

NVLM 1.0 是一系列多模态大型语言模型(LLM),可与专有和开源模型相媲美。尤其值得注意的是,经过多模态训练后,NVLM 1.0 在纯文本任务上的表现优于其 LLM 基础架构。
本文对两种模型设计方法进行了全面的比较:纯解码器的多模态大语言模型(如LLaVA)和基于交叉注意力的模型体系(如Flamingo),并提出了一个混合架构。此外,本文还提出了一种一维瓦片标签设计,专门用于动态高分辨率图像。这种设计在多模态推理和OCR相关任务中表现出色。
该项目已托管在GitHub上。
方法论:NVLM-1.0系列具有三种架构
- 解码器仅有的 NVLM-D
- 基于 X 注意力交叉的 NVLM-X
- 采用混合架构的 NVLM-H
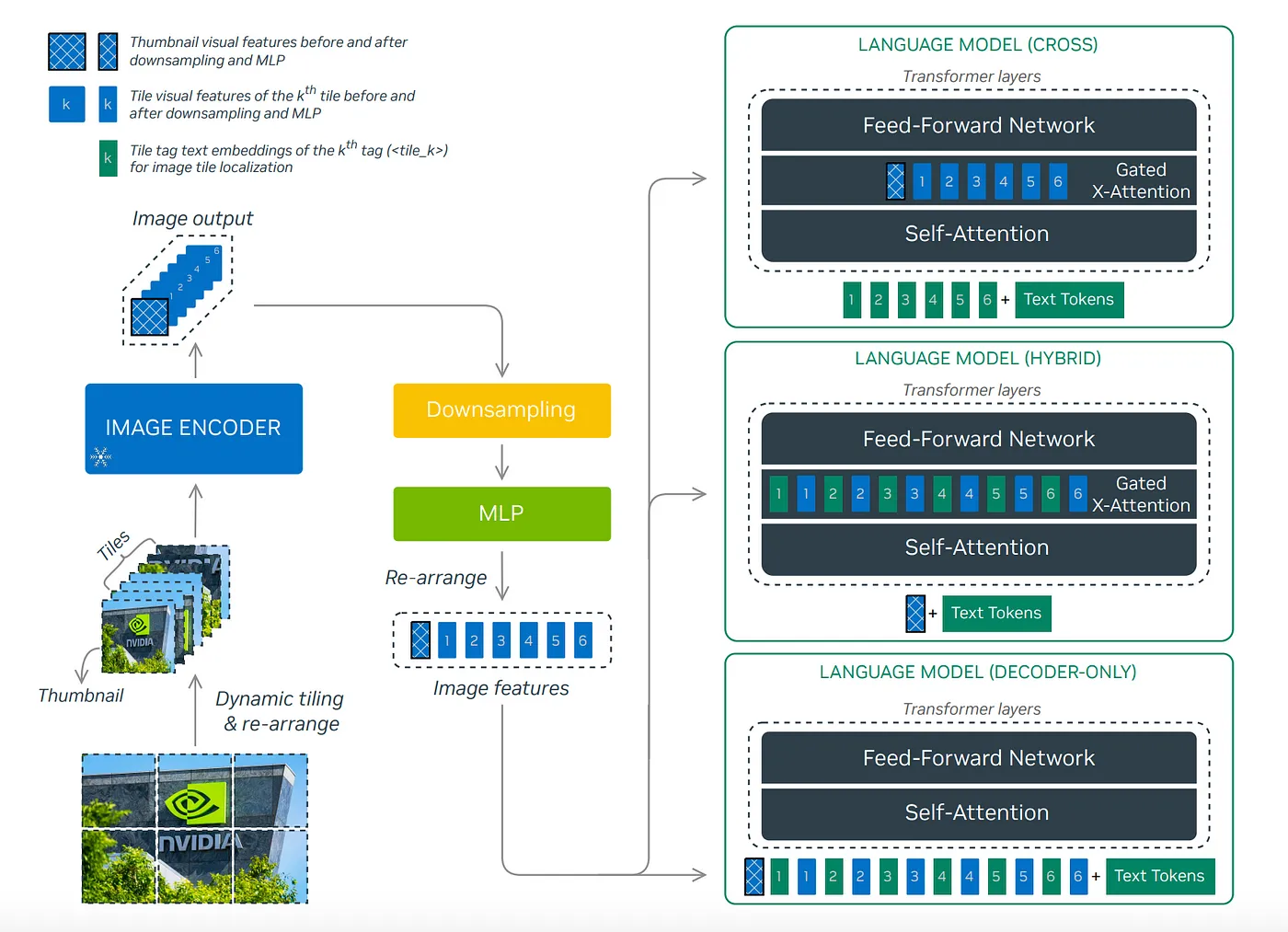
NVLM-1.0 提供了三种架构选择:位于上方的基于交叉注意力的 NVLM-X、位于中间的混合 NVLM-H 和位于下方的仅解码器的 NVLM-D。
InternViT-6B-448px-V1–5 作为所有三个架构的默认视觉编码器,在所有训练阶段中保持冻结状态。它以固定分辨率为448×448处理图像,生成1,024个输出令牌(tokens)。

高分辨率图像的动态拼接。
采用动态高分辨率(DHR)方法。训练时最多可以使用6个瓦片。因此,包括由1到6个瓦片构成的所有可能的宽高比:{1:1, 1:2, 1:3, 1:4, 1:5, 1:6, 2:1, 2:2, 2:3, 3:1, 3:2, 4:1, 5:1, 6:1}。每个输入图像会根据其分辨率动态匹配到预定义的宽高比,并被分割成1到6个瓦片,每个瓦片都是448×448像素的。还包括一个整个图像的缩略图瓦片,用于捕捉全局上下文。每个瓦片随后被输入到InternViT-6B-448px-V1-5中,生成1,024个token(标记)。通过下采样将1,024个图像token减少到256个,以减少LLM的处理负担。此操作将四个相邻的图像token合并为一个,即通过通道维度的拼接进行像素洗牌。
NVLM-D: 仅解码器 模型NVLM-D模型利用一个两层的MLP将预训练的视觉编码器与大语言模型连接起来,该MLP用作投影器或对齐模块。训练NVLM-D分为两个阶段:预训练和监督微调(SFT)。
- MLP从随机初始化开始,并需要先进行预训练,此时视觉编码器和LLM骨干网络均保持冻结状态。
- 在SFT阶段,MLP投影器和LLM被训练以学习新的视觉-语言任务,而视觉编码器保持冻结。
- NVLM-D模型通过引入高质量的纯文本SFT数据集,有效保持了纯文本的性能。
动态高清标签
LLM骨干网络需要处理来自所有动态高分辨率瓦片的展平图像令牌,包括一个额外的缩略图瓦片在内。直接将展平的令牌连接起来而不加分隔符可能会使LLM混淆,因为LLM缺乏关于动态瓦片过程的先验知识。为解决这个问题,在输入序列中插入一个基于文本的瓦片标签,以指示瓦片的开始及其在整体瓦片结构中的位置。瓦片标签之后,再添加该瓦片的256个展平的图像令牌。
以下三种不同的标签与Yi-34B进行比较,使用以下标签的变体:
- 无标签:直接拼接,没有使用瓦片标签,这是InternVL-1.5的设计。
- 一维展开瓦片标签:例如 <tile_1>, <tile_2>, · · · , <tile_6>, <tile_global>。
- 二维网格瓦片标签:<tile_x0_y0>, <tile_x1_y0>, · · · , <tile_xW_yH>, <tile_global>,其中<tile_xi_yj>中的{i : j}可以是{1:1,1:2,1:3,1:4,1:5,1:6,2:1,2:2,2:3,3:1,3:2,4:1,5:1,6:1}。
- 二维包围盒标签:例如<box>(x0,y0),(x1,y1)</box>,···,<box>(xW,yH),(xW+1,yH+1)</box>,其中的(xi, yj)和(xi+1, yj+1)是该特定瓦片在整体高分辨率图像中的(左上角), (右下角)坐标。

使用解码器only NVLMD(Yi-34B作为基础LLM)进行高分辨率动态(DHR)中瓦片标签格式的消融实验。
- 纯动态高分辨率方法(DHR + 无标签)在所有基准测试中均显著提高了性能,除了 MMMU(50.0 对比 50.9),相比不使用标签的低分辨率版本。
- 将所有类型的瓦片标签插入到大语言模型解码器中,显著优于不使用任何标签的简单拼接,尤其是在 OCR 任务上。
- 一维标记 <tile_k> 通常比其他标记表现更佳。
NVLM-X 使用具有门控机制的交叉注意力来处理图像特征。
发现虽然感知重采样器对自然图像描述有益,但对密集OCR任务(例如从扫描文档中转录文本)却有负面影响,因为在Perceiver [48] 中,跨注意力机制会混合输入图像的标记,这可能会破坏图像块之间的重要空间关系,这对文档OCR来说非常重要。因此,NVLM-X架构不使用感知重采样器;相反,它完全依靠跨注意力直接读取视觉编码器中的图像标记。
NVLM-X的LLM骨干网络在多模态SFT过程中不会被解冻,并融合高质量文本SFT数据集以保持强大的文本性能。
动态高清磁贴标签
类似于NVLM-D的设计,我们在LLM解码器中插入了一系列基于文本的图块标签<tile_1> · · · <tile_k>,并通过正确配置X-注意力掩码,使每个标签<tile_k>仅能关注与其对应的图像标记。这种做法确保LLM能够更好地了解图块结构,而无需从缩略图和普通图块的内容中推断图块结构。
仅解码器与X注意机制

使用基于交叉注意力的NVLM-X(以Yi-34B作为基础模型)对动态高分辨率进行瓷砖标签技术的消融实验。
- NVLM-D 的参数比 NVLM-X 少,因为后者增加了新的门控跨注意力层。随着模型规模的增大,额外的参数数量变得显著。
- NVLM-X 通过避免在高分辨率图像处理中展开所有图像标记,从而在大语言模型解码器侧实现更高效的处理。
- NVLM-D 对来自不同模态的所有标记进行统一处理,从而在大语言模型解码器中实现联合多模态推理。然而,对于高分辨率图像,由于长标记序列(例如 256×7 = 1792 个标记),即使借助了瓷砖标记的帮助,推理仍然可能具有挑战性。
NVLM-H 是一种新颖的混合架构,结合了两种方法的最佳特性。它将图像标记的处理分为两条路径。缩略图图像标记与文本标记一起输入到 LLM 中,并通过自注意力层处理,从而实现联合多模态推理。同时,动态数量的常规图像块通过门控交叉注意力处理,使模型能够捕捉更细微的图像信息。这种方法不仅在高分辨率图像处理上优于 NVLM-X,同时计算效率相比 NVLM-D 也有显著提高。
动态高清标签位
NVLM-H 也使用相同的1-D展平的tile标签。主要的区别在于处理方式:将<tile_k>的文本嵌入与视觉嵌入一起输送到门控跨注意力层中。这种方法是有效的,因为在预训练期间,文本和视觉嵌入很好地配对,使得模型能够在跨注意力机制中无缝地理解和处理tile标签。
模型设置:- 骨干LLM: Qwen2–72B-Instruct
- 视觉编码模型: InternViT-6B-448px-V1–5
- 对于NVLM-D模型,LLM和视觉编码器通过一个两层MLP连接以对齐模态,隐藏维度为12800 → 29568 → 8192。需要注意的是,InternViT-6B的初始隐藏维度为3200,经过像素拼接后,维度扩大到3200 × 4 即12800。
- 对于NVLM-X模型,图像特征首先通过一个一层MLP投影到LLM的隐藏维度。每8个LLM自注意力层后插入一个具有门控功能的X-注意力层,总共插入10个具有门控功能的X-注意力层。
- NVLM-H模型利用两层MLP和X-注意力层作为模态对齐模块。缩略图和常规瓦片的图像令牌通过两层MLP进行投影,隐藏维度为12800 → 29568 → 8192。投影后的缩略图令牌直接输入LLM解码器。常规瓦片的投影令牌通过X-注意力层进行交叉注意力处理。与NVLM-X模型一样,共插入10个具有门控功能的X-注意力层。
训练过程包括两个阶段。
- 预训练阶段:所有模型中,LLM主干和视觉编码器部分都被冻结,只训练模态对齐模块。
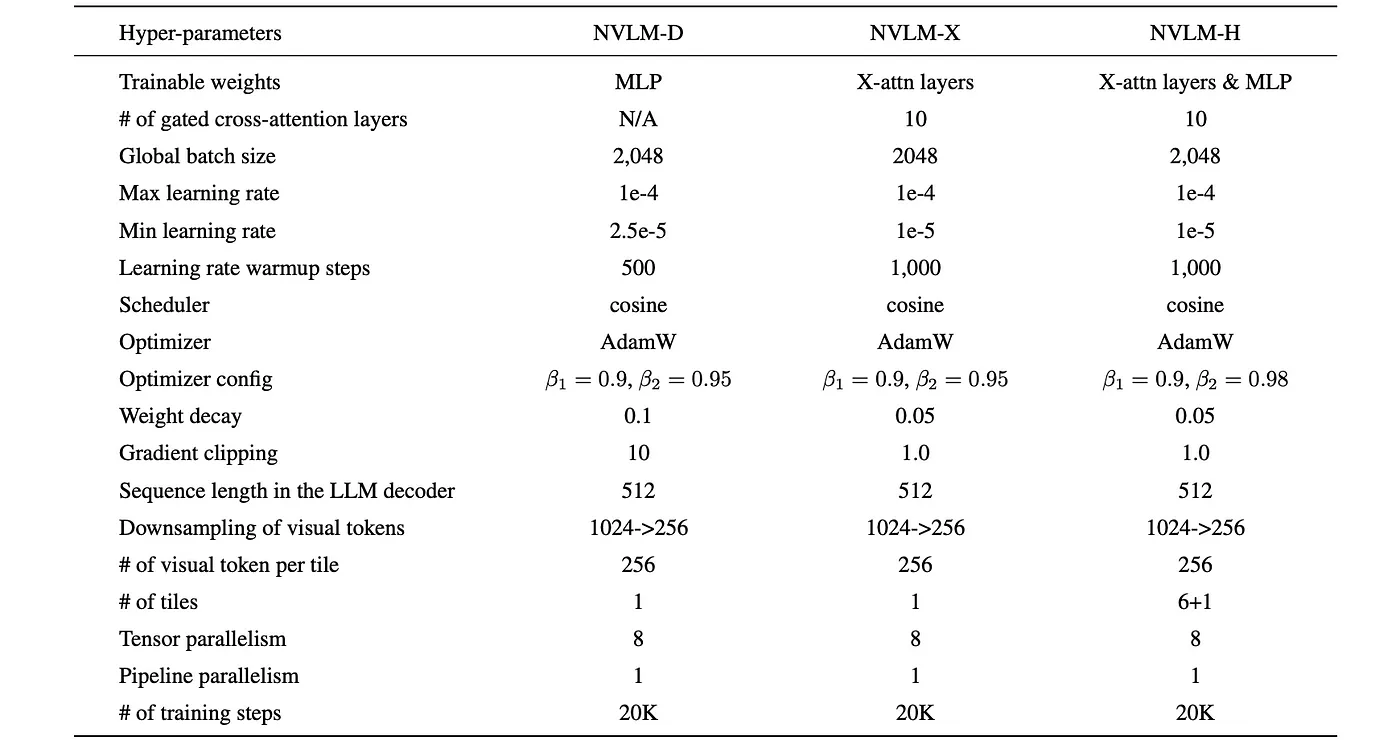
在预训练阶段中调整NVLM模型的超参数。
- 监督微调(SFT):在训练大语言模型和模态对齐模块的过程中,视觉编码器保持冻结。
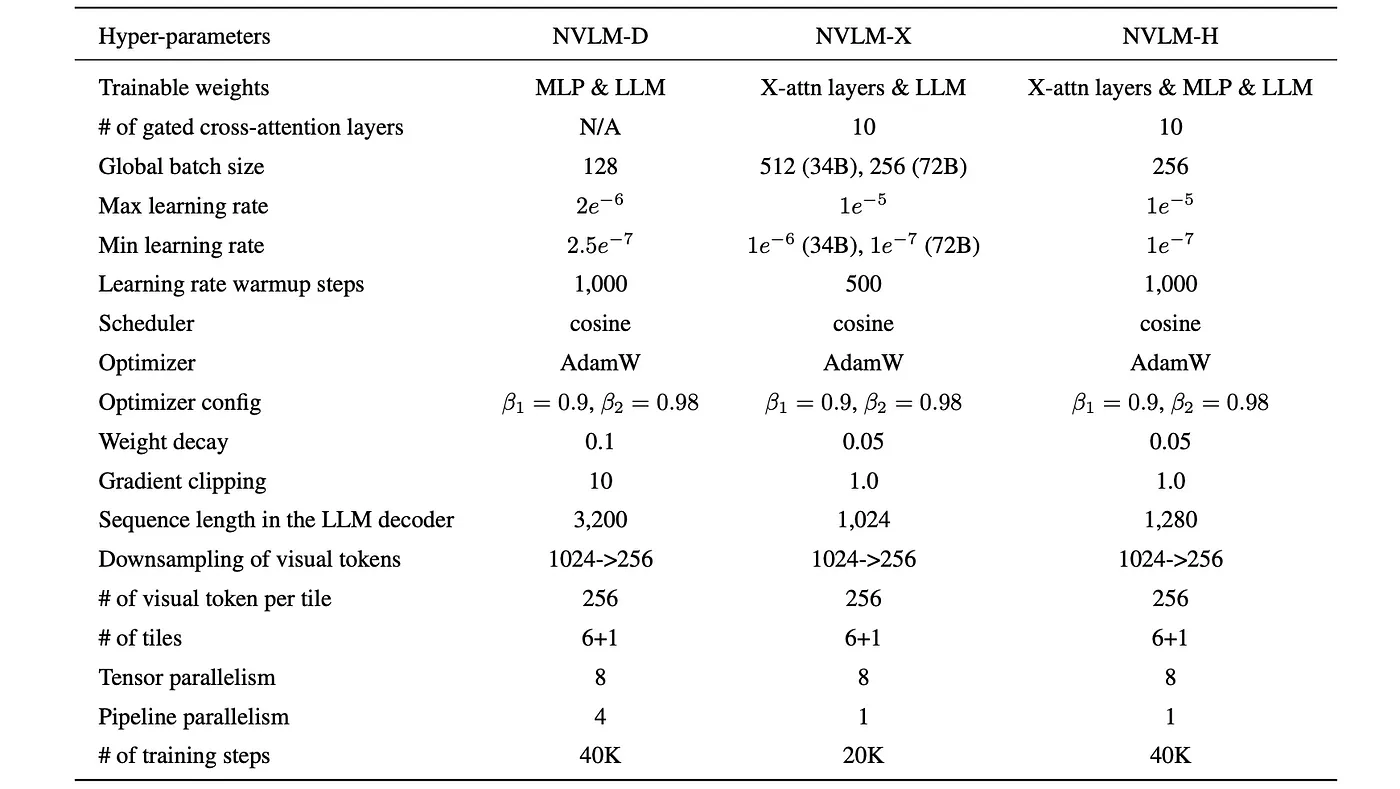
在SFT阶段训练NVLM模型的超参数(hyper-parameters)。
训练数据多模态的预训练数据
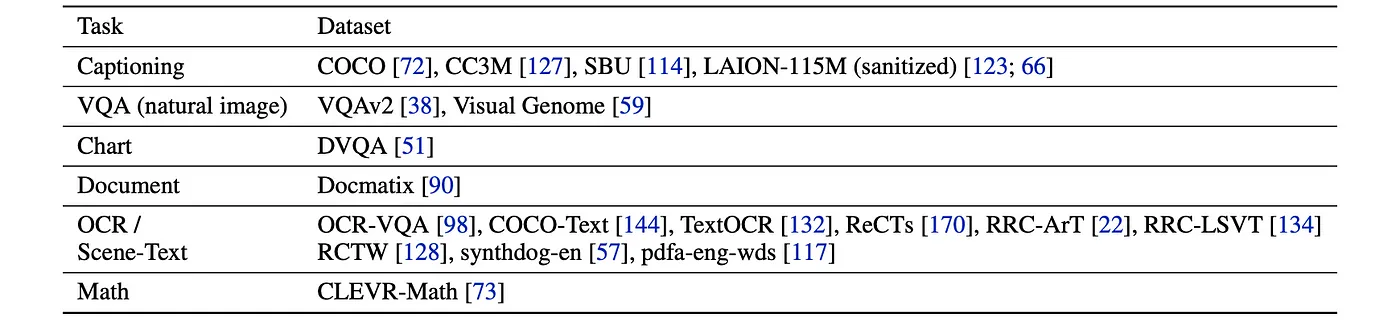
多模SFT数据
仅文本的SFT数据
一个高质量的纯文本SFT(自我指示微调)数据集被整理并纳入多模态微调阶段,有效保持了LLM骨干模型纯文本性能的优势,避免了灾难性遗忘。
SFT数据集涵盖了通用类别,包括ShareGPT、SlimOrca、EvolInstruct、GPTeacher、AlpacaGPT4和UltraInteract。此外,还包括来自数学类别的数据集,包括OrcaMathWordProblems、MathInstruct和MetaMath等数据集。涵盖来自代码类别的数据集则包括Magicoder、WizardCoder和GlaiveCodeAssistant等数据集。
为了进一步优化这些数据集中提示的回复,使用了OpenAI的模型,尤其是GPT-4o和GPT-4o-mini,来提高SFT数据集的质量。
要评估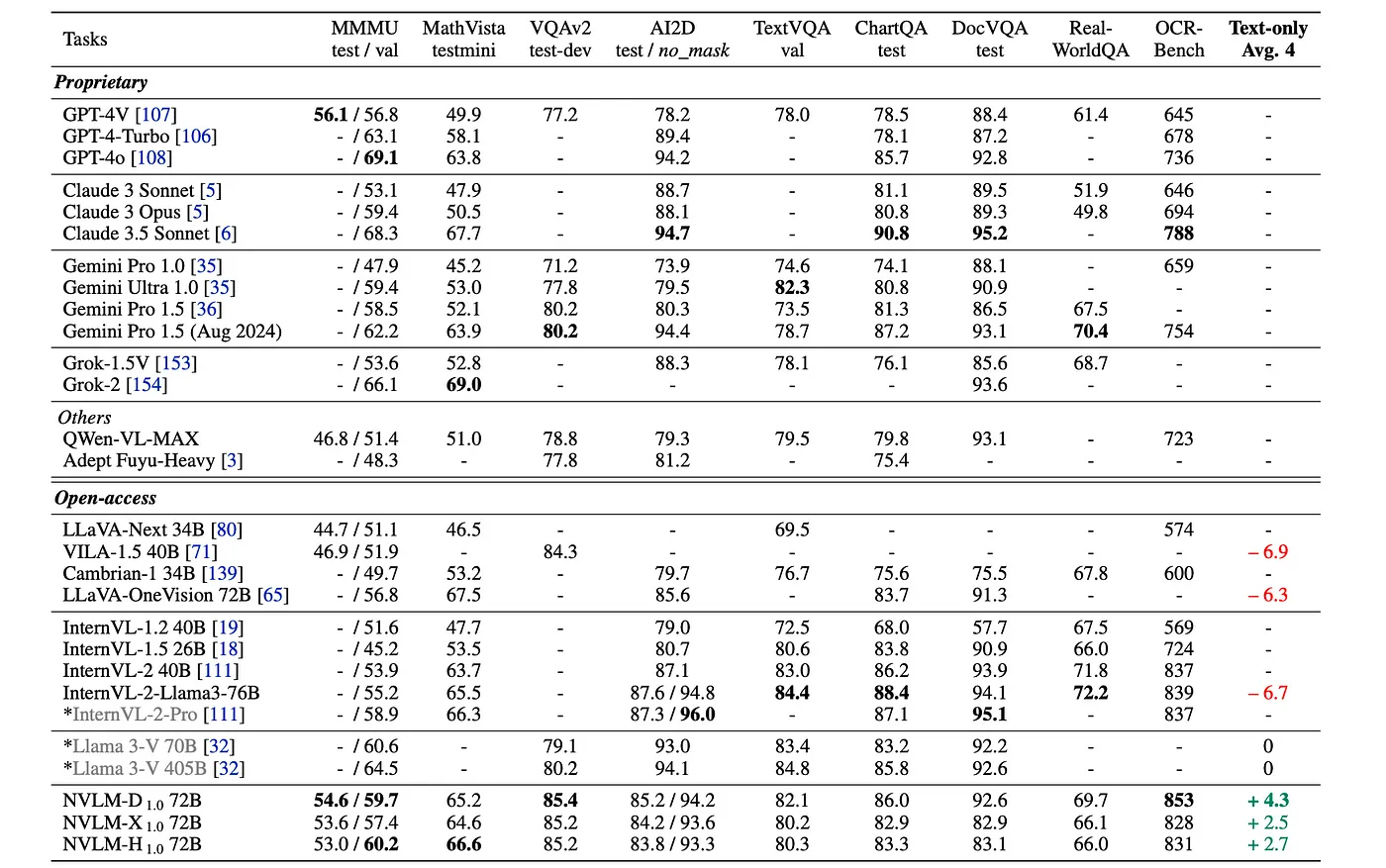
关于视觉与文本基准的评估
- NVLM-D1.0 72B 在 OCRBench(853 分)、VQAv2(85.4 分)和 MMMU(59.7 分)上取得了最高分,超过了领先的专有和开源模型。
- NVLM-H1.0 72B 在开源多模态LLM中获得了最高的 MMMU(Val)得分(60.2 分),并且在 NVLM-1.0 家族中获得了最佳的 MathVista 得分(66.6 分)。
- NVLM-X1.0 72B 与尚未发布的 Llama 3-V 70B 相媲美,并且在训练和推理速度上明显快于其仅解码的版本。
- NVLM-1.0 模型在仅文本性能上优于开源多模态LLM,例如 LLaVA-OneVision 72B 和 InternVL-2-Llama3–76B,突显了引入高质量纯文本SFT数据的有效性。
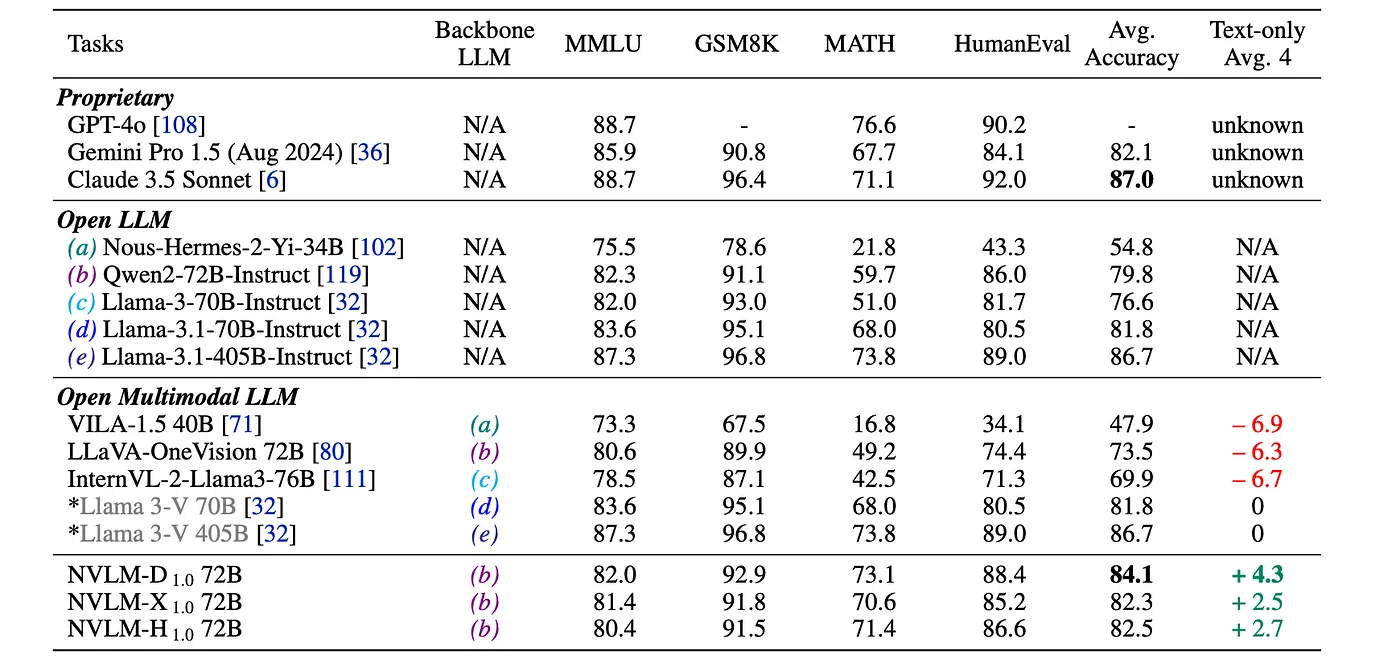
对文本基准的评价
- 开放获取的多模态LLM通常在准确率上明显低于它们的LLM基础模型。
- 这些NVLM-1.0 72B模型拥有更高的平均准确率,这可能是因为它们各自的基础LLM模型(Qwen2–72B-Instruct)相比,结合了高质量的文本监督微调(SFT)数据和大量的多模态数学训练数据。
NVLM:开放边界型多模态大语言模型 https://arxiv.org/abs/2409.11402
推荐阅读的内容 [多模态的Transformer]
想了解更多信息吗?
只需点击此处,即可发现这个系列中的其他精彩帖子或线程,探索最前沿的研究!
每周关注,不要错过更新!





