

“Python 瓶颈问题。”图片来源 — Viktoria Drake @ viktoria.dev
比如说,你写了个脚本处理笔记本上的数据,去喝咖啡休息一下,15分钟后回来一看,才跑了10%。
怎么这么慢?是哪个环节慢?是读取、处理还是保存数据慢?我怎么才能让它快点?它是不是真的慢?
一个名为 profiler 的工具可以帮你回答这些问题。
什么是Profiler呢?剖析器(Profiler)是一个工具,它会分析你的代码,运行它,并收集每个函数调用的耗时信息、执行次数以及调用栈。
通过分析其输出,你可以找出代码中最耗时的部分(称为瓶颈),甚至可能找到改进的方法。你想识别并解决这些瓶颈,这会带来整体速度的最大提升。
本例问题比如说,我们有一个很大的文本文件,我们想在其中找到几次特定模式。首先,让我们生成一个包含随机字母和数字的大型文件。
import random
import string
def generate_random_string(length):
"""生成由小写字母和数字组成的指定长度的随机字符串。"""
letters_and_digits = string.ascii_letters + string.digits
return ''.join(random.choice(letters_and_digits) for _ in range(length))
def generate_random_file(filename, num_lines, line_length):
"""生成一个指定行数和行长度的随机行文件。"""
with open(filename, 'w') as f:
for i in range(num_lines):
random_line = generate_random_string(line_length) + '\n'
f.write(random_line)
if __name__ == '__main__':
# 生成一个文件,包含1,000,000行,每行具有1000个字符
generate_random_file('random.txt', 1_000_000, 1000) 接下来,让我们定义我们的基线函数——它逐行读取文件,并统计其中前面带有数字的 bob 和 rob 的出现次数。例如,统计前面带有数字的 bob 和 rob 的出现次数。
import re
def baseline():
num_total_matches = 0
pattern1 = r"[0-9]{1}bob"
pattern2 = r"[0-9]{1}rob"
with open('random.txt', 'rt') as f:
# 读取文件并逐行处理
for line in f:
line = line.lower() # 将文本转换为小写
for pattern in [pattern1, pattern2]:
# 查找字符串中所有模式的匹配项
matches = re.findall(pattern, line)
# 计算匹配的数量
num_matches = len(matches)
num_total_matches += num_matches
return num_total_matches # 返回匹配的总计数量比如,这个字符串abc1robdef02bob中有两个“出现”。
我们运行了 baseline 函数,计算出现次数(在我的例子中是 10861 次),并测量运行耗时,我的机器上是 32 秒。
我们怎么才能让它更快?
潜在改进空间以下是让代码运行变慢的四个部分:
- 使用原始字符串(而不是编译的正则表达式对象)
- 使用两个单独的搜索操作而不是单个联合的正则表达式
- 将每一行都转换为小写而不是使用忽略大小写的标志(例如 re.I)
- 逐行读取文件而不是一次性读取大块内容

我们代码中潜在的瓶颈点
我们怎么知道哪个是瓶颈?我们用一个工具叫 profiler。
Python 性能分析器好消息是您不需要自己实现任何东西。Python 自带了两个内置的性能分析模块——cProfile 和 profile。它们的作用相同,但 cProfile 是用 C 语言编写的,而 profile 则是纯 Python 编写的,不过这对我们的需求来说无关紧要。可以直接用它们。这样可以简化我们的工作。我们将会用到一些外部工具。
我们需要一种快速简便的方法来对代码的一部分(例如,一个函数)进行代码剖析并将结果保存到文件中。一个叫做 profilehooks 的模块提供了一个简单的装饰器,我们可以像下面这样将它应用到感兴趣的函数上:
from profilehooks import profile
# stdout=False -> 不在终端输出任何内容
# filename -> 包含 profiling 结果的文件路径
@profile(stdout=False, filename='baseline.prof')
def 基础实现():
...只需一条简单的命令 pip install profilehooks 即可安装它。
这里我们需要把这个文件可视化一下,让人能看得懂。我用下面两种工具来做这个。
SnakeViz — 超快速简单Snakeviz(https://github.com/jiffyclub/snakeviz)将Python性能分析结果可视化,可以在浏览器里运行。安装极其简单(`pip install snakeviz),使用起来也十分方便(snakeviz <性能分析输出文件路径>)。我们来看看baseline`函数的性能分析结果吧。

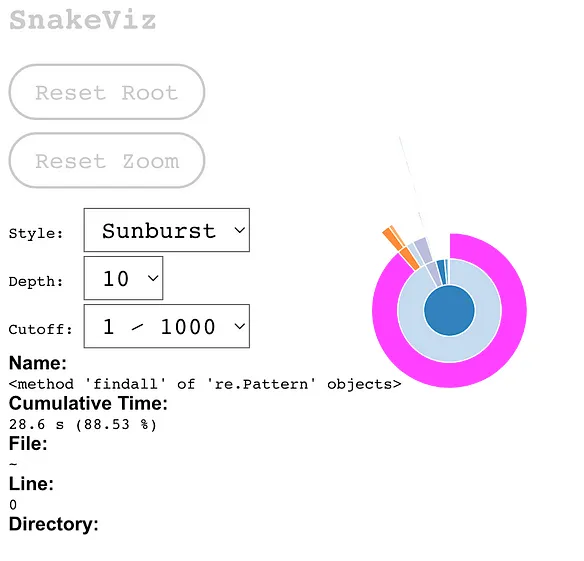
蛇可视化结果(交互式)如下所示 — icicle(左)和 sunburst(右,可能不太容易阅读)图。你可以悬停或点击每个函数调用来查看其详细信息。从上到下代表你调用的嵌套层次结构,线条的长度表示代码执行该调用所花费的相对时间的多少。
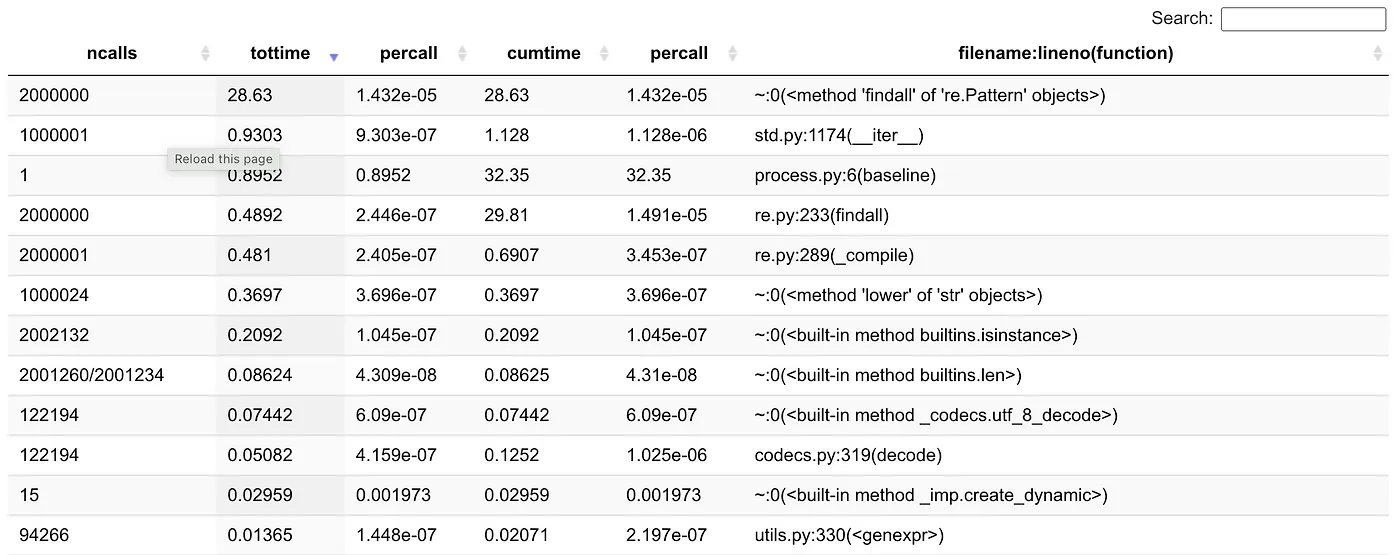
Snakeviz 还展示了一个关于你函数执行时间的交互式统计表格。
我们注意到,大部分的执行时间都花在了findall这个函数上,也就是说,在进行正则表达式匹配。也就是说,如果我们想提速代码,就需要重点加快这个函数的速度,因为它才是瓶颈,不是其他部分。
我们再用另一个工具来核对一下结果。
gprof2dot —易于阅读且灵活
Gprof2dot 提供更易读的流程图形式的可视化,保存为图片文件,易于分享,如需还可自动化。不过它不是交互式的,并且需要在系统中安装 Graphviz。
要安装 gprof2dot,只需运行命令 pip install gprof2dot。
要生成包含性能分析结果的输出图像,请使用以下命令:
python -m gprof2dot -f pstats <文件名> | dot -Tpng -o output.png我们首先将函数调用的层级表示为一个 dot 格式的图,然后生成该图的图像——即图的可视化。dot 命令支持多种输出格式,如 .jpg 和 .svg,并且 gprof2dot 的输出也非常灵活。
我们来看看它是什么样的。
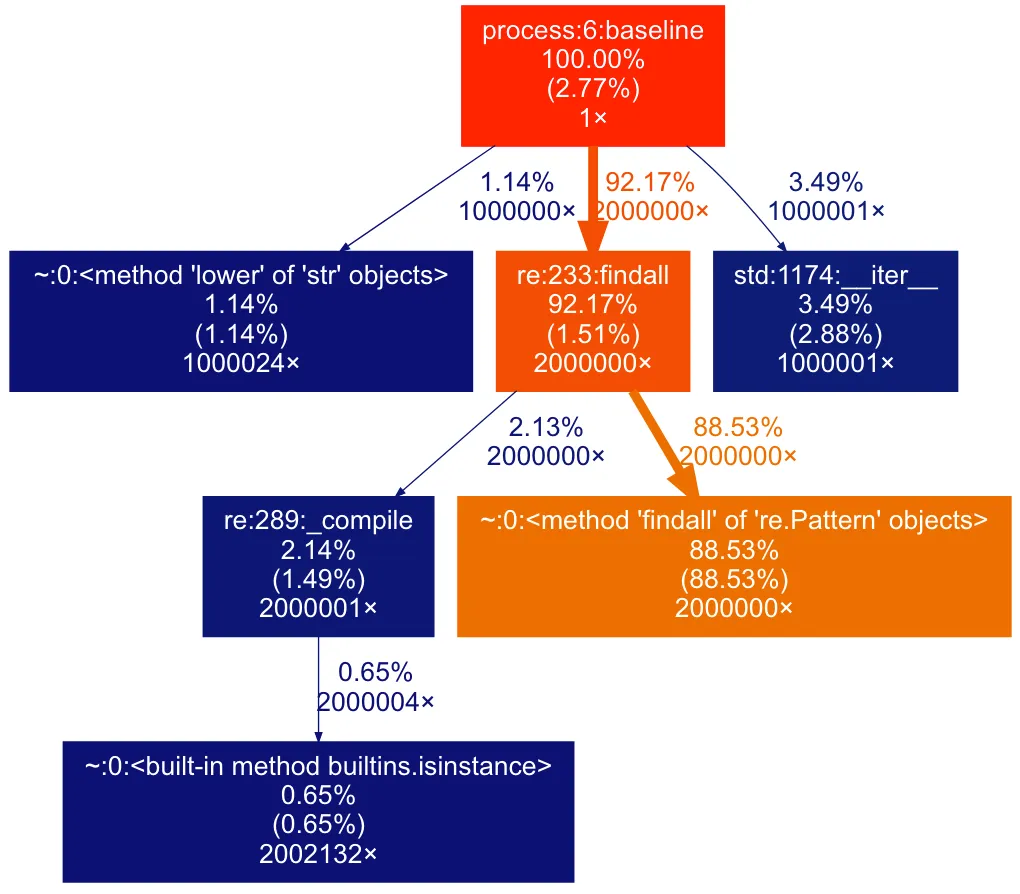
我们的代码中函数执行情况的图展示。百分比显示了函数内部执行时间所占的总比例,以及 (%) ,但这些仅包括该函数自身的代码。最后一个数字是该函数在代码中调用的次数。
现在这张图确实更易读了,它显示正则表达式的搜索占了总执行时间的88%之多,所以我们需要想办法让它跑得更快。
如果你没有安装 Graphviz(dot 命令),你可以使用一个对应的 Python 库(Graphviz)(通过 pip install graphviz 安装),并编写一个简单的 Python 脚本来生成结果。
- 我们将把
gprof2dot的输出保存为一个.dot文件:python -m gprof2dot -f pstats file.prof > file.dot这条命令会将分析结果输出到
file.dot文件中。 - 接下来,我们将使用以下代码从该
.dot文件生成一个图像:
import graphviz
# 生成指定格式的图片文件
def make_png(input_file_name, output_file_name):
dot = graphviz.Source.from_file(input_file_name)
dot.render(outfile=output_file_name)
if __name__ == '__main__':
make_png('file.dot', 'file.svg') # 也支持如 .png,.jpg 等格式让我们通过将两个正则表达式合并成一个来加快代码。
def single_pattern(): # 定义一个只进行一次模式匹配的函数
num_total_matches = 0
pattern = r"[0-9][rb]ob" # 现在我们只需要一次搜索
with open('random.txt', 'rt') as f:
for line in tqdm(f, total=1_000_000):
line = line.lower()
# 查找字符串中所有匹配模式的部分
matches = re.findall(pattern, line)
# 统计匹配数
num_matches = len(matches)
num_total_matches += num_matches
return num_total_matches跑起来,现在我们有15秒了,快了一倍!
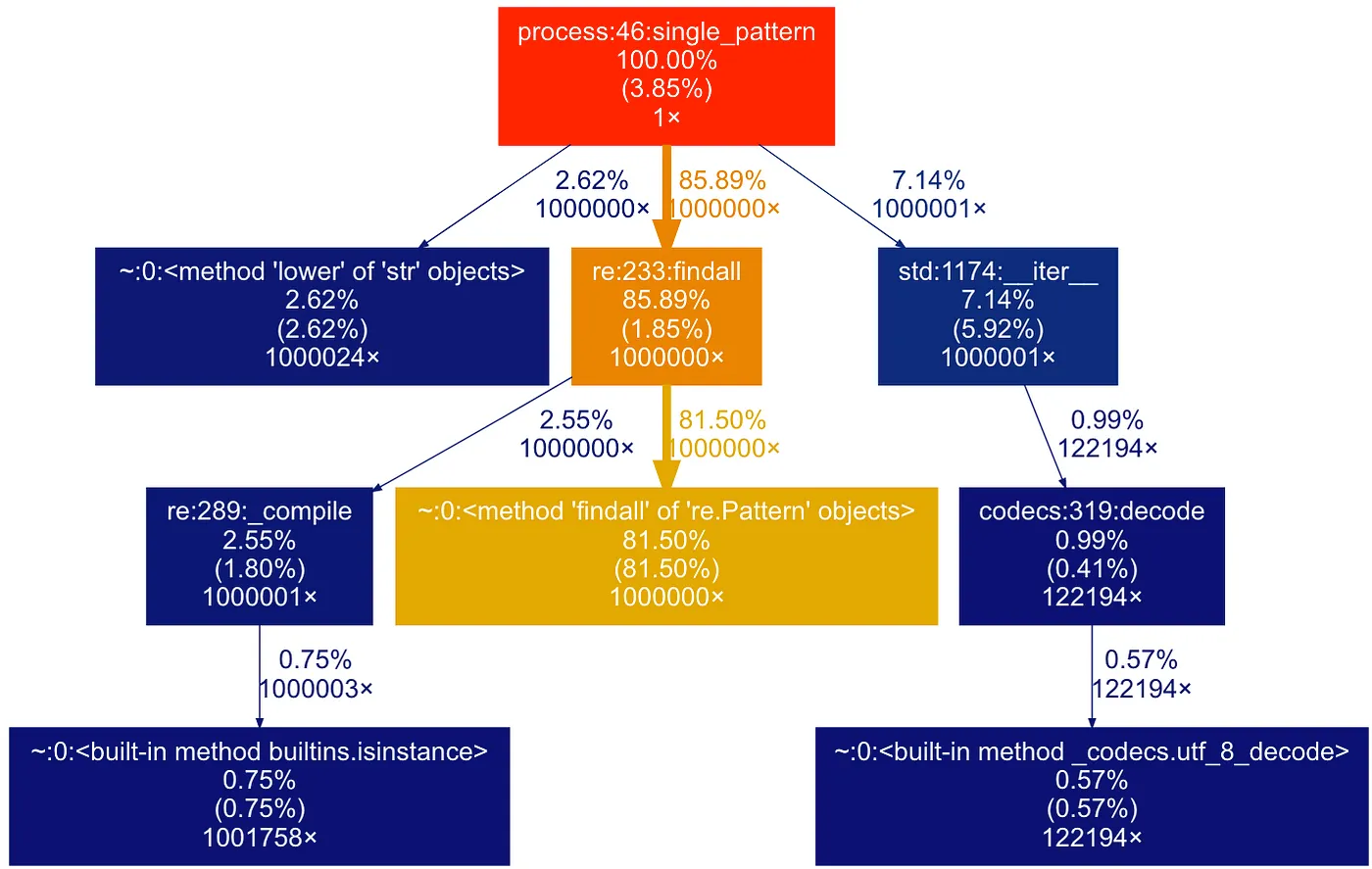
新代码的性能分析结果如下。注意,findall 花费的时间百分比从 88% 下降到 81.5%。
分析新代码后,我们确认这是一个正确的选择——主要的findall函数所用的时间减少了,而其他函数的执行时间则增加了大约两倍。
如果我们实现其他三个想法而不是专注于瓶颈,运行时间会是32秒,和原来的完全一样!我们白费了这么多功夫却毫无进展!这就是为什么专注于瓶颈很重要。
def 无效的努力():
总匹配数 = 0
# 我们使用了正则表达式的编译版本
模式1 = re.compile(r"[0-9]{1}rob", flags=re.IGNORECASE)
# 我们也使用了大小写不敏感性
模式2 = re.compile(r"[0-9]{1}bob", flags=re.IGNORECASE)
with open('random.txt', 'rt') as f:
# 我们将行加载到一个块中,然后一次性处理
块 = []
for 行 in tqdm(f, total=1_000_000):
块.append(行)
if len(块) == 1000:
块字符串 = ''.join(块)
for 模式 in [模式1, 模式2]:
# 在字符串中查找所有匹配的模式
匹配 = re.findall(模式, 块字符串)
# 计算匹配的数量
匹配数 = len(匹配)
总匹配数 += 匹配数
块 = []
# 尽管我们做了努力,这段代码仍然像原文一样慢
return 总匹配数findall函数依然是瓶颈。然而,在这个简单的例子中,我们只能做一件事来进一步提升它:将代码并行化。
不同字符串中的匹配互不相关,因此我们可以同时搜索这些匹配。那我们该怎么操作呢,大家有什么好主意吗?
最简单的方法是创建一个进程池——一个操作多个可并行运行的 Python 进程的对象,这些进程可以同时运行。如果我们有一个值列表和一个应用于每个值的函数,我们只需调用进程池的 map 方法即可,它就会为我们并行运行该函数,处理所有这些值。
from multiprocessing import Pool
def 计算匹配数量(string):
# 这是一个为Pool对象准备的函数
# 它将在文件的每一行上并行执行
pattern = r"[0-9]{1}[rb]ob"
return len(re.findall(pattern, string))
def 分块单个池():
总匹配数 = 0
pool = Pool(8) # 进程数量,应不超过您的CPU核心数
with open('random.txt', 'rt') as f:
分块 = []
# 我们将行加载到列表里
for line in tqdm(f, total=1_000_000):
line = line.lower()
分块.append(line)
if len(分块) == 1000:
# 然后我们并行地将`计算匹配数量`函数应用于分块中的每一行
匹配数 = pool.map(计算匹配数量, 分块)
# 将所有独立匹配的数量汇总起来
总匹配数 += sum(匹配数)
# 清空分块
分块 = []
返回 总匹配数哇,6.1秒!这是一个新的记录。它比我们优化后的方案快2.2倍,比原来的方案快约5倍!我们来看一下性能分析的结果:
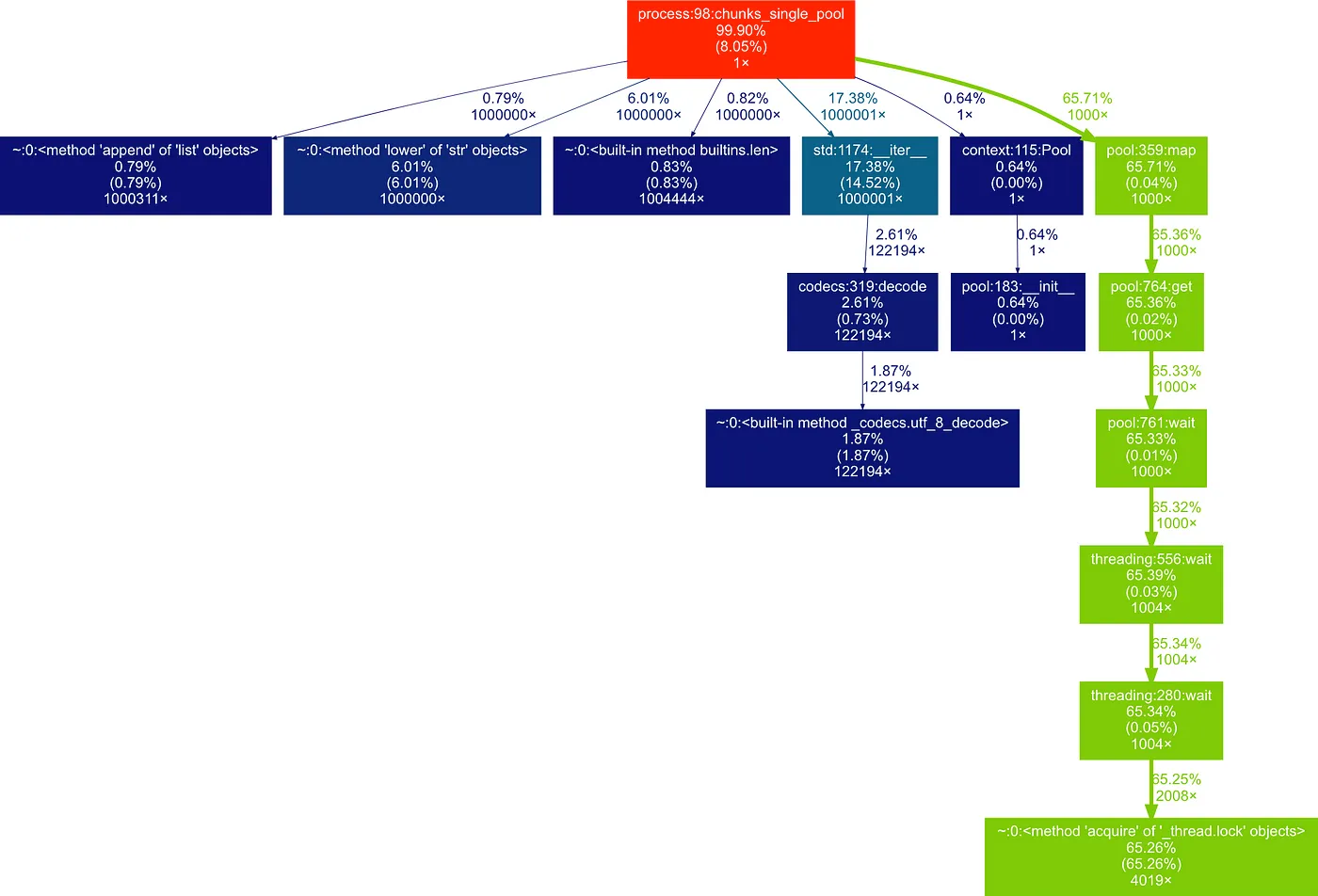
多进程代码的分析结果。可以看到,正则表达式搜索的比例在不断减少(绿色块)。

Snakeviz 会为多进程的代码显示相同的图表。
他们确认现在当前的正则表达式搜索大约占据总时间的2/3,远低于原来的版本。
一个注意点 多处理进程一个重要的注意事项是,剖析器不再知道子程序中进行正则表达式搜索时的具体情况。它只是显示了等待所有这些进程完成共花了4秒,但它无法访问子程序中执行的代码,因为这些子程序是与我们的主Python进程松散连接的独立程序。
如果你想分析程序中子进程的运行状况,你应该在将会在子进程中执行的函数或代码中添加 @profile 装饰器。
一般情况下,由于[全局解释器锁(GIL)]的限制,单个Python进程中同一时间只能有一个线程执行Python代码,因此你通常不需要直接编写多线程的Python代码。
不过,如果你在使用很多非Python的库(例如NumPy、PyTorch、scipy)或者处理大量输入输出(例如网络通信),那么你的程序运行时间大多花费在Python解释器之外运行用C、C++、Fortran等语言编写的代码。
在这样的两个场景中,使用多个线程可能是实用的,因此你需要明白,Python 内置的两个性能分析工具模块——profile 和 cProfile——仅对应用程序的主线程进行性能分析。如果你想分析其他线程执行的代码,你可以在线程执行的函数中运行性能分析器,或者使用一些第三方性能分析工具,例如 Yappi 或 VizTracer。
GPU(图形处理器)计算:如果你使用 GPU 进行计算,请注意它在你的系统中是一个独立的硬件,并且与你的 CPU 异步工作。当你在 GPU 上运行代码时,测量执行时间时要特别小心,因为你的 Python 代码无法知道 GPU 上的具体情况。它只能让 GPU 去执行任务,并等待 GPU 完成。
下面来看这段代码:
导入 torch
from profilehooks import profile
@profile(filename='gpu_test.prof', stdout=False)
def compute_big_sum(tensor: torch.Tensor):
# 执行一些耗时的计算,最终输出一个结果
a = tensor.sum()
b = tensor.pow(2).sum()
c = tensor.sqrt().sum()
sum_all = a + b + c
sum_all_cpu = sum_all.cpu() # 将值移动到CPU内存
# 返回所有操作结果的总和(标量)
return sum_all_cpu
if __name__ == '__main__':
# 创建一个位于GPU上的大随机数矩阵
X = torch.rand((10000, 10000), dtype=torch.float64, device='cuda:0')
res = compute_big_sum(X)
print(float(res)) 我们在 PyTorch 中(在 GPU 上)创建一个 10000x10000 的矩阵,然后对计算如下操作的函数进行性能分析:
- 所有元素的总和
- 所有元素平方的总和
- 所有元素平方根的总和
- 前三项的总和
这个函数会输出一个数字。
你觉得哪一行代码最耗时?

性能分析结果:_compute_bigsum函数的
或
性能分析结果:计算大和的
更令人惊讶的是,是 .cpu() 方法将数据从 GPU 内存移动到了 CPU 内存!但这似乎没有道理,我们只是在移动 8 字节大小的数据!内存传输真的这么慢吗?数据传输速度真的这么低吗?
不行
由于在 PyTorch 的底层,计算是由 CUDA 在 GPU 上完成的,而 GPU 是一个独立于 CPU 的设备,因此当你使用 .sum() 或 torch.pow() 或其他类似函数时,Python 只是告诉 GPU 开始算,并不会等计算结果出来!这意味着 Python 会立即跳到下一行代码。
等待发生在 .cpu() 方法里,该方法会把数据从 GPU 内存移到 CPU 内存。因此,它必须等待,直到所有之前的计算结果都在 GPU 内存中准备好——也就是说,我们对大矩阵做的所有操作都已完成。
但我们如何建立这个档案呢?
- 使用内置的PyTorch profiler,它支持跨多个设备的操作性能剖析;
- 如果你对每个单独的GPU操作所花费的时间不感兴趣(或者你只有一个GPU),你可以在启动所有GPU计算后立即在代码中添加
torch.cuda.synchronize(),这将迫使PyTorch等待所有GPU上的操作完成。
让我们看看这条线上的特征分析结果怎么样。
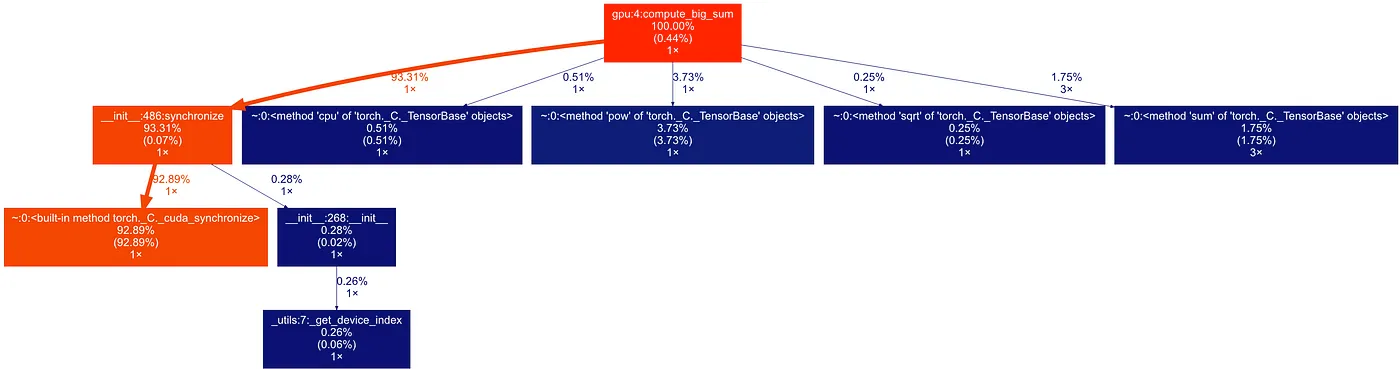
使用 torch.cuda.synchronize() 时的分析结果。现在来看,. cpu() 只占总时间的大约 1%,而大部分运行时间都花在等待 GPU 计算结束上,这符合预期。
我们修改后的 compute_big_sum 函数的代码如下:
def compute_big_sum(tensor: torch.Tensor):
a = tensor.sum()
b = tensor.pow(2).sum()
c = tensor.sqrt().sum()
sum_all = a + b + c
torch.cuda.synchronize() # 在所有GPU操作之后添加这行代码
# 这将确保时间测量的准确性
sum_all_cpu = sum_all.cpu()
return sum_all_cpu



