
大多数我交谈过的数据从业者都认为有这两点。
- 我们需要一个抽象层次来一致且严谨地定义这些指标。
- 我们还没有一致的看法,这一层最终会是什么样子。暂时还没有。
每一篇Substack文章,不管是呼吁还是推广语义层,都能感受到这种强烈的氛围。
当我们查阅文献时,很少有人讨论这样一个概念的第一性原理,也没有人提到这样一个层的理想设计应该是什么样的。所以当最近有人邀请我们在新加坡举办的dbt 交流会上发言时,我们决定自己深入研究一下。
我们发现的结果非常吸引人:语义层(或度量层)不仅仅是一个概念,它是一个整个思维方式和推理方式上的范式转变,让人们在商业背景下思考和处理分析数据。
我们将这一范式转变称为“以指标为中心的思维”。
从以表格为中心的思维方式转变为以指标为中心的思维方式,就像是从Assembly转向C,或是从C转向Python一样,你正在向更高的抽象层次前进,越来越接近业务逻辑本身,而远离具体的技术细节。
这会给数据分析行业带来什么影响?
这一步让自助分析更加接近现实——非技术人员可以更好地理解和分析数据,而无需被“数据的技术思维”所困扰。
这意味着数据分析师现在可以更好地扮演思想合作伙伴的角色,以更高层次的抽象思维进行思考,这种思维方式更接近业务同事的思考方式。
好的,那咱们开始。这里有几种方式可以使用这些内容。
- 您可以观看这30分钟的演示视频。
- 如果您是那种喜欢快速浏览的人,我在邮件中附上了带语音的文稿,不过这个文稿没有视频那样全面和细致。
- 或者您可以查看幻灯片。
在YouTube上观看全程演讲视频
这是怎么回事“语义层”这个词很冗余,因为不同的供应商可能对它有不同的定义。
尽管关于语义层的讨论已经持续了一段时间,但在2021年,这些讨论变得更加热烈,伴随着几项重要事件。让我们快速回顾一下,以便更好地理解这一切是如何开始的:
- 2021年,Transform 筹集了2450万美元的B轮融资,用于构建一个能够从数据宝库中查询并构建指标的系统。
- dbt Lab 的联合创始人在其发布于 dbt Github 的帖子中提出了将指标集成到 dbt 中的问题,这为他们自己语义层的开发铺平了道路。他们后来在2022年推出了自己语义层,并在2023年收购了Transform。
- Airbnb 发布了一篇详尽的博客文章来解释他们内部的指标层 Minerva。
- Benn Stancil 通过讨论语义层的重要性引发了讨论,指出了作为现代数据堆栈中缺失部分的语义层的重要性。他指出,我们当前堆栈的根本问题在于缺乏一个集中式的仓库来建立一致的指标。
投资已作出。产品已发布。引发了讨论。有人称之为语义层,有人称之为指标层。无论它叫什么,这都是我们之前提到的转变的具体体现。
在谈到这个范式转变之前,让我们先来看一个具体例子。
示例:当日开通(以下示例来自 Pedram Navid 对指标层级的深入剖析 。这是迄今为止我们读到的最好的分析之一,我们非常推荐你完整阅读这篇文章。)

我们先不谈SQL(你可以在幻灯片/演讲中查看它们),为了当天就能激活,爱丽丝需要:
- 创建“user_funnel”,用于存储每个“user_id”的“signup_date”和“activation_date”。
- 创建“same_day_activations”,用于检查某个特定的“user_id”是否在同一天注册和激活。
- 创建“same_day_activated_daily”,统计每日同时注册和激活的“user_id”数量。
- 最后一步,创建“activation_rates”以按天计算激活率。
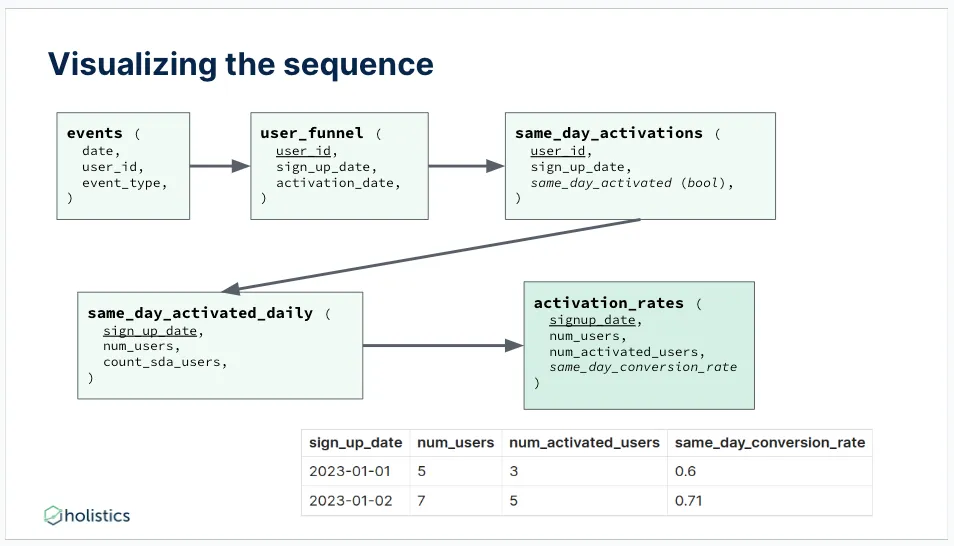
这个操作步骤很简单——但这是个好办法吗?
如果我们回顾整个过程,爱丽丝不断创造出一个又一个新的模型,直到她达到了activation_rate这个指标。为了得到单一的指标经历了如此长时间的序列,不禁让人怀疑这种努力是否值得,或者是否有更好的方法。
当我们查看这个指标的稍微不同的版本时,我们就能找到答案。
遇到的问题是:小小的改动需要重新编写表的逻辑。现在,老板没有让艾丽丝请求同日激活,而是要求她实现七天激活率。审查DAG,可以看到艾丽丝需要复制并稍微调整三个模型的逻辑:7_day_activations,7_day_activated_daily,和activation_rates。
我们为什么要这么做,不是挺简单的吗?
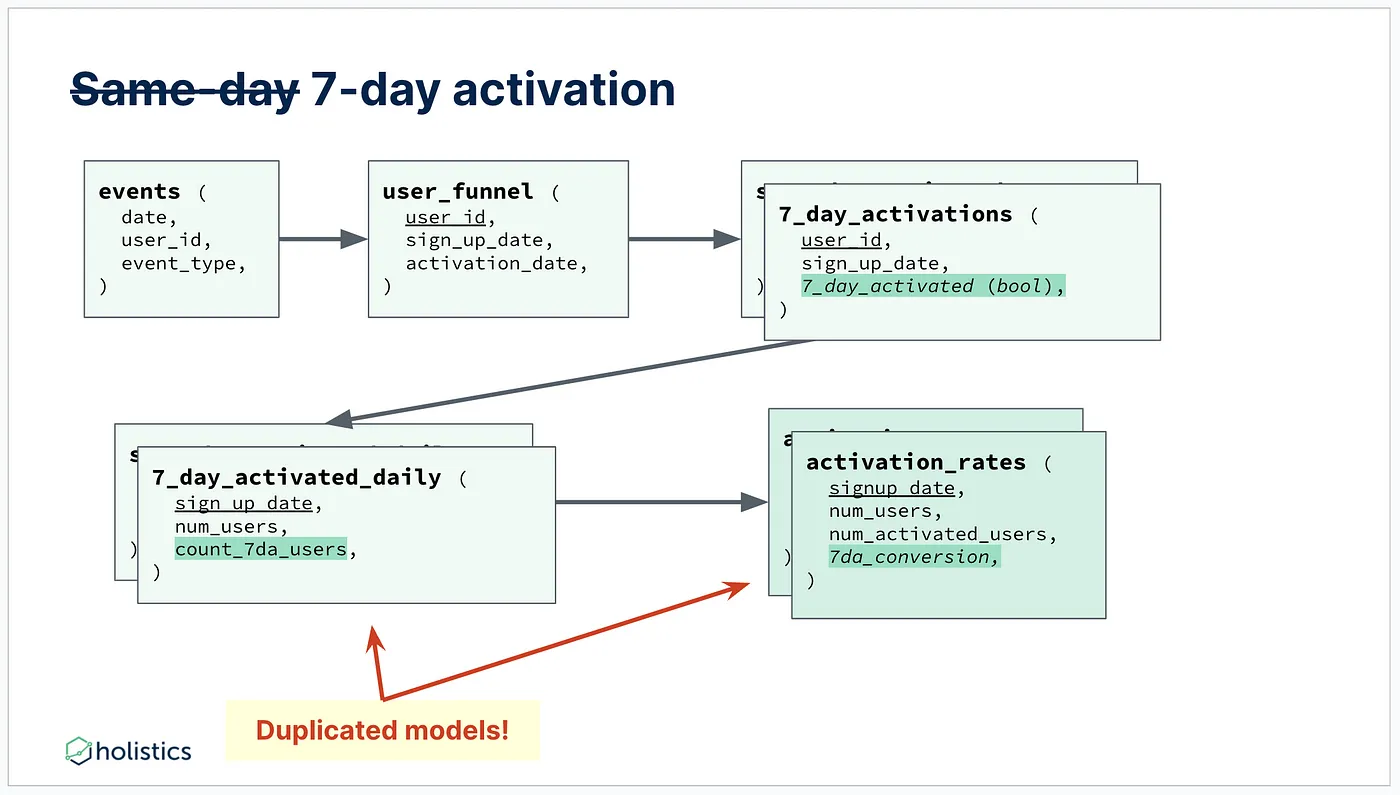
现在已经很明显了,这种维度建模方法的问题在于:任何细微的变化都会导致很多的返工,这既容易犯错——你得仔细维护重复,也耗时——任何细微的变化都会让分析师重新做很多工作。
有更好的办法吗?
希望是的。因为我们做事的方式相当于早期蒸汽机这样的分析方法:虽然勉强可以使用,但在过程中却浪费了很多努力,没有真正抓住重点。重点 (点击了解详情)。
在我们的情况下,重要的是度量逻辑。
在 dbt 中,模型是一等公民,这也没什么帮助。你定义模型,复用它们,并通过依赖图来跟踪模型间的依赖关系。模型是基本的工作单元,因此当你转换数据时,你仍然需要传递必要的维度,以确保它们能正常工作。

但是如果我们能将指标和维度定义解耦呢?
如果我们不再死盯着基于模型的思维,而是转向度量至上的模式,世界会变成什么样?
从模型为中心的思维方式转向指标中心思维让我们用度量的概念来重建上述图示,并根据一个模型来定义它们。从一种伪语法语言入手:
- 首先,定义一个具有三个不同维度的模型。
- 定义一个度量来计算用户的数量。
- 定义一个名为num_same_day_activation的度量。
- 最终,我们得到了结果:我们构建的两个度量的比率 — 同日激活的数量除以用户数量。
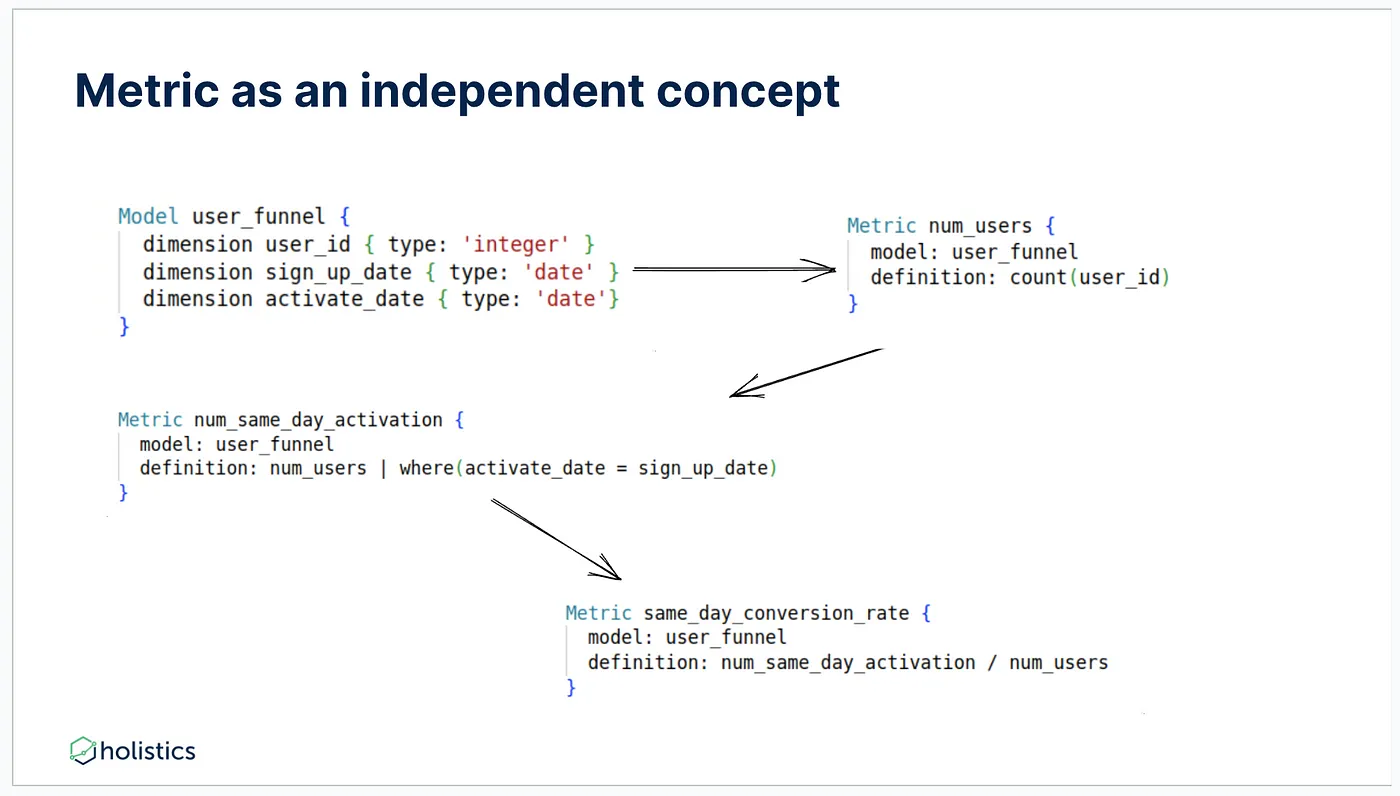
要得到类似于续集中的结果,你只需要这样写就可以了。
查询 q1 = 选择(
注册日期,
用户数量,
激活用户数,
同日转化率
)这个例子展示了,当分析师从基于模型的方法转而采用基于指标的分析时,他们可以同样地达到目标,但花费的时间和精力却少得多。
将指标与维度和表解耦后,还有哪些好处呢?
- 写起来需要花费的心智努力更少——因为你只需要专注于你想计算的聚合。
- 更直观,更贴近最终用户的日常语言。例如,在这个例子中,
num_same_day_activation被定义为“激活日期是注册日期的用户数量”。这听起来像日常英语。 - 大大减少了重复逻辑和修改的工作量。
- (最重要的是)它提供了更大的灵活性,因为维度可以在运行时组合,而不需要在开发时预设,这意味着鲍勃可以在运行时组合不同的维度——而不是等待爱丽丝将这些后续内容在开发时写好,然后在一天结束时传给他。
但这还没完。
通过这种虚构的查询语言,爱丽丝可以轻松地给鲍勃激活7天的使用权限。
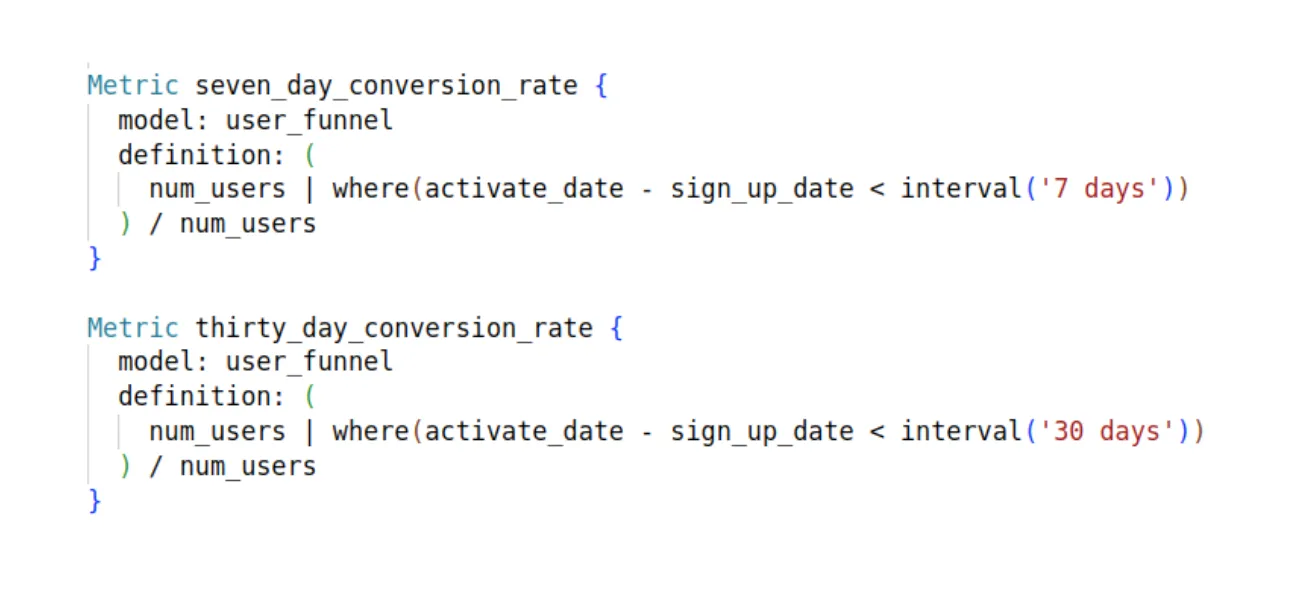
或者用参数化的指标来通用化,以计算鲍勃任意n天激活率。

如果有更多的表格会怎么样?
我想要计算2022年的新加坡客户的每个月的同日激活率按销售代理的平均值。
你需要花多少时间用SQL得到这个结果,10分钟,15分钟?通过dbt维度建模,你需要回头确定正确的地方将users表和sales_agents表连接起来,并找到正确的地方进行数据聚合。
这看起来不复杂——但整个过程在于找到何处汇合、何处聚合以及何处过滤数据,听起来对分析师而言相当乏味。
虽然技术上来说不算难,但会更累心。
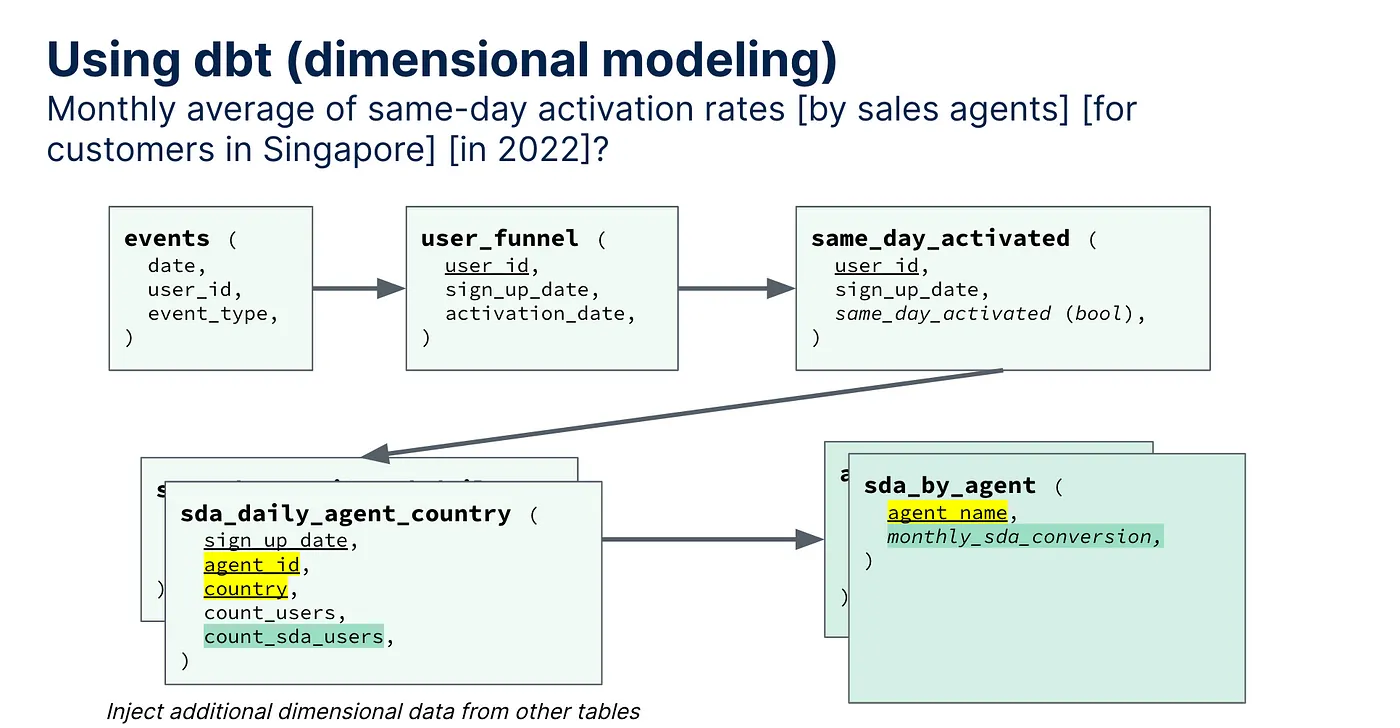
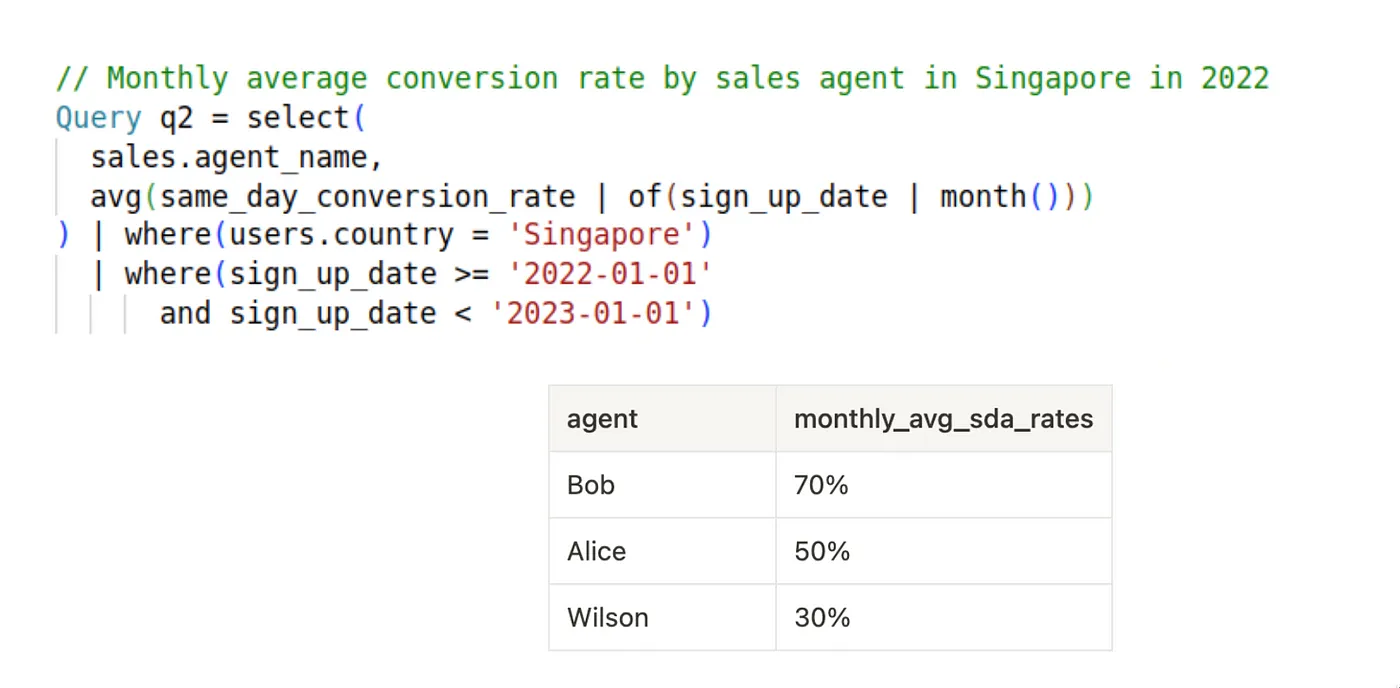
如果我们用度量单位来思考会怎么样?
有了所有这些我们之前创建的指标——要回答这个问题的话,我们只需要写五行代码。你甚至都不用担心关联操作。
不仅为分析师节省了时间,同时也为业务用户节省了宝贵的时间。你可以轻松地为该指标搭建一个用户界面,以便进行自助式探索。
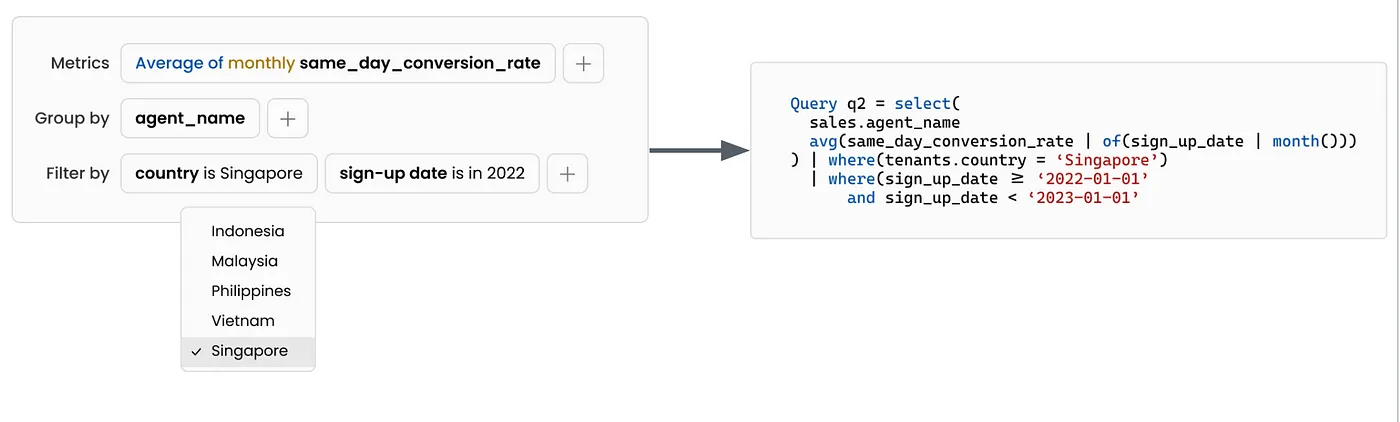
或者添加一个像ChatGPT那样的界面,让用户以自然对话的方式输入问题。
当你有了这样一个语义层和查询系统时,你可以在这个语义层中编码所有约束,从而可以提高ChatGPT的可靠性,因为用这种(假想的)查询语言生成输出比用SQL容易得多。

这听起来可能有些不真实,但想象一下理想化的指标驱动范式,可以说明语义层次能为数据团队带来实际的好处。
现在我们只需要知道要找什么。
让我们回到核心问题:理想的语义层会是怎样的?
理想的语义层次我们认为,理想的语义层应该具备以下特点:
- 提供了比 SQL 更高的抽象层级,这节省工作量,减少错误,并支持自助服务界面。
- 指标可以与维度解耦,维度可以在查询时动态提供,而不是在开发时硬编码。
- 新的指标可以基于现有的指标构建,即可以基于现有的指标构建新的指标。
- 应该支持连接操作,以便能够处理多个模型,而不仅仅是单一的模型。
而且我们也不算是唯一有梦想的人。
ThoughtSpot的CTO — Amit Prakash, 在一篇关于理想指标层设计的精彩博客文章中也提到过六类指标,其中包括:
- 简单的聚合 例如:sum(revenue),avg(price),count(distinct users)
- 结合聚合和标量表达式 例如:sum(revenue) — sum(cost)
- 需要连接的指标 例如:sum(sales.revenue * conversion_rates.exchange_rate)
- 使用窗口函数的指标 例如:按周累积求和 sales.revenue
- 需要动态分组的指标 例如:具有动态分组的指标
- 跨越无直接关联的事实表的指标 例如:metrics that span fact tables without direct relationships
其中一些度量标准类已经在像 PowerBI、Looker、Thoughtspot 和 GoodData 这样的知名 BI 工具中可用——这些工具提供了不同的能力层次,但它们被封闭在专有的黑匣子中。这个问题可以通过独立的、开源的语义层来缓解——但它们仍然有很大的改进空间。
在Holistics,我们敢打赌,语义层将是BI和分析未来不可或缺的一部分。
而我们憧憬的理想状态——将彻底改变我们熟知的分析领域。虽然我们离此还有很长的路要走,这样的未来充满吸引力,而我们如何到达那里可能更值得期待。




