

介绍:
近年来,两篇具有突破性的论文彻底改变了我们对神经网络及其与微分方程之间关系的理解。第一篇是陈等人(2018)撰写的《神经普通微分方程》(“Neural Ordinary Differential Equations”),提出了将神经网络视作连续动态系统的概念。第二篇是格拉霍尔等人(2019)等在2019年发表的《FFJORD: 自由形式连续动力系统在可逆生成模型中的应用》(“FFJORD: Free-form Continuous Dynamics for Scalable Reversible Generative Models”),将这一概念应用于基于流的生成模型。这两篇论文均出自多伦多大学向量研究所,引发了一波新的研究热潮。
接下来,我们来看看背景信息 常微分方程及其ODE解法器要理解这些文章中提到的创新,我们得先了解一下常微分方程(ODEs)的基本概念及其数值解。
常微分方程是关于未知函数相对于单一自变量的导数的方程。两个经典例子是:
放射性衰减方程为:dx(t)/dt = -cx(t)
其解为:x(t) = x₀ exp(-ct),其中,x₀ 表示初始值。
2) 简谐运动的方程是这样的:d²x(t)/dt² = -c²x(t)
解的形式是 x(t) = A sin(ct) + B cos(ct),其中 A 和 B 是任意系数
虽然这些简单的微分方程有解析解,但在实际应用中,大多数微分方程需要通过数值方法来求解。
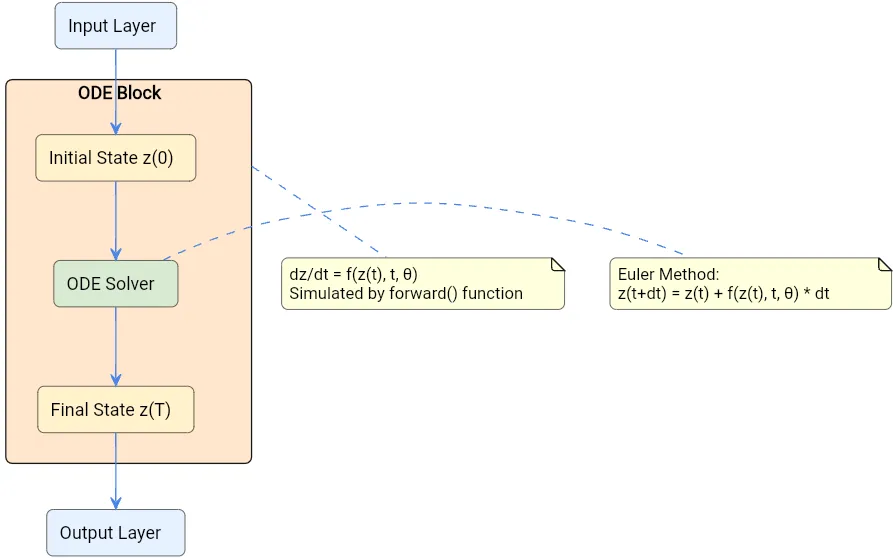
这里就是ODE求解器登场的时候了。最简单的欧拉方法,它通过取小步并利用每点的导数来估计下一个点来近似解。对于形式为dy/dt = f(t, y)且初始条件为y(t₀) = y₀的ODE,简单来说,欧拉方法近似如下:
在时间 t₀ 后经过 h 单位时间,y 的值可以近似为 y₀ 加上 f(t₀, y₀) 与 h 的乘积。
y(t₀ + h) ≈ y₀ + f(t₀, y₀) · h
其中 h 是步长。更先进的方法,如龙格-库塔(Runge-Kutta)算法家族,能够在增加计算复杂度的同时提供更高的准确度。
这里有一个简单的Python实现的欧拉方法
import numpy as np
def euler_method(f, y0, t0, t1, h):
t = np.arange(t0, t1+h, h)
y = np.zeros(len(t))
y[0] = y0
for i in range(1, len(t)):
y[i] = y[i-1] + h * f(t[i-1], y[i-1])
return t, y
# 例子:解 dy/dt = -y
def f(t, y):
return -y
t, y = euler_method(f, 1, 0, 5, 0.1)这段代码使用欧拉法解决了 dy/dt = -y 的微分方程问题.
2. ResNet:通往连续动力学的桥梁通过残差网络(ResNets)的视角来看,神经网络和常微分方程(ODE)之间的联系因此变得清晰明了。与传统的深度神经网络直接在层间进行变换的学习不同,残差网络只学习层间的残差(即差异)。
传统的DeepNet:
设 h1 = f1(x)
设 h2 = f2(h1)
设 h3 = f3(h2)
设 h4 = f4(h3)
设 y = f5(h4)ResNet(残差网络):
定义 h1 为 f1(x) 加上 x,
定义 h2 为 f2(h1) 加上 h1,
定义 h3 为 f3(h2) 加上 h2,
定义 h4 为 f4(h3) 加上 h3,
定义 y 为 f5(h4) 加上 h4这种剩余学习可以被视为连续变换过程的欧拉近似,这为神经ODEs奠定了基础。
3. 神经普通微分方程(NODE)陈等人团队的重要见解是将ResNet层的极限推向无穷大,从而形成了一个连续深度的模型。这促成了神经ODE的提出:
这个就是我们用来表示随时间和参数变化的状态变化率的公式:dh(t)/dt = f(h(t), t, θ).
在这里,f 是一个神经网络,用于建模隐藏状态 h(t) 的动力学,θ 表示网络的参数。h(t) 的演化是通过一个 ODE 求解器计算出来的。
神经网络中的ODE模型的优势包括:
1) 计算图不需要存储。
2) 可以根据需要调整数值精度和速度之间的权衡。
3) 一组参数定义了整个转换过程。
4) 时间步长变得连续,这使得更自然的建模成为可能。
在基于ODE的神经网络中,前向传播非常简单。
z(t₁) = ∫_{t₀}^{t₁} f(z(t), t, θ) dt = ODESolver(z(t₀), f, t₀, t₁, θ)
然而,反向传播算法需要一个巧妙的方法来避免存储整个计算图的整个过程。由Pontryagin等人在1962年提出的一种伴随方法提供了一个优雅的解决方案:“它定义了一个伴随状态 a(t) = -∂L/∂z(t)”,并遵循自身的微分方程。
da(t)/dt = -a(t)ᵀ ∂f(z(t), t, θ)/∂z
通过逆时间求解这个常微分方程,我们可以计算相对于初始状态、参数和时间范围的梯度,而不需要保存中间结果。
让我们用PyTorch来实现一个简单的神经ODE模型吧。
import torch
import torch.nn as nn
from torchdiffeq import odeint # 解决微分方程的函数
class ODEFunc(nn.Module):
def __init__(self):
super(ODEFunc, self).__init__()
self.net = nn.Sequential(
nn.Linear(2, 50), # 输入维度为2,输出维度为50的全连接层
nn.Tanh(), # Tanh激活函数
nn.Linear(50, 2), # 输入维度为50,输出维度为2的全连接层
)
def forward(self, t, y):
return self.net(y) # 将输入y通过神经网络计算输出
class ODEBlock(nn.Module):
def __init__(self, odefunc):
super(ODEBlock, self).__init__()
self.odefunc = odefunc # ODEFunc对象的实例
self.integration_time = torch.tensor([0, 1]).float() # 积分的时间段
def forward(self, x):
out = odeint(self.odefunc, x, self.integration_time) # 对输入x进行积分计算
return out[1] # 返回积分计算的最终结果
ode_block = ODEBlock(ODEFunc()) # 创建ODEBlock实例之前的例子展示了简单的神经ODE的例子,现在我们来看看一个更实际的实现,用于分类MNIST手写数字。这个实现将神经ODE的概念与传统的神经网络架构结合起来。
import numpy as np
import matplotlib.pyplot as plt
import torch
from torchvision import datasets, transforms
# 参数
x_num = 28*28 # 输入层大小
z_num = 100 # 隐藏层的节点数
y_num = 10 # 输出层大小
x = np.zeros(x_num) # 输入层
z = np.zeros(z_num) # 隐藏层
y = np.zeros(y_num) # 输出层
t = np.zeros(y_num) # 目标值
# 权重
w1 = np.random.rand(x_num, z_num)
w2 = np.random.rand(z_num, z_num)
w3 = np.random.rand(z_num, y_num)
w2_ = np.random.rand(z_num, z_num) # 临时 w2 用于更新
# 偏置
b1 = np.random.rand(z_num)
b2 = np.random.rand(z_num)
b2_ = np.random.rand(z_num) # 临时 b2 用于更新
b3 = np.random.rand(y_num)
# 使用 torchvision 加载 MNIST 数据
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=1, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=1, shuffle=False)
def disp(x):
image = x.reshape((28, 28))
plt.imshow(image, cmap='gray')
plt.show()
def func(x):
return 1.0 / (1.0 + np.exp(-0.05*x))
def forward(z, n, dt):
for i in range(n):
z = func(z.dot(w2) - b2) * dt + z
return z
# 训练
dt = 0.002
n = 20
print(f'dt={dt}, n={n}, T={n*dt}')
for j, (image, label) in enumerate(train_loader):
x = image.view(-1).numpy()
label = label.item()
# 前向传递
z = func(np.dot(x, w1) - b1)
z = forward(z, n, dt)
y = func(np.dot(z, w3) - b3)
# 设置标签向量
t = np.zeros(y_num)
t[int(label)] = 1
e = 0.7 # 学习率
# 误差计算
Error2 = (t - y) * (1 - y) * y # 误差函数对输出 y 的导数
# 更新输出层权重值
w3 += e * np.outer(z, Error2)
b3 -= e * Error2
# 更新隐藏层权重值(伴随法)
a = np.dot(Error2, w3.T) * (1 - z) * z # a(T)
for k in range(n):
z_ = -func(z.dot(w2) - b2) * dt + z # z(t-dt) 向后计算
w2_ += e * np.outer(a, z_)
b2_ -= e * a
a += (1 - z) * z * a * dt # a(t-dt)
z = z_
# 更新输入层权重值
w1 += e * np.outer(x, a) # a(0)
b1 -= e * a
# 更新权重值
w2 = w2_
b2 = b2_
if j % 1000 == 0:
print(f"处理了 {j} 张图像")
if j >= 59999: # 处理完 60,000 张图像后停止
break
# 测试
correct = 0
total = 0
for image, label in test_loader:
x = image.view(-1).numpy()
label = label.item()
# 前向传递
z = func(x.dot(w1) - b1)
z = forward(z, n, dt)
y = func(z.dot(w3) - b3)
predicted = np.argmax(y)
if label == predicted:
correct += 1
total += 1
accuracy = correct / total
print(f"测试准确度: {accuracy:.4f}")通过将神经ODE应用于MNIST分类的这个实现,展示了神经ODEs理论的几个关键实际应用在实践中。
forward函数模拟了隐状态z在连续时间区间内的演变。这类似于在传统的神经网络中使用无限数量的层。- 虽然这里没有用到复杂的 ODE 解算库,
forward函数实现了一个简单的欧拉方法来近似解 ODE。更新规则z = func(z.dot(w2) - b2) * dt + z实质上是欧拉方法的一步。 - 反向过程采用了一种离散化的方式近似连续伴随 ODE。变量
a表示伴随状态,其更新a += (1 - z) * z * a * dt近似连续伴随 ODE。 - 这种实现只需要跟踪当前状态,并通过 ODE 完成前向和反向的传递。
- 通过改变步数
n或步长dt,我们可以在计算时间和准确性之间找到一个平衡点,而无需重新训练模型。
结果表明,这种方法(即神经ODE方法)在MNIST数据集上可以达到约92%到93%的准确率,在经过一个训练周期后。这表明连续深度网络可以在实际机器学习任务中有效应用。
在MNIST数据集上,神经ODE(ODE-Net)取得了不错的结果,结果如下:
ODE-Net:
- 测试误差率: 1.40%
- 参数: 0.27兆
- 所需内存: 0.22兆字节
与ResNet相比:
- 测试误差率:1.45%
- 参数量:0.29M
- 内存:0.24 MB
1层MLP:
- 测试错误: 1.60%
- 参数: 0.24M
- 所需内存: 0.11 MB
这些结果表明,神经ODEs可以使用更少的参数和内存,达到或超过相似的性能。
6. 连续的归一化流神经ODEs的概念可以自然地扩展到归一化流模型,这是一种基于可逆变换的生成模型类别。在连续极限下,这导致了连续归一化流模型(CNF)。
dz(t)/dt = f(z(t), t)
∂log p(z(t))/∂t = -tr(∂f/∂z)
这里,dz(t)/dt 表示 z(t) 关于 t 的导数。∂log p(z(t))/∂t 表示对数概率 p(z(t)) 关于 t 的偏导数。
这种表达方式允许更丰富的变换方式,同时保持易于计算的概率密度估计。
下面是一个简单的实现
import torch
import torch.nn as nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
class CNF(nn.Module):
def __init__(self, dim):
super(CNF, self).__init__()
self.net = nn.Sequential(
nn.Linear(dim, 64),
nn.Tanh(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, dim)
)
def forward(self, z, t):
dz_dt = self.net(z)
return dz_dt
class CNFModel(nn.Module):
def __init__(self, dim):
super(CNFModel, self).__init__()
self.cnf = CNF(dim)
self.fc = nn.Linear(dim, 10)
self.integration_steps = 10
def forward(self, x):
z = x.view(x.size(0), -1)
t = torch.linspace(0, 1, self.integration_steps).to(z.device)
for i in range(1, self.integration_steps):
dz = self.cnf(z, t[i-1])
z = z + dz * (t[i] - t[i-1])
return self.fc(z)
# 加载MNIST数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 定义模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = CNFModel(784).to(device)
optimizer = torch.optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
# 训练阶段
epochs = 5
for epoch in range(epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Epoch {epoch+1}, 批处理 {batch_idx}, 损失: {loss.item():.4f}')
# 测试阶段
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = correct / total
print(f"CNF 测试准确度: {accuracy:.4f}")基于神经ODE和连续正常化流的思想,Grathwohl等人提出了FFJORD。该方法消除了可逆生成模型的架构限制,并通过两种关键技术实现了无偏线性时间对数密度估计。
1) 自动微分法
2) Hutchinson迹估计
对数密度估计如下:
log p(z(t₁)) = log p(z(t₀)) — 期望[∫ 从 t₀ 积分到 t₁ εᵀ (偏导数 ∂f/∂z(t)) ε dt]
这种构建方式让FFJORD能够使用任意复杂的神经网络来定义f,同时保持高效的计算效率。
以下是一段简单的代码,来说明
import torch
import torch.nn as nn
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torchdiffeq import odeint_adjoint as odeint
class FFJORD(nn.Module):
def __init__(self, dim):
super(FFJORD, self).__init__()
self.net = nn.Sequential(
nn.Linear(dim, 64),
nn.Tanh(),
nn.Linear(64, 64),
nn.Tanh(),
nn.Linear(64, dim)
)
def forward(self, t, states):
z, log_p_z, epsilon = states
with torch.set_grad_enabled(True):
z.requires_grad_(True)
dz_dt = self.net(z)
epsilon_dz_dt = torch.sum(epsilon * dz_dt, dim=1)
grad_epsilon_dz_dt = torch.autograd.grad(epsilon_dz_dt, z, torch.ones_like(epsilon_dz_dt), create_graph=True)[0]
trace = torch.sum(grad_epsilon_dz_dt * epsilon, dim=1)
dlog_p_z_dt = -trace
return dz_dt, dlog_p_z_dt, torch.zeros_like(epsilon)
class FFJORDModel(nn.Module):
def __init__(self, dim):
super(FFJORDModel, self).__init__()
self.ffjord = FFJORD(dim)
self.register_buffer('integration_times', torch.tensor([0.0, 1.0]))
self.fc = nn.Linear(dim, 10)
def forward(self, x):
z0 = x.view(x.size(0), -1)
log_p_z0 = torch.zeros(z0.size(0), device=z0.device)
epsilon = torch.randn_like(z0)
states = (z0, log_p_z0, epsilon)
solution = odeint(self.ffjord, states, self.integration_times)
zT, log_p_zT = solution[-1][:2] # 获取最后一个时间步长的z和log_p_z
return self.fc(zT)
# 加载MNIST数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.MNIST(root='./data', train=False, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 初始化模型实例
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = FFJORDModel(784).to(device)
optimizer = torch.optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
# 训练
epochs = 5
for epoch in range(epochs):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
if batch_idx % 100 == 0:
print(f'Epoch {epoch+1}, Batch {batch_idx}, 损失值: {loss.item():.4f}')
# 进行测试
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = correct / total
print(f"FFJORD 测试准确性: {accuracy:.4f}")FFJORD 在可逆生成模型中表现出顶级性能,且其所需的参数数量远少于像 Glow 这样的模型。其中包括 UCI 数据集、MNIST 和 CIFAR10 数据集。
当作为VAE编码器使用时,FFJORD在多个数据集上表现优于其他基于流的方法(平面变换、IAF(逆自动回归流)、Sylvester(西尔弗斯特变换))。
MNIST数据集结果:
- FFJORD: 82.82 ± 0.01
- Sylvester: 83.32 ± 0.06
Omniglot 汇总如下:
- FFJORD 是 98.33,误差在正负 0.09 之间
- Sylvester 是 99.00,误差在正负 0.04 之间
弗雷表情:
- FFJORD: 4.39 ± 0.01
- 西尔维斯特: 4.45 ± 0.04
Caltech 影像:
- FFJORD: 104.03 ± 0.43
- Sylvester: 104.62 ± 0.29
虽然神经网络ODE和FFJORD表现出色,但它们仍然存在一些问题。
1) 在训练过程中,函数评估的数量可能会突然增加,从而可能延长计算时间。
2) 求解刚性微分方程处理起来比较棘手,但可以通过使用如权重衰减等技巧来缓解这个问题。
未来的研究方向包括:
- 开发更适合神经网络动力学的更高效的ODE求解器
- 探索在光流和流体模拟领域的应用
- 研究连续深度模型的理论特性
神经普通微分方程模型和FFJORD在深度学习中代表了一个重要的范式转变,弥合了离散神经网络与连续动力系统的差距。通过引入数值分析和微分方程的技术,这些方法为构建更灵活、高效且理论基础更牢固的神经网络模型开辟了新的途径。随着这一领域的研究不断深入,我们可以期待更多的创新出现,这些创新将推动机器学习和人工智能的边界不断拓展。
我是乔,我的志向是引领行业步入5.0时代。我总是对新机会感兴趣,所以不要犹豫,可以通过我的LinkedIn联系我。





