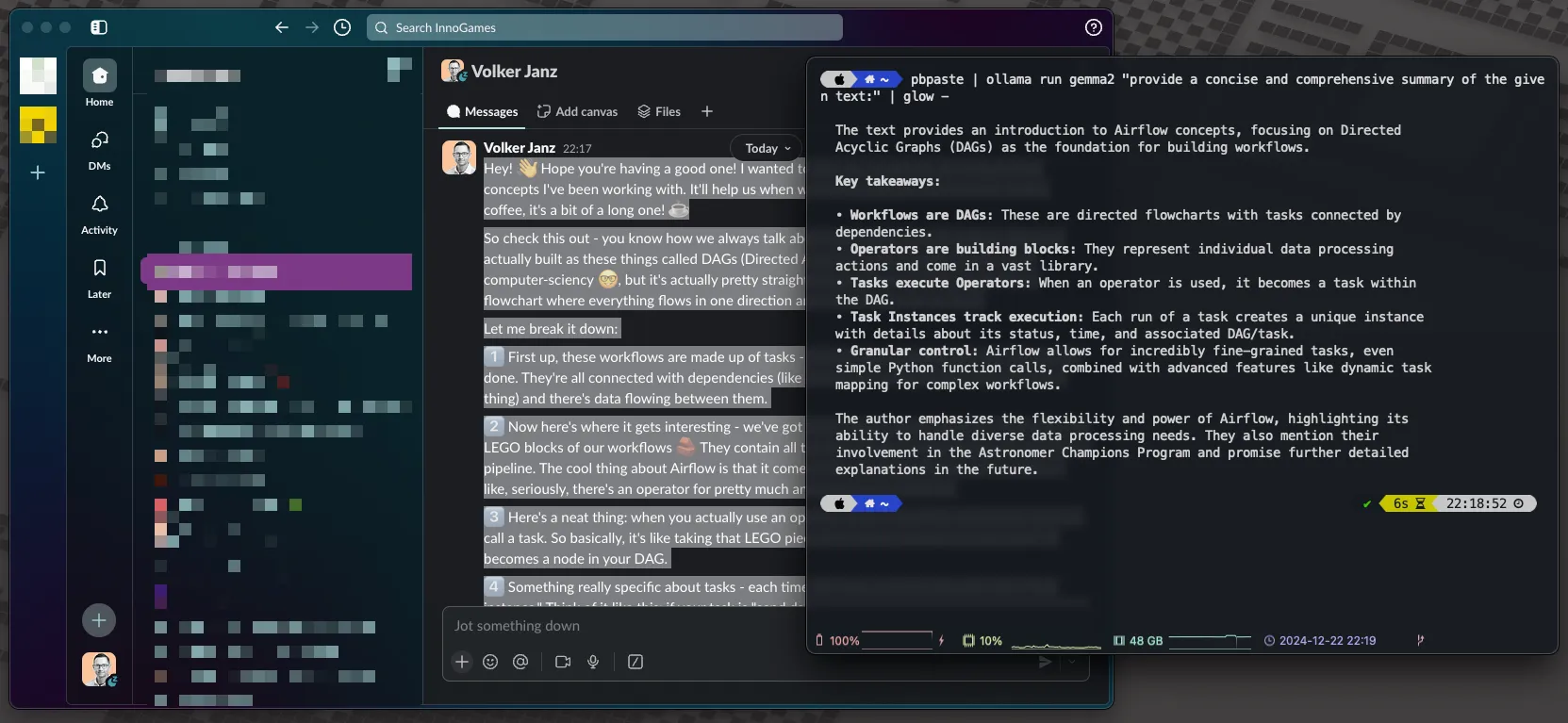
作者写的长 Slack 消息,用 Ollama 概括
示例:绘制思维导图说实话,我不会以这种方式使用这个代码片段,因为直接复制到终端会覆盖剪贴板。首先你需要粘贴这个代码片段,然后复制需要的文本,在终端输入并回车。我重视效率,而这个过程不够高效。相反,我将这个代码片段集成到一个脚本中,并将其绑定到一个快捷键,通过Raycast运行这个快捷键。稍后我会在文章中解释这个方法,所以请继续往下看,还有提高生产力的方法。
简单地说,思维导图是以视觉图表形式呈现的一系列想法。它以中间的一个中心思想或主题开始,从那里延伸出分支,包含进一步探讨的主题和概念,通常用词、短语和图像表示。这种结构让思维导图有了自然的组织流程。
思维导图以放射状而非线性的方式整理信息,这种方式模仿大脑的工作模式。它画出了你的思维,通过关联、连接和触发因素激发更多想法。这种方法让理解复杂信息更简单。
我真的很喜欢通过思维导图来学习。将复杂的文章、书籍和文档转化为思维导图,让它们更易于理解,并且作为以后参考的绝佳工具。
通过以下代码段,我们将本地AI与markmap项目结合使用,该项目可将普通Markdown转换为思维导图。由于LLM在总结和生成Markdown方面表现出色,我们只需在提示中添加一些特殊成分。
使用这个小工具,你可以复制任何复杂的文档、消息或文本,并将其转换为思维导图。思维导图的代码会自动复制到你的剪贴板中。然后,只需将其粘贴到 https://markmap.js.org/repl,你可以看到奇妙的变化。他们还提供了多种集成选择,包括 Obsidian 和 VS Code。
pbpaste | ollama run gemma2 "你是一个专门用于生成思维导图的工具,可以生成与Markmap兼容的Markdown输出。你的任务是分析提供的文本,并使用Markdown语法创建一个分层的思维导图结构。
生成思维导图的规则:
1. 使用Markdown标题(##, ###等)为主要主题和子主题
2. 使用项目符号(-)为主题下的细节列表
3. 保持从一般到具体的清晰层级结构
4. 保持条目简洁且有意义
5. 包含源文本中的所有相关信息
6. 对于:
- 链接:[文本](https://medium.com/URL)
- 强调:**加粗**,*斜体*
- 代码:\`内联代码\` 或使用\`\`\`的代码块
- 在需要时使用表格
- 根据需要使用项目符号和编号列表
7. 对主要主题始终使用适当的表情符号,如果合适,也可以为子主题添加表情符号
示例格式:
## 📋 项目概述
### 主要功能
- 功能1
- 功能2
请为这段文本生成一个与Markmap兼容的思维导图:"
| LC_ALL=en_US.UTF-8 pbcopy为了展示这个代码片段,我们使用了我的非常尊敬的同事Data Engineer Yaakov Bressler写的一篇文章:
Pydantic 高手指南:复用和导入验证器:在 Python 模型间共享验证技巧.blog.det.life- 首先,我们将代码片段粘贴到终端窗口但先不提交。
- 然后,我们选择整篇文章(cmd+a)并复制它(cmd+c)。
- 接下来,在终端窗口中按下回车键提交代码片段。
- 让AI本地施展魔力。
- 当完成时,结果会自动出现在剪贴板中,我们可以粘贴(cmd+v)到https://markmap.js.org/repl。
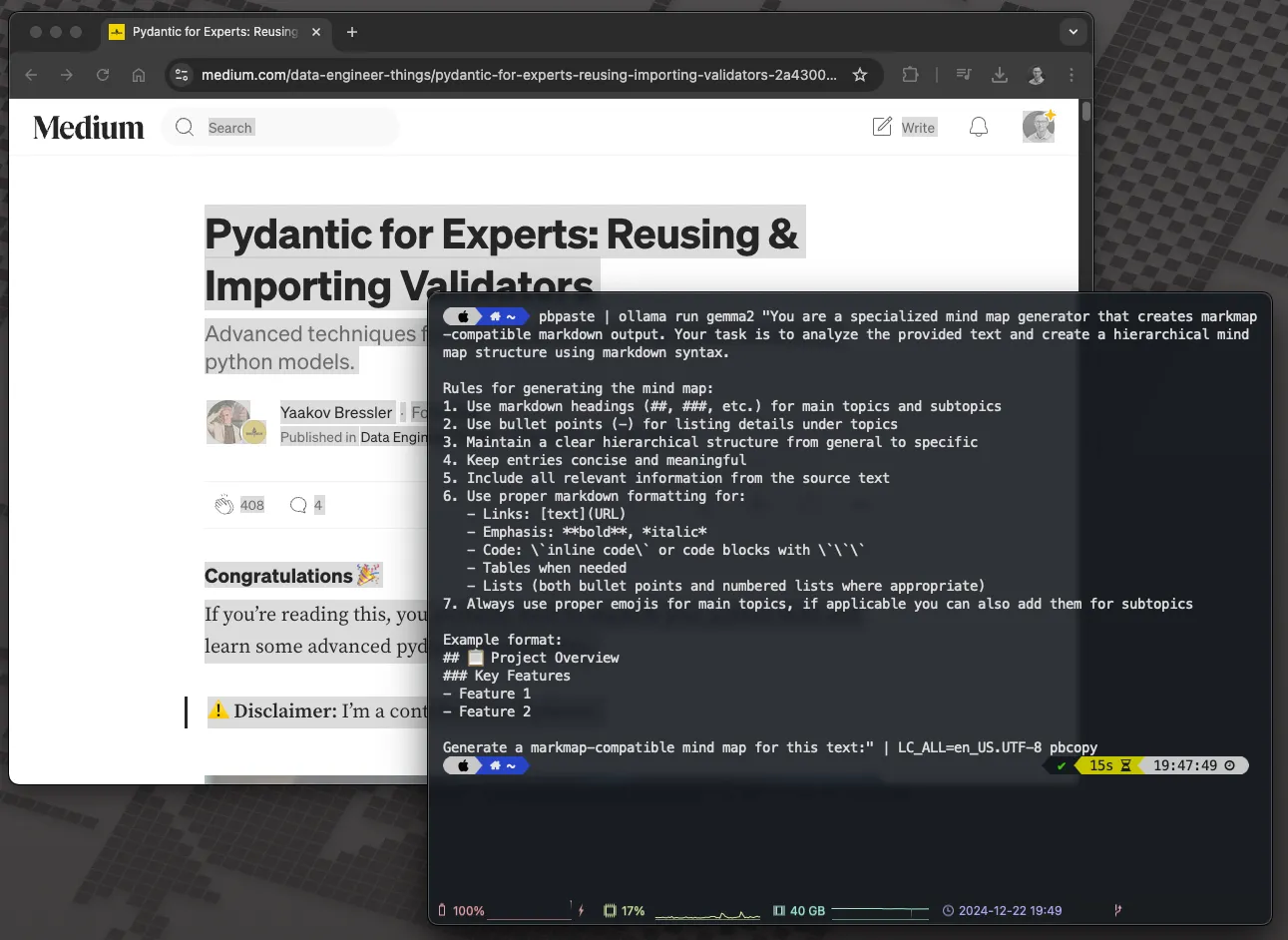
基于文章生成 Markdown 格式的思维导图,来源是作者的文稿。
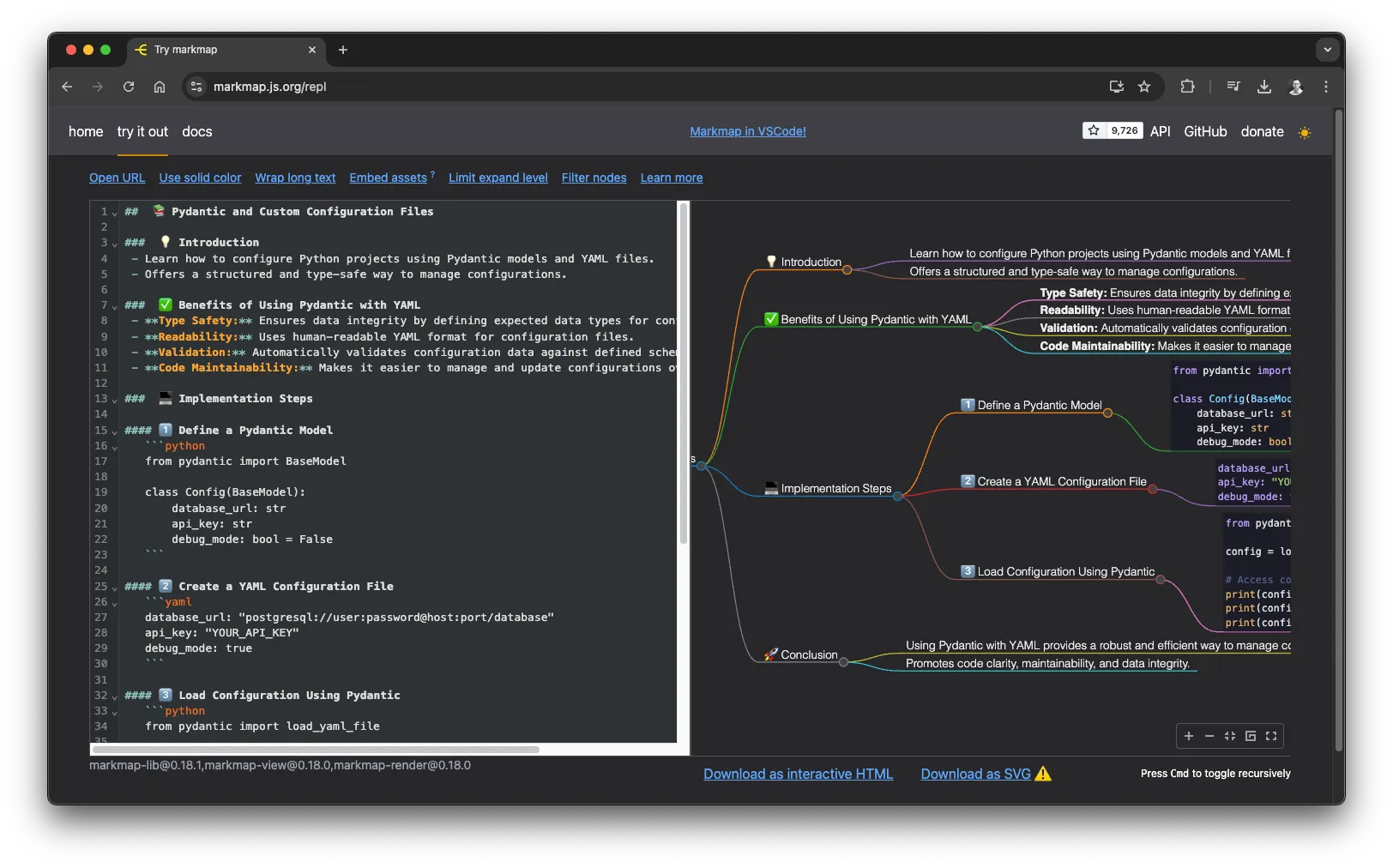
使用脑图工具Markmap制作的思维导图,作者提供。
结果就是这样的:
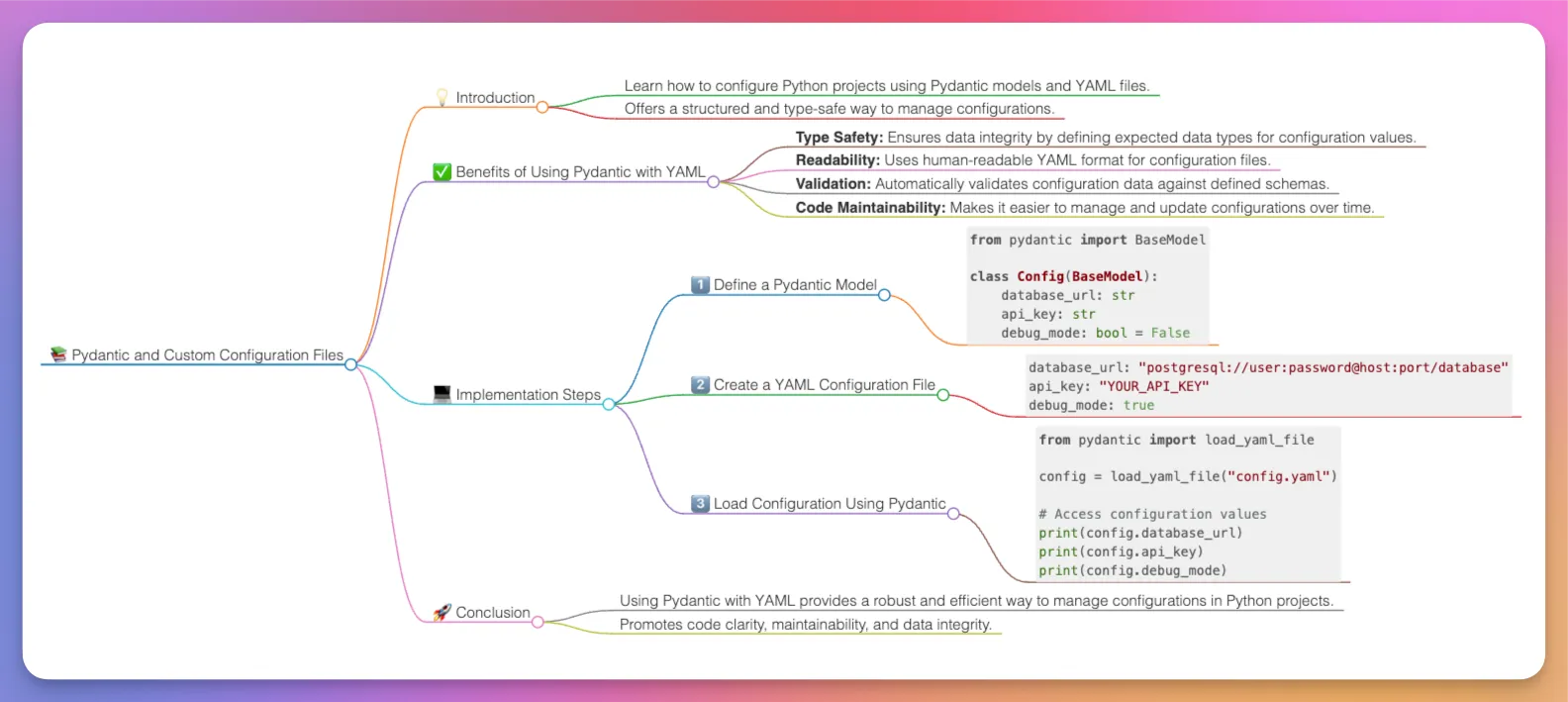
AI 生成的思维地图,来源:作者
想象你在阅读这篇文章,并且有一个思维导图作为以后的参考,你的学习过程可以变得更加高效,简直就像是开了挂。
请记住,思维导图之所以如此有用的一个重要原因在于,创建过程需要你将复杂的信息提炼成几个要点,并按逻辑顺序连接起来。这个创造性的过程在内化和理解信息方面扮演了至关重要的角色,例如从雅科夫(Yaakov)这样的文章中学到的东西。当你让AI为你生成内容时,这个好处就会完全丧失。我个人发现,AI生成的思维导图最适用于参考工具。我在探索一篇文章或文档之后创建它们,以便有一个快速参考,帮助我以后回忆起内容。学习是一个个人化的进程,所以找到最适合你的学习方法。然而,不要忽视AI,它可以显著提高你的学习效率和生产力。
此外,因为所有内容都是本地运行的,你可以用来制作项目文档或相关概念的概念图,例如。
示例:分析图片这只是个小演示,额外展示一下,展示你可以在本地使用多模态AI。这可能有助于让AI帮助你管理照片,而无需上传到云端,保持所有内容都在本地。如果你有一个支持这种功能的模型,你只需在提示中添加一个指向本地图片的路径,Ollama会自动将图片路径传递给模型。
我建议使用完整的路径来指定图片文件。我发现使用相对路径时经常会出问题。如果图片未找到,Ollama 将不会发出任何警告,而是继续生成其他东西,这可能会特别令人沮丧。当你这样做的时候,确保输出显示 Added image … ,以确认确实使用了图片文件。
让我们来看看这张有趣的猫的图片。

照片由 Ernesto Carrazana 在 Unsplash 拍摄。
ollama 和 llava "描述这张图片的内容, ./funny-cat.jpg" | glow -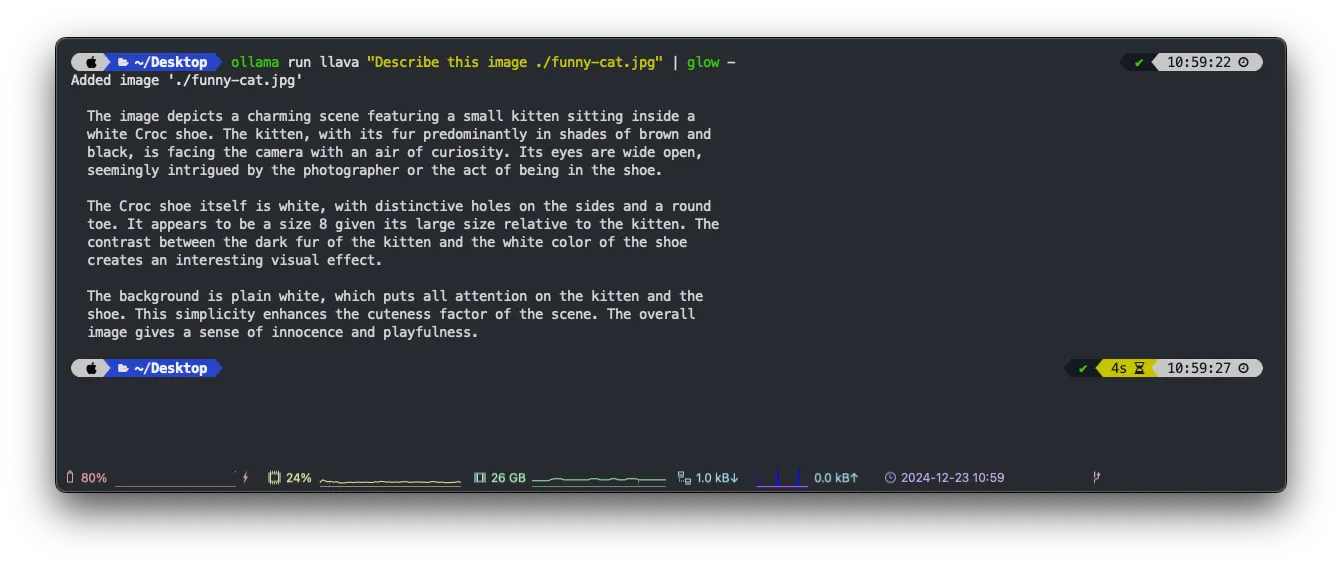
本地AI生成的图像概要,来源:作者
AI小助手,你每天的小帮手我发现这在处理结构化输出时特别有用。自2024年12月以来,Ollama支持结构化输出。此功能允许你编写脚本来分析图像,并确保LLM始终返回一个结构合理的对象。例如,你可以识别主色调、物体或图像类别。这种能力可以帮助你创建一个有用的应用程序来管理图像。尽管存在性能限制,它仍然可以是一个有趣的自学项目。
如前所述,复制粘贴这些片段可能不是最高效的工作流程。在本文中,我们旨在提高效率。不如我们创建一些 Bash 脚本来作为日常的 AI 助手如何?
我们将以摘要演示为例,但你可以轻松地将这种方式适应到其他代码片段。
首先,在你的家目录下新建一个脚本文件夹:
mkdir ~/bin # 在你的家目录下创建一个名为bin的文件夹接下来,创建你的脚本文件并确保它可执行。
touch ~/bin/ai-摘要
chmod +x ~/bin/ai-摘要添加一个名为 ai-摘要 的可执行文件到 ~/bin 目录,并授予其执行权限。chmod +x 命令用于授予文件执行权限。
用你最喜欢的编辑器打开它就可以了。
vim ~/bin/ai-summarize # 编辑AI摘要脚本然后,将其作为 Bash 脚本添加。
#!/bin/bash
MODEL=gemma2 # 这里设置模型为gemma2
echo "正在总结剪贴板中的内容..."
pbpaste | ollama run ${MODEL} "对给定文本提供简洁而全面的摘要:" | glow -最后,将脚本文件夹添加到您的路径中。在您的 home 目录中,并在 ~/.zshrc 文件中添加以下行以完成设置。
export PATH="$PATH:/Users/vojay/bin"现在,如果你打开一个新的终端窗口或重新加载配置文件,你就可以在任何地方执行这条新命令了。
你现在可以复制任何文本内容,然后在终端输入 ai-summarize,即可得到简洁的摘要。
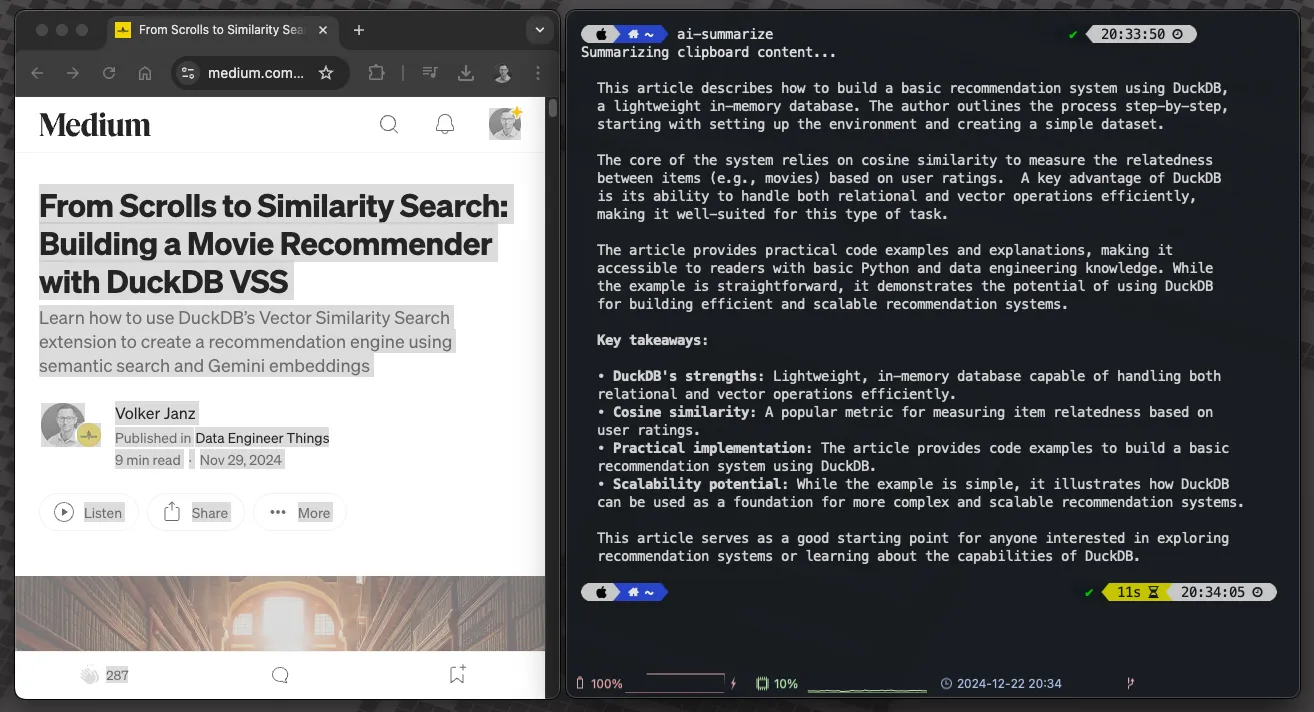
使用辅助脚本(helper脚本)来运行本地AI任务(作者提供)
要提高下一阶段的生产力,用 Raycast 让你的工作更上一层楼Raycast 可以说是 Spotlight 的升级版——它不仅能够查找文件,而是一个功能更强大的 Mac 启动器,不仅可以管理日历,还能控制 Spotify 等等,这一切都可以通过这个极简的启动器完成。
虽然 Raycast 的 Pro 计划自带 AI 功能,但我们也可以用他们免费的脚本命令来使用本地的 AI。有了 Ollama 在本地运行,谁还真的需要订阅啊?😉 认真说,我觉得 Raycast 项目真的很棒。Pro 功能很赞,团队也值得支持,所以我选择了订阅,个人觉得绝对物有所值!
魔法发生得通过Raycast的脚本命令。你可以创建Raycast可以执行的自定义脚本,这些脚本可以用多种语言编写,包括Bash。让我们把我们的AI助手脚本与Raycast集成起来。
- 打开Raycast设置界面
- 导航到扩展 → 脚本命令
- 添加脚本目录(例如
~/bin)
现在你可以直接通过Raycast平台启动你的AI工作流。例如,你可以:
- 打开 Raycast
- 在命令行中输入 summarize 来运行你的总结脚本
- 你剪贴板中的文本将由你本地的 Gemma 2 模型处理
- 立即获得结果,同时保持你的数据私密
小提示:你可以为最常用的AI命令自定义快捷键。我常用 cmd+shift+s 来总结内容的总结,用 cmd+shift+m 来制作思维导图。
本地AI与Raycast结合,创建了一个强大、私密且免费的高效系统。无需在浏览器中打开新标签页,你的数据也不会离开你的设备,也不需要订阅。只需享受纯粹的键盘操作高效体验。
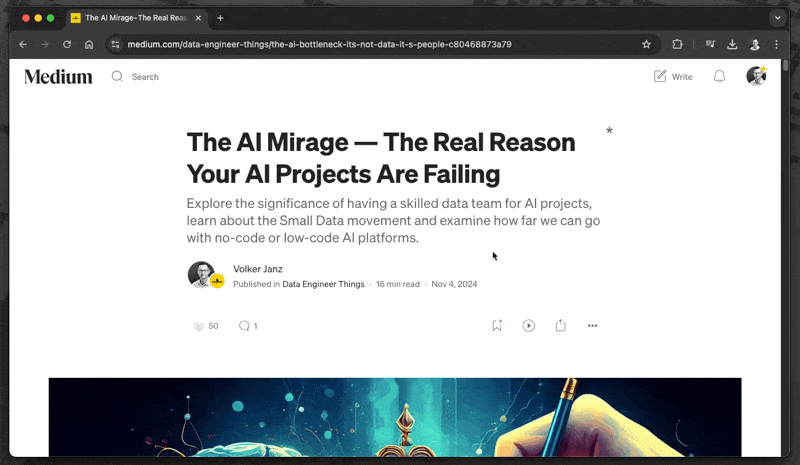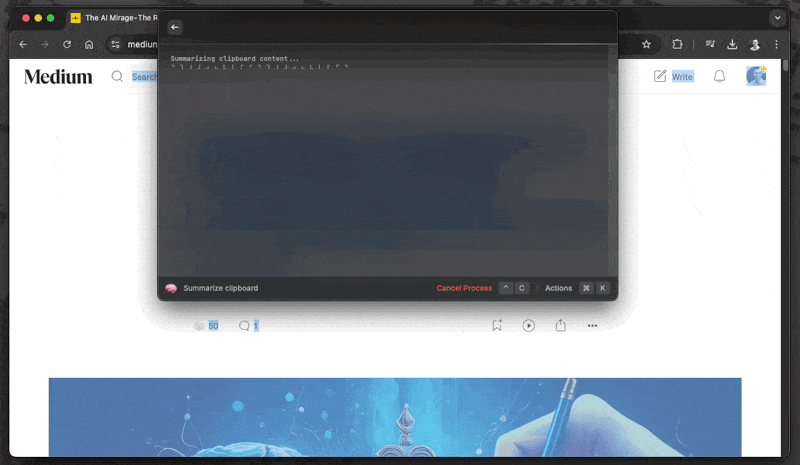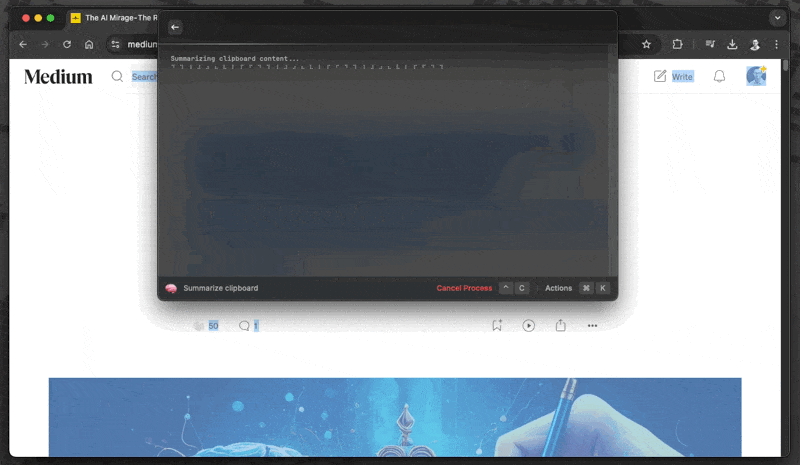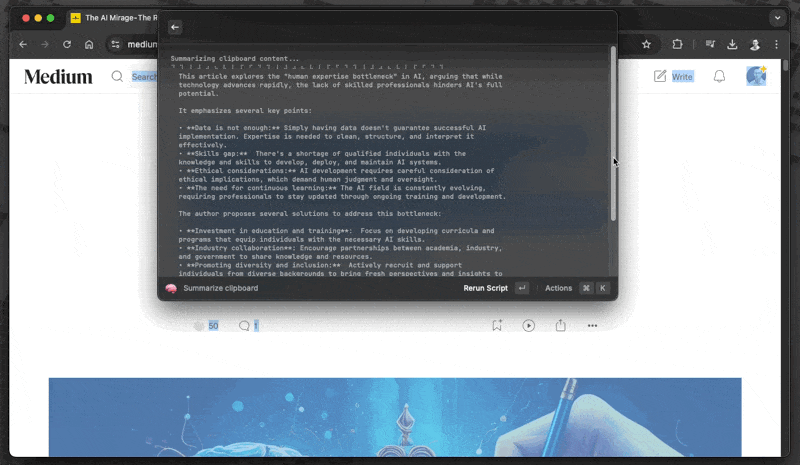
Raycase 示例,由作者提供
额外功能:支持网络搜索等功能的WebUI这值得单独写一篇文章,但如果你读到这一部分,这是一步非常强大的发现,值得一试。Open WebUI 是一个开源的 Web 用户界面,完全离线操作,可扩展、功能丰富且用户友好。它支持各种大型语言模型(LLM)运行器,包括 Ollama。
我们可以用Docker启动Open WebUI。启动之前,请确保你的Ollama服务器已经在运行 ollama serve。
# 启动并运行open-webui容器
docker run -d -p 3000:8080 # 映射端口3000到容器内的8080 -e WEBUI_AUTH=False # 设置WEBUI_AUTH环境变量为False -e OLLAMA_BASE_URL=http://host.docker.internal:11434 # 设置OLLAMA_BASE_URL环境变量为http://host.docker.internal:11434 -v open-webui:/app/backend/data # 挂载卷open-webui到容器内的/app/backend/data路径 --name open-webui ghcr.io/open-webui/open-webui:main # 使用ghcr.io/open-webui/open-webui:main镜像下面来拆解一下发生了什么
--rm: 在容器停止时自动删除容器,保持整洁。-d: 以“分离”模式(在后台)运行,这样你就可以继续使用终端。-p 3000:8080: 将你 Mac 上的 3000 端口映射到容器内的 8080 端口(这是你访问 UI 的方式)。-e WEBUI_AUTH=False: 禁用 Open WebUI 的身份验证,适合本地使用,但在生产环境中请注意。-e OLLAMA_BASE_URL=http://host.docker.internal:11434: 这是将 Docker 内的 Open WebUI 与你的 Mac 上的 Ollama 服务器相连的关键配置。-v open-webui:/app/backend/data: 创建一个卷来保存聊天记录和设置。--name open-webui: 给容器起一个友好的名字。ghcr.io/open-webui/open-webui:main: 来自 GitHub 的 Open WebUI 最新版本。
小技巧:
host.docker.internal是 Docker Desktop for Mac 的一个特殊功能,允许容器与运行在你 Mac 上的服务进行通信。这里host.docker.internal是一个特殊的标识符,它使得容器能够与你 Mac 上的服务进行通信。这就像给你的 Docker 容器提供了一个秘密通道,从而连接到你本地的 Ollama 服务器!
运行此命令后,您自己的个人AI聊天,拥有许多高级功能,全部本地免费运行,并可通过http://localhost:8080/访问它。您可以在左上角从所有通过Ollama拉取的模型中进行选择。
打开WebUI,享受自己的本地AI聊天功能,作者:某某。
结论部分如果你不想麻烦地设置 Open WebUI,而你使用的是 macOS,可以考虑一个很棒且实用的替代方案叫作 Enchanted。这款开源工具与 Ollama 配套使用。可以直接在 App Store 下载,使其成为轻量级启动的好选择。
还记得6点的情景吗?信息如洪水般涌来,长长的消息在Slack上,还有急切想要第一杯咖啡?现在是时候给这个场景一个不同的结局了。
没错,还是先拿咖啡,有些事情连AI也替代不了!
通过这段旅程,我们发现本地AI如何可以改变我们的日常工作流程。从即时代码审查到神奇的思维导图,再到文章总结和图像分析——所有这些都在确保我们的敏感信息安全并处于我们控制之下。
但最令人兴奋的可能不是这些工具能做什么,而是你能够用它们做什么。我们制作的小脚本只是个开始。当你发现自己在重复任务时,记得:可能已经有现成的本地AI解决方案等着你去开发。
我从简单的脚本开始,很快发现自己构建了一个完整的AI工具生态系统。这就像拥有一个超级好用的命令行界面,它真的能理解你的需求。
所以,下一步是什么?那就要看你的了。工具掌握在你手中,模型已经在你的机器上了,可能性无穷无尽。也许你会打造出那个完美的工作流程,每周能帮你团队节省几个小时。或者,你可能会创造一些我们甚至都想不到的新东西。
现在,如果你们允许我先告退一下,我得写一些 Slack 的文章……但现在别担心,同事们现在都有办法处理了!😉
喜欢这篇文章吗?🫶最后一提:你打算怎么在工作中使用本地AI呢?这些演示是否激发了你创造自己的生产力小技巧?在下面的评论中分享你的想法和实验吧——我很想看看你如何用本地AI改变日常任务!如果你已经在用Ollama做创新的事情,不妨和全世界分享一下。毕竟,最实用的生产力建议通常都是来自社区的。
- 👏 如果你觉得这篇文章有价值,请给它点赞(你可以点赞最多50次!)
- 💭 在下方评论区分享你的想法——我很想听听你的想法
-
✨ 高亮你最喜欢的部分,方便以后查看
🙏你的参与对我来说非常重要,能让这份内容被更多人看到。





