
在过去几年中,RAG(检索增强生成技术)已经发展成熟,并且已经进行了多项研究以了解能够实现低成本高精度的方法和行为特征。其中一篇相关的研究论文是《检索增强生成最佳实践的研究》(Searching for Best Practices in Retrieval-Augmented Generation)。
典型的RAG系统流程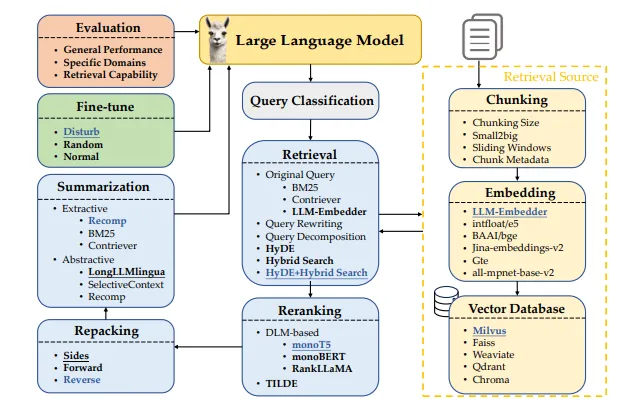
引用: https://arxiv.org/pdf/2407.01219
一个典型的RAG(检索增强生成)流程包含几个阶段等。
- 查询分类: 将用户的问题分类为是否需要文档检索。
- 检索: 快速找到并获取最相关的文档。
- 重新排序: 按相关性对检出的文档进行排序。
- 重组: 将文档重新打包成结构化的格式。
- 摘要: 提取关键点,生成清晰简洁的答案,避免重复。
实现RAG还涉及决定如何将文档拆分成片段,选择恰当的嵌入方式以理解文本的意义,选择合适的向量数据库以高效存储这些特征,以及找到微调语言模型的方式,如下面的图1所示。
我们一个一个仔细看看:
想要找到正确和准确的答案?来参加我们的大型语言模型面试课程吧!- 100+ 个涵盖 14 个类别的问题
- 每个类别精选 100+ 项评估
- 基于 FAANG 和财富 500 强 公司的真实世界面试问题
- 侧重于 视觉学习方法
- 真实的 案例研究和认证
50%, 优惠码 — LLM50码
课程链接 —
大型语言模型(LLM)面试问题与答案深入了解大型语言模型(LLM)的世界,探索其面试问题与答案的全面课程……www.masteringllm.com 分类查询为什么进行查询分类很重要?
- 并非所有问题都需要额外查资料,因为大型语言模型自带知识。
- 虽然RAG(检索增强生成)可以提高准确性并减少错误,但频繁检索文档会拖慢回应速度。
- 为了提高性能,我们对查询进行分类,以判断是否需要检索资料。
什么时候推荐查找?
通常,当答案需要额外的信息时,这些信息是模型内部没有的,此时通常需要查找信息。
任务是怎么分类的?
- 任务被分为15种类型,依据是否拥有足够信息。
- 仅凭提供的用户信息即可回答的任务被标记为“足够”,不需要检索。
- 需要更多信息的任务被标记为“不够”,可能需要文档检索来补充信息。
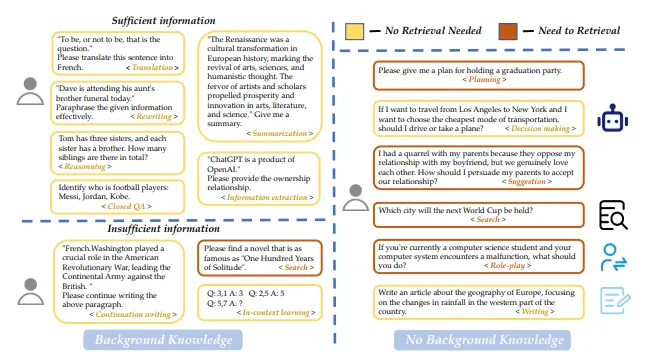
不同任务的检索需求分类。在没有提供具体信息的情况下,我们依据模型的用途来区分任务。图片来源 — https://arxiv.org/pdf/2407.01219
我们通过训练一个分类器来自动完成这个分类任务。
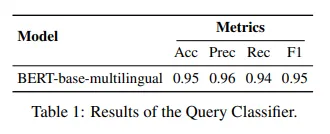
查询分类器的结果如下:
分段处理(将任务分成小块)为什么拆分文档很重要?
- 将文档分解成更小的部分有助于提高检索的准确性,并且可以避免在使用LLM(大型语言模型)时因文档长度引起的问题。
分块可以分成几个层次呢?
- 基于Token的切分:这种方式虽然简单,但可能会断开句子,从而降低检索质量。
- 语义级别切分:利用大模型识别自然的断点,虽然保持了上下文的完整性,但需要更多处理时间。
- 句子级别切分:在句子边界分割文本,平衡了意义的保持和效率与简洁性。
哪种分块方法更常用?
句子级别的切分常被使用,因为它很好地平衡了保持文本意义和易于实现这两点。
片段大小这一点很重要,分块大小对性能有很大影响。
- 更大的块提供了更多的上下文,有助于更好地理解内容,但可能会减慢处理速度。
- 更小的块处理更快,并提高了记忆率,但可能无法提供足够的上下文,导致无法准确理解内容。
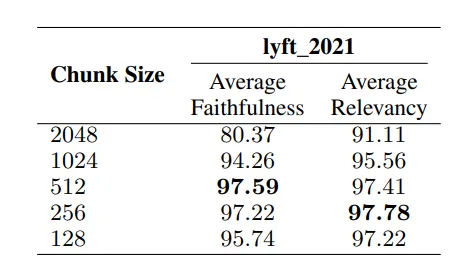
不同数据块大小的比较。
重要的评估指标
- 如图所示,块是基于两个指标进行评估的:
- 忠实度:评估响应是否忠实于检索到的文本,或者是否出现了偏差。
- 相关度:检查检索到的文本和响应是否与查询密切相关。
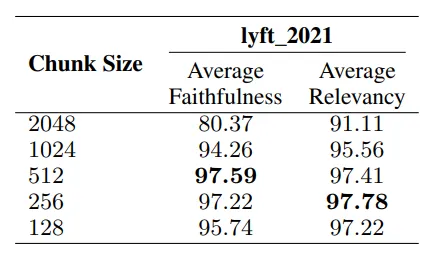
不同大小的块对比
段落是怎么组织的呢?
图5中的分析比较了不同大小的块。
- 较小的块大小:175 个 token。
- 较大的块大小:512 个 token。
- 块的重叠:20 个 token,用于确保块之间有一定的连续性。
不同部分技能的比较
词嵌入模型
- 选择嵌入模型对于平衡性能和资源使用至关重要。
- 根据图6,LLM-Embedder 的性能与 BAAI/bge-large-en 相当,但其大小仅为后者的约三分之一。
- 由于其较小的大小和效果类似,LLM-Embedder 因此成为优化性能和效率的首选模型。
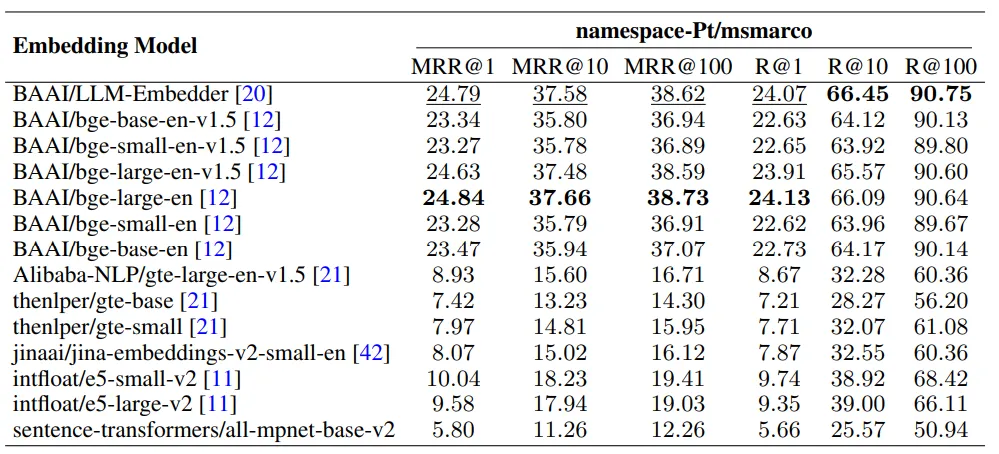
不同嵌入模型在 namespace-Pt/msmarco 上的表现
添加元数据
使用元数据(例如标题、关键词和假设问题)来增强这些区块可以提高检索效果。
这篇论文没有包含具体的实验,而是将这些实验留待将来再做。
矢量数据库- 向量数据库对比:包括 Weaviate、Faiss、Chroma、Qdrant 和 Milvus。
- 推荐选择:Milvus 性能卓越,比其他选项更全面地满足所有基本需求。

不同类型的向量型数据库比较
让我们来搜寻一下吧!针对用户的查询,检索模块从预先构建的语料库中挑选与查询最相关的排名前 k 位的文档,基于相似度。
检索方法:
- 查询重写:利用大规模语言模型改进查询,以实现更佳的文档匹配效果。
- 查询分解:基于原查询的子问题检索文档。
- 生成伪文档:利用假设文档来检索相似文档;一个典型例子是HyDE。

不同检索方法在TREC DL19/20上的结果比较
评估结果:如下图所示
- 监督方法的表现优于非监督方法。
- HyDE + 混合搜索:取得了最高的性能得分。
- 混合搜索:结合了BM25(稀疏检索)和LLM生成的嵌入(密集检索),以实现最佳性能和低延迟。
建议:使用 HyDE + 混合搜索 作为默认的搜索方法。
重新排序重新排序环节:在初步检索之后提升文档的相关度。
重排序方法 :
- DLM 重新排序:使用深度语言模型(DLM)来评估文档的相关性;文档的排序依据是其被视为“正确”或“准确”的概率。
- TILDE 重新排序:通过累加查询词的概率对文档进行评分,TILDEv2 通过仅索引相关术语并使用 NCE 损失来提高效率。
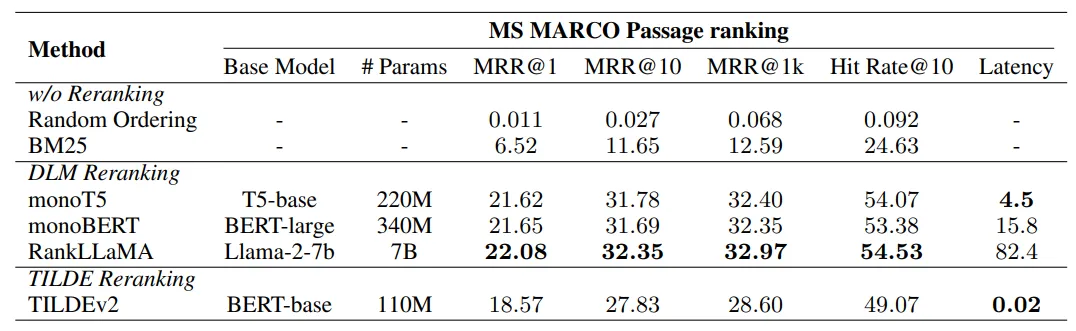
在MS MARCO Passage ranking数据集的dev set上,不同重排序方法的结果
评估结果如下:(见上图):
- monoT5 :推荐用于性能与效率的平衡。
- RankLLaMA :最适合追求最佳的性能。
- TILDEv2 :适合快速实验,使用固定的集合。
推荐使用 monoT5 ,因为它能提供全面的性能和效率。
重新打包- 重组模块:通过优化重新排序文档顺序来确保有效生成LLM的响应。
重新打包指南:
- 按重要性递减:对文档进行排序,按相关性从高到低。
- 按重要性递增:对文档进行排序,按相关性从低到高。
- 侧边显示:基于“中间失落”的理念,将重要信息置于开头或结尾。
评估:在下一节中,我们会详细评估这些方法。
总结- 总结的重要性在于:减少冗余,避免长时间提示减慢LLM的推理过程。
总结方法:
- 提取式压缩器:根据句子的重要性进行切割和排序。
- 生成压缩器:整合并重新表达信息。
评估方法:
- Recomp : 结合了抽取式和生成式压缩器,用于选择和合成重要信息。
- LongLLMLingua : 侧重于与查询相关的关键信息,以提高摘要的质量。
- Selective Context : 通过剔除冗余信息来提高LLM的效率。

不同总结方法之间的比较
评估:在NQ、TriviaQA和HotpotQA数据集上经过测试的方法。Recomp更受欢迎,LongLLMLingua作为备选方案。
AgenticRAG with LlamaIndex: 基于LlamaIndex的AgenticRAG课程了解我们的AgenticRAG 和 LlamaIndex 相关课程,包含5个实时案例研究,其中包括摘要。
代理增强检索生成(AgenticRAG)与LlamaIndex学习代理增强检索生成(AgenticRAG)与LlamaIndex。克服传统RAG挑战。www.masteringllm.com 生成器的微调研究在不同上下文中微调如何影响生成器的表现,将检索器的微调留待以后的研究。
训练情境的各种变体:
- Dg : 仅包含查询相关的文档。
- Dr : 仅随机选取的文档。
- Dgr : 相关文档和随机文档的混合。
- Dgg : 两个相关文档的副本。
模型版本:
- Mb:基础LM生成器(没有经过微调)。
- 比如 Mg, Mr, Mgr, Mgg,分别使用Dg、Dr、Dgr和Dgg上下文进行微调的模型。

这是微调生成器得到的结果。
- 使用混合文档进行训练:使用相关和随机文档混合训练的模型(Mgr)在黄金或混合背景的情况下表现出最佳性能。
- 关键见解:在训练期间混合相关和随机上下文可以提高生成器对无关信息的抗干扰能力,同时有效利用相关上下文。
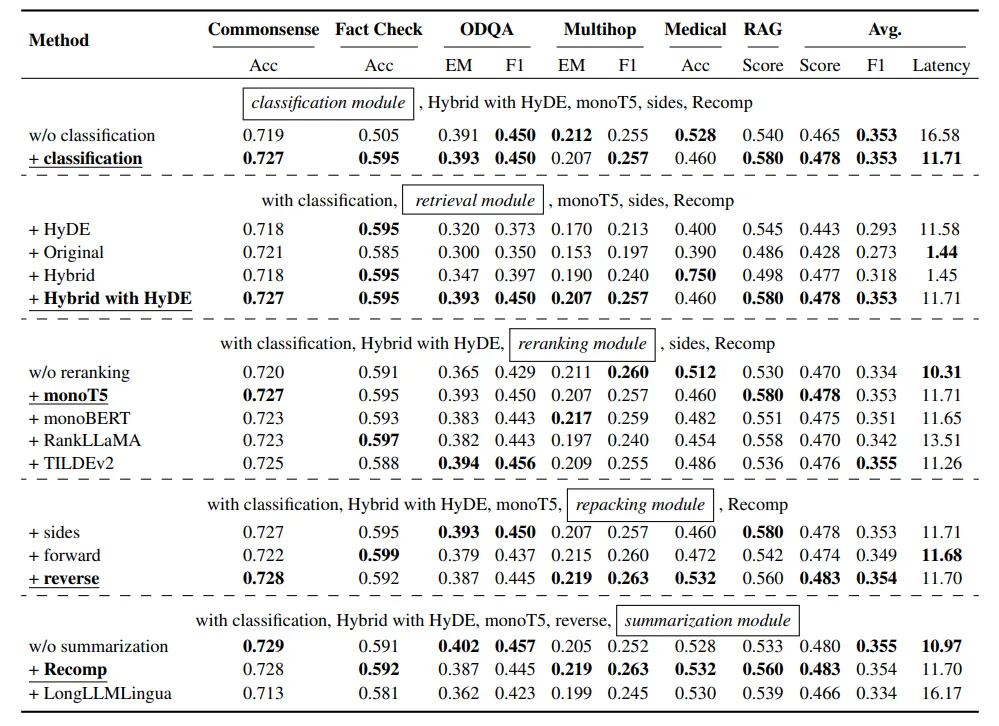
搜索最优RAG实践的结果如下。框起来的模块正在接受调查,以找到最佳方法。下划线的方法表示选定的实现方式。‘Avg’(平均分)是根据所有任务的Acc、EM和RAG得分计算得出的,而平均延迟则是以每查询秒为单位进行测量。最佳得分以粗体突出显示。
查询分类模块:
- 改进:提升效率和效果。
- 性能指标:平均得分从0.428升至0.443。
- 延迟:从16.41秒缩短至11.58秒。
检索模块:
- 最佳性能:带有 HyDE 的“混合”获得了最高的 RAG 分数(0.58),但计算成本较高(每查询耗时 11.71 秒左右)。
- 推荐:为了平衡性能和延迟时间,建议使用“混合”或“原生”方法。
重排序模块:
- 影响 :缺勤导致显著的性能降低。
- 最佳方法 :MonoT5取得了最高的平均分,突显了重排序在相关性方面的重要性。
重新打包模块:
- 最佳设置:反向设置得到了0.560的RAG分数。
- 见解:让更相关的背景信息靠近查询,可以取得更好的效果。
总结模块
- 最棒的方法:Recomp表现得更好。
- 替代方案:去掉摘要模块可以得到差不多的结果,但延迟更小。不过,如果考虑生成器的最大长度限制,Recomp仍然是更好的选择。
找找我们所有的咖啡休息系列,
掌握LLM:生成式AI和LLM的全面课程 掌握LLM的目标是在未来五年内培养一千万名AI工程师。无论你是新手还是资深开发者,我们的课程都能帮助你提升技能。我们提供全面的课程,内容涵盖……www.masteringllm.com关注我们吧,你们的评论和点赞能激励我们为社区带来更好的内容。
你可以给多次掌声吗?是的,你可以





