[链接]
时间序列在许多领域中非常重要(虽然它常常被低估!),因为它能够准确预测未来数据点,从而有助于更好的决策、资源配置和风险管理。这种能力带来了显著的运营改进和战略优势,尤其是在金融、医疗和能源管理等行业。
深度神经网络 已成为一种流行且有效的解决方案,用于时间序列预测任务,反映了利用先进的机器学习技术来解决序列数据复杂性的日益增长的兴趣。
自监督学习法这是一种范式,通过内部生成的监督信号从未标注的数据中进行学习,通常通过预设任务实现。
与需要标注数据的监督学习不同,自监督学习则利用数据内部的结构来自动生成训练所需的标签。
时间序列自监督学习:在自监督学习的框架下,时间序列具有独特的优势,可以开发出能够从未标注的数据中学习到通用特征的模型。
这种方法可以增强时间序列预测,通过允许模型捕捉长期依赖和局部细节。然而,要有效地捕捉这些方面仍然具有挑战性,因此需要创新方法如TimeDART,该方法结合了扩散模型和自回归模型以解决这些挑战。
问题:(更口语化的表达可以是:"问题是什么呢?" 如果上下文较为非正式的话)
考虑到只需要输出翻译,且XML标签不需要出现在最终输出中,直接给出翻译如下:
问题是什么呢?时间序列的挑战是在自监督学习方法中有效地捕捉全局序列依赖和局部细节。
传统方法难以应对这两项任务,影响了它们对时间序列数据进行全面且具有表达性表示的学习能力。
解决方案是TimeDarT(或可以更口语化为:答案就是TimeDarT)。
TimeDarT简而言之,这就是时间序列预测问题的“解”!不过,这还不够!我们还得好好研究一番 :)
TimeDART,即扩散自回归变压器模型,是一种旨在进行时间序列预测的自我监督学习方法。它通过从时间序列中的过去数据中学习模式和规律来提高对未来数据点的预测。这就像将时间序列数据分解成更小的部分,称为片段,但更直接地表达为将这些片段作为建模的基础。
研究人员使用具有自注意力机制的Transformer编码器来理解这些补丁间的关系中的依赖关系,有效地捕捉到数据中的整体序列特征。
两个扩散和去噪的过程被用来解决每个补丁内的细节特征。这两个过程通过向数据添加和移除噪声来帮助捕捉局部特征(这在所有扩散模型中都非常典型)。事实上,这有助于模型更好地捕捉细节模式。
TimeDART 架构: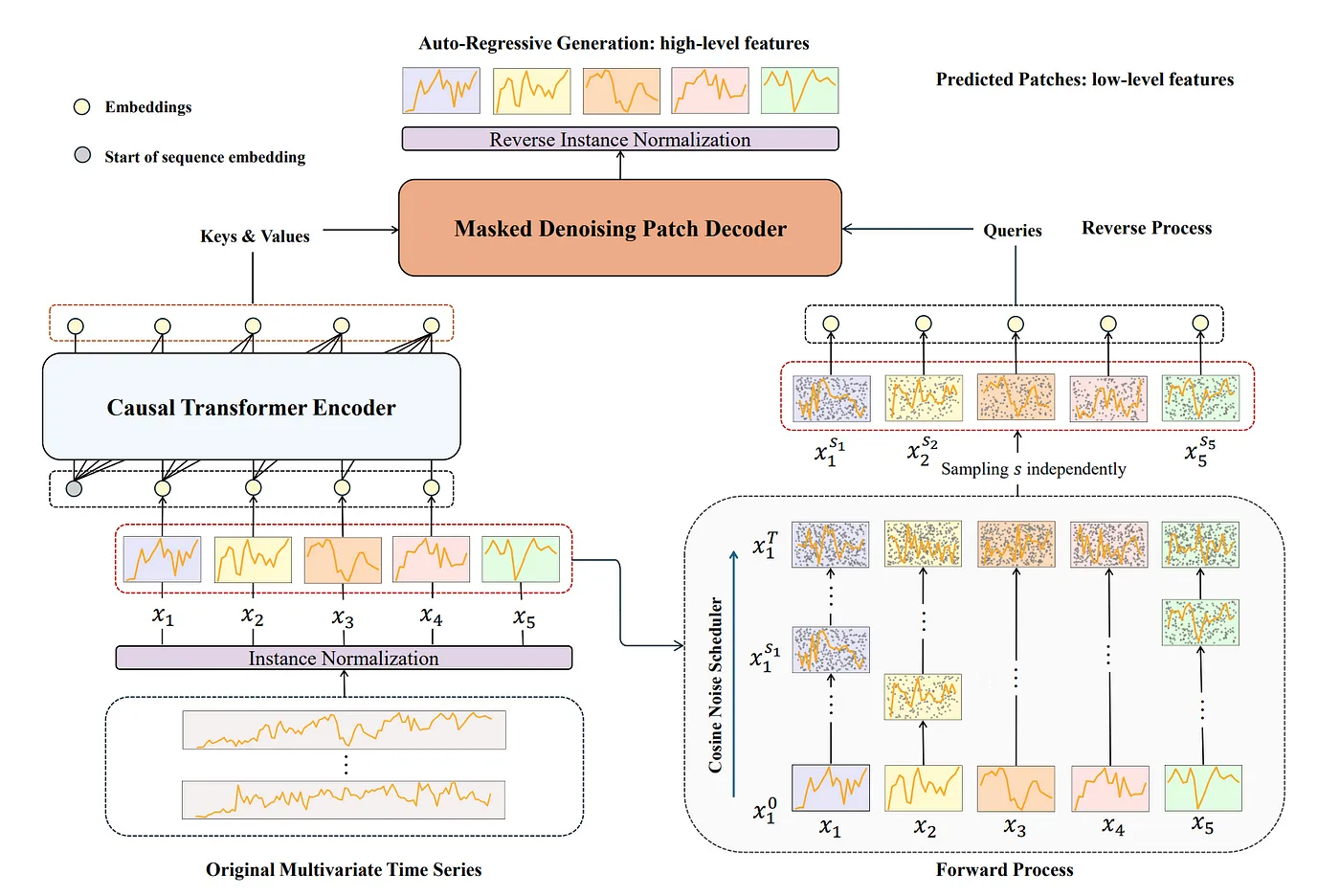
图1:TimeDART架构通过自回归生成捕捉全局依赖性,同时利用去噪扩散模型技术处理局部结构。该架构在正向扩散过程中向输入补丁引入噪声,生成自监督信息。在反向过程中,自回归地恢复原始序列。[原文]
实例正则化和补丁嵌入技术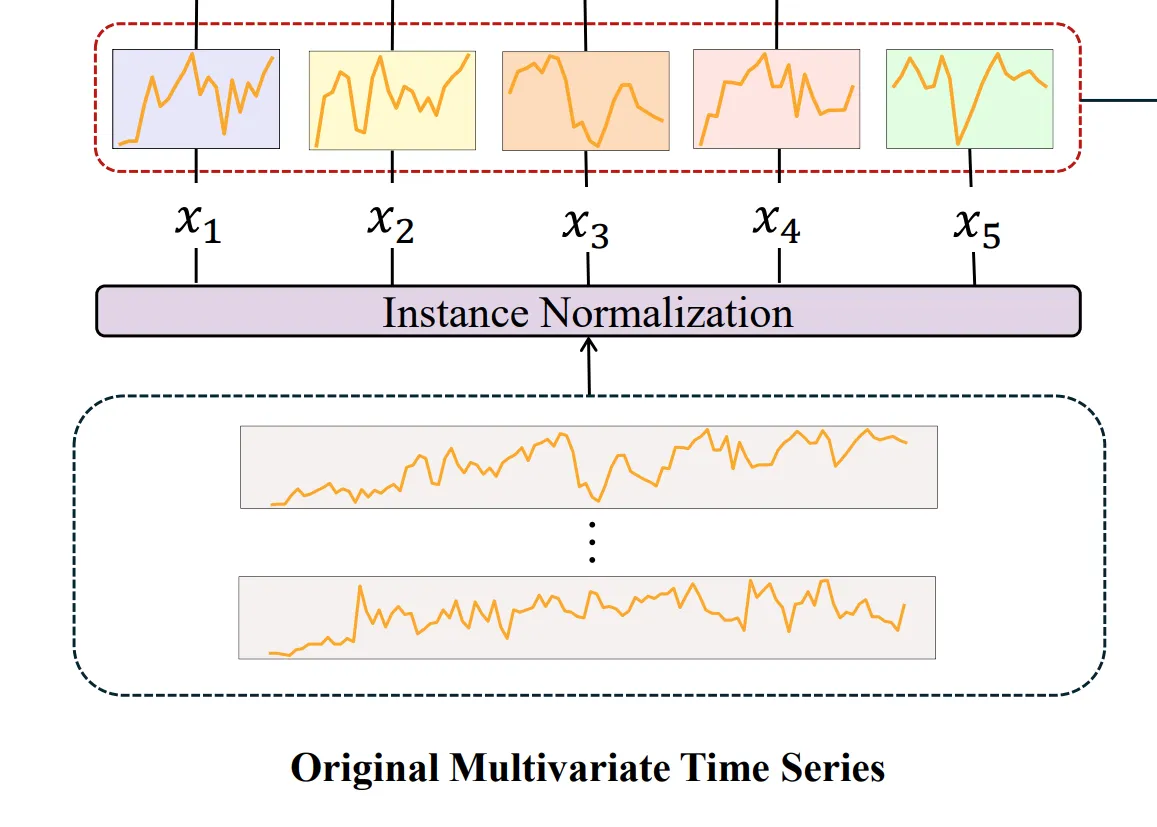
第一步是将输入的多变量时间序列数据进行实例标准化处理,以确保每个实例均值为零、标准差为一,这样有助于确保最终预测的一致性。
时间序列数据被划分为patches,而不是单独的点,这能让捕捉到更全面的局部特征。
补丁长度被设置为与步长相等,以避免信息泄漏,这有助于我们确保每个补丁仅包含原始序列的非重叠片段。
Transformer编码器用于捕捉图块间的依赖关系
我们在架构中有一个基于自注意力的Transformer编码器,这有助于描述图像补丁之间的依赖性。
这种方法有助于捕捉时间序列数据中不同部分之间的联系,从而更好地捕捉全局依赖关系。
使用Transformer编码器使得TimeDART能够学习这些有意义的跨块特征,这对于理解时间序列的高层次结构至关重要。
前向扩散过程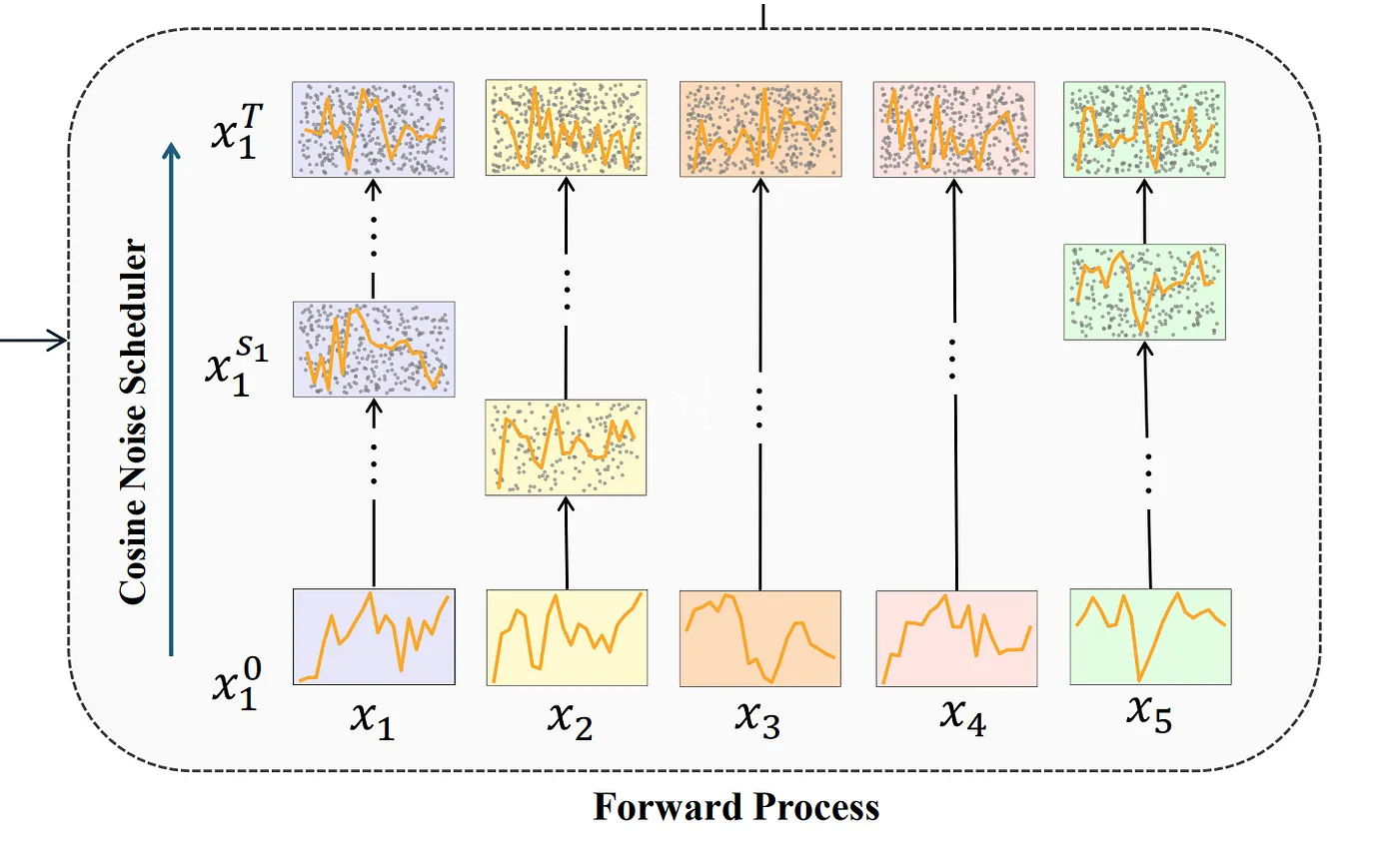
在前向扩散过程里,会在输入的图像块上添加噪声。这一步对于生成自监督信号非常重要,使模型能够通过从其噪声版本中恢复原始数据来学习稳健的表示。
这种噪声有助于模型识别出并集中注意力在时间序列数据里的内在模式。
基于交叉注意力机制的去噪解码器模型降噪解码器采用了一种跨注意力机制(cross-attention机制)来重新构建原始干净的补丁。
这使得可调节的优化难度,使自监督任务更加有效,并使模型能够专注于捕捉更详细的局部特征。这种设计增强了模型学习全局和局部特征的能力。

它将噪音(作为查询)和编码器的输出(键和值)输入,并屏蔽解码器,以确保添加到噪音中的第j个输入对应于从Transformer编码器输出的第j个结果。
自回归生成中的全局依赖关系
责任在于捕捉时间序列中的高层次全局依赖关系。通过自回归方式恢复原始序列,模型可以理解整体的时间模式和依赖性,从而能够提高其预测能力。
优化和调整细节最后,整个模型以自回归地进行优化,以获得可以针对特定预测任务进行微调的可转移的表示。这一步确保了模型学习到的表示既全面又适应性不同的各种下游应用,从而使在时间序列预测任务中表现出优越性能。
瑞典语评价如下:(Note: Since the source text was in English and there was no indication of changing the language to Swedish, I kept the translation in Chinese as "# 评价:" with the expert suggestion of adding "如下" for better fluency and naturalness.)
数据集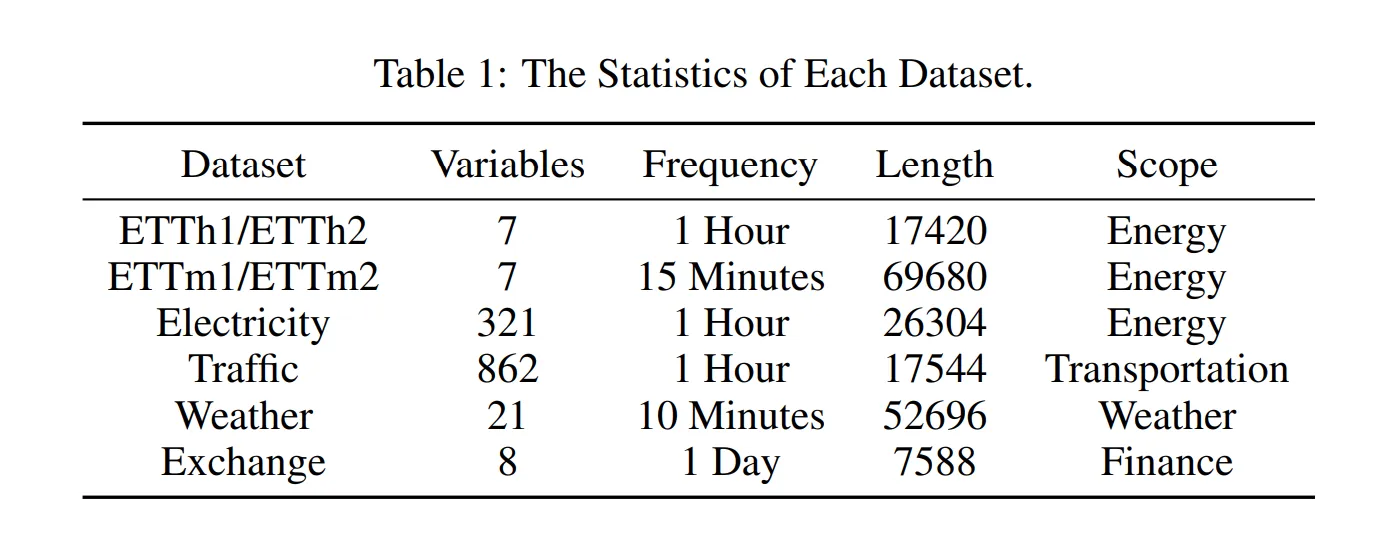
TimeDART模型在八个流行的數據集上进行了评估,以测试其在时间序列预测方面的有效性。这些数据集包括四个ETT数据集(ETTh1、ETTh2、ETTm1、ETTm2),以及Weather、Exchange、Electricity和交通数据集。
这些数据集涵盖了各种应用领域,如电力系统、交通网络和天气预报。(正如我之前所说,时间序列在各个领域都很关键)
结果如下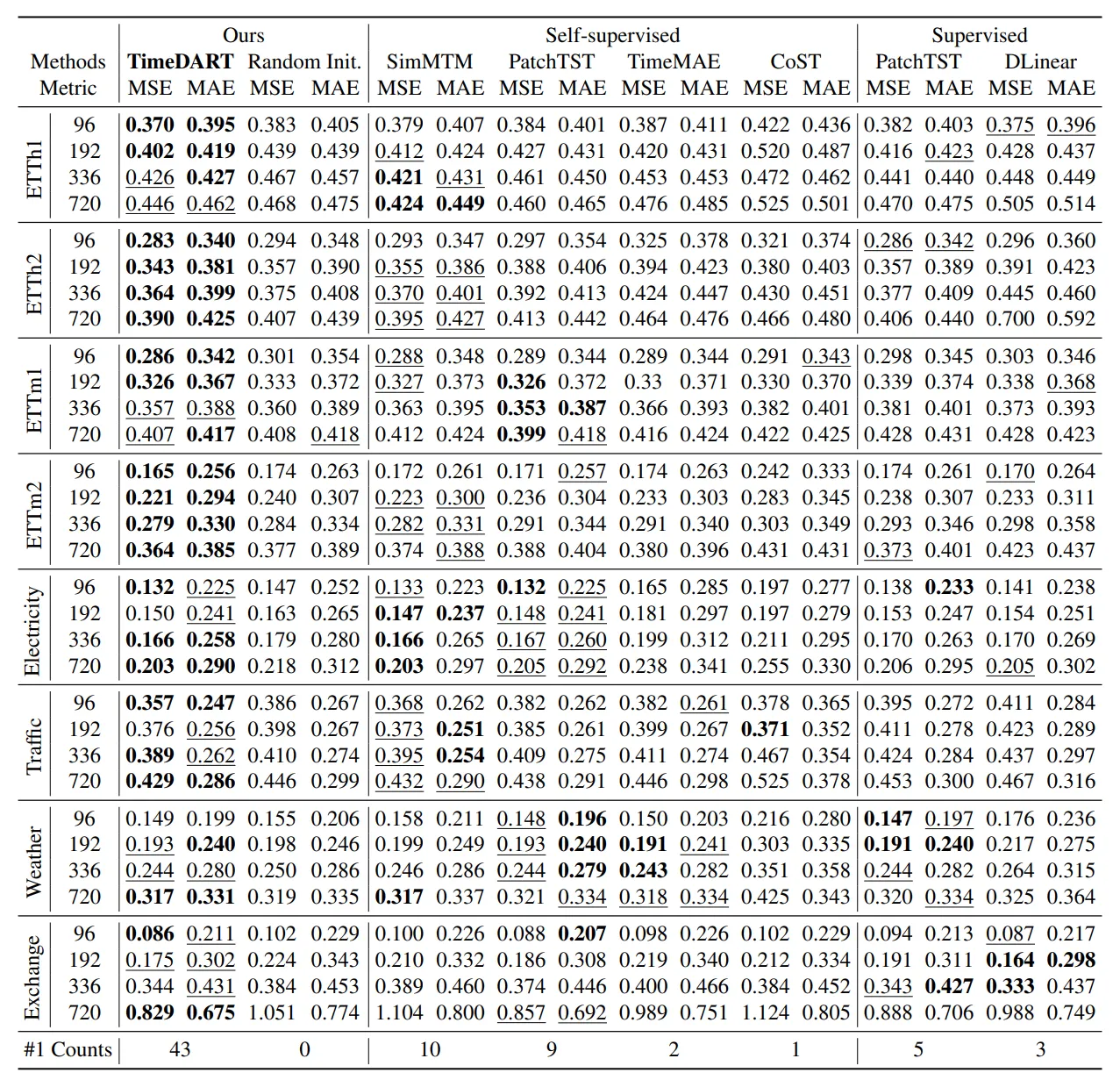
表1. TimeDART与顶尖的自监督和监督方法在多变量时间序列预测的比较结果。最佳结果用粗体标注,次佳结果用下划线标注。“最佳次数”表示该方法获得最佳结果的频率。
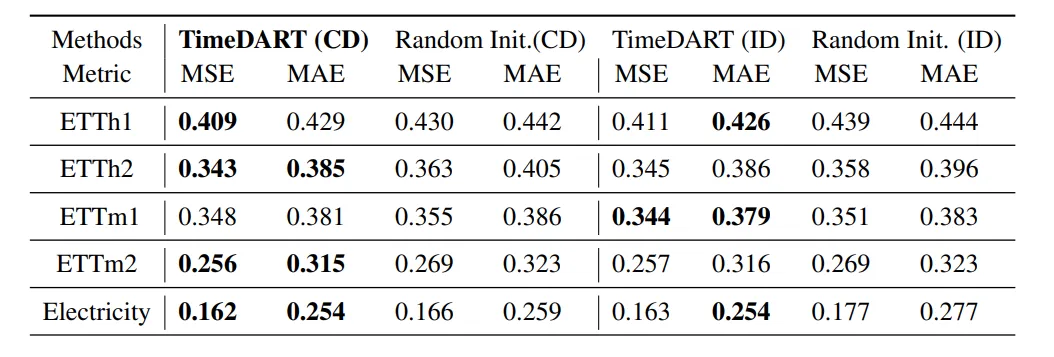
表2. 多变量时间序列预测结果比较,TimeDART在五个数据集上进行预训练并针对特定数据集进行微调。所有结果均为四种不同的预测窗口({96, 192, 336, 720})的平均值。最佳结果以粗体突出显示。【来源】:https://arxiv.org/pdf/2410.05711
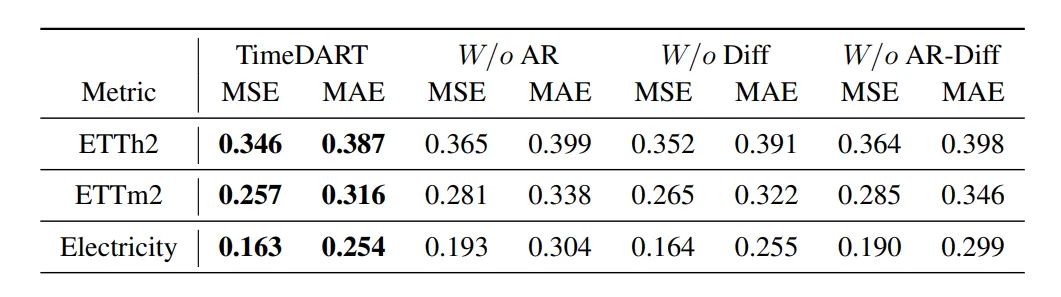
消融分析。这些结果是通过四个不同的预测时间窗口{96, 192, 336, 720}计算的平均值。最佳结果以加粗显示。[原文链接]
请注意,研究人员提到了更多关于工作的细节,如超参数等细节;然而,为了避免文章过长,我没有提及这些内容,并参阅原文:原论文。
我得到了一些来自AI的帮助,具体来说,我使用了Nouswise.com的帮助来写这篇文章,你可以在Nouswise上找到这篇论文和其他数百万篇AI论文。