
- 大型语言模型的问题
- 什么是代理、工具和链?
- 创建一个不使用工具的简单聊天
- 使用谷歌的方法进行功能调用,将工具添加到我们的聊天中
- 使用Langchain的方式进行代理操作,将工具添加到我们的聊天中
- 给我们的代理添加记忆功能
- 创建一个包含人工验证环节的链
- 使用搜索引擎工具
所以你有你最喜欢的聊天机器人,你用它来提高你的工作效率,帮助你更好地完成日常任务。它可以帮你翻译文本,写邮件,讲笑话。有一天,你的同事突然来找你,问你:
你知道现在美元和欧元的汇率吗?我在考虑要不要把欧元换成美元,你觉得呢?
你向你最喜爱的聊天机器人提问,得到的答案蹦出来了。
抱歉,我不能完成这个请求。
我没有实时信息的访问权限,包括像汇率这样的金融数据。这里有什么问题?
问题是,你碰到了大型语言模型(LLM)的一个弱点。这些模型在解决许多类型的问题上非常强大,例如文本摘要、生成等等。
但是,他们,面临以下限制:
- 训练后它们就会被冻结,导致知识变得陈旧。
- 它们无法查询或修改外部的数据。
就像我们每天使用搜索引擎来查找信息、阅读书籍和文档或查询数据库一样,我们希望把这些知识告诉我们的大语言模型,让它更高效。
好,有一个办法可以做到这一点:使用工具和代理程序。
虽然基础模型在文本和图像生成方面表现出色,但它们仍然无法与外部世界互动。工具可以弥补这一不足,使代理能够与外部数据和服务互动,从而解锁更多超出基础模型本身能力范围的行动。
(来源:Google 白皮书)
我们可以利用代理和工具,在聊天界面里做到这些:
- 从我们自己的文件中检索数据
- 读发邮件
- 与内部数据库互动
- 实时谷歌搜索
- 等等
- 什么是代理、工具和链?
一个 代理 是一个应用程序,它试图通过使用一组工具,并根据对环境的观察来做出决策,从而实现目标或完成任务。
比如,如果你需要计算一个复杂的数学问题(目标),你可以选择用计算器(工具#1)来做简单加法,或者用编程语言(工具#2)来处理更复杂的算法。
所以,代理包括:
- 一个模型:我们代理的大脑是大语言模型(LLM),它将理解查询(目标),并浏览其可用工具以选择最适合的。
- 一个或多个工具:这些是用于执行特定任务的函数或API(例如,获取美元和欧元的当前汇率、执行加法计算等)。
- 一个编排过程:这是定义模型如何分析问题、精炼输入和选择工具的认知过程。例如,这样的过程包括ReAct、CoT(思维链)、ToT(思维树)。
如下工作流解释:
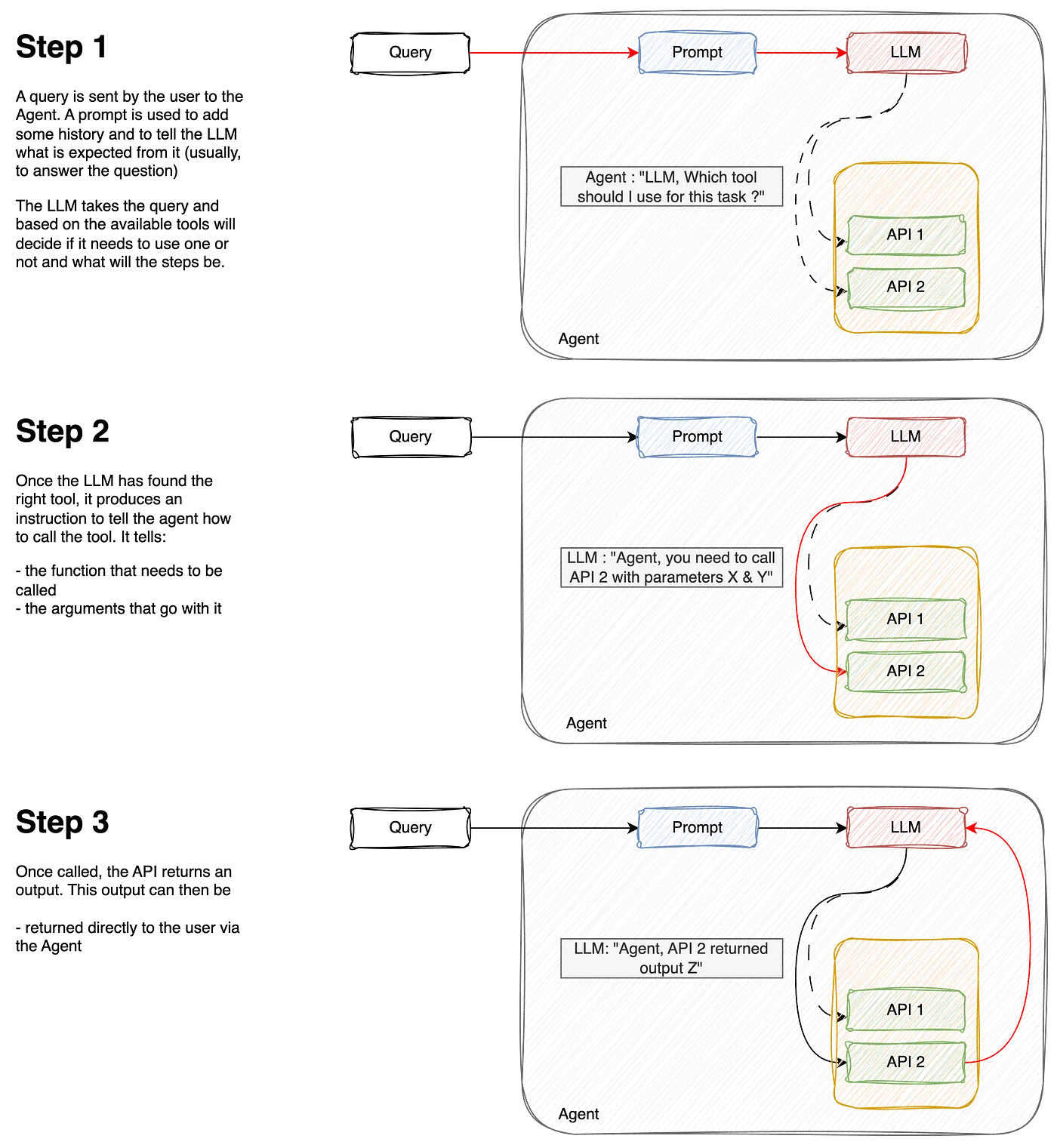
作者供图
‘链’有些不同。相比之下,代理可以自主‘决定’要做什么以及采取哪些步骤,而链只是由一系列预设步骤组成的。链仍可依赖工具,也就是说,它们可以包含一个选择可用工具的步骤。我们会在后面详细讨论这一点。
3. 创建一个简单的聊天,无需任何工具为了说明我们的观点,我们将先来看看我们的LLM表现得怎么样。
我们来安装需要的库:
vertexai==1.65.0
langchain==0.2.16
langchain-community==0.2.16
langchain-core==0.2.38
langchain-google-community==1.0.8
langchain-google-vertexai==1.0.6使用谷歌的Gemini LLM来创建我们这个非常简单的聊天程序。
from vertexai.generative_models import GenerativeModel, GenerationConfig
gemini_model = GenerativeModel(
"gemini-1.5-flash",
generation_config=GenerationConfig(temperature=0),
)
chat = gemini_model.start_chat()如果你运行这个简单的聊天并问现在的汇率,可能会收到类似的回答:
response = chat.send_message("当前美元对欧元的汇率是多少?")
answer = response.candidates[0].content.parts[0].text
--- 输出 ---
"很抱歉,我无法满足此请求。我没有实时金融信息的访问权限,包括像汇率这样的信息。" 一点都不奇怪,因为我们知道大语言模型不能拿到最新的信息。
让我们添加一个工具来实现这个功能。我们的工具是一个调用API来实时获取汇率的小功能。
# 获取汇率从API函数定义,该函数用于从API获取货币汇率。
def 获取汇率从API(params):
url = f"https://api.frankfurter.app/latest?from={params['currency_from']}&to={params['currency_to']}"
print(url)
api_response = requests.get(url)
return api_response.text
# 下面试试看 !
获取汇率从API({'currency_from': 'USD', 'currency_to': 'EUR'})
---
'{"amount":1.0,"base":"USD","date":"2024-11-20","rates":{"EUR":0.94679}}'现在我们知道我们的工具是如何工作的,我们希望聊天LLM使用这个功能来回答我们的问题。所以我们要创建一个单一功能代理。我在这里列出来一些选项。
- 使用 Google 的 Gemini 聊天 API 并启用功能调用。
- 使用 LangChain 的 API 并利用代理和工具。
两者各有优缺点。本文的目的也是向你展示这些可能性,让你自己做决定,更喜欢哪一个。
4. 在我们的聊天中添加工具:像谷歌那样通过功能调用主要有两种方法可以把一个函数变成工具。
第一种方法是使用“字典”方式,在工具中指定输入及函数的描述,重要的参数是:
- 函数名(要明确)
- 描述:这里需要详细描述,详细的信息有助于大语言模型选择正确的工具
- 参数:在这里指定参数(类型和描述)。同样,详细描述参数,以帮助大语言模型知道如何传递参数给函数
import requests
from vertexai.generative_models import FunctionDeclaration
get_exchange_rate_func = FunctionDeclaration(
name="get_exchange_rate",
description="获取两国之间货币的汇率.",
parameters={
"type": "object",
"properties": {
"currency_from": {
"type": "string",
"description": "从ISO 4217格式货币"
},
"currency_to": {
"type": "string",
"description": "转换成ISO 4217格式货币"
}
},
"required": [
"currency_from",
"currency_to",
]
},
)第二种使用Google SDK添加工具的方法是通过from_func实例化。这需要我们修改函数,使其更加明确,例如添加文档字符串。我们不再在工具创建上冗长描述,而是通过详细说明函数。
# 编辑我们的函数
def get_exchange_rate_from_api(currency_from: str, currency_to: str):
"""
从 API 获取指定货币之间的汇率
参数:
currency_from (str): 源货币,ISO 4217 格式
currency_to (str): 目标货币,ISO 4217 格式
"""
url = f"https://api.frankfurter.app/latest?from={currency_from}&to={currency_to}"
api_response = requests.get(url)
return api_response.text
# 创建功能
get_exchange_rate_func = FunctionDeclaration.from_func(
get_exchange_rate_from_api
)下一步实际上是创建工具。为此,我们将把FunctionDeclaration添加到一个列表中,以创建Tool对象。
from vertexai.generative_models import Tool as VertexTool
tool = VertexTool(
function_declarations=[
get_exchange_rate_func,
# 在这里添加更多函数
]
)让我们现在将这个问题传递给聊天,看看它能不能回答我们关于汇率的问题!记得,在没有工具的情况下,我们的聊天曾经回答过。

让我们试试看谷歌的调用功能工具,看看这是否管用!首先,我们把问题发到聊天里试试。
from vertexai.generative_models import GenerativeModel
gemini_model = GenerativeModel(
"gemini-1.5-flash",
generation_config=GenerationConfig(temperature=0),
tools=[tool] # 添加工具
)
chat = gemini_model.start_chat()
response = chat.send_message(prompt)
# 提取函数调用响应
response.candidates[0].content.parts[0].function_call
--- 输出 ---
"""
name: "get_exchange_rate"
args {
fields {
key: "currency_to"
value {
string_value: "EUR"
}
}
fields {
key: "currency_from"
value {
string_value: "USD"
}
}
fields {
key: "currency_date"
value {
string_value: "latest"
}
}
}""" LLM 正确地猜到它需要使用 get_exchange_rate 函数,并且也正确地猜到这两个参数是 USD 和 EUR 。
但这还远远不够。我们现在真正想要的是运行这个函数来得到我们的结果。
# 映射函数名和函数的字典
function_handler = {
"get_exchange_rate": get_exchange_rate_from_api,
}
# 提取函数调用名称
function_name = function_call.name
print("#### 预测的函数名称")
print(function_name, "\n")
# 提取函数调用参数
params = {key: value for key, value in function_call.args.items()}
print("#### 预测的函数参数")
print(params, "\n")
function_api_response = function_handler[function_name]()
print("#### API 响应")
print(function_api_response)
response = chat.send_message(
Part.from_function_response(
name=function_name,
response={"content": function_api_response},
),
)
print("\n#### 最终答案")
print(response.candidates[0].content.parts[0].text)
--- 输出 ---
"""
#### 预测的函数名称
get_exchange_rate
#### 预测的函数参数
{'currency_from': 'USD', 'currency_date': 'latest', 'currency_to': 'EUR'}
#### API 响应
{"amount":1.0,"base":"USD","date":"2024-11-20","rates":{"EUR":0.94679}}
#### 最终答案
当前 USD 对 EUR 的汇率是 0.94679。也就是说,1 美元等于 0.94679 欧元。
"""现在我们的聊天机器人能回答问题了!它能:
- 正确地猜出了应该调用的函数是
get_exchange_rate - 正确地设置了函数
get_exchange_rate的参数{‘currency_from’: ‘USD’, ‘currency_to’: ‘EUR’} - 成功从 API 获取了结果
- 并将结果以易于理解的格式进行了格式化
我们现在来看看使用LangChain的另一种方式。
5. 在我们的聊天中添加工具:Langchain的代理方式LangChain 是一款用于构建 LLM 的可组合框架。它是可控制的代理工作流的流程编排框架。大型语言模型。
就像我们以前为“Google”做的一样,从现在开始,我们将用Langchain的方式构建工具。我们从定义函数开始。同样地,对于Langchain,我们也需要在文档字符串中详尽地描述。
从 langchain_core.tools 导入 tool
@tool
def 获取汇率(currency_from: str, currency_to: str) -> str:
"""
返回两种货币之间的汇率
参数说明:
currency_from: str
currency_to: str
"""
url = f"https://api.frankfurter.app/latest?from={currency_from}&to={currency_to}"
# 获取汇率数据的API请求URL
api_response = requests.get(url)
return api_response.text为了好玩一点,我将添加另一个可以列出 BigQuery 数据集中表格的工具。下面是一个代码示例:
[此处为代码段] @工具装饰器
def list_tables(project: str, dataset_id: str) -> list:
"""
返回 Bigquery 表格的列表
参数说明:
project: GCP 项目 ID
dataset_id: 数据集 ID
"""
client = bigquery.Client(project=project)
try:
response = client.list_tables(dataset_id)
return [table.table_id for table in response]
except Exception as e:
return f"无法在项目 {params['project']} 中找到数据集 {dataset_id}, 请检查并指定正确的数据集和项目名称"完成之后,我们就把这些功能加入到LangChain工具箱里!
langchain_tool = [
list_tables,
从API获取汇率
]要构建我们的代理,我们将利用LangChain提供的AgentExecutor对象。这个对象主要需要3个我们之前定义过的组件,即我们之前定义的三个组件。
• 一个LLM模型
• 一个提示词
• 和工具
我们先选我们的大型语言模型:
gemini_llm = ChatVertexAI(model="gemini-1.5-flash") # 这里初始化了一个名为gemini_llm的人工智能对话模型然后我们创建一个提示来管理聊天:
prompt = ChatPromptTemplate.from_messages,
[
("system", "你是一个乐于助人的助手"),
("human", "{input}"),
// 占位符可以是 {agent_scratchpad}
("placeholder", "{agent_scratchpad}"),
]
)最后,我们创建 AgentExecutor 并运行查询请求:
agent = create_tool_calling_agent(gemini_llm, langchain_tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=langchain_tools)
agent_executor.invoke({
"input": "thelook_ecommerce 数据集中有哪些表?"
})
--- 输出 ---
"""
{'input': 'thelook_ecommerce 数据集中有哪些表?',
'output': '在 gcp-project-id 项目中找不到 thelook_ecommerce 数据集。
请指定正确的数据集和项目。'}
""" 嗯。这个代理好像少了一个参数,或者是想获得更多详情……我们这样回复,提供更多信息:
agent_executor.invoke({"input": "项目ID是bigquery-public-data"})
--- 输出 ---
"""
{'input': '项目ID是bigquery-public-data',
'output': '好。还有别的我能帮您的吗? \n'}
""" 唉,看来我们又回到了起点。LLM 被告知了项目ID,却忘了问题。我们的代理似乎没有记住之前的问题和答案的记忆。或许我们应该考虑一下其他办法……
6. 给我们的代理增加记忆.记忆是代理中的另一个概念,它基本上帮助系统记住对话历史,避免陷入像上面那样的无尽循环。可以把记忆想象成笔记本,LLM 在上面记录之前的问答内容,以构建对话的背景信息。
我们将修改模型的提示(指令),使其包含记忆。
from langchain_core.chat_history import InMemoryChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
# 在 Langchain 中可以找到不同类型的记忆
memory = InMemoryChatMessageHistory(session_id="foo")
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个乐于助人的助手。"),
# 先放历史记录
("placeholder", "{chat_history}"),
# 然后是新的输入
("human", "{input}"),
# 最后是草稿区
("placeholder", "{agent_scratchpad}"),
]
)
# 这部分保持不变
agent = create_tool_calling_agent(gemini_llm, langchain_tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=langchain_tools)
# 我们给它添加了记忆部分和聊天历史
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)
config = {"configurable": {"session_id": "foo"}}我们现在从头重新运行查询:
agent_with_chat_history.invoke({
"input": "thelook_ecommerce 数据集中有哪些表?"
},
config
)
--- 输出 ---
"""
{'input': 'thelook_ecommerce 数据集中有哪些表?',
'chat_history': [],
'output': '在 `gcp-project-id` 项目中找不到 `thelook_ecommerce` 数据集。请问您能否提供正确的数据集和项目信息?'}
"""当聊天记录是空的时候,模型还是在问项目ID。这和我们之前用的没有记忆的代理一样。我们回复代理补上缺少的信息吧,
reply = "回复"
agent_with_chat_history.invoke({"input": reply}, config)
--- 输出 ---
"""
{'input': '项目ID是bigquery-public-data',
'chat_history': [HumanMessage(content='thelook_ecommerce 数据集中有哪些表呀?'),
AIMessage(content='未在 `gcp-project-id` 项目中找到 `thelook_ecommerce` 数据集。请指定正确的数据集和项目名称。\n')],
'output': '在 `thelook_ecommerce` 数据集中,你可以找到以下表:\n- distribution_centers。\n- events。\n- inventory_items。\n- order_items。\n- orders。\n- products。\n- users。\n'}
"""注意输出中的:
聊天记录的内容记录了之前的问答内容- 现在输出的是表格列表哦。
'output': '在 `thelook_ecommerce` 数据集中有以下表格:\n- 配送中心\n- events\n- inventory_items\n- order_items\n- orders\n- products\n- users\n'}然而,在某些情况下,因为这些操作的特殊性(例如删除数据库中的记录、修改和编辑信息、发送电子邮件等),这些操作可能需要特别关注。如果完全自动化且不加以控制,可能导致代理做出错误决定并造成损害。
一种确保我们工作流程安全的方法是加入一个人工审核环节。
- 创建一个包含人工验证环节的链
链条和代理在某些方面有所不同。代理可以自由选择是否使用工具,而链条则相对固定。它是由一系列固定的步骤组成的,但我们仍然可以在其中加入一个步骤,让LLM从一组工具中做出选择。
在LangChain中,我们使用LCEL来构建链。
LCEL是LangChain表达式语言,它是一种声明性的方式,使链的组合变得简单。LangChain中的链使用管道|(管道符号)操作符来指示步骤执行的顺序,例如步骤1 | 步骤2 | 步骤3 ...。与代理不同,链将严格按照这些步骤执行,而代理可以自主决定,独立于其决策过程。
我们这里将这样来做,以构建一个简单的 prompt | llm。
# 定义一个带有记忆的提示
prompt = ChatPromptTemplate.from_messages(
[
("system", "你是一个乐于助人的助手。"),
# 先放历史记录
("placeholder", "{chat_history}"),
# 然后放新的输入
("human", "{input}"),
# 最后放草稿板
("placeholder", "{agent_scratchpad}"),
]
)
# 将工具与LLM绑定
gemini_with_tools = gemini_llm.bind_tools(langchain_tool)
# 构建这条链
chain = prompt | gemini_with_tools还记得我们在上一步中给RunnableWithMessageHistory传入了一个代理对象吗?在这里,我们也将做同样的事,但是...
# 使用AgentExecutor
# agent = create_tool_calling_agent(gemini_llm, langchain_tool, prompt)
# agent_executor = AgentExecutor(agent=agent, tools=langchain_tool)
# agent_with_chat_history = RunnableWithMessageHistory(
# agent_executor,
# lambda session_id: memory,
# input_messages_key="input",
# history_messages_key="chat_history",
# )
config = {"configurable": {"session_id": "foo"}}
# 使用Chains
memory = InMemoryChatMessageHistory(session_id="foo")
chain_with_history = RunnableWithMessageHistory(
chain,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)
response = chain_with_history.invoke(
{"input": "当前的瑞郎欧元汇率是多少?"}, config)
--- 输出
"""
content='',
additional_kwargs={
'function_call': {
'name': 'get_exchange_rate_from_api',
'arguments': '{"currency_from": "CHF", "currency_to": "EUR"}'
}
}
""" 与代理不同,链不会主动提供答案,除非我们明确告知它。在我们的情况下,它在大语言模型(LLM)返回需要调用的函数后停止了。
我们需要再加一步来实际使用这个工具。我们再加一个函数来运行工具。
from langchain_core.messages 导入 AIMessage
def call_tools(msg: AIMessage) -> list[dict]:
"""一个简单的顺序工具调用助手。"""
tool_map = {工具.map(lambda 工具: (工具.名称, 工具)) for 工具 in langchain_tool}
tool_calls = msg.tool_calls.copy()
for tool_call in tool_calls:
tool_call["output"] = tool_map[tool_call["name"]].invoke(tool_call["args"])
return tool_calls
chain = prompt | gemini_with_tools | call_tools # <-- 额外的步骤
chain_with_history = RunnableWithMessageHistory(
chain,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)
# 重新运行链路
chain_with_history.invoke({"input": "瑞郎对欧元的当前汇率是多少?"}, config)我们现在得到了以下输出,这表明API调用成功了。
[{'name': '从API获取汇率',
'args': {'currency_from': '源货币', 'currency_to': '目标货币'},
'id': '编号',
'type': '类型',
'output': '输出:`{"amount":1.0,"base":"USD","date":"2024-11-20","rates":{"EUR":0.94679}}`,这里的JSON数据表示转换结果。'
}]现在我们已经学会了如何连接步骤,让我们添加一个人工干预的步骤!我们希望这一步能检查LLM是否正确理解了我们的请求并将正确调用API。如果LLM误解了我们的请求或者错误地使用了函数,我们可以决定停止流程。
def human_approval(msg: AIMessage) -> AIMessage:
"""负责通过其输入或引发异常。
参数:
msg: 来自聊天模型的输出
返回:
msg: 来自msg的原始输出
"""
for tool_call in msg.tool_calls:
print(f"我想使用函数 [{tool_call.get('name')}],带有以下参数:")
for k, v in tool_call.get('args').items():
print(" {} = {}".format(k, v))
print("")
input_msg = (
f"你批准吗 (Y|y)?\n\n"
">>>"
)
resp = input(input_msg)
if resp.lower() not in ("yes", "y"):
raise NotApproved(f"工具调用未获批准:\n\n{tool_strs}")
return msg接下来,在调用函数之前,将这个步骤添加到链中
chain = prompt | gemini_with_tools | human_approval | call_tools
memory = InMemoryChatMessageHistory(session_id="foo")
chain_with_history = RunnableWithMessageHistory(
chain,
lambda session_id: memory,
input_messages_key="input",
history_messages_key="chat_history",
)
chain_with_history.invoke({"input": "当前的欧元兑瑞郎汇率是多少?"}, config)你将被要求确认LLM是否理解正确。

这种人工介入步骤在关键的工作流程中非常有用,因为LLM的误判可能会带来严重的后果。
8. 使用搜索功能实时获取信息最便捷的工具之一是搜索引擎。可以使用 GoogleSerperAPIWrapper(你需要注册并获取一个API密钥才能使用它),它提供了一个很好的界面来快速获取Google搜索结果。
幸好 LangChain 已经有一个现成的工具,我们不用自己动手写了。
那么,我们试着就昨天(11月20日)的事件提问,看看我们的代理能不能回答。我们的问题是关于拉斐尔·纳达尔最后的官方比赛(他在那场比赛中输给了范·德·赞舒普(van de Zandschulp))。
agent_with_chat_history 调用(
{"input": "拉斐尔·纳达尔最近的比赛结果怎么样?"}, config)
--- 输出 ---
"""
{'input': '拉斐尔·纳达尔最近的比赛结果怎么样?',
'chat_history': [],
'output': '我没有实时信息,包括最新的体育赛事结果。要获取拉斐尔·纳达尔比赛的最新信息,我建议你查看可靠的体育网站或新闻报道。'}
"""无法访问Google搜索,我们的模型也就无法回答,因为当时训练模型时并没有这些信息。
我们现在把Serper工具加入工具箱里,看看我们的模型能不能用Google搜索找信息。
从 langchain_community.utilities 导入 GoogleSerperAPIWrapper()
# 在这里创建我们的新搜索工具
search = GoogleSerperAPIWrapper(serper_api_key="...")
@工具
def google_search(query: str):
"""
在Google上进行搜索
参数:
query: 要用Google搜索获取的信息
"""
return search.run(query)
# 将其添加到现有的工具列表中
langchain_tool = [
list_datasets,
list_tables,
get_exchange_rate_from_api,
google_search
]
# 创建代理:
agent = create_tool_calling_agent(gemini_llm, langchain_tool, prompt)
agent_executor = AgentExecutor(agent=agent, tools=langchain_tool)
# 添加记忆:
memory = InMemoryChatMessageHistory()
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
lambda session_id: memory(),
input_messages_key="input",
history_messages_key="chat_history",
)再运行一遍我们的查询
调用 agent_with_chat_history({"input": "拉斐尔·纳达尔最近一场比赛的结果是什么?"}, config)
--- 输出 ---
"""
{'input': '拉斐尔·纳达尔最近一场比赛的结果是什么?',
'chat_history': [],
'output': '拉斐尔·纳达尔最近一场比赛输给了博蒂奇·范·德·赞舒普,在戴维斯杯中西班牙被荷兰队淘汰了。'}
"""LLM(大型语言模型)在处理个人、企业、私密或真实数据时往往遇到障碍。确实,在训练阶段这些信息往往是不可获取的。通过让这些模型能够与系统和API进行互动,并协调工作流程来提升效率,代理和工具则是增强这些模型的强力手段。





