
Binder的实现是比较复杂的,想要完全弄明白是怎么一回事,并不是一件容易的事情。
这里面牵涉到好几个层次,每一层都有一些模块和机制需要理解。这部分内容预计会分为三篇文章来讲解。本文是第一篇,首先会对整个Binder机制做一个架构性的讲解,然后会将大部分精力用来讲解Binder机制中最核心的部分:Binder驱动的实现。
Binder机制简介
Binder源自Be Inc公司开发的OpenBinder框架,后来该框架转移的Palm Inc,由Dianne Hackborn主导开发。OpenBinder的内核部分已经合入Linux Kernel 3.19。
Android Binder是在OpneBinder上的定制实现。原先的OpenBinder框架现在已经不再继续开发,可以说Android上的Binder让原先的OpneBinder得到了重生。
Binder是Android系统中大量使用的IPC(Inter-process communication,进程间通讯)机制。无论是应用程序对系统服务的请求,还是应用程序自身提供对外服务,都需要使用到Binder。
因此,Binder机制在Android系统中的地位非常重要,可以说,理解Binder是理解Android系统的绝对必要前提。
在Unix/Linux环境下,传统的IPC机制包括:
管道
消息队列
共享内存
信号量
Socket
等。
由于篇幅所限,本文不会对这些IPC机制做讲解,有兴趣的读者可以参阅《UNIX网络编程 卷2:进程间通信》。
Android系统中对于传统的IPC使用较少(但也有使用,例如:在请求Zygote fork进程的时候使用的是Socket IPC),大部分场景下使用的IPC都是Binder。
Binder相较于传统IPC来说更适合于Android系统,具体原因的包括如下三点:
Binder本身是C/S架构的,这一点更符合Android系统的架构
性能上更有优势:管道,消息队列,Socket的通讯都需要两次数据拷贝,而Binder只需要一次。要知道,对于系统底层的IPC形式,少一次数据拷贝,对整体性能的影响是非常之大的
安全性更好:传统IPC形式,无法得到对方的身份标识(UID/GID),而在使用Binder IPC时,这些身份标示是跟随调用过程而自动传递的。Server端很容易就可以知道Client端的身份,非常便于做安全检查
整体架构
Binder整体架构如下所示:
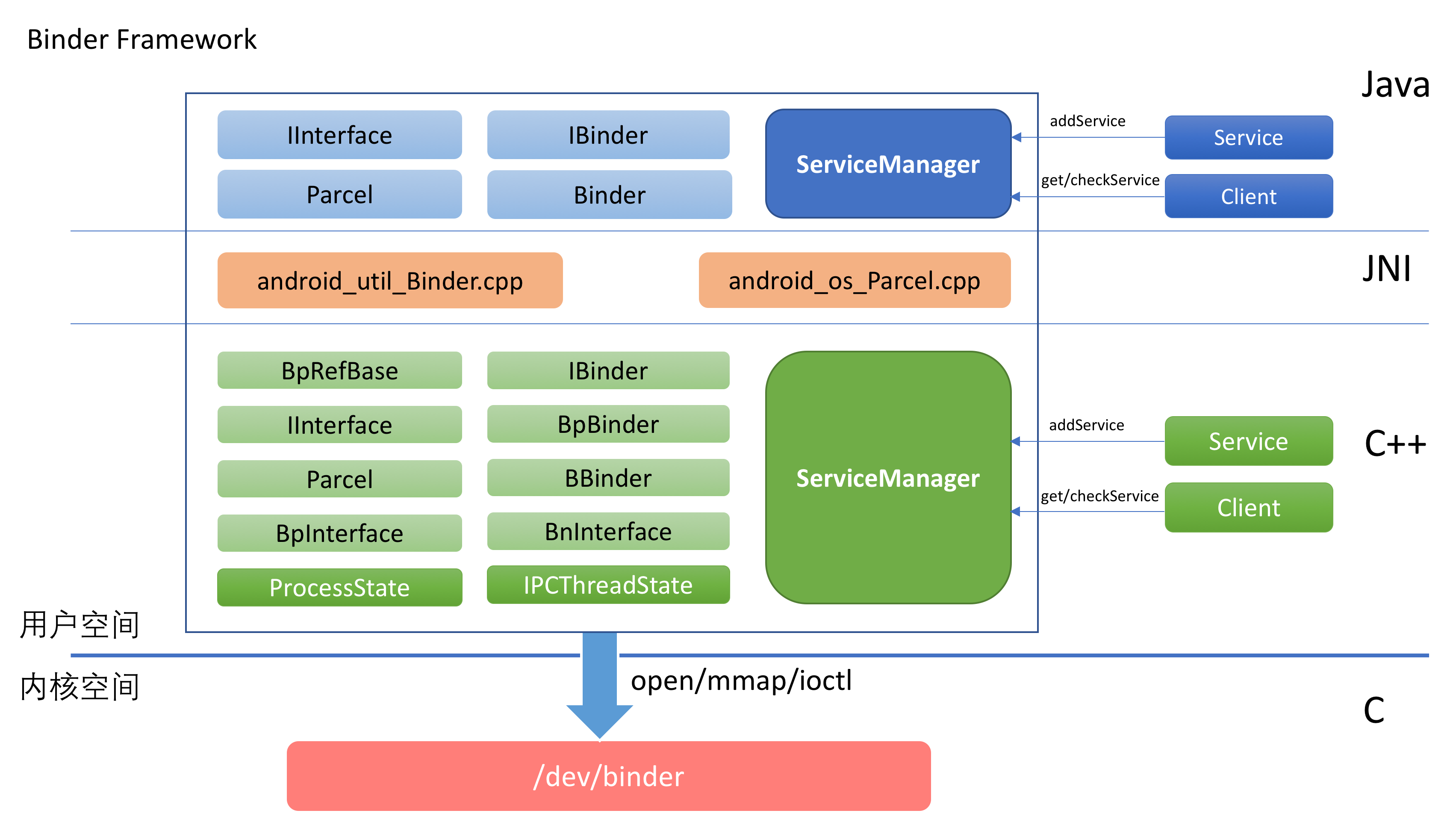
从图中可以看出,Binder的实现分为这么几层:
Framework层
Java部分
JNI部分
C++部分
驱动层
驱动层位于Linux内核中,它提供了最底层的数据传递,对象标识,线程管理,调用过程控制等功能。驱动层是整个Binder机制的核心。
Framework层以驱动层为基础,提供了应用开发的基础设施。
Framework层既包含了C++部分的实现,也包含了Java部分的实现。为了能将C++的实现复用到Java端,中间通过JNI进行衔接。
开发者可以在Framework之上利用Binder提供的机制来进行具体的业务逻辑开发。其实不仅仅是第三方开发者,Android系统中本身也包含了很多系统服务都是基于Binder框架开发的。
既然是“进程间”通讯就至少牵涉到两个进程,Binder框架是典型的C/S架构。在下文中,我们把服务的请求方称之为Client,服务的实现方称之为Server。
Client对于Server的请求会经由Binder框架由上至下传递到内核的Binder驱动中,请求中包含了Client将要调用的命令和参数。请求到了Binder驱动之后,在确定了服务的提供方之后,会再从下至上将请求传递给具体的服务。整个调用过程如下图所示:

对网络协议有所了解的读者会发现,这个数据的传递过程和网络协议是如此的相似。
初识ServiceManager
前面已经提到,使用Binder框架的既包括系统服务,也包括第三方应用。因此,在同一时刻,系统中会有大量的Server同时存在。那么,Client在请求Server的时候,是如果确定请求发送给哪一个Server的呢?
这个问题,就和我们现实生活中如何找到一个公司/商场,如何确定一个人/一辆车一样,解决的方法就是:每个目标对象都需要一个唯一的标识。并且,需要有一个组织来管理这个唯一的标识。
而Binder框架中负责管理这个标识的就是ServiceManager。ServiceManager对于Binder Server的管理就好比车管所对于车牌号码的的管理,派出所对于身份证号码的管理:每个公开对外提供服务的Server都需要注册到ServiceManager中(通过addService),注册的时候需要指定一个唯一的id(这个id其实就是一个字符串)。
Client要对Server发出请求,就必须知道服务端的id。Client需要先根据Server的id通过ServerManager拿到Server的标示(通过getService),然后通过这个标示与Server进行通信。
整个过程如下图所示:

如果上面这些介绍已经让你一头雾水,请不要过分担心,下面会详细讲解这其中的细节。
下文会以自下而上的方式来讲解Binder框架。自下而上未必是最好的方法,每个人的思考方式不一样,如果你更喜欢自上而下的理解,你也按这样的顺序来阅读。
对于大部分人来说,我们可能需要反复的查阅才能完全理解。
驱动层
源码路径(这部分代码不在AOSP中,而是位于Linux内核代码中):
/kernel/drivers/android/binder.c/kernel/include/uapi/linux/android/binder.h
或者
/kernel/drivers/staging/android/binder.c/kernel/drivers/staging/android/uapi/binder.h
Binder机制的实现中,最核心的就是Binder驱动。 Binder是一个miscellaneous类型的驱动,本身不对应任何硬件,所有的操作都在软件层。 binder_init函数负责Binder驱动的初始化工作,该函数中大部分代码是在通过debugfs_create_dir和debugfs_create_file函数创建debugfs对应的文件。 如果内核在编译时打开了debugfs,则通过adb shell连上设备之后,可以在设备的这个路径找到debugfs对应的文件:/sys/kernel/debug。Binder驱动中创建的debug文件如下所示:
# ls -l /sys/kernel/debug/binder/ total 0-r--r--r-- 1 root root 0 1970-01-01 00:00 failed_transaction_logdrwxr-xr-x 2 root root 0 1970-05-09 01:19 proc-r--r--r-- 1 root root 0 1970-01-01 00:00 state-r--r--r-- 1 root root 0 1970-01-01 00:00 stats-r--r--r-- 1 root root 0 1970-01-01 00:00 transaction_log-r--r--r-- 1 root root 0 1970-01-01 00:00 transactions
这些文件其实都在内存中的,实时的反应了当前Binder的使用情况,在实际的开发过程中,这些信息可以帮忙分析问题。例如,可以通过查看/sys/kernel/debug/binder/proc目录来确定哪些进程正在使用Binder,通过查看transaction_log和transactions文件来确定Binder通信的数据。
binder_init函数中最主要的工作其实下面这行:
ret = misc_register(&binder_miscdev);
该行代码真正向内核中注册了Binder设备。binder_miscdev的定义如下:
static struct miscdevice binder_miscdev = {
.minor = MISC_DYNAMIC_MINOR,
.name = "binder",
.fops = &binder_fops
};这里指定了Binder设备的名称是“binder”。这样,在用户空间便可以通过对/dev/binder文件进行操作来使用Binder。
binder_miscdev同时也指定了该设备的fops。fops是另外一个结构体,这个结构中包含了一系列的函数指针,其定义如下:
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};这里除了owner之外,每一个字段都是一个函数指针,这些函数指针对应了用户空间在使用Binder设备时的操作。例如:binder_poll对应了poll系统调用的处理,binder_mmap对应了mmap系统调用的处理,其他类同。
这其中,有三个函数尤为重要,它们是:binder_open,binder_mmap和binder_ioctl。 这是因为,需要使用Binder的进程,几乎总是先通过binder_open打开Binder设备,然后通过binder_mmap进行内存映射。
在这之后,通过binder_ioctl来进行实际的操作。Client对于Server端的请求,以及Server对于Client请求结果的返回,都是通过ioctl完成的。
这里提到的流程如下图所示:

主要结构
Binder驱动中包含了很多的结构体。为了便于下文讲解,这里我们先对这些结构体做一些介绍。
驱动中的结构体可以分为两类:
一类是与用户空间共用的,这些结构体在Binder通信协议过程中会用到。因此,这些结构体定义在binder.h中,包括:
| 结构体名称 | 说明 |
|---|---|
| flat_binder_object | 描述在Binder IPC中传递的对象,见下文 |
| binder_write_read | 存储一次读写操作的数据 |
| binder_version | 存储Binder的版本号 |
| transaction_flags | 描述事务的flag,例如是否是异步请求,是否支持fd |
| binder_transaction_data | 存储一次事务的数据 |
| binder_ptr_cookie | 包含了一个指针和一个cookie |
| binder_handle_cookie | 包含了一个句柄和一个cookie |
| binder_pri_desc | 暂未用到 |
| binder_pri_ptr_cookie | 暂未用到 |
这其中,binder_write_read和binder_transaction_data这两个结构体最为重要,它们存储了IPC调用过程中的数据。关于这一点,我们在下文中会讲解。
Binder驱动中,还有一类结构体是仅仅Binder驱动内部实现过程中需要的,它们定义在binder.c中,包括:
| 结构体名称 | 说明 |
|---|---|
| binder_node | 描述Binder实体节点,即:对应了一个Server |
| binder_ref | 描述对于Binder实体的引用 |
| binder_buffer | 描述Binder通信过程中存储数据的Buffer |
| binder_proc | 描述使用Binder的进程 |
| binder_thread | 描述使用Binder的线程 |
| binder_work | 描述通信过程中的一项任务 |
| binder_transaction | 描述一次事务的相关信息 |
| binder_deferred_state | 描述延迟任务 |
| binder_ref_death | 描述Binder实体死亡的信息 |
| binder_transaction_log | debugfs日志 |
| binder_transaction_log_entry | debugfs日志条目 |
这里需要读者关注的结构体已经用加粗做了标注。
Binder协议
Binder协议可以分为控制协议和驱动协议两类。
控制协议是进程通过ioctl(“/dev/binder”) 与Binder设备进行通讯的协议,该协议包含以下几种命令:
| 命令 | 说明 | 参数类型 |
|---|---|---|
| BINDER_WRITE_READ | 读写操作,最常用的命令。IPC过程就是通过这个命令进行数据传递 | binder_write_read |
| BINDER_SET_MAX_THREADS | 设置进程支持的最大线程数量 | size_t |
| BINDER_SET_CONTEXT_MGR | 设置自身为ServiceManager | 无 |
| BINDER_THREAD_EXIT | 通知驱动Binder线程退出 | 无 |
| BINDER_VERSION | 获取Binder驱动的版本号 | binder_version |
| BINDER_SET_IDLE_PRIORITY | 暂未用到 | - |
| BINDER_SET_IDLE_TIMEOUT | 暂未用到 | - |
Binder的驱动协议描述了对于Binder驱动的具体使用过程。驱动协议又可以分为两类:
一类是
binder_driver_command_protocol,描述了进程发送给Binder驱动的命令一类是
binder_driver_return_protocol,描述了Binder驱动发送给进程的命令
binder_driver_command_protocol共包含17个命令,分别是:
| 命令 | 说明 | 参数类型 |
|---|---|---|
| BC_TRANSACTION | Binder事务,即:Client对于Server的请求 | binder_transaction_data |
| BC_REPLY | 事务的应答,即:Server对于Client的回复 | binder_transaction_data |
| BC_FREE_BUFFER | 通知驱动释放Buffer | binder_uintptr_t |
| BC_ACQUIRE | 强引用计数+1 | __u32 |
| BC_RELEASE | 强引用计数-1 | __u32 |
| BC_INCREFS | 弱引用计数+1 | __u32 |
| BC_DECREFS | 弱引用计数-1 | __u32 |
| BC_ACQUIRE_DONE | BR_ACQUIRE的回复 | binder_ptr_cookie |
| BC_INCREFS_DONE | BR_INCREFS的回复 | binder_ptr_cookie |
| BC_ENTER_LOOPER | 通知驱动主线程ready | void |
| BC_REGISTER_LOOPER | 通知驱动子线程ready | void |
| BC_EXIT_LOOPER | 通知驱动线程已经退出 | void |
| BC_REQUEST_DEATH_NOTIFICATION | 请求接收死亡通知 | binder_handle_cookie |
| BC_CLEAR_DEATH_NOTIFICATION | 去除接收死亡通知 | binder_handle_cookie |
| BC_DEAD_BINDER_DONE | 已经处理完死亡通知 | binder_uintptr_t |
| BC_ATTEMPT_ACQUIRE | 暂未实现 | - |
| BC_ACQUIRE_RESULT | 暂未实现 | - |
binder_driver_return_protocol共包含18个命令,分别是:
| 返回类型 | 说明 | 参数类型 |
|---|---|---|
| BR_OK | 操作完成 | void |
| BR_NOOP | 操作完成 | void |
| BR_ERROR | 发生错误 | __s32 |
| BR_TRANSACTION | 通知进程收到一次Binder请求(Server端) | binder_transaction_data |
| BR_REPLY | 通知进程收到Binder请求的回复(Client) | binder_transaction_data |
| BR_TRANSACTION_COMPLETE | 驱动对于接受请求的确认回复 | void |
| BR_FAILED_REPLY | 告知发送方通信目标不存在 | void |
| BR_SPAWN_LOOPER | 通知Binder进程创建一个新的线程 | void |
| BR_ACQUIRE | 强引用计数+1请求 | binder_ptr_cookie |
| BR_RELEASE | 强引用计数-1请求 | binder_ptr_cookie |
| BR_INCREFS | 弱引用计数+1请求 | binder_ptr_cookie |
| BR_DECREFS | 若引用计数-1请求 | binder_ptr_cookie |
| BR_DEAD_BINDER | 发送死亡通知 | binder_uintptr_t |
| BR_CLEAR_DEATH_NOTIFICATION_DONE | 清理死亡通知完成 | binder_uintptr_t |
| BR_DEAD_REPLY | 告知发送方对方已经死亡 | void |
| BR_ACQUIRE_RESULT | 暂未实现 | - |
| BR_ATTEMPT_ACQUIRE | 暂未实现 | - |
| BR_FINISHED | 暂未实现 | - |
单独看上面的协议可能很难理解,这里我们以一次Binder请求过程来详细看一下Binder协议是如何通信的,就比较好理解了。
这幅图的说明如下:
Binder是C/S架构的,通信过程牵涉到:Client,Server以及Binder驱动三个角色
Client对于Server的请求以及Server对于Client回复都需要通过Binder驱动来中转数据
BC_XXX命令是进程发送给驱动的命令
BR_XXX命令是驱动发送给进程的命令
整个通信过程由Binder驱动控制

这里再补充说明一下,通过上面的Binder协议的说明中我们看到,Binder协议的通信过程中,不仅仅是发送请求和接受数据这些命令。同时包括了对于引用计数的管理和对于死亡通知的管理(告知一方,通讯的另外一方已经死亡)等功能。
这些功能的通信过程和上面这幅图是类似的:一方发送BC_XXX,然后由驱动控制通信过程,接着发送对应的BR_XXX命令给通信的另外一方。因为这种相似性,对于这些内容就不再赘述了。
在有了上面这些背景知识介绍之后,我们就可以进入到Binder驱动的内部实现中来一探究竟了。
PS:上面介绍的这些结构体和协议,因为内容较多,初次看完记不住是很正常的,在下文详细讲解的时候,回过头来对照这些表格来理解是比较有帮助的。
打开Binder设备
任何进程在使用Binder之前,都需要先通过open("/dev/binder")打开Binder设备。上文已经提到,用户空间的open系统调用对应了驱动中的binder_open函数。在这个函数,Binder驱动会为调用的进程做一些初始化工作。binder_open函数代码如下所示:
static int binder_open(struct inode *nodp, struct file *filp)
{
struct binder_proc *proc; // 创建进程对应的binder_proc对象
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL) return -ENOMEM;
get_task_struct(current);
proc->tsk = current; // 初始化binder_proc
INIT_LIST_HEAD(&proc->todo);
init_waitqueue_head(&proc->wait);
proc->default_priority = task_nice(current); // 锁保护
binder_lock(__func__);
binder_stats_created(BINDER_STAT_PROC); // 添加到全局列表binder_procs中
hlist_add_head(&proc->proc_node, &binder_procs);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
filp->private_data = proc;
binder_unlock(__func__); return 0;
}在Binder驱动中,通过binder_procs记录了所有使用Binder的进程。每个初次打开Binder设备的进程都会被添加到这个列表中的。
另外,请读者回顾一下上文介绍的Binder驱动中的几个关键结构体:
binder_proc
binder_node
binder_thread
binder_ref
binder_buffer
在实现过程中,为了便于查找,这些结构体互相之间都留有字段存储关联的结构。
下面这幅图描述了这里说到的这些内容:

内存映射(mmap)
在打开Binder设备之后,进程还会通过mmap进行内存映射。mmap的作用有如下两个:
申请一块内存空间,用来接收Binder通信过程中的数据
对这块内存进行地址映射,以便将来访问
binder_mmap函数对应了mmap系统调用的处理,这个函数也是Binder驱动的精华所在(这里说的binder_mmap函数也包括其内部调用的binder_update_page_range函数,见下文)。
前文我们说到,使用Binder机制,数据只需要经历一次拷贝就可以了,其原理就在这个函数中。
binder_mmap这个函数中,会申请一块物理内存,然后在用户空间和内核空间同时对应到这块内存上。在这之后,当有Client要发送数据给Server的时候,只需一次,将Client发送过来的数据拷贝到Server端的内核空间指定的内存地址即可,由于这个内存地址在服务端已经同时映射到用户空间,因此无需再做一次复制,Server即可直接访问,整个过程如下图所示:

这幅图的说明如下:
Server在启动之后,调用对/dev/binder设备调用mmap
内核中的binder_mmap函数进行对应的处理:申请一块物理内存,然后在用户空间和内核空间同时进行映射
Client通过BINDER_WRITE_READ命令发送请求,这个请求将先到驱动中,同时需要将数据从Client进程的用户空间拷贝到内核空间
驱动通过BR_TRANSACTION通知Server有人发出请求,Server进行处理。由于这块内存也在用户空间进行了映射,因此Server进程的代码可以直接访问
了解原理之后,我们再来看一下Binder驱动的相关源码。这段代码有两个函数:
binder_mmap函数对应了mmap的系统调用的处理binder_update_page_range函数真正实现了内存分配和地址映射
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
struct vm_struct *area;
struct binder_proc *proc = filp->private_data; const char *failure_string;
struct binder_buffer *buffer;
... // 在内核空间获取一块地址范围
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP); if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area"; goto err_get_vm_area_failed;
}
proc->buffer = area->addr; // 记录内核空间与用户空间的地址偏移
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
...
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL); if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array"; goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc; /* binder_update_page_range assumes preemption is disabled */
preempt_disable(); // 通过下面这个函数真正完成内存的申请和地址的映射
// 初次使用,先申请一个PAGE_SIZE大小的内存
ret = binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma);
...
}static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
void *page_addr;
unsigned long user_page_addr;
struct vm_struct tmp_area;
struct page **page;
struct mm_struct *mm;
... for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
struct page **page_array_ptr;
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
BUG_ON(*page); // 真正进行内存的分配
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO); if (*page == NULL) {
pr_err("%d: binder_alloc_buf failed for page at %p\n",
proc->pid, page_addr); goto err_alloc_page_failed;
}
tmp_area.addr = page_addr;
tmp_area.size = PAGE_SIZE + PAGE_SIZE /* guard page? */;
page_array_ptr = page; // 在内核空间进行内存映射
ret = map_vm_area(&tmp_area, PAGE_KERNEL, &page_array_ptr); if (ret) {
pr_err("%d: binder_alloc_buf failed to map page at %p in kernel\n",
proc->pid, page_addr); goto err_map_kernel_failed;
}
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset; // 在用户空间进行内存映射
ret = vm_insert_page(vma, user_page_addr, page[0]); if (ret) {
pr_err("%d: binder_alloc_buf failed to map page at %lx in userspace\n",
proc->pid, user_page_addr); goto err_vm_insert_page_failed;
} /* vm_insert_page does not seem to increment the refcount */
} if (mm) {
up_write(&mm->mmap_sem);
mmput(mm);
}
preempt_disable(); return 0;
...在开发过程中,我们可以通过procfs看到进程映射的这块内存空间:
将Android设备连接到电脑上之后,通过
adb shell进入到终端然后选择一个使用了Binder的进程,例如system_server(这是系统中一个非常重要的进程,下一章我们会专门讲解),通过
ps | grep system_server来确定进程号,例如是1889通过
cat /proc/[pid]/maps | grep "/dev/binder"过滤出这块内存的地址
在我的Nexus 6P上,控制台输出如下:
angler:/ # ps | grep system_server system 1889 526 2353404 140016 SyS_epoll_ 72972eeaf4 S system_server angler:/ # cat /proc/1889/maps | grep "/dev/binder" 7294761000-729485f000 r--p 00000000 00:0c 12593 /dev/binder
PS:grep是通过通配符进行匹配过滤的命令,“|”是Unix上的管道命令。即将前一个命令的输出给下一个命令作为输入。如果这里我们不加“ | grep xxx”,那么将看到前一个命令的完整输出。
内存的管理
上文中,我们看到binder_mmap的时候,会申请一个PAGE_SIZE(通常是4K)的内存。而实际使用过程中,一个PAGE_SIZE的大小通常是不够的。
在驱动中,会根据实际的使用情况进行内存的分配。有内存的分配,当然也需要内存的释放。这里我们就来看看Binder驱动中是如何进行内存的管理的。
首先,我们还是从一次IPC请求说起。
当一个Client想要对Server发出请求时,它首先将请求发送到Binder设备上,由Binder驱动根据请求的信息找到对应的目标节点,然后将请求数据传递过去。
进程通过ioctl系统调用来发出请求:ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr)
PS:这行代码来自于Framework层的IPCThreadState类。在后文中,我们将看到,IPCThreadState类专门负责与驱动进行通信。
这里的mProcess->mDriverFD对应了打开Binder设备时的fd。BINDER_WRITE_READ对应了具体要做的操作码,这个操作码将由Binder驱动解析。bwr存储了请求数据,其类型是binder_write_read。
binder_write_read其实是一个相对外层的数据结构,其内部会包含一个binder_transaction_data结构的数据。binder_transaction_data包含了发出请求者的标识,请求的目标对象以及请求所需要的参数。它们的关系如下图所示:

binder_ioctl函数对应了ioctl系统调用的处理。这个函数的逻辑比较简单,就是根据ioctl的命令来确定进一步处理的逻辑,具体如下:
如果命令是BINDER_WRITE_READ,并且
如果 bwr.write_size > 0,则调用binder_thread_write
如果 bwr.read_size > 0,则调用binder_thread_read
如果命令是BINDER_SET_MAX_THREADS,则设置进程的max_threads,即进程支持的最大线程数
如果命令是BINDER_SET_CONTEXT_MGR,则设置当前进程为ServiceManager,见下文
如果命令是BINDER_THREAD_EXIT,则调用binder_free_thread,释放binder_thread
如果命令是BINDER_VERSION,则返回当前的Binder版本号
这其中,最关键的就是binder_thread_write方法。当Client请求Server的时候,便会发送一个BINDER_WRITE_READ命令,同时框架会将将实际的数据包装好。此时,binder_transaction_data中的code将是BC_TRANSACTION,由此便会调用到binder_transaction方法,这个方法是对一次Binder事务的处理,这其中会调用binder_alloc_buf函数为此次事务申请一个缓存。这里提到到调用关系如下:

binder_update_page_range这个函数在上文中,我们已经看到过了。其作用就是:进行内存分配并且完成内存的映射。而binder_alloc_buf函数,正如其名称那样的:完成缓存的分配。
在驱动中,通过binder_buffer结构体描述缓存。一次Binder事务就会对应一个binder_buffer,其结构如下所示:
struct binder_buffer { struct list_head entry; struct rb_node rb_node; unsigned free:1; unsigned allow_user_free:1; unsigned async_transaction:1; unsigned debug_id:29; struct binder_transaction *transaction; struct binder_node *target_node; size_t data_size; size_t offsets_size; uint8_t data[0];
};而在binder_proc(描述了使用Binder的进程)中,包含了几个字段用来管理进程在Binder IPC过程中缓存,如下:
struct binder_proc {
... struct list_head buffers; // 进程拥有的buffer列表
struct rb_root free_buffers; // 空闲buffer列表
struct rb_root allocated_buffers; // 已使用的buffer列表
size_t free_async_space; // 剩余的异步调用的空间
size_t buffer_size; // 缓存的上限
...
};进程在mmap时,会设定支持的总缓存大小的上限(下文会讲到)。而进程每当收到BC_TRANSACTION,就会判断已使用缓存加本次申请的和有没有超过上限。如果没有,就考虑进行内存的分配。
进程的空闲缓存记录在binder_proc的free_buffers中,这是一个以红黑树形式存储的结构。每次尝试分配缓存的时候,会从这里面按大小顺序进行查找,找到最接近需要的一块缓存。查找的逻辑如下:
while (n) {
buffer = rb_entry(n, struct binder_buffer, rb_node);
BUG_ON(!buffer->free);
buffer_size = binder_buffer_size(proc, buffer); if (size < buffer_size) {
best_fit = n;
n = n->rb_left;
} else if (size > buffer_size)
n = n->rb_right; else {
best_fit = n; break;
}
}找到之后,还需要对binder_proc中的字段进行相应的更新:
rb_erase(best_fit, &proc->free_buffers);
buffer->free = 0;
binder_insert_allocated_buffer(proc, buffer);if (buffer_size != size) {
struct binder_buffer *new_buffer = (void *)buffer->data + size;
list_add(&new_buffer->entry, &buffer->entry);
new_buffer->free = 1;
binder_insert_free_buffer(proc, new_buffer);
}
binder_debug(BINDER_DEBUG_BUFFER_ALLOC, "%d: binder_alloc_buf size %zd got %p\n",
proc->pid, size, buffer);
buffer->data_size = data_size;
buffer->offsets_size = offsets_size;
buffer->async_transaction = is_async;if (is_async) {
proc->free_async_space -= size + sizeof(struct binder_buffer);
binder_debug(BINDER_DEBUG_BUFFER_ALLOC_ASYNC, "%d: binder_alloc_buf size %zd async free %zd\n",
proc->pid, size, proc->free_async_space);
}下面我们再来看看内存的释放。
BC_FREE_BUFFER命令是通知驱动进行内存的释放,binder_free_buf函数是真正实现的逻辑,这个函数与binder_alloc_buf是刚好对应的。在这个函数中,所做的事情包括:
重新计算进程的空闲缓存大小
通过binder_update_page_range释放内存
更新binder_proc的buffers,free_buffers,allocated_buffers字段
Binder中的“面向对象”
Binder机制淡化了进程的边界,使得跨越进程也能够调用到指定服务的方法,其原因是因为Binder机制在底层处理了在进程间的“对象”传递。
在Binder驱动中,并不是真的将对象在进程间来回序列化,而是通过特定的标识来进行对象的传递。Binder驱动中,通过flat_binder_object来描述需要跨越进程传递的对象。其定义如下:
struct flat_binder_object {
__u32 type;
__u32 flags; union { binder_uintptr_t binder; /* local object */
__u32 handle; /* remote object */
}; binder_uintptr_t cookie;
};这其中,type有如下5种类型。
enum { BINDER_TYPE_BINDER = B_PACK_CHARS('s', 'b', '*', B_TYPE_LARGE),
BINDER_TYPE_WEAK_BINDER = B_PACK_CHARS('w', 'b', '*', B_TYPE_LARGE),
BINDER_TYPE_HANDLE = B_PACK_CHARS('s', 'h', '*', B_TYPE_LARGE),
BINDER_TYPE_WEAK_HANDLE = B_PACK_CHARS('w', 'h', '*', B_TYPE_LARGE),
BINDER_TYPE_FD = B_PACK_CHARS('f', 'd', '*', B_TYPE_LARGE),
};当对象传递到Binder驱动中的时候,由驱动来进行翻译和解释,然后传递到接收的进程。
例如当Server把Binder实体传递给Client时,在发送数据流中,flat_binder_object中的type是BINDER_TYPE_BINDER,同时binder字段指向Server进程用户空间地址。但这个地址对于Client进程是没有意义的(Linux中,每个进程的地址空间是互相隔离的),驱动必须对数据流中的flat_binder_object做相应的翻译:将type该成BINDER_TYPE_HANDLE;为这个Binder在接收进程中创建位于内核中的引用并将引用号填入handle中。对于发生数据流中引用类型的Binder也要做同样转换。经过处理后接收进程从数据流中取得的Binder引用才是有效的,才可以将其填入数据包binder_transaction_data的target.handle域,向Binder实体发送请求。
由于每个请求和请求的返回都会经历内核的翻译,因此这个过程从进程的角度来看是完全透明的。进程完全不用感知这个过程,就好像对象真的在进程间来回传递一样。
驱动层的线程管理
上文多次提到,Binder本身是C/S架构。由Server提供服务,被Client使用。既然是C/S架构,就可能存在多个Client会同时访问Server的情况。 在这种情况下,如果Server只有一个线程处理响应,就会导致客户端的请求可能需要排队而导致响应过慢的现象发生。解决这个问题的方法就是引入多线程。
Binder机制的设计从最底层–驱动层,就考虑到了对于多线程的支持。具体内容如下:
使用Binder的进程在启动之后,通过BINDER_SET_MAX_THREADS告知驱动其支持的最大线程数量
驱动会对线程进行管理。在binder_proc结构中,这些字段记录了进程中线程的信息:max_threads,requested_threads,requested_threads_started,ready_threads
binder_thread结构对应了Binder进程中的线程
驱动通过BR_SPAWN_LOOPER命令告知进程需要创建一个新的线程
进程通过BC_ENTER_LOOPER命令告知驱动其主线程已经ready
进程通过BC_REGISTER_LOOPER命令告知驱动其子线程(非主线程)已经ready
进程通过BC_EXIT_LOOPER命令告知驱动其线程将要退出
在线程退出之后,通过BINDER_THREAD_EXIT告知Binder驱动。驱动将对应的binder_thread对象销毁
再聊ServiceManager
上文已经说过,每一个Binder Server在驱动中会有一个binder_node进行对应。同时,Binder驱动会负责在进程间传递服务对象,并负责底层的转换。另外,我们也提到,每一个Binder服务都需要有一个唯一的名称。由ServiceManager来管理这些服务的注册和查找。
而实际上,为了便于使用,ServiceManager本身也实现为一个Server对象。任何进程在使用ServiceManager的时候,都需要先拿到指向它的标识。然后通过这个标识来使用ServiceManager。
这似乎形成了一个互相矛盾的现象:
通过ServiceManager我们才能拿到Server的标识
ServiceManager本身也是一个Server
解决这个矛盾的办法其实也很简单:Binder机制为ServiceManager预留了一个特殊的位置。这个位置是预先定好的,任何想要使用ServiceManager的进程只要通过这个特定的位置就可以访问到ServiceManager了(而不用再通过ServiceManager的接口)。
在Binder驱动中,有一个全局的变量:
static struct binder_node *binder_context_mgr_node;
这个变量指向的就是ServiceManager。
当有进程通过ioctl并指定命令为BINDER_SET_CONTEXT_MGR的时候,驱动被认定这个进程是ServiceManager,binder_ioctl函数中对应的处理如下:
case BINDER_SET_CONTEXT_MGR: if (binder_context_mgr_node != NULL) {
pr_err("BINDER_SET_CONTEXT_MGR already set\n");
ret = -EBUSY; goto err;
}
ret = security_binder_set_context_mgr(proc->tsk); if (ret < 0) goto err; if (uid_valid(binder_context_mgr_uid)) { if (!uid_eq(binder_context_mgr_uid, current->cred->euid)) {
pr_err("BINDER_SET_CONTEXT_MGR bad uid %d != %d\n",
from_kuid(&init_user_ns, current->cred->euid),
from_kuid(&init_user_ns, binder_context_mgr_uid));
ret = -EPERM; goto err;
}
} else
binder_context_mgr_uid = current->cred->euid;
binder_context_mgr_node = binder_new_node(proc, 0, 0); if (binder_context_mgr_node == NULL) {
ret = -ENOMEM; goto err;
}
binder_context_mgr_node->local_weak_refs++;
binder_context_mgr_node->local_strong_refs++;
binder_context_mgr_node->has_strong_ref = 1;
binder_context_mgr_node->has_weak_ref = 1; break;ServiceManager应当要先于所有Binder Server之前启动。在它启动完成并告知Binder驱动之后,驱动便设定好了这个特定的节点。
在这之后,当有其他模块想要使用ServerManager的时候,只要将请求指向ServiceManager所在的位置即可。
在Binder驱动中,通过handle = 0这个位置来访问ServiceManager。例如,binder_transaction中,判断如果target.handler为0,则认为这个请求是发送给ServiceManager的,相关代码如下:
if (tr->target.handle) {
struct binder_ref *ref;
ref = binder_get_ref(proc, tr->target.handle, true); if (ref == NULL) {
binder_user_error("%d:%d got transaction to invalid handle\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY; goto err_invalid_target_handle;
}
target_node = ref->node;
} else {
target_node = binder_context_mgr_node; if (target_node == NULL) {
return_error = BR_DEAD_REPLY; goto err_no_context_mgr_node;
}
}结束语
本篇文章中,我们对Binder机制做了整体架构和分层的介绍,也详细讲解了Binder机制中的驱动模块。对于驱动之上的模块,会在今后的文章中讲解。
下一篇文章中,我们会详细讲解Android Binder机制的Framework层,敬请期待。






