
Falcon Mamba 是阿布扎比技术创新研究所 (TII) 推出的新模型,该模型是在 TII Falcon Mamba 7B 许可证 1.0 下开放访问和开源。任何人都可以用于研究或应用目的,该模型在 Hugging Face 生态系统中的 此处 也可以获取。
在这篇博客中,我们将讨论模型背后的设计决策,该模型如何在与其他现有SOTA(最先进)模型的竞争中具有优势,以及如何在Hugging Face生态系统中使用它。
首个通用的大规模预训练纯Mamba模型,基于注意力机制的Transformer模型是当今所有最强大的大型语言模型中主导的架构之一。然而,但由于序列长度增加会增加计算和内存成本,注意力机制在处理长序列时本质上是有限制的。各种替代架构,特别是状态空间语言模型(State Space Language Model,SSLMs),试图解决处理长序列的限制,但与最先进的Transformer相比,它们的表现却不如最先进的Transformer。
借助 Falcon Mamba,我们展示了序列尺度限制确实可以在不影响性能的情况下被克服。Falcon Mamba 基于最初在 Mamba: 具有选择性状态空间的线性时间序列建模 中提出的 Mamba 架构,并添加了额外的 RMS 规范化层以确保在大规模训练中的稳定性。这一架构选择确保 Falcon Mamba 具备以下特性:
- 可以处理任意长度的序列而不会增加任何内存存储,特别是可以在单个 A10 24GB GPU 上运行而无需增加内存。
- 生成新 token 所需的时间是固定的,与上下文的大小无关,详见 此部分
Falcon Mamba 是用大约 5500GT 的数据训练而成的,主要由精炼的网络文本数据组成,并加入了来自公共来源的高质量技术数据和代码文本。我们主要采用恒定的学习率进行训练,随后经历了一个相对较短的学习率衰减阶段。在这一阶段的最后,我们也加入了一部分高质量的精选数据来进一步提升模型性能。
评价使用 lm-evaluation-harness 包在新排行榜版本的所有基准上对模型进行评估,然后使用 Hugging Face 的分数标准化方法来规范化基准的评估结果。
在理论上高效处理大规模序列的SSM模型的基础上,我们使用optimum-benchmark库比较了Falcon Mamba与流行Transformer模型的内存使用和生成吞吐量。为了公平比较,我们将所有Transformer模型的词汇表大小调整为与Falcon Mamba相同,因为词汇表大小对模型的内存需求有很大影响。
在进入结果之前,让我们先讨论一下序列中的提示(预填充)和生成(解码)部分之间的区别。正如接下来将要看到的,预填充的细节对于状态空间模型来说比变压器模型更为关键。当变压器生成下一个标记时,它需要关注上下文中所有先前标记的键和值,这意味着它需要更多的内存和时间。状态空间模型只关注和存储其循环状态,因此无需额外的内存或时间来生成长序列。虽然这解释了状态空间模型在解码阶段相对于变压器的优势,但是在预填充阶段需要额外的努力来充分利用状态空间模型架构。
预填充的标准做法是并行处理整个提示,以充分利用GPU资源。这种方法在optimum-benchmark库中被使用,我们将这种方法称为并行预填充。并行预填充需要在内存中保存提示中每个令牌的隐藏状态。对于转换器模型而言,这种额外的内存主要由KV缓存占用。对于SSM模型而言,无需缓存,存储隐藏状态的内存是唯一与提示长度成正比的部分。因此,内存需求会随着提示长度的增加而增加,SSM模型将像转换器模型一样失去处理任意长度序列的能力。
另一种替代并行预填充的方法是逐令牌处理提示文本,我们将这种方法称之为顺序预填充。类似于序列并行,它不仅可以在单个令牌上进行,还可以在更大的提示块上进行,以更有效地利用 GPU。虽然顺序预填充对于变压器而言意义不大,但它为 SSM 模型处理任意长度的提示提供了可能。
有了这些考虑,我们首先测试了可以容纳单个24GB A10 GPU的最大序列长度,并将结果放在下方的图中。批大小固定为1,我们使用的是float32精度。即使对于并行预填充阶段,Falcon Mamba也能容纳比变压器更大的序列,而在顺序预填充阶段,它完全发挥其潜力,可以处理任意长度的提示。
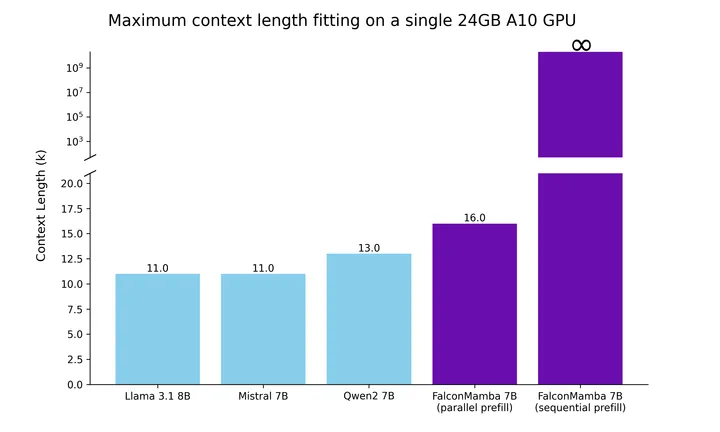
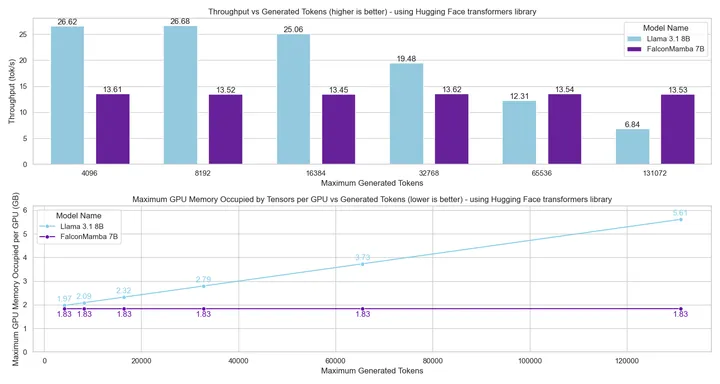
接下来,测量在长度为1的提示且最多生成130k个标记的情况下,使用批量大小1和H100 GPU的生成吞吐。结果如下方的图所示。可以看到,Falcon Mamba在整个过程中以恒定的吞吐生成所有标记,并且CUDA的峰值内存没有增加。对于变压器模型,随着生成标记数量的增多,峰值内存增长且生成速度逐渐减慢。
在Hugging Face的transformers中,我们应该怎么使用它?
猎鹰曼巴架构将在Hugging Face transformers库的下一个版本(>4.45.0)中可用。使用该模型时,请确保安装了最新版本的Hugging Face transformers或通过安装源代码版本。
猎鹰魔鼠兼容Hugging Face提供的大多数API,比如你熟悉的AutoModelForCausalLM或pipeline等。
从transformers库中导入AutoModelForCausalLM 和 AutoTokenizer model_id = "tiiuae/falcon-mamba-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, torch_dtype="auto", device_map="auto")
inputs = tokenizer("Hello world, today", return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=100, do_sample=True)
print(tokenizer.decode(output[0], skip_special_tokens=True))因为这个模型很大,它还支持如 bitsandbytes 量化技术等功能,以便在较小的 GPU 内存条件下运行模型,例如:
从transformers库导入 AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig model_id = "tiiuae/falcon-mamba-7b"
tokenizer = AutoTokenizer.from_pretrained(model_id) # 加载分词器
quantization_config = BitsAndBytesConfig(load_in_4bit=True) # 设置量化配置
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config) # 加载模型并应用量化配置
inputs = tokenizer("Hello world, today", return_tensors="pt").to(0) # 将输入转换为适合模型的格式并移动到指定设备
output = model.generate(**inputs, max_new_tokens=100, do_sample=True)
print(tokenizer.decode(output[0], skip_special_tokens=True))这是经过指令优化的Falcon Mamba版本,该版本通过额外的50亿个SFT数据进行了微调。这种扩展的训练增强了模型执行指令任务的能力,使其更加准确和有效。您可以通过这里的演示来体验指令模型的功能:这里。聊天模板请使用以下格式。
用户:
提示:
助手: 您也可以直接使用这两个模型的4位转换版本,即基础版模型和指令版模型。请确保您的GPU与bitsandbytes库兼容,以便运行这些量化模型。基础版模型(基础版模型)和指令版模型(指令版模型)。
您也可以通过使用 torch.compile 来获得更快的推理;只需在加载模型之后调用 model = torch.compile(model) 即可。





