
- 完整配置和网格文件可在此获取https://www.patreon.com/posts/kohya-flux-fine-112099700




- 我还在严格测试不同的超参数,并比较每个超参数的影响,以找到最佳的工作流程
- 到目前为止已完成16次完整的训练,现在正在完成另外8次训练
- 我正在使用这个差但过拟合的15张图片的数据集进行实验(第四张图片)
- 我已证明,使用更好的数据集时,效果会好很多,并能完美生成表情
- 例如这种情况:https://www.reddit.com/r/FluxAI/comments/1ffz9uc/tried_expressions_with_flux_lora_training_with_my/
- 当分析结果时,微调后过拟合程度更低,泛化能力更佳,质量更佳
- 在前两张图片中,它能够更出色地改变发色和添加胡须,这意味着它过拟合的程度更低
- 在第三张图片中,你可以看出盔甲的质量更好,因此过拟合程度更低
- 我注意到环境和服装的过拟合程度更小,质量更佳
- Kohya 仍然没有 FP8 训练,因此,24GB 的显卡速度会大幅下降
- 另外,48GB 的显卡必须使用 Fused Back Pass 优化,速度会有一定下降
- 16GB 的显卡由于没有 FP8 支持,速度下降会更严重
- Clip-L 和 T5 的训练仍然不支持
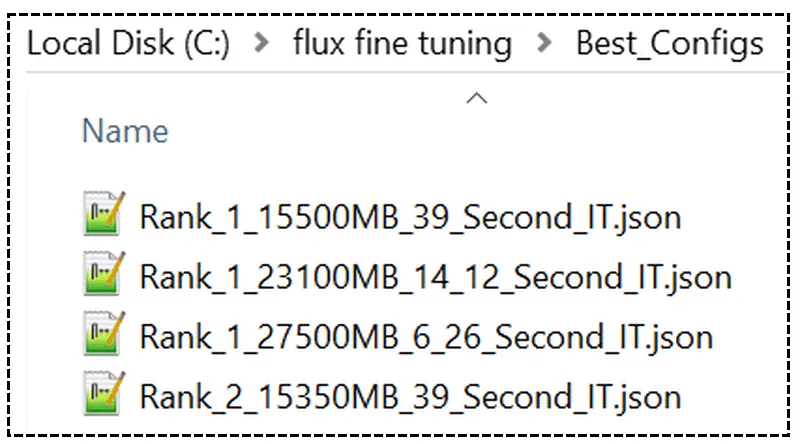
- 第1级快速配置 — 使用 27.5 GB 显存,每轮时间 6.28 秒(LoRA 每轮时间 4.85 秒)
- 第1级较慢配置 — 使用 23.1 GB 显存,每轮时间 14.12 秒(LoRA 每轮时间 4.85 秒)
- 第1级最慢配置 — 使用 15.5 GB 显存,每轮时间 39 秒(LoRA 每轮时间 6.05 秒)
- 保存的检查点为FP16,因此大小为23.8GB(没有训练Clip-L或T5)
- 根据Kohya的说法,应用的优化不会改变质量,因此所有配置目前都被评为第一
- 我仍在测试这些优化是否会对质量有任何影响
- 我仍在尝试寻找更好的超参数
- 所有训练都在1024x1024分辨率下进行,因此降低分辨率可以提高速度,减少VRAM使用,但也会降低质量
- 希望当FP8训练到来的时候,即使12GB的显存也能很好地进行精细调优,速度也会很快





