
免责声明: 本大纲详细解释了LangGraph AI Agent的代码库。我建议您一边看代码一边学习,可以在共享的_Google Colab笔记本_中进行。为了更深入地理解,试着自己动手测试代码中的各个部分。祝你好运,玩得愉快!
AI代理正在改变我们管理任务的方式,提供了前所未有的能力,通过使用多个工具和拥有长期记忆的能力。这些代理不仅能完成孤立的任务,而且可以与API、数据库及其他系统相互协作,以高效和精准的方式完成复杂的任务。
正是这种长期记忆能力使它们真正具有变革性。与传统的AI系统在每次交互后忘记一切不同,现代AI代理能够在不同会话之间存储和调用信息。这使它们能够从反馈中学习,适应用户偏好,并随着时间保持连续性。通过结合这些记忆能力与对各种工具的访问,AI代理成为了动态问题解决者,能够主动支持用户达成目标。
在这篇文章中,我们将展示如何使用这些先进功能来构建一个AI社交媒体管理器。我们将使用LangGraph AI代理来创建一个系统,该系统可以跟踪内容创意、监控并分析特定平台的策略,并从帖子的起草到最后版本对其进行组织。
AI记忆的进化:从金鱼般的记忆到主动协作伙伴如今大多数人工智能系统都存在所谓的“金鱼般的记忆力”问题——它们在对话结束时就会忘记一切。虽然这种限制对于简单的单次会话任务还勉强够用,但对于需要持续性、个性化或复杂流程的应用场景来说,这种局限性就显得远远不够了。想象一位社交媒体经理记不住你上次的活动策略,或者每次互动后都忘记你偏好的聊天机器人。这不仅低效,还限制了人工智能发挥其全部潜力。
LangGraph 正在改变游戏。通过引入 长期记忆,让 AI 代理变得更智能、更主动,成为用户的合作伙伴。与短期记忆只能记住单次对话的内容不同,长期记忆让代理可以记住多个对话中的信息,并从中学习。这不仅关乎记忆,更关乎进化。由 LangGraph 的长期记忆驱动的 AI 代理可以适应用户偏好,吸收用户反馈并不断调整行为,提供更贴合用户需求的帮助。
LangGraph是如何实现这一飞跃的:
- 跨会话持久性:代理不再在每次交互后“重置”。它们在会话之间保持上下文,使工作流程更加无缝和连续。
- 个性化:通过记住用户的偏好和反馈,AI代理可以根据个人需求调整其响应和策略。
- 效率优化:忘记不仅令人不便,还很耗费成本。长期记忆能消除重复任务,减少冗余交互,并加快决策过程。
LangGraph的记忆系统的核心是一个持久化的文档库——这看似简单却功能强大的工具,用于以JSON文档的形式存储数据。此框架支持灵活的命名空间,允许开发者按上下文、用户或应用来组织记忆。结合基于内容的过滤,代理可以迅速检索最相关的信息,让每次互动都显得既智能又富有信息量。
但真正的魔力在于LangGraph如何无缝地融合短期记忆和长期记忆。短期记忆通过“检查点”机制来保持代理在单一会话中的敏锐和专注。长期记忆则使它们能够积累并延续知识,将静态工具转变为能够随着时间推移不断成长和自我适应的动态系统。
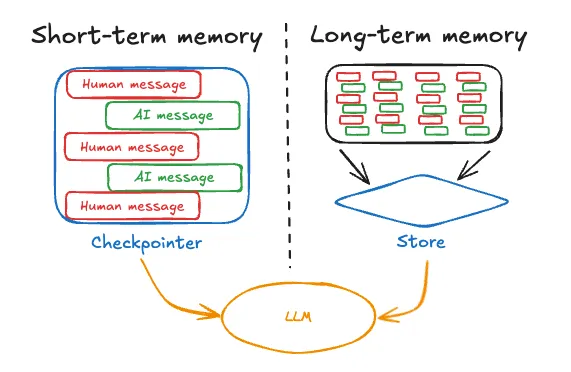
记忆支持:从短期(局限于一个线程的)到长期(跨越不同线程的)。来源链接:https://blog.langchain.dev/launching-long-term-memory-support-in-langgraph/
从持久记忆到更智能的社交媒体运营在这次教程里,我们将通过构建一个AI社交媒体管理器来展示长期记忆的强大功能,比如。这个智能助手将展示LangGraph如何利用其强大的记忆能力,将AI助手从简单的工具变成动态的合作伙伴。通过利用长期记忆,AI社交媒体管理器可以跟踪内容想法,管理截止日期,并根据反馈调整策略——并适应用户的偏好。
管理内存内存管理的有效性是AI代理存储和调取信息、适应用户的输入并提供无缝的用户体验的基石。为了实现这一点,代理使用Pydantic定义的结构化模式定义,确保一致性和验证,同时提高可扩展性。
AI代理将记忆组织成结构化的框架来有效地存储和管理信息,以便有效存储和管理信息。这些框架包括对单独的记忆和记忆群组的定义。
from pydantic import BaseModel, Field
class Memory(BaseModel):
content: str = Field(description="记忆内容的主要内容。例如:用户对学习法语表现出兴趣。")
class MemoryCollection(BaseModel):
memories: list[Memory] = Field(description="用户的记忆列表。")Memory 类 :代表一个单独的记忆项,包含一个 content 字段,用于存储具体的信息,比如:.
“用户对学习法语表达了兴趣。”“用户更喜欢在 Instagram 和 LinkedIn 上发帖子。”
MemoryCollection 类:将多个内存数据汇集到一个列表中,代表用户的全部记忆内容。例如:
{
"memories": [
{"content": "用户表达了想学法语的兴趣。"},
{"content": "用户偏好轻松的风格。"}
]
}通过这种结构化的记忆方式,代理确保数据易于验证、更新和检索,为长期信息管理奠定了坚实的基础。
在这个教程里,AI助手依赖于三个关键的记忆组件:用户记忆、内容计划和指导。这些组件的设计目的是确保一致性和验证,这使得AI更容易根据用户输入做出动态调整。
- 用户个人资料记忆功能:智能代理会随着时间的推移更深入地了解你的偏好,包括你偏好的平台和内容的语气与风格。
Profile类代表AI能够动态更新的一个记忆片段。
class Profile(BaseModel):
"""这是你正在聊天的用户的个人简介"""
name: Optional[str] = Field(description="用户的昵称", default=None)
location: Optional[str] = Field(description="用户的所在地信息", default=None)
target_audience: Optional[str] = Field(description="内容创作的目标群体", default=None)
preferred_platforms: list[str] = Field(description="用户喜欢用来发布内容的平台", default_factory=list)- 内容日历: 它维护一个集中式的日历来跟踪您的内容流程,涵盖想法、截止日期、状态和草稿等,确保不会错过任何细节。与
Profile类不同,ContentCalendar类表示一个内存集合体而不是单个内存。这意味着它可以容纳多个条目(如内存对象列表),AI代理程序可以动态添加或更新这些条目。
class ContentCalendar(BaseModel):
"""表示内容日历条目"""
title: str = Field(description="内容的标题或主题。")
platform: Optional[str] = Field(description="内容发布平台(例如Instagram、博客)。", default=None)
deadline: Optional[datetime] = Field(description="发布内容的截止日期。", default=None)
status: Literal["idea", "draft", "review", "posted"] = Field(description="内容的当前状态。", default="idea")
tags: list[str] = Field(description="与内容相关的标签。", default_factory=list)
idea: str = Field(description="内容的概念。", default=None)- 指导方针提示:代理根据用户反馈来调整其行为,遵循一组指导原则来塑造内容创作过程。这些指导原则会根据需要动态更新,确保代理与用户不断变化的需求保持同步。
CREATE_GUIDELINES = """先思考一下下面的互动。
根据这次互动,更新一下你的内容创作指南吧。
用用户的反馈来调整他们喜欢的头脑风暴、组织或追踪内容的方式。
你目前的指南是:
<guidelines>
{guidelines}
</guidelines>
看看你现在的指南,看看有什么需要调整的地方吧。"""这些存储组件(或称为内存组件)将用于存储通过与AI代理互动收集的长期数据。
Trustcall 如何追踪和更新内存数据?有了用来存储信息的记忆组件之后,我们也需要一个系统来动态更新和增加记忆。为此,我们使用了Trustcall,一个专门用于JSON模式结构化更新的框架。Trustcall让AI能够高效且透明地管理记忆。它会自动纠正验证错误,确保与定义模式保持一致。它仅在必要时进行精确更新,避免覆盖整个数据结构。
为了监控Trustcall如何更新内存组件,我们实现了一个自定义的 Spy 类。作为监听器,Spy捕获Trustcall执行期间所有工具调用的详细信息。通过将Spy附加到Trustcall提取器的过程中,我们可以看到每次对内存组件所做的变更。下面是如何实现的:
从trustcall导入create_extractor()
从langchain_openai导入ChatOpenAI
# 检查Trustcall调用的工具调用信息
class Spy:
def __init__(self):
self.called_tools = []
def __call__(self, run):
# 收集由extractor调用的工具调用信息
q = [run]
while q:
r = q.pop()
if r.child_runs:
q.extend(r.child_runs)
if r.run_type == "聊天模型":
self.called_tools.append(
r.outputs["generations"][0][0]["message"]["kwargs"]["tool_calls"]
)
# 初始化间谍对象
spy = Spy()
# 初始化模型
model = ChatOpenAI(model="gpt-4o", temperature=0)
# 创建个人资料提取器(profile_extractor)
profile_extractor = create_extractor(
model,
tools=[Profile],
tool_choice="Profile",
)
# 创建内容提取器(content_extractor),插入功能启用=True
content_extractor = create_extractor(
model,
tools=[ContentCalendar],
tool_choice="ContentCalendar",
enable_inserts=True).带有监听器(on_end=spy)在这个例子中,Spy 类被附加为 content_extractor 的监听器,而 content_extractor 会更新 ContentCalendar 记忆模块。由于 ContentCalendar 代表了一个由多个 JSON 文档组成的记忆集合,Spy 通过捕获所有更新的细节来确保透明度和可追踪性。因此,profile_extractor 不需要 Spy 监听器,因为 Profile 记忆单元只是一个单个 JSON 文档。由于对个人档案的更新较为简单,因此不需要详细监控。
间谍 类型在提供对 Trustcall 操作的可见性方面起着关键作用。它确保每个内存更新都被监控,使开发人员能够跟踪并验证更改。间谍在初始化时使用一个空列表 (called_tools) 来存储执行过程中调用的工具详情。当 Trustcall 提取器处理用户输入时,它会生成一个执行轨迹——记录整个过程中执行的所有操作记录。该轨迹不仅包括父操作,还包括执行过程中触发的所有子操作。间谍系统地使用队列来检查父操作和子操作,确保捕获每一个工具调用。
对于执行过程中的每一步,监听器会检查聊天模型(run_type == "chat_model")的输出,以提取有关工具调用的详细信息。这些详细信息会被添加到 called_tools 列表中,以便进一步分析工具调用。通过将监听器集成到 Trustcall 提取器中,我们可以确保它实时捕获内存更新的信息。
通过结合Trustcall进行结构化内存更新和使用Spy类进行详细监控,AI代理实现了效率、精准性和透明度三者的平衡。这种设置确保所有内存组件的更改都可追踪,从而增强了代理随时间演进和适应能力的信任和责任感,促进了代理随时间演进和适应能力的信任和责任感。
重新格式化间谍程序的输出:提取并展示工具调用详情为了更好地理解和利用 Spy类 捕捉到的信息,我们将定义一个自定义函数 extract_tool_info,用于处理和重新格式化从 spy.called_tools 获取的输出。这些格式化的数据也可以整合到语言模型的提示中,为生成知情回应提供更多上下文。
def extract_tool_info(tool_calls, schema_name="Memory"):
"""从工具调用中提取补丁和新记忆的相关信息。
参数:
tool_calls: 模型中的工具调用列表
schema_name: 工具模式的名称(例如,“Memory”,“ToDo”,“Profile”)
"""
# 初始化变更清单
changes = []
for call_group in tool_calls:
for call in call_group:
if call['name'] == 'PatchDoc':
changes.append({
'type': 'update',
'doc_id': call['args']['json_doc_id'],
'planned_edits': call['args']['planned_edits'],
'value': call['args']['patches'][0]['value']
})
elif call['name'] == schema_name:
changes.append({
'type': 'new',
'value': call['args']
})
# 将结果格式化为单一字符串
result_parts = []
for change in changes:
if change['type'] == 'update':
result_parts.append(
f"文档 {change['doc_id']} 更新:\n"
f"计划:{change['planned_edits']}\n"
f"添加的内容为:{change['value']}"
)
else:
result_parts.append(
f"创建新的 {schema_name}:\n"
f"内容:{change['value']}"
)
return "\n\n".join(result_parts)此功能处理Trustcall提取器发出的工具调用,区分现有文档的更新(PatchDoc 功能)和新记忆项的创建。对于更新,它提取文档ID、计划修改及新值等信息,而对于新记忆项,则捕获其完整内容。输出格式化为易于阅读的字符串,便于审查更改或将其纳入与语言模型进一步互动的提示中。
下面是一些示例用法
这里有个例子说明了extract_tool_info如何处理spy.called_tools以生成一个易读的内存更新摘要。
spy.called_tools = [[{'name': 'PatchDoc',
'args': {'json_doc_id': '0',
'planned_edits': '1. 用包含新活动的更新内容替换现有内容:去 Tartine 吃羊角面包以及考虑今年冬天回日本。',
'patches': [{'op': 'replace',
'path': '/content',
'value': '今天早上 Lance 在旧金山骑了一段不错的自行车。之后,他去了 Tartine 吃了羊角面包。他正在考虑今年冬天再回日本。'}]},
'id': 'call_bF0w0hE4YZmGyDbuJVe1mh5H',
'type': 'tool_call'}]]
# 看看 spy.called_tools 里面具体发生了什么
schema_name = "Memory"
changes = extract_tool_info(spy.called_tools, schema_name)
print(changes)输出如下:
文档 0 更新:
计划:1. 用更新的包含新活动(去 Tartine 吃羊角面包和考虑今年冬天回日本)的内容替换现有内容。
添加的内容:今天早上 Lance 在旧金山骑了一段不错的自行车。之后,他去了 Tartine 吃了一个羊角面包,并且他还在考虑今年冬天回日本。在有了长期记忆组件的情况下,我们可以设计AI代理的图来整合所有部分。设计的核心是一个以content_generAItor函数作为核心的结构良好的流程。作为中央路由器,这个函数处理用户输入并查询现有记忆,并确定调用哪个工具——无论是更新用户档案、修改内容日历还是完善内容创作指南。这种路由确保AI社交媒体经理保持响应迅速、适应性强,并高效地处理各种任务。
这个功能的核心在于一个精心设计的提示信息——MODEL_SYSTEM_MESSAGE——它定义了代理的职责、推理过程和记忆更新机制。通过路由逻辑和提示信息,AI社交媒体管理器可以智能地回应用户互动。

内容生成器的工作流程(图片来源:作者)
分析用户输入内容 — content_generator当AI代理接收到用户的最新消息时,**content_generAItor** 函数在内存更新中起到核心作用。它将其与现有的内存组件(如用户档案、内容日历和指南)整合,并确定需要更新的内存类型。为了确保清晰和一致性,代理使用Pydantic模式,明确地定义了需要更新的内存类型。这种结构化的处理方式有助于保持代理记忆管理和演进的顺畅和有序。
class UpdateMemory(TypedDict):
""" 决定要更新哪种内存类型 """
update_type: Literal['user', 'content_calendar', 'guidelines']
def content_generAItor(state: MessagesState, config: RunnableConfig, store: BaseStore):
user_id = config["configurable"]["user_id"]
# 检索记忆
profile_memories = store.search(("profile", user_id))
user_profile = profile_memories[0].value if profile_memories else None
calendar_memories = store.search(("content_calendar", user_id))
content_calendar = "\n".join(f"{item.value}" for item in calendar_memories)
guidelines_memories = store.search(("guidelines", user_id))
guidelines = guidelines_memories[0].value if guidelines_memories else ""
# 准备系统消息
system_msg = MODEL_SYSTEM_MESSAGE.format(
user_profile=user_profile,
content_calendar=content_calendar,
guidelines=guidelines
)
# 生成回复
response = model.bind_tools([UpdateMemory], parallel_tool_calls=False).invoke(
[SystemMessage(content=system_msg)] + state["messages"]
)
return {"消息": [response]}MODEL_SYSTEM_MESSAGE提示对于content_generAItor来说非常重要,因为它用于协调这个工作流程。它充当蓝图,明确地定义了代理的角色和推理过程。我们来详细看看:
1. 定义代理的作用
你是个乐于帮助的内容创作的小助手。这一部分介绍了助理行为的背景,强调其合作和组织协调的功能。
2. 构建代理的记忆系统
你有三种类型的内存:
- 用户的个人资料(内容创作的偏好)。
- 内容日历,包含想法、截止日期、状态和草稿。
- 基于用户反馈制定的内容创作指南。
通过明确定义内存类型,这样可以确保智能体有效地组织信息。
3. 动态注入上下文环境
这是当前的用户资料:
<user_profile>
{user_profile}
</user_profile>
这里有个当前的内容日程:
<content_calendar>
{content_calendar}
</content_calendar>
这里有个当前的内容创作指南:
<guidelines>
{guidelines}
</guidelines>这一部分会利用用户当前的记忆状态,确保代理的回应是基于上下文并富有信息量的。
4. 推理与决策:
下面是处理用户消息的指导:
1. 仔细分析下面的用户消息。
2. 决定是否需要更新长期记忆:
- 如果用户提供了个人信息,请调用 UpdateMemory 工具,设置类型为 `user` 更新用户档案。
- 如果提到内容创作,请调用 UpdateMemory 工具,设置类型为 `content_calendar` 更新内容日历。
- 如果用户指定了内容日历的更新偏好,请调用 UpdateMemory 工具,设置类型为 `guidelines` 更新指示。5. 友好的用户反馈
3. 在必要时,告知用户你已更新了系统信息:
- 不要告知用户有关个人资料的更新。
- 告知用户有关内容日历更新。
- 不要提及指导方针的更新。这确保代理能自然地分享更新信息,不会让用户觉得信息太多。
6. 优先安排内容日历的更新
4. 宁可多做点更新内容日历,无需特意请示。这项指示确保代理优先更新内容规划表中的条目,保持积极主动的内容管理。
7. 自然地回答
在保存记忆或未执行任何操作后,自然地回答用户。
通过提供自然的回应,助手与用户保持了流畅自然的对话。
确定更新的类型使用 route_message 函数(路由消息函数),智能代理确定输入是否需要更新以下内容:
- 用户资料:个人偏好,比如平台选择或目标受众。
- 内容日程表:内容项目的想法、截止日期和状态。
- 指南:影响内容创作过程的反馈和建议。
def route_message(state: MessagesState, config: RunnableConfig, store: BaseStore) -> Literal[END, "update_content_calendar", "update_guidelines", "update_profile"]:
"""根据记忆和聊天历史来决定是否更新记忆集合。"""
message = state['messages'][-1]
if len(message.tool_calls) == 0:
return END
else:
tool_call = message.tool_calls[0]
if tool_call['args']['update_type'] == "user":
return "update_profile"
elif tool_call['args']['update_type'] == "content_calendar":
return "update_content_calendar"
elif tool_call['args']['update_type'] == "guidelines":
return "update_guidelines"
else:
raise ValueError通过 content_generAItor 节点来路由用户输入,并通过 route_message 函数决定适当的下一步。工作流程平滑地过渡到 工具节点。这些节点是专门负责更新不同记忆组件的。无论是完善用户资料、管理内容日历,还是调整内容创作指南,工具节点都能确保每次互动都能促进代理的成长,使其更好地符合用户需求。通过处理聊天历史,调用Trustcall进行结构化更新,并将结果保存到记忆中,这些节点构成了AI社交媒体管理器的核心操作。以下我们来分解关键工具节点的实现与目的:update_profile,update_content_calendar 和 update_guidelines。
1. 更新用户信息
这个update_profile函数能帮助代理保持对用户偏好(比如平台、语气和目标受众群体)的最新理解。
def update_profile(state: MessagesState, config: RunnableConfig, store: BaseStore):
"""根据聊天历史更新记忆集合."""
# 检索现有个人资料记忆
user_id = config["configurable"]["user_id"]
namespace = ("profile", user_id)
# 获取现有个人资料记忆
existing_items = store.search(namespace)
tool_name = "Profile"
existing_memories = ([(item.key, tool_name, item.value) for item in existing_items] if existing_items else None)
# 格式化指令并将指令与聊天历史合并
TRUSTCALL_INSTRUCTION_FORMATTED = TRUSTCALL_INSTRUCTION.format(time=datetime.now().isoformat())
updated_messages = list(merge_message_runs(messages=[SystemMessage(content=TRUSTCALL_INSTRUCTION_FORMATTED)] + state["messages"][:-1]))
# 提取更新并保存到存储中
result = profile_extractor.invoke({"messages": updated_messages, "existing": existing_memories})
for r, rmeta in zip(result["responses"], result["response_metadata"]):
store.put(namespace, rmeta.get("json_doc_id", str(uuid.uuid4())), r.model_dump(mode="json"))
tool_calls = state['messages'][-1].tool_calls
return {"messages": [{"role": "tool", "content": "已更新个人资料", "tool_call_id": tool_calls[0]['id']}]}
# Trustcall 指示
TRUSTCALL_INSTRUCTION = """反思以下交互。
使用提供的工具保留有关用户的必要记忆。
系统时间: {time}"""流程介绍:
- 检索现有个人资料数据:该功能查询内存存储以检索当前个人资料数据,使用
("profile", user_id)命名空间。这确保了更新是在用户现有的明确背景下进行,例如平台、语气和目标受众的偏好。 - 格式化和处理消息:使用
TRUSTCALL_INSTRUCTION模板创建格式化的指令,其中包括当前系统时间。该指令通过merge_message_runs与聊天历史合并,生成一个准备处理的更新消息集。 - 使用Trustcall处理更新:
profile_extractor调用Trustcall来分析更新后的消息,识别个人资料所需的任何更改。Trustcall验证并提取结构化的更新,确保与模式保持一致。 - 保存并总结更新:该功能将更新后的个人资料数据存回内存存储。每个更新都存储在唯一的标识符(
json_doc_id)下,确保可追溯性。这确保用户的个人资料保持准确,反映最新的输入。 - 返回反馈:该功能生成确认个人资料更新的响应。响应包括有关更改的信息,保持透明,完成反馈循环。
update_content_calendar函数负责管理内容日历,跟踪与内容相关任务,如创意点子、截止日期和状态更新。它确保日历根据用户输入动态更新,利用Trustcall进行结构化更新,同时Spy监控类监控变化。
def update_content_calendar(state: MessagesState, config: RunnableConfig, store: BaseStore):
user_id = config["configurable"]["user_id"]
namespace = ("content_calendar", user_id)
existing_items = store.search(namespace)
tool_name = "ContentCalendar"
existing_memories = [(item.key, tool_name, item.value) for item in existing_items] if existing_items else None
TRUSTCALL_INSTRUCTION_FORMATTED = TRUSTCALL_INSTRUCTION.format(time=datetime.now().isoformat())
updated_messages = merge_message_runs([SystemMessage(content=TRUSTCALL_INSTRUCTION_FORMATTED)] + state["messages"][:-1])
# 启动一个监视器来监视 Trustcall 的工具调用情况
spy = Spy()
content_extractor = create_extractor(model, tools=[ContentCalendar], tool_choice=tool_name, enable_inserts=True).with_listeners(on_end=spy)
result = content_extractor.invoke({"messages": updated_messages, "existing": existing_memories})
for r, rmeta in zip(result["responses"], result["response_metadata"]):
store.put(namespace, rmeta.get("json_doc_id", str(uuid.uuid4())), r.model_dump(mode="json"))
tool_calls = state['messages'][-1].tool_calls
# 提取 Trustcall 执行的变更,并添加到由 task_mAIstro 返回的信息中
content_calendar_update_msg = extract_tool_info(spy.called_tools, tool_name)
return {"messages": [{"role": "tool", "content": content_calendar_update_msg, "tool_call_id":tool_calls[0]['id']}]} 流程简介:
- 检索现有条目内容:该功能查询内存存储以检索当前内容日历条目,为更新提供上下文。
- 格式化和处理消息:它根据
TRUSTCALL_INSTRUCTION准备格式化的指令,并将其与当前聊天历史合并以生成更新后的消息。 - 使用 Trustcall 应用更新,并用 Spy 追踪工具调用:
content_extractor调用 Trustcall 应用更新,而 Spy 类跟踪工具调用,捕获有关内容日历所做更改的详细信息。 - 保存并总结更新:更新后的日历条目保存回内存存储。此外,该功能使用
extract_tool_info提取变更摘要,确保可追溯性和透明度。 - 返回反馈:该功能生成一个包含更新摘要的响应,确保更改被清晰传达并记录。
update_guidelines函数通过根据用户反馈更新内容创作指南来改进代理的行为模式。
def 更新指引(state: MessagesState, config: RunnableConfig, store: BaseStore):
user_id = config["configurable"]["user_id"]
命名空间名称 = ("guidelines", user_id)
现有内容 = store.get(命名空间名称, "content_guidelines")
系统信息 = 生成指令.format(guidelines=现有内容.value if 现有内容 else None)
新记忆 = 模型调用([SystemMessage(content=系统信息)] + state["messages"][:-1] + [HumanMessage(content="请更新指引。")])
store.put(命名空间名称, "content_guidelines", {"memory": 新记忆.content})
工具调用信息 = state['messages'][-1].tool_calls
return {"messages": [{"role": "tool", "content": "已更新指引", "tool_call_id":工具调用信息[0]['id']}]}流程概览:
- 检索现有指南:该功能查询内存存储以使用
("guidelines", user_id)命名空间访问当前的内容创作指南。如果没有找到现有的指南,则初始化为默认的空状态。 - 格式化和处理消息:准备一条系统消息,使用
CREATE_INSTRUCTIONS模板,并包含现有的指南(如果有的话)。这确保更新的指南参考了之前的用户反馈。系统消息然后与最新的聊天历史合并。 - 生成更新指南:模型处理准备的消息,并根据对话生成一组精炼的指南。此步骤使得内容创作过程能动态适应用户的需求和偏好。
- 保存和持久化更新:精炼的指南被存储回内存存储的
"content_guidelines"键下。这确保更新的指令集在未来的交互中得到保留,以符合用户的期望。 - 返回反馈:生成一条确认指南成功更新的反馈。此反馈提供了可追溯性,并向用户保证其输入已纳入代理的行为中。
AI 社交媒体管理器的功能在图编译过程中达到顶峰,将所有节点和边连接成一个统一的系统。通过结合 content_generAItor、route_message 以及专用工具节点,图定义了从头到尾的工作流程,处理用户输入、更新记忆组件和反馈到下一次互动。下面是如何组合在一起的:
构建图形StateGraph 通过 MessagesState 类来初始化,该类充当用户交互的集中状态跟踪器。这种设置使得 AI 代理的工作流程中的任务和决策能够灵活地流动起来。图中的每个节点代表一个独立的任务,并且通过定义边来协调这些任务之间的流程,确保平滑过渡和逻辑上互动的逐步推进。
# 图形设置
builder = StateGraph(MessagesState)
# 向图中添加节点
builder.add_node(content_generAItor) # 生成响应的中心节点,用于产生回复
builder.add_node(update_profile) # 更新用户档案的节点,用于更新用户资料
builder.add_node(update_content_calendar) # 更新内容日历的节点,用于更新内容日历
builder.add_node(update_guidelines) # 更新内容指南的节点,用于调整内容指南
# 定义节点之间的流程
builder.add_edge(START, "content_generAItor") # 从内容生成器开始,作为流程的起点
builder.add_conditional_edges("content_generAItor", route_message) # 根据用户输入进行路由,选择相应的路径
builder.add_edge("update_profile", "content_generAItor") # 更新档案后返回内容生成器
builder.add_edge("update_content_calendar", "content_generAItor") # 更新日历后返回内容生成器
builder.add_edge("update_guidelines", "content_generAItor") # 更新指南后返回内容生成器主节点: content_generAItor 节点作为图的核心枢纽。它处理用户的输入,获取相关的记忆组件(例如,用户资料信息、内容日历信息和指南),并负责引导对话流程。该节点封装了核心逻辑功能,确保回应既符合情境又有根据,来决定下一步行动。
这些图包含专门用于更新特定内存组件的节点:
**update_profile**:将用户资料更新为互动过程中提供的新偏好或详情。**update_content_calendar**:管理并更新与内容创作相关的任务,如创意、截止日期或状态。**update_guidelines**:根据用户反馈完善内容创作指南,确保代理符合用户期望。
每个节点完成后,会返回到content_generator继续流程,实现无缝连接。
边定义了节点之间的转换,确保任务流程既逻辑又一致:
- 工作流从生成器开始:工作流从
contentGenerator开始,处理初始的用户输入。 - 根据条件进行路由:
route_message函数根据需要更新的类型(例如update_profile、update_content_calendar或update_guidelines)动态决定要调用哪个工具模块。 - 循环返回:完成任务后,流程返回到
contentGenerator,确保能继续处理下一个用户的输入。
要有效地管理信息,该图表集成了两个记忆体系。
- 跨线程内存:由
InMemoryStore管理,这个长期记忆系统使代理能够在不同会话间保存信息,确保信息在不同会话间保持连续性。 - 单会话内存:由
MemorySaver负责,这个短期记忆系统跟踪单一对话中的上下文,提供即时反馈。
# 跨线程内存存储
across_thread_memory = InMemoryStore()
within_thread_memory = MemorySaver()该图是通过将定义的节点、边以及内存系统连接在一起形成一个统一的工作流程而编译而成。
# 编译图形:使用builder编译图,检查点保存在当前线程内存中,存储则跨线程共享。
graph = builder.compile(checkpointer=within_thread_memory, store=across_thread_memory)这一步确保每个部分都能协同运作,内存更新能够无缝地融入工作流程中。
一旦图形绘制完成,就可以进行可视化,以理解工作流程中节点和边的连接情况。图形的可视化有助于调试和理解,并让人一目了然地了解AI社交媒体助手是如何处理用户输入并在任务间切换的。
下面是一段我们用来画图的代码:
从IPython.display导入display, Image
# 可视化图结构,展示其结构
display(Image(graph.get_graph(xray=1).draw_mermaid_png()))如图所示:结果如下图所示:
内容生成器的工作流程(作者提供)
测试:AI助手在AI代理构建完成后,我们现在可以通过真实世界的场景来展示它的能力。这个互动展示突显了代理如何动态处理用户的输入,更新记忆模块,并通过长期记忆提供定制响应。从头脑风暴内容创意到管理截止日期和起草内容,这些例子展示了代理的适应性和智能。
添加新内容的想法想象一个用户为他们想要发布的新文章提供输入。助手处理输入,将其通过 content_generator 路由,并更新内容日程表。它是这样工作的:
# 我们提供一个线程ID用于短期(同一线程内的)记忆
# 我们提供一个用户ID用于长期(跨线程的)记忆
config = {"configurable": {"thread_id": "1", "user_id": "Lore"}}
# 用户输入的内容项
input_messages = [HumanMessage(content="我想写一篇关于AI代理的文章,下周五发布。")]
# 运行流程图
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()
# 检查更新的指示
user_id = "Lore"
# 进行搜索
for memory in across_thread_memory.search(("content_calendar", user_id)):
print(memory.value)输出:
{
"title": "AI 代理",
"platform": "Medium",
"deadline": "2024-12-06T00:00:00",
"status": "状态",
"tags": ["AI", "代理", "生成 AI"],
"idea": "一篇文章探讨了 AI 代理的概念、应用,及其在构建生成式 AI 应用中的使用。"
}内容日历现在反映出了新的文章构思,展示了代理动态更新和管理长期内容的灵活性。
下周的列表内容接下来,我们将测试代理如何检索信息。首先,让它列出下周所有计划的内容,代理会查询content_calendar记忆库,筛选出相关项,并提供简洁的总结:
# 用户输入的消息
input_messages = [HumanMessage(content="你能帮我列出我下周的所有内容吗?")]
# 运行图模型
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].格式化输出()输出:
================================ 人类消息 =================================
你能列出我下周的所有内容吗?
================================== AI 消息 ==================================
这是你下周的安排:
1. **Medium 文章:AI 代理**
- **日期:** 2024年12月6日(星期五)
- **想法:** 想法阶段
- **描述:** 一篇文章讲AI代理的概念,它们的应用场景,以及如何用它们来构建生成式AI。
如果你还有其他想加或改的,请告诉我!智能代理有效地从其长期存储中检索和整理信息,使规划过程更简单。
准备下周帖子的草稿最后,代理会利用它对预定内容和用户偏好的理解,生成符合用户需求的草稿,来满足用户的需求。代理帮忙起草一篇计划于下周五发布的文章。
# 用户输入的内容项
input_messages = [HumanMessage(content="你能帮我准备一下我下周五要写的文章吗?")]
# 运行图
for chunk in graph.stream({"messages": input_messages}, config, stream_mode="values"):
chunk["messages"][-1].pretty_print()得到:
================================ 人类消息 =================================
你能帮我准备周五在Medium上的文章吗?
================================== AI 消息 ==================================
当然没问题!我们先从概述关键点开始。这里有一个建议的结构:
1. **引言**
- 简要介绍AI代理的概念。
- 解释为什么它们关于AI代理很重要。
2. **什么是AI代理?**
- 定义AI代理及其特性。
- 讨论不同类型的AI代理(例如,反应式、主动式)。
3. **AI代理的应用**
- 探索AI代理在不同行业中的各种应用。
- 举例说明与生成式AI相关的具体应用。
4. **构建生成式AI应用的AI代理**
- 讨论如何将AI代理集成到生成式AI应用中。
- 为开发人员提供分步指南或框架。
5. **挑战与考虑因素**
- 讨论使用AI代理时可能遇到的挑战。
- 总结关键点。
- 鼓励开发人员在他们的项目中探索AI代理。
你想要扩展这些部分中的任何一个或者添加更多细节吗?这展示了代理生成和整合内容并根据用户的需求进行调整的能力,输出既结构化又与上下文相关的答案。
结尾通过这些例子,AI 社交媒体助手展示了其动态交互流程,流畅地更新记忆、检索相关信息资料,并协助完成创意工作,如内容草稿创作。通过结合长期记忆和结构化工作流程,该代理变成一个积极且灵活的合作伙伴。如需更多例子,请查看提供的Google Colab 笔记本,可以动手试试这个代理的实际效果!
感谢你一直读到这里!如果你喜欢这篇文章的内容,不妨看看我之前的文章,了解更多关于AI代理的内容。别忘了关注我的Medium账号,获取未来文章的更新。你的支持对我来说非常重要——祝你学习愉快,多多益善!
关注我了解更多关于人工智能的深度信息!





