

在我的上一篇文章中,我讨论了大型语言模型(LLMs)的基本微调方法及其使用 Apple MLX 框架的具体用例,包括如何构建自定义版本的 LLM。在另一篇文章中,我讨论了使用 LLM 微调进行医学诊断预测的应用。在这篇文章中,我将探索 LLM 微调在网络安全领域高级预测任务的应用。具体而言,我提出了一种使用微调的 LLM 实时检测网络中攻击的机制。在这里,我使用了一个包含恶意和良性数据包的网络PCAP 数据集微调了 mistralai/Mistral-7B-Instruct-v0.2 模型。通过此数据集训练 mistralai/Mistral-7B-Instruct-v0.2 模型,模型学会了预测实时网络数据(例如 PCAP 数据)中的异常。微调过程是在配备了 M2 芯片的苹果硅 Mac 上使用 LoRA 和 Apple MLX 框架完成的。在微调之后,这些自定义模型使用 [Ollama](https://ollama.com/) 进行部署和运行。所有与此文章相关的源代码已发布在 GitLab。请克隆仓库以继续了解本文的内容。
微调是指调整预训练的大规模语言模型(LLM)的参数或权重的过程,以使其专用于特定的任务或领域。虽然像GPT这样的预训练语言模型拥有广泛的通用语言知识,但它们在特定专业领域中往往缺乏专业性。微调通过在特定领域数据上的训练来解决这一问题,从而提高其在特定应用中的准确性和有效性。这一过程涉及将模型暴露于任务特定示例中,使其能够更好地理解领域的细微差别。这一关键步骤将通用语言模型转化为专业工具,从而释放LLM在特定领域或应用中的潜力。然而,微调LLM需要大量的计算资源,例如GPU,以确保高效训练。
有多种大规模语言模型(LLM)微调技术可供选择,包括低秩适配器(LoRA)、量化低秩适配器(QLoRA)、参数高效微调(PEFT)、DeepSpeed 和 ZeRO。有关 LLM 微调的更多信息,请参阅此链接:此处。在这篇文章中,我将讨论在 Apple MLX 框架中使用 LoRA 技术对大规模语言模型进行微调的过程。LoRA 于 2021 年由微软的研究团队首次提出的论文中,它提供了一种参数高效的微调方法。与传统方法相比,传统方法需要对整个基础模型进行微调,这可能会非常耗时且成本高昂,LoRA 只添加少量可训练参数,而无需解冻原始模型参数,同时保持原有模型参数的不变。
LoRA 的核心在于向模型中添加适配器层,从而提高其效率和适应性。LoRA 并不是引入全新的层,而是通过利用低秩矩阵来修改现有层的行为。这种方法只引入了少量的额外参数,与完全重新训练模型相比,显著减少了计算成本和内存使用。通过将适应集中在特定的模型组件上,LoRA 保留了原始权重中的基本知识,从而降低了灾难性遗忘的风险。这种定向调整不仅保持了模型的通用能力,还使其能够快速迭代并针对特定任务进行增强,使 LoRA 成为微调大规模预训练模型的灵活且可扩展的解决方案。有关 LoRA 和示例的更多信息,请阅读 此处。
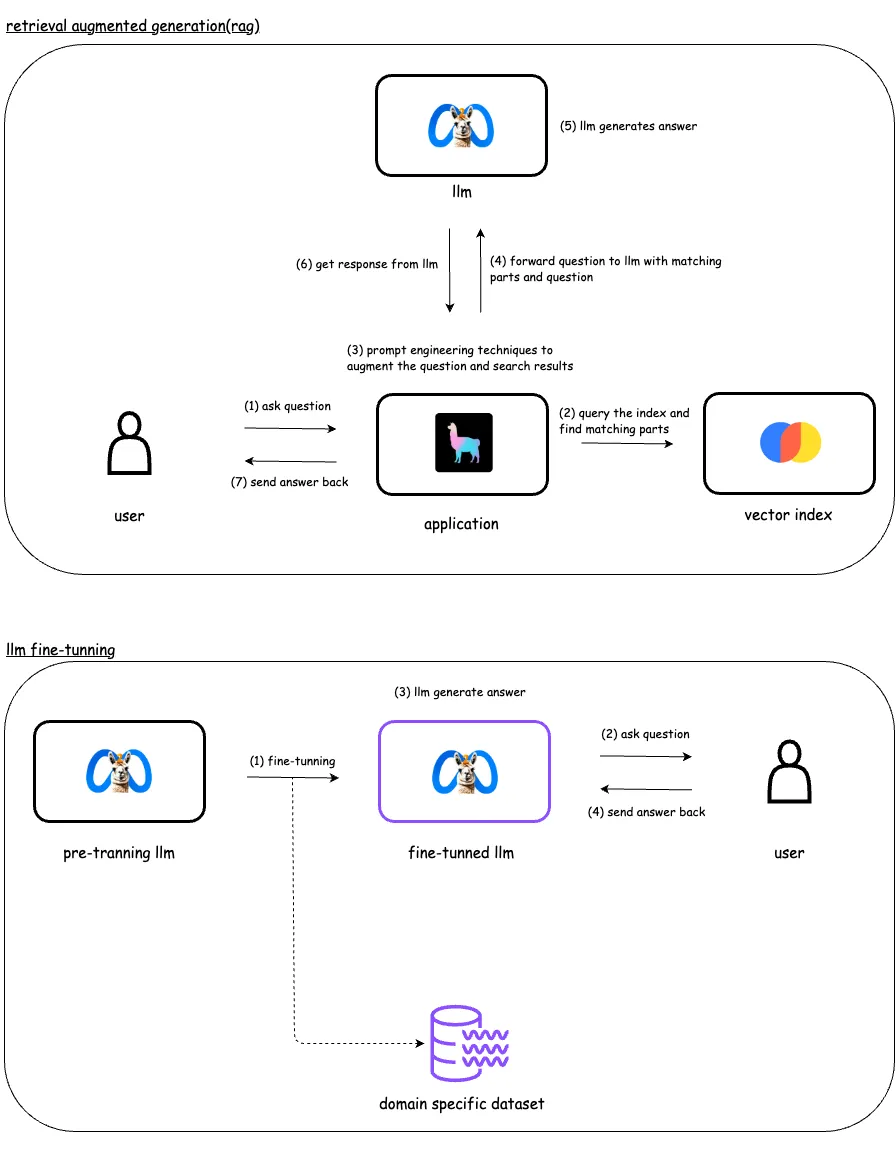
3. RAG vs LLM 对比RAG(检索增强生成)通过提供访问一个精心整理的数据库的权限,来增强大型语言模型的能力,使其能够根据需要动态检索相关的信息来生成响应。相比之下,微调则是通过在特定标注的数据集上训练来调整模型的参数,从而提升其在特定任务上的表现。微调则是直接修改模型本身,而RAG则增加了模型可以访问的数据来源。
当您需要为语言模型的提示添加其初始训练时没有的数据时,请使用RAG。这可以包括实时数据、特定用户的资料或与提示相关的上下文信息。RAG非常适合确保模型能够访问最新的和最相关的数据。相比之下,微调更适合训练模型以更准确地理解和执行特定任务。要了解用例以及如何在RAG和微调之间进行选择,请阅读这篇文章。
一直以来,人们认为机器学习的训练和推理只能在英伟达的 GPU 设备上进行。然而,随着 MLX 的发布,这种看法发生了变化。这种框架类似于 TensorFlow 和 PyTorch,支持基于 GPU 的任务。该库允许在新的苹果 M 系列芯片上对大规模语言模型 (LLM) 进行微调。此外,MLX 支持使用 LoRA 方法对该方法进行大规模语言模型的微调。我已经成功地用 MLX 和 LoRA 微调了多个大规模语言模型,包括 Llama-3 和 Mistral 等。
这篇文章里,我将探讨使用大型语言模型(LLM)进行实时网络攻击检测的一个更高级的应用。这里,我将对模型进行微调 mistralai/Mistral-7B-Instruct-v0.2,使用一个包含恶意和正常的数据包的PCAP数据集。通过用该数据集训练,该模型学会预测实时网络流量数据(比如PCAP数据)中的异常情况。
首先,我需要安装MLX以及一组必需的工具。以下是已安装的工具列表,以及我配置MLX环境的方式和设置。
# 步骤:克隆名为mlxa的仓库
❯❯ git clone https://gitlab.com/rahasak-labs/mlxa.git
❯❯ cd mlxa
# 创建并激活虚拟环境
❯❯ python -m venv .venv
❯❯ source .venv/bin/activate
# 安装mlx-lm
❯❯ pip install -U mlx-lm
# 安装其他所需的Python包,比如
❯❯ pip install pandas
❯❯ pip install pyarrow我在从Hugging Face获取大型语言模型(大模型)和数据集。为此,我需要在Hugging Face上注册一个账户并配置huggingface-cli命令行工具。
# 在 Hugging Face 上设置账户,请点击这里
https://huggingface.co/welcome
# 创建访问令牌以通过 Hugging Face 命令行读取/写入数据
# 此令牌在登录 Hugging Face 命令行时需要
https://huggingface.co/settings/tokens
# 设置 Hugging Face CLI
❯❯ pip install huggingface_hub
❯❯ pip install "huggingface_hub[cli]"
# 通过命令行登录 Hugging Face
# 会要求输入之前创建的访问令牌
❯❯ huggingface-cli login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
您机器上已经保存了一个令牌。运行 `huggingface-cli whoami` 查看更多信息,或者使用 `huggingface-cli logout` 注销。
设置新令牌将替换现有令牌。
`huggingface_hub` 需要从 https://huggingface.co/settings/tokens 生成的令牌来进行登录。
请输入令牌(输入内容不会显示):
是否将令牌添加为 git 凭证? (Y/n) [Y]
令牌有效(权限:读取)。
您的令牌已保存在您的 git 凭证管理器(osxkeychain)中。
您的令牌已保存在 /Users/lambda.eranga/.cache/huggingface/token 文件中
登录成功
# 登录成功后,令牌将保存在 ~/.cache/huggingface 文件夹中
❯❯ ls ~/.cache/huggingface
datasets
hub
tokenMLX需要数据处于特定格式。MLX中讨论了三种主要格式:chat,completion和text。您可以在这里了解更多关于这些数据格式的信息here。对于这个用例,我将使用completion格式的数据,这种格式将prompt和completion结合成一个自然语言短语。这种格式需要包括prompt(输入给LLM的内容)和completion(LLM的响应)。数据集的生成在LLM的微调中起着关键作用,因为它直接影响微调模型的准确性。可以采用多种技术来生成用于微调LLM的数据集。例如,这篇文章介绍了如何使用LLM和提示工程技术来生成数据集。
原始的数据集是一个 .csv 文件。为了对 Apple MLX 进行微调,我将其转换成了 completion 格式。每个记录包含 prompt 和 completion,形成一个连贯的短语。以下是原始 PCAP CSV 数据和转换后的 completion 格式。
{"prompt": "您是一位网络流量分类专家。根据提供的网络流量属性,您必须确定流量是正常还是异常。以下是属性,'源IP地址:192.168.100.103,源端口号:34293,网络协议:TCP,连接时长:2.998556,连接状态:S0,丢失字节:0,从源到目的端口的数据包数:3,从源到目的端口的IP字节数:180,从目的端口到源的数据包数:0,从目的端口到源的IP字节数:0'。", "completion": "异常的网络流量"}
{"prompt": "您是一位网络流量分类专家。根据提供的网络流量属性,您必须确定流量是正常还是异常。以下是属性,'源IP地址:192.168.100.103,源端口号:41106,网络协议:TCP,连接时长:2.998779,连接状态:S0,丢失字节:0,从源到目的端口的数据包数:3,从源到目的端口的IP字节数:180,从目的端口到源的数据包数:0,从目的端口到源的IP字节数:0'。", "completion": "异常的网络流量"}
{"prompt": "您是一位网络流量分类专家。根据提供的网络流量属性,您必须确定流量是正常还是异常。以下是属性,'源IP地址:192.168.100.103,源端口号:45986,网络协议:TCP,连接时长:2.998807,连接状态:S0,丢失字节:0,从源到目的端口的数据包数:3,从源到目的端口的IP字节数:180,从目的端口到源的数据包数:0,从目的端口到源的IP字节数:0'。", "completion": "异常的网络流量"}
{"prompt": "您是一位网络流量分类专家。根据提供的网络流量属性,您必须确定流量是正常还是异常。以下是属性,'源IP地址:192.168.100.1,源端口号:3,网络协议:ICMP,连接时长:1.999924,连接状态:OTH,丢失字节:0,从源到目的端口的数据包数:2,从源到目的端口的IP字节数:136,从目的端口到源的数据包数:0,从目的端口到源的IP字节数:0'。", "completion": "正常的网络流量"}
{"prompt": "您是一位网络流量分类专家。根据提供的网络流量属性,您必须确定流量是正常还是异常。以下是属性,'源IP地址:192.168.100.103,源端口号:51216,网络协议:TCP,连接时长:2.999077,连接状态:S0,丢失字节:0,从源到目的端口的数据包数:3,从源到目的端口的IP字节数:180,从目的端口到源的数据包数:0,从目的端口到源的IP字节数:0'。", "completion": "异常的网络流量"}
{"prompt": "您是一位网络流量分类专家。根据提供的网络流量属性,您必须确定流量是正常还是异常。以下是属性,'源IP地址:192.168.100.103,源端口号:51022,网络协议:TCP,连接时长:2.999300,连接状态:S0,丢失字节:0,从源到目的端口的数据包数:3,从源到目的端口的IP字节数:180,从目的端口到源的数据包数:0,从目的端口到源的IP字节数:0'。", "completion": "异常的网络流量"}MLX 需要用于微调的三个数据集分别是 train、test 和 valid。数据文件需要以 [JSONL](https://jsonlines.org/) 格式提供。下面的脚本会将 CSV 文件中的 PCAP 数据转换成 JSONL 格式。在转换过程中,脚本会合并 PCAP 数据属性,并生成一个 prompt,即一个自然语言短语。根据 CSV 记录中的标签字段生成完成字段。
import pandas as pd
import json
import random
# 读取CSV文件
csv_file_path = "pcap-labeled.csv"
pcap_data = pd.read_csv(csv_file_path, delimiter="|")
# 准备JSONL文件内容
jsonl_data = []
# 需要检查的字段
fields_to_check = [
'id.orig_p',
'proto', 'conn_state',
'duration', 'missed_bytes',
'orig_pkts', 'resp_pkts',
'orig_ip_bytes', 'resp_ip_bytes'
]
for _, row in pcap_data.iterrows():
# 跳过任何指定字段值为'-'的行
if any(row[field] == '-' for field in fields_to_check):
continue
# 构建标签
label = "异常流量" if row['label'] == "恶意" else "正常流量"
# 创建JSONL记录
record = {
"prompt": (
f"您是一名网络流量分类专家。请注意,以下是属性:\n"
f"'源IP地址:{row['id.orig_h']},源端口:{row['id.orig_p']},\n"
f"网络协议类型:{row['proto']},\n"
f"连接持续时间:{row['duration']},\n"
f"连接状态:{row['conn_state']},\n"
f"丢失字节数:{row['missed_bytes']},从源到目的地的数据包数:{row['orig_pkts']},\n"
f"从源到目的地的IP数据字节数:{row['orig_ip_bytes']},从目的地到源的数据包数:{row['resp_pkts']},\n"
f"从目的地到源的IP数据字节数:{row['resp_ip_bytes']}'."
),
"completion": f"{label}网络流量,"
}
jsonl_data.append(record)
# 打乱数据
random.shuffle(jsonl_data)
# 计算2/3训练数据和1/3测试数据的分割点
train_split = int(len(jsonl_data) * 7 / 10)
# 拆分数据
train_data = jsonl_data[:train_split]
test_data = jsonl_data[train_split:]
# 保存训练数据文件train.jsonl
train_file_path = 'train.jsonl'
with open(train_file_path, 'w', encoding='utf-8') as train_file:
for entry in train_data:
train_file.write(json.dumps(entry) + '\n')
# 保存测试数据文件test.jsonl
test_file_path = 'test.jsonl'
with open(test_file_path, 'w', encoding='utf-8') as test_file:
for entry in test_data:
test_file.write(json.dumps(entry) + '\n')
# 保存验证数据文件valid.jsonl
valid_file_path = 'valid.jsonl'
with open(valid_file_path, 'w', encoding='utf-8') as valid_file:
for entry in test_data:
valid_file.write(json.dumps(entry) + '\n')我已经将数据集放置在了 data 目录中。然后,我运行了脚本来生成 train、test 和 valid 数据集的 JSONL 格式文件。下面展示的是生成的数据文件结构。
# 激活虚拟环境
❯❯ source .venv/bin/activate
# 数据目录
❯❯ ls -l data
prepare.py
s2d.csv
# 生成 JSONL 文件
❯❯ cd data
❯❯ python prepare.py
# 生成的文件
❯❯ ls -ls
test.jsonl
train.jsonl
valid.jsonl
# train JSONL
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:33037,网络协议:TCP,连接时长:2.998781秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:45506,网络协议:TCP,连接时长:2.998830秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:39972,网络协议:TCP,连接时长:2.998819秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:40262,网络协议:TCP,连接时长:2.998574秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:60633,网络协议:TCP,连接时长:2.999060秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
# test JSONL
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:55520,网络协议:TCP,连接时长:2.998521秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:45461,网络协议:TCP,连接时长:2.998792秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:37168,网络协议:TCP,连接时长:2.998772秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "正常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:60316,网络协议:TCP,连接时长:2.998572秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:53036,网络协议:TCP,连接时长:2.998555秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
# valid JSONL
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:46557,网络协议:TCP,连接时长:2.998811秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:47863,网络协议:TCP,连接时长:2.998817秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:38867,网络协议:TCP,连接时长:2.998996秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:54329,网络协议:TCP,连接时长:2.998824秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}
{"prompt": "您是网络流量分类方面的专家。根据提供的网络流量属性,您需要确定该流量是否正常。'源IP地址:192.168.100.103,源端口号:60526,网络协议:TCP,连接时长:2.999080秒,连接状态:S0(空闲),丢失的字节数:0,从源到目标发送的数据包数:3,从源到目标发送的IP点对点字节数:180,从目标到源发送的数据包数:0,从目标到源发送的IP点对点字节数:0'。", "completion": "异常流量"}下一步是使用我之前准备的数据集,通过MLX对Mistral-7B LLM进行细调。最初,我从Hugging Face下载了mistralai/Mistral-7B-Instruct-v0.2 LLM,使用huggingface-cli工具。然后,我使用提供的数据集和LoRA对LLM进行了训练。LoRA,也就是所谓的低秩适应(Low-Rank Adaptation,简称LoRA),通过引入低秩矩阵来调整模型的行为,而无需大量的重新训练,从而在保留原始参数的同时,实现了高效且有针对性的调整。
训练过程大约花了25分钟,在配备64GB RAM 和 30 GPU的Mac M2上训练大规模语言模型并生成所需的适配。
# 下载大型语言模型 (LLM)
❯❯ huggingface-cli download mistralai/Mistral-7B-Instruct-v0.2
/Users/lambda.eranga/.cache/huggingface/hub/models--mistralai--Mistral-7B-Instruct-v0.2/snapshots/1296dc8fd9b21e6424c9c305c06db9ae60c03ace
# 模型下载到 ~/.cache/huggingface/hub/ 目录下
❯❯ ls ~/.cache/huggingface/hub/models--mistralai--Mistral-7B-Instruct-v0.2
blobs refs snapshots
# 列出从 Hugging Face 下载的所有模型
❯❯ huggingface-cli scan-cache
REPO ID REPO TYPE SIZE ON DISK NB FILES LAST_ACCESSED LAST_MODIFIED REFS LOCAL PATH
-------------------------------------- --------- ------------ -------- ------------- ------------- ---- -------------------------------------------------------------------------------------------
BAAI/bge-reranker-base model 1.1G 6 3 months ago 4 months ago main /Users/lambda.eranga/.cache/huggingface/hub/models--BAAI--bge-reranker-base
NousResearch/Meta-Llama-3-8B model 16.1G 14 2 months ago 5 months ago main /Users/lambda.eranga/.cache/huggingface/hub/models--NousResearch--Meta-Llama-3-8B
gpt2 model 2.9M 5 8 months ago 8 months ago main /Users/lambda.eranga/.cache/huggingface/hub/models--gpt2
infgrad/stella_en_1.5B_v5 model 240.7K 6 4 months ago 4 months ago main /Users/lambda.eranga/.cache/huggingface/hub/models--infgrad--stella_en_1.5B_v5
mistralai/Mistral-7B-Instruct-v0.2 model 29.5G 21 1 day ago 1 day ago main /Users/lambda.eranga/.cache/huggingface/hub/models--mistralai--Mistral-7B-Instruct-v0.2
sentence-transformers/all-MiniLM-L6-v2 model 91.6M 11 8 months ago 8 months ago main /Users/lambda.eranga/.cache/huggingface/hub/models--sentence-transformers--all-MiniLM-L6-v2
扫描完成。共计扫描了 6 个库,合计 46.8G。
扫描过程中收到 1 个警告。使用 -vvv 查看详细信息
# 微调模型
# --model - 原始模型,从 Hugging Face 下载
# --data data - 数据目录路径,包含 train.jsonl 文件
# --batch-size 4 - 批量大小
# --lora-layers 16 - LoRA 层的数量
# --iters 1000 - 训练迭代次数
❯❯ python -m mlx_lm.lora \
--model mistralai/Mistral-7B-Instruct-v0.2 \
--data data \
--train \
--batch-size 4\
--lora-layers 16\
--iters 1000
# 以下是训练输出
# 开始训练时,初始验证损失为 1.939,训练损失为 1.908
# 训练完成后,验证损失为 0.548,训练损失为 0.534
加载预训练模型
检索 11 个文件: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11/11 [00:00<00:00, 17980.26it/s]
加载数据集
开始训练
可训练参数: 0.024% (1.704M/7241.732M)
开始训练..., 迭代次数: 1000
迭代 1: 验证损失 3.346, 验证时间为 35.688s
迭代 10: 训练损失 2.713, 学习率 1.000e-05, 每秒训练次数 0.473, 每秒训练 token 量 314.028, 训练 token 量 6640, 最大内存占用 16.083 GB
迭代 20: 训练损失 1.179, 学习率 1.000e-05, 每秒训练次数 0.474, 每秒训练 token 量 314.641, 训练 token 量 13280, 最大内存占用 16.083 GB
迭代 30: 训练损失 0.432, 学习率 1.000e-05, 每秒训练次数 0.474, 每秒训练 token 量 314.606, 训练 token 量 19920, 最大内存占用 16.083 GB
迭代 40: 训练损失 0.484, 学习率 1.000e-05, 每秒训练次数 0.476, 每秒训练 token 量 313.707, 训练 token 量 26511, 最大内存占用 16.083 GB
迭代 50: 训练损失 0.361, 学习率 1.000e-05, 每秒训练次数 0.471, 每秒训练 token 量 311.593, 训练 token 量 33123, 最大内存占用 16.083 GB
迭代 60: 训练损失 0.335, 学习率 1.000e-05, 每秒训练次数 0.472, 每秒训练 token 量 312.100, 训练 token 量 39739, 最大内存占用 16.083 GB
迭代 70: 训练损失 0.315, 学习率 1.000e-05, 每秒训练次数 0.473, 每秒训练 token 量 313.810, 训练 token 量 46367, 最大内存占用 16.083 GB
迭代 80: 训练损失 0.311, 学习率 1.000e-05, 每秒训练次数 0.473, 每秒训练 token 量 313.270, 训练 token 量 52994, 最大内存占用 16.083 GB
---
迭代 910: 训练损失 0.165, 学习率 1.000e-05, 每秒训练次数 0.470, 每秒训练 token 量 311.057, 训练 token 量 603153, 最大内存占用 16.213 GB
迭代 920: 训练损失 0.154, 学习率 1.000e-05, 每秒训练次数 0.469, 每秒训练 token 量 310.728, 训练 token 量 609781, 最大内存占用 16.213 GB
迭代 930: 训练损失 0.158, 学习率 1.000e-05, 每秒训练次数 0.470, 每秒训练 token 量 311.830, 训练 token 量 616409, 最大内存占用 16.213 GB
迭代 940: 训练损失 0.148, 学习率 1.000e-05, 每秒训练次数 0.465, 每秒训练 token 量 308.425, 训练 token 量 623037, 最大内存占用 16.213 GB
迭代 950: 训练损失 0.156, 学习率 1.000e-05, 每秒训练次数 0.468, 每秒训练 token 量 310.664, 训练 token 量 629669, 最大内存占用 16.213 GB
迭代 960: 训练损失 0.166, 学习率 1.000e-05, 每秒训练次数 0.466, 每秒训练 token 量 308.836, 训练 token 量 636297, 最大内存占用 16.213 GB
迭代 970: 训练损失 0.150, 学习率 1.000e-05, 每秒训练次数 0.470, 每秒训练 token 量 311.695, 训练 token 量 642925, 最大内存占用 16.213 GB
迭代 980: 训练损失 0.151, 学习率 1.000e-05, 每秒训练次数 0.474, 每秒训练 token 量 314.600, 训练 token 量 649564, 最大内存占用 16.213 GB
迭代 990: 训练损失 0.146, 学习率 1.000e-05, 每秒训练次数 0.470, 每秒训练 token 量 312.381, 训练 token 量 656204, 最大内存占用 16.213 GB
迭代 1000: 验证损失 0.149, 验证时间为 35.181s
迭代 1000: 训练损失 0.146, 学习率 1.000e-05, 每秒训练次数 4.690, 每秒训练 token 量 3106.646, 训练 token 量 662828, 最大内存占用 16.213 GB
迭代 1000: 已将适配器权重保存到 adapters/adapters.safetensors 和 adapters/0001000_adapters.safetensors。
已保存最终适配器权重到 adapters/adapters.safetensors。
# 训练过程中 GPU 的使用情况
❯❯ sudo powermetrics --samplers gpu_power -i500 -n1
密码:
机器型号: Mac14,6
系统版本: 23F79
启动参数:
启动时间: 2024年12月6日 09:26:57
*** 采集系统活动 (2024年12月9日 08:43:34 -0500) (共503.37ms) ***
**** GPU 使用情况 ****
GPU 硬件使用时间: 1397 MHz
GPU 硬件使用时间: 98.22% (444 MHz: .09% 612 MHz: 0% 808 MHz: 0% 968 MHz: 0% 1110 MHz: 0% 1236 MHz: 0% 1338 MHz: 0% 1398 MHz: 98%)
GPU 软件请求状态: (P1 : 0% P2 : 0% P3 : 0% P4 : 0% P5 : 0% P6 : 0% P7 : 0% P8 : 100%)
GPU 软件状态: (SW_P1 : 0% SW_P2 : 0% SW_P3 : 0% SW_P4 : 0% SW_P5 : 0% SW_P6 : 0% SW_P7 : 0% SW_P8 : 0%)
GPU 空闲驻留时间: 1.78%
GPU 功耗: 42023 mW
# 训练完成后,生成的 LoRA 适配器保存在 adapters 文件夹中
❯❯ ls adapters
0000100_adapters.safetensors
0000300_adapters.safetensors
0000500_adapters.safetensors
0000700_adapters.safetensors
0000900_adapters.safetensors
adapter_config.json
0000200_adapters.safetensors
0000400_adapters.safetensors
0000600_adapters.safetensors
0000800_adapters.safetensors
0001000_adapters.safetensors
adapters.safetensors大语言模型现在已经训练好了,LoRA适配器也已经创建好了。我们可以用这些适配器和原始的大语言模型来测试微调后的模型。最初,我使用--train参数对大语言模型进行了测试。接着,我向原始模型和微调后的模型提出了同样的问题。这种对比让我们可以看到,微调后的大语言模型基于提供的医学诊断预测数据集是如何被优化的。通过调整提示、数据集及其他参数,可以进一步优化微调过程。
# 使用测试数据测试大语言模型
# --model - 从hugging face下载的原始模型
# --adapter-path adapters - lora适配器的位置
# --data data - 包含test.jsonl的数据目录路径
❯❯ python -m mlx_lm.lora \
--model mistralai/Mistral-7B-Instruct-v0.2 \
--adapter-path adapters \
--data data \
--test
# 输出
加载预训练模型
正在获取11个文件: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11/11 [00:00<00:00, 54471.48it/s]
加载数据集
测试
测试损失 0.151,测试PPL 1.163。
测试完成。
# 首先使用mlx从原始大语言模型中提问
# --model - 从hugging face下载的原始模型
# --max-tokens 500 - 生成多少tokens
# --prompt - 提给llm的提示
❯❯ python -m mlx_lm.generate \
--model mistralai/Mistral-7B-Instruct-v0.2 \
--max-tokens 500 \
--prompt "您是网络流量分析方面的专家。根据提供的网络流量属性,您必须确定该流量是否正常或异常。这里是一些属性:'源IP地址:192.168.100.103,源端口:47525,网络协议:tcp,连接持续时间:2.998777,连接状态:S0,丢失的数据包和字节:0,从源到目的地发送的数据包数:3,从源到目的地发送的字节数:180,从目的地到源发送的数据包数:0,从目的地到源发送的字节数:0'。"
# 它基于原始的大语言模型知识库提供通用答案
提示:<s> [INST] 您是网络流量分析方面的专家。根据提供的网络流量属性,您必须确定该流量是否正常或异常。这里是一些属性:'源IP地址:192.168.100.103,源端口:47525,网络协议:tcp,连接持续时间:2.998777,连接状态:S0,丢失的数据包和字节:0,从源到目的地发送的数据包数:3,从源到目的地发送的字节数:180,从目的地到源发送的数据包数:0,从目的地到源发送的字节数:0'。 [/INST]
根据提供的网络流量属性,该流量看起来是正常的,原因如下:
1. 源IP地址:IP地址192.168.100.103属于一个私有的IP地址范围,通常用于内部网络。这并不是异常流量的迹象。
2. 源端口:源端口47525并未与任何已知的恶意活动相关联。它是一个常用的应用程序发出连接的高编号临时端口。
3. TCP协议:使用TCP协议是一种常见的正常协议,用于应用程序间可靠的数据传输。
4. 连接持续时间:连接持续时间为2.998777秒,这在典型的连接持续时间内是正常的。
5. 连接状态:连接处于SYN阶段,这是连接开始时的正常状态。
6. 丢失的数据包和字节:没有丢失的数据包和字节,表明所有数据都如预期般接收。
7. 发送的数据包和字节数:发送的数据包和字节数在典型的连接范围内是合理的。
因此,根据给定的网络流量属性,该流量看起来是正常的。
==========
提示:348.322 tokens-per-sec
生成:20.630 tokens-per-sec
# 使用适配器从微调后的模型中提问相同的问题
# --model - 从hugging face下载的原始模型
# --max-tokens 500 - 生成多少tokens
# --adapter-path adapters - 适配器的位置
# --prompt - 提给llm的提示
❯❯ python -m mlx_lm.generate \
--model mistralai/Mistral-7B-Instruct-v0.2 \
--max-tokens 500 \
--adapter-path adapters \
--prompt "您是网络流量分析方面的专家。根据提供的网络流量属性,您必须确定该流量是否正常或异常。这里是一些属性:'源IP地址:192.168.100.103,源端口:47525,网络协议:tcp,连接持续时间:2.998777,连接状态:S0,丢失的数据包和字节:0,从源到目的地发送的数据包数:3,从源到目的地发送的字节数:180,从目的地到源发送的数据包数:0,从目的地到源发送的字节数:0'。"
# 它根据用于微调的数据集提供特定答案
提示:<s> [INST] 您是网络流量分析方面的专家。根据提供的网络流量属性,您必须确定该流量是否正常或异常。这里是一些属性:'源IP地址:192.168.100.103,源端口:47525,网络协议:tcp,连接持续时间:2.998777,连接状态:S0,丢失的数据包和字节:0,从源到目的地发送的数据包数:3,从源到目的地发送的字节数:180,从目的地到源发送的数据包数:0,从目的地到源发送的字节数:0'。 [/INST]
异常网络流量
==========
提示:351.853 tokens-per-sec
生成:21.462 tokens-per-sec微调完成后,我们可以将新模型学到的调整合并到现有的模型权重中,这个过程称为融合过程。从技术角度看,这涉及到更新预训练或基础模型的权重和参数,以融合微调模型的改进。简而言之,我可以将LoRA适配器文件融合回基础模型。
微调完成后,我可以将新模型学到的调整与现有模型的权重合并,这个过程叫做融合。技术上,这要求更新预训练或基础模型的权重和参数,以便整合微调模型的改进。简单来说,我可以把LoRA适配器再合并进基础模型。
# --model - 原始模型,从 Hugging Face 下载
# --adapter-path adapters - LoRA adapter 的位置
# --save-path models/effectz-attack - 新模型路径
# --de-quantize - 如果要反量化模型,请使用此标志。
❯❯ python -m mlx_lm.fuse \
--model mistralai/Mistral-7B-Instruct-v0.2 \
--adapter-path adapters \
--save-path models/effectz-attack \
--de-quantize
# 输出
加载预训练模型
加载 11 个文件:100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 11/11 [00:00<00:00, 19929.74it/s]
将模型反量化
# 新模型生成在 models 目录中
❯❯ tree models
models
└── effectz-attack
├── config.json
├── model-00001-of-00003.safetensors
├── model-00002-of-00003.safetensors
├── model-00003-of-00003.safetensors
├── model.safetensors.index.json
├── special_tokens_map.json
├── tokenizer.json
├── tokenizer.model
└── tokenizer_config.json
# 现在可以直接地从新模型中提问
# --model models/effectz-attack - 新模型路径
# --max-tokens 500 - 生成多少个 tokens
# --prompt - 提供给 LLM 的提示
❯❯ python -m mlx_lm.generate \
--model models/effectz-attack \
--max-tokens 500 \
--prompt "您是网络流量分类方面的专家。根据提供的网络流量属性,您必须确定流量是否正常或异常。以下是属性,'源IP地址:192.168.100.103,源端口:47525,网络协议:TCP,连接时长:2.998777,连接状态:S0,丢失的字节数:0,从源到目的发送的数据包数量:3,从源到目的发送的IP字节数:180,从目的到源发送的数据包数量:0,从目的到源发送的IP字节数:0'。"
# 输出
提示: <s> [INST] 您是网络流量分类方面的专家。根据提供的网络流量属性,您必须确定流量是否正常或异常。以下是属性,'源IP地址:192.168.100.103,源端口:47525,网络协议:TCP,连接时长:2.998777,连接状态:S0,丢失的字节数:0,从源到目的发送的数据包数量:3,从源到目的发送的IP字节数:180,从目的到源发送的数据包数量:0,从目的到源发送的IP字节数:0'。 [/INST]
异常网络流量
==========
提示:346.093 tokens-per-sec 生成:23.113 tokens-per-sec注:GGUF 是一个特定的模型类型,可能需要进一步解释以帮助不熟悉的读者理解。
我想用 [Ollama](https://github.com/ollama/ollama) 运行这个新创建的模型,这是一个轻量且灵活的设计,用于在个人电脑上部署大型语言模型(LLMs)。为了在 Ollama 中运行这个新创建的模型,我需要将其转换为 [GGUF (Georgi Gerganov 统一格式)](https://github.com/ggerganov/ggml/blob/master/docs/gguf.md) 文件。GGUF 是 Ollama 使用的标准存储格式。为了将模型转换为 GGUF,我使用了另一个名为 [llama.cpp](https://github.com/ggerganov/llama.cpp) 的工具,这是一个用 C++ 语言编写的开源软件库,可以对各种 LLM 进行推断。以下把模型转换成 GGUF 格式并构建 Ollama 模型的方法。
# 将 llama.cpp 克隆到 mlxa 仓库所在的相同目录下
❯❯ git clone https://github.com/ggerganov/llama.cpp.git
# 包含着 llama.cpp 和 mlxa 的目录结构
❯❯ ls
llama.cpp
mlxa
# 在 llama.cpp 中安装必要的包,并设置虚拟环境
❯❯ cd llama.cpp
❯❯ python -m venv .venv
❯❯ source .venv/bin/activate
❯❯ pip install -r requirements.txt
# llama.cpp 包含一个脚本 `convert-hf-to-gguf.py`,用于将 Hugging Face 模型转换为 GGUF 格式
❯❯ ls convert-hf-to-gguf.py
convert-hf-to-gguf.py
# 将 mlxa/models/effectz-attack 新生成的模型转换为 GGUF 格式
# --outfile ../mlxa/models/effectz-attack.gguf - 输出 GGUF 模型文件路径
# --outtype q8_0 - 8 位量化,有助于提高推理速度
# 为了优化模型性能,可以尝试调整 outtype 参数(例如不使用 outtype 等)
❯❯ python convert-hf-to-gguf.py ../mlxa/models/effectz-attack \
--outfile ../mlxa/models/effectz-predict.gguf \
--outtype q8_0
# 输出信息
INFO:hf-to-gguf:加载模型: effectz-attack
INFO:gguf.gguf_writer:gguf: 此 GGUF 文件只能用于小端格式
INFO:hf-to-gguf:设置了模型参数
INFO:hf-to-gguf:gguf: 上下文长度 = 32768
INFO:hf-to-gguf:gguf: 嵌入长度 = 4096
INFO:hf-to-gguf:gguf: 前馈长度 = 14336
INFO:hf-to-gguf:gguf: 头数 = 32
INFO:hf-to-gguf:gguf: 键值头数 = 8
INFO:hf-to-gguf:gguf: 旋转因子 = 1000000.0
INFO:hf-to-gguf:gguf: RMS 归一化 ε值 = 1e-05
INFO:hf-to-gguf:gguf: 文件类型 = 7
INFO:hf-to-gguf:设置了模型分词器
INFO:gguf.vocab:将特殊标记类型 bos 设置为 1
INFO:gguf.vocab:将特殊标记类型 eos 设置为 2
INFO:gguf.vocab:将特殊标记类型 unk 设置为 0
INFO:gguf.vocab:将 add_bos_token 设置为 True
INFO:gguf.vocab:将 add_eos_token 设置为 False
---
INFO:hf-to-gguf:blk.29.attn_v.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 1024}
INFO:hf-to-gguf:blk.30.attn_norm.weight, torch.bfloat16 --> F32, 维度 = {4096}
INFO:hf-to-gguf:blk.30.ffn_down.weight, torch.bfloat16 --> Q8_0, 维度 = {14336, 4096}
INFO:hf-to-gguf:blk.30.ffn_gate.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 14336}
INFO:hf-to-gguf:blk.30.ffn_up.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 14336}
INFO:hf-to-gguf:blk.30.ffn_norm.weight, torch.bfloat16 --> F32, 维度 = {4096}
INFO:hf-to-gguf:blk.30.attn_k.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 1024}
INFO:hf-to-gguf:blk.30.attn_output.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 4096}
INFO:hf-to-gguf:blk.30.attn_q.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 4096}
INFO:hf-to-gguf:blk.30.attn_v.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 1024}
INFO:hf-to-gguf:blk.31.attn_norm.weight, torch.bfloat16 --> F32, 维度 = {4096}
INFO:hf-to-gguf:blk.31.ffn_down.weight, torch.bfloat16 --> Q8_0, 维度 = {14336, 4096}
INFO:hf-to-gguf:blk.31.ffn_gate.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 14336}
INFO:hf-to-gguf:blk.31.ffn_up.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 14336}
INFO:hf-to-gguf:blk.31.ffn_norm.weight, torch.bfloat16 --> F32, 维度 = {4096}
INFO:hf-to-gguf:blk.31.attn_k.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 1024}
INFO:hf-to-gguf:blk.31.attn_output.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 4096}
INFO:hf-to-gguf:blk.31.attn_q.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 4096}
INFO:hf-to-gguf:blk.31.attn_v.weight, torch.bfloat16 --> Q8_0, 维度 = {4096, 1024}
INFO:hf-to-gguf:output_norm.weight, torch.bfloat16 --> F32, 维度 = {4096}
写入: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 7.70G/7.70G [01:21<00:00, 94.9Mbyte/s]
INFO:hf-to-gguf:模型成功导出为 '../mlxa/models/effectz-attack.gguf'
# 新生成的 GGUF 模型在 mlxa/models 目录中
❯❯ cd ../mlxa
❯❯ ls models/effectz-attack.gguf
models/effectz-attack.gguf现在我可以创建一个 [Ollama Modelfile](https://github.com/ollama/ollama/blob/main/docs/modelfile.md),并用名为 effectz-predict.gguf 的 GGUF 模型文件来构建一个 Ollama 模型。Ollama Modelfile 是一个配置文件,用于定义和管理 Ollama 平台上的模型,就像一个模型的说明书一样。下面是如何创建 Modelfile 并生成新的 Ollama 模型的步骤。
# 在models目录下创建名为`Modelfile`的文件,并包含如下内容
❯❯ cat models/Modelfile
FROM ./effectz-attack.gguf
# 使用ollama创建模型
❯❯ ollama create effectz-attack -f models/Modelfile
正在传输模型数据 100%
使用已存在的层(sha256:189106bcbbfa1942e25555311d0097b1b2604d4a44416ae90436763ea8e17886)
正在创建新层 sha256:633247d6e759ef95ed88aba596b6882716cdf3888236ab14762070b42126f039
写入清单
成功
# 列出ollama模型
# effectz-attack:latest 是新创建的模型
❯❯ ollama ls
名称: ID 大小 修改时间:
effectz-attack:latest 7aa76a0412bc 7.7 GB 44秒前
effectz-predict:latest e87d93dff4c4 14 GB 4周前
effectz-sql:latest 736275f4faa4 7.7 GB 5个月前
rahasak-sql:latest e41d278330ed 7.7 GB 5个月前
mistral:latest 2ae6f6dd7a3d 4.1 GB 5个月前
llama3:latest a6990ed6be41 4.7 GB 7个月前
llama3:8b a6990ed6be41 4.7 GB 7个月前
llama2:latest 78e26419b446 3.8 GB 8个月前
llama2:13b d475bf4c50bc 7.4 GB 8个月前
# 使用ollama运行模型并询问关于诊断的问题
# 它将基于用于微调模型的自定义知识库给出答案
❯❯ ollama run effectz-attack
>>> 您是一位网络流量分类专家。基于以下网络流量属性,您必须确定该流量是否正常或异常。以下是属性:'源IP地址:192.168.100.103,源端口:47525,网络协议类型:TCP,连接持续时间:2.998777秒,连接状态:S0,丢失的数据字节数:0,从源发送到目的地的数据包数:3,从源发送到目的地的IP字节数:180,从目的地发送到源的数据包数:0,从目的地发送到源的IP字节数:0'。
这是一次异常的网络流量- https://medium.com/rahasak/fine-tuning-llms-on-macos-using-mlx-and-run-with-ollama-182a20f1fd2c - 在 macOS 上使用 MLX 和 Ollama 进行大语言模型的微调。
- https://medium.com/rahasak/fine-tune-llm-for-medical-diagnosis-prediction-with-apple-mlx-1366ca2c5d63 - 使用 Apple MLX 对大语言模型进行微调以进行医学诊断预测。
- https://www.datacamp.com/tutorial/fine-tuning-large-language-models - 如何在 DataCamp 上微调大语言模型教程。
- https://www.lakera.ai/blog/llm-fine-tuning-guide - 大语言模型微调指南。
- https://medium.com/rahasak/fine-tune-llms-on-your-pc-with-qlora-apple-mlx-c2aedf1f607d - 使用 QLoRA 和 Apple MLX 在个人电脑上微调大语言模型。
- https://medium.com/@elijahwongww/how-to-finetune-llama-3-model-on-macbook-4cb184e6d52e - 如何在 MacBook 上微调 Llama 3 模型。
- https://heidloff.net/article/fine-tuning-llm-locally-apple-silicon-m3/ - 在本地的 Apple Silicon M3 上微调大语言模型。
- https://heidloff.net/article/apple-mlx-fine-tuning/ - 使用 Apple MLX 进行大语言模型的微调。
- https://medium.com/@anchen.li/fine-tune-llama3-with-function-calling-via-mlx-lm-5ebbee41558f - 使用 MLX LM 通过函数调用微调 Llama3 模型。
- https://iwasnothing.medium.com/llm-fine-tuning-with-macbook-pro-982fbea50b3d - 使用 MacBook Pro 微调大语言模型。
- https://medium.com/@mustangs007/mlx-building-fine-tuning-llm-model-on-apple-m3-using-custom-dataset-9209813fd38e - 使用 MLX 在 Apple M3 上使用自定义数据集构建并微调大语言模型。
- https://mer.vin/2024/02/mlx-mistral-lora-fine-tuning/ - 使用 MLX Mistral LoRA 进行微调。
- https://apeatling.com/articles/simple-guide-to-local-llm-fine-tuning-on-a-mac-with-mlx/ - 使用 MLX 在 Mac 上进行本地大语言模型微调的简单指南。
- https://dassum.medium.com/fine-tune-large-language-model-llm-on-a-custom-dataset-with-qlora-fb60abdeba07 - 使用 QLoRA 在自定义数据集上微调大语言模型。
- https://www.youtube.com/watch?v=MwD0GmF3Whk&t=450s - 如何在 YouTube 上微调大语言模型的视频教程。
- https://www.datacamp.com/tutorial/fine-tuning-llama-3-2 - DataCamp 上微调 Llama 3.2 的教程。
- https://www.kaggle.com/code/kingabzpro/fine-tune-llama-3-8b-on-medical-dataset/notebook - 在医疗数据集上微调 Llama 3.8B 的 Kaggle 笔记本。





