
这是 Tianzheng Wang 等人在 2017 年的一篇论文《高效地使任何并发控制机制变得可串行化》的总结。[https://arxiv.org/pdf/1605.04292]
本文介绍了一种名为“可串行化安全网”(SSN)的算法,以确保事务的可串行性。该算法适用于现有的支持读已提交或快照隔离级别的数据库系统,将其转换为可串行化的系统。
这又是一篇让我头疼的论文。弄懂之后,我觉得它很有趣还很有启发性,所以我写这篇帖子来和你分享这份乐趣。
背景:串行化串行性让人感觉像是这些事务按顺序一个接一个地执行,即使它们实际上是在同时执行的。
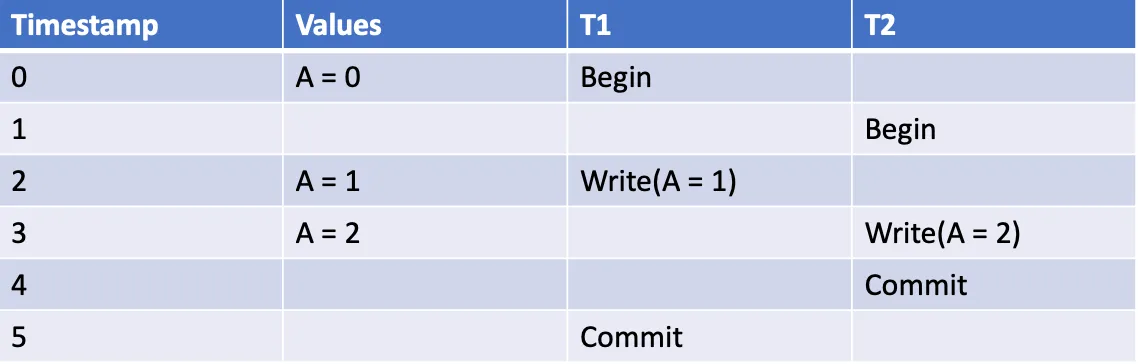
如下示例中,两个事务 T1 和 T2 不能达到串行化。
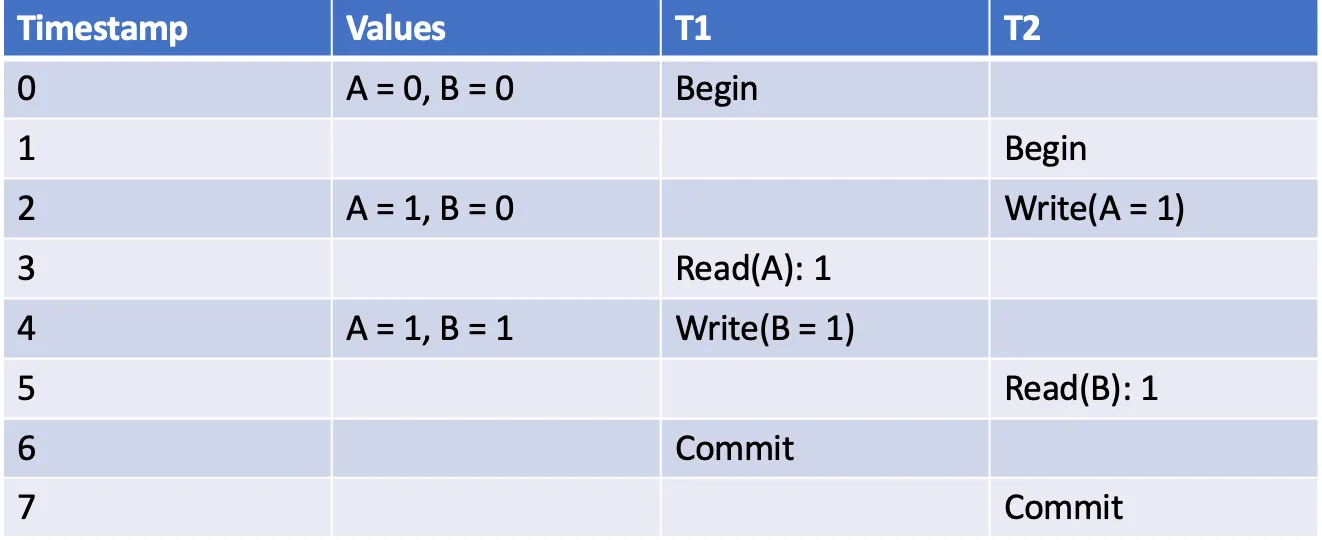
因此,T1 读取 A == 1,T2 读取 B == 1。例如,如果两个事务是按序执行的,T1 在 T2 开始之前完成提交,则 T1 应该读取 A == 0。如果 T2 在 T1 之前按序执行,则 T2 应该读取 B == 0。不管哪种情况,上述实际结果都无法用任何顺序解释。
依赖图背景可串行化违规可以通过依赖循环检测到。当存在多个事务时,它们形成一个有向图,其中节点是事务,边表示两个事务之间的依赖关系。例如,T2 读取了 T1 刚写入的值,因此 T2 依赖于 T1,用 T1 <- T2 表示。比如上述 T1 和 T2 的例子可以用一个简单的依赖关系图来表示。
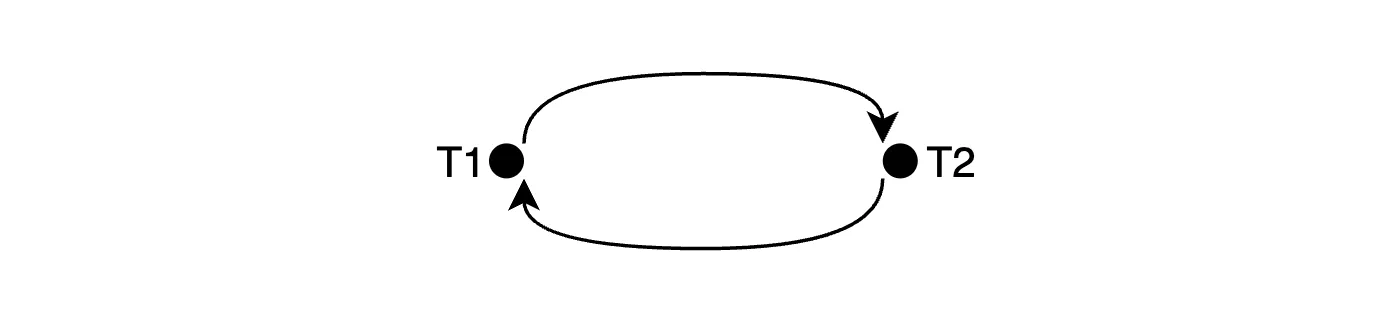
如果一个有向依赖图中没有环,则它是一个有向无环图(DAG)。DAG可以被排序成一个可串行化的执行顺序(因此它是可串行的),但是有环的图则不可串行。
有三种类型的事务依赖:write-write、write-read 和 read-write,分别表示为:
T1 <-w:r- T2 // 写-读依赖
T1 <-w:w- T2 // 写-写依赖
T1 <-r:w- T2 // 读-写反依赖例如,如果 T1 写 A = 1,然后 T2 覆盖为 A = 2,则形成 T1 <-w:w- T2 依赖关系。如果 T1 写 A = 1,然后 T2 读取到值 A == 1,则形成 T1 <-w:r- T2 依赖关系。如果 T1 读取 A == 0,然后 T2 覆盖 A = 1,则形成 T1 <-r:w- T2 依赖关系。这被称为“读取反依赖”。显然,没有 r:r 依赖。
一个“完美”的序列化算法可以简单地维护一个所有最近执行的事务的有向图,并在每次出现新的依赖关系时动态添加边。当一个事务尝试提交时,它可以遍历图以发现循环,并在存在循环时中止事务。然而,这样的算法成本过高。大多数生产数据库中的序列化算法采取了一种“近似”的方法来提高性能或减少成本:100%的时间防止“假阴性”(因此序列化违规是不可能的),但可能会导致“假阳性”:错误地拒绝一个实际上可以序列化的事务。
背景:前后依赖为了明确论文的前提,我们也需要定义前向依赖和后向依赖。前向依赖是指T2依赖于T1(T1 <- T2),也就是T1先于T2提交。后向依赖是指T1在T2之后提交,即使T2也依赖于T1。
下面举个例子:
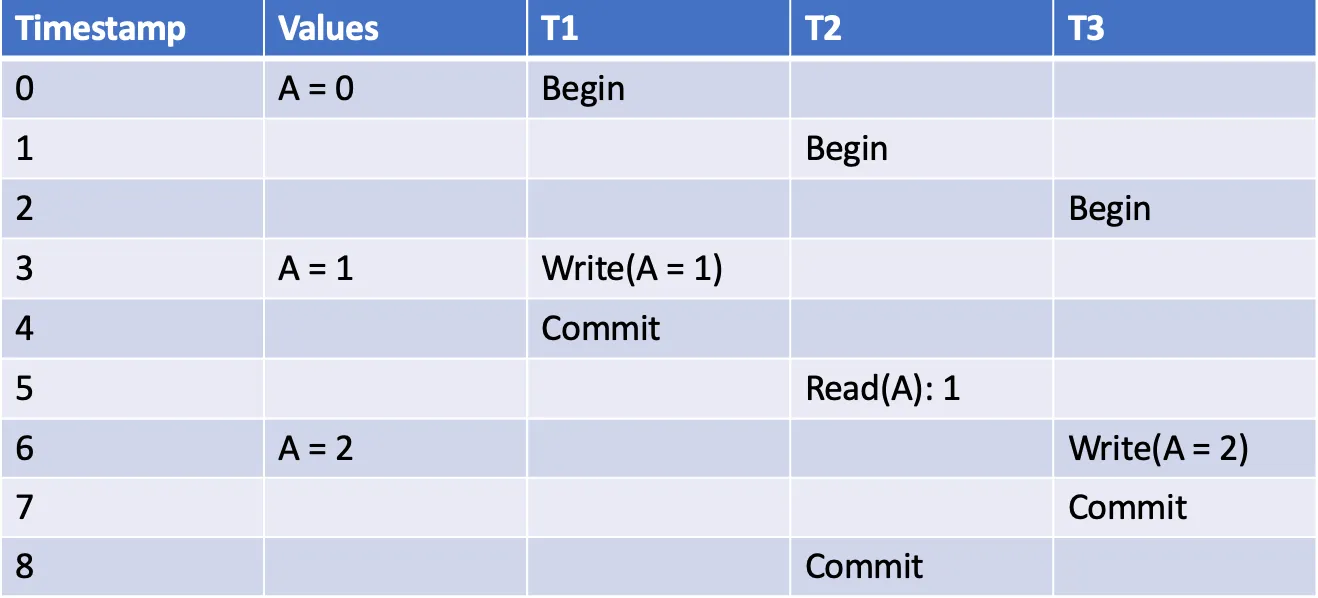
在这里,T1 <-w:r- T2,T2在T1之后执行,因此这是一个_正向_依赖关系。T2 <-r:w- T3,T3在T2执行前已经完成,因此这是一个_反向_依赖关系。
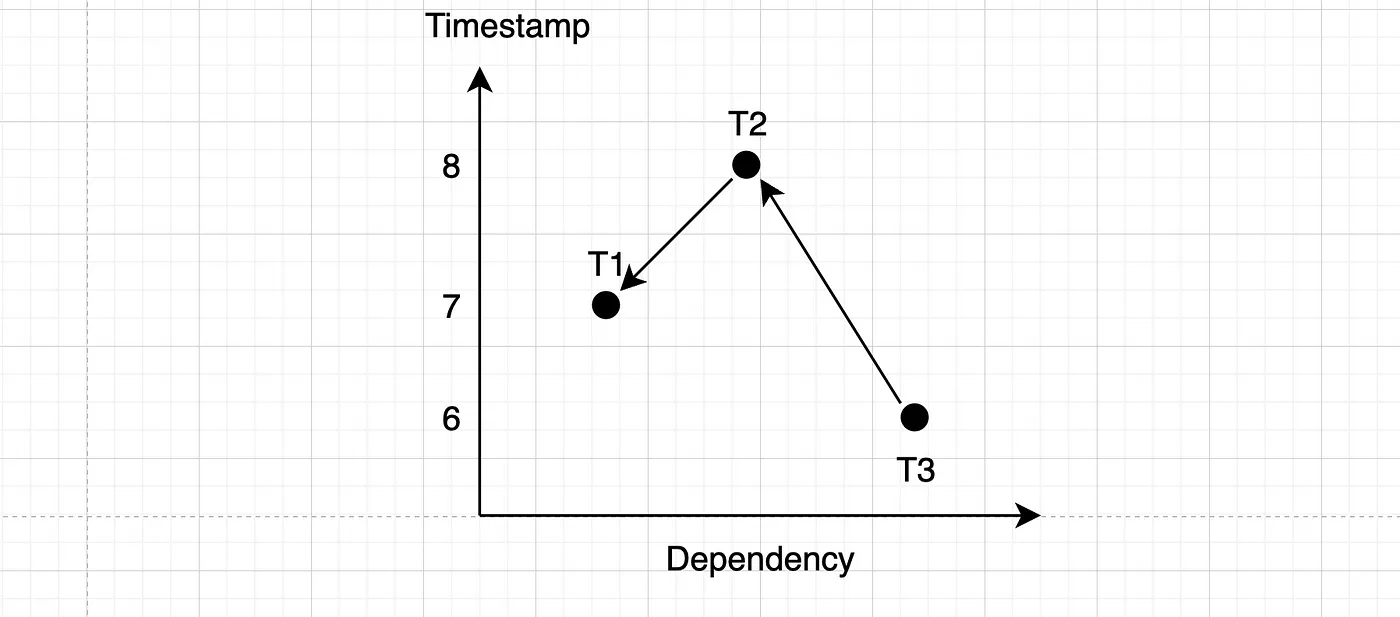
如下图所示,你可以表示这样的依赖关系,其中 x 轴表示依赖顺序,y 轴则表示时间戳的顺序。
终于到了论文的核心内容!该论文介绍了一种新的可串行化检测算法,称为可串行化安全网(Serializable Safety Net,SSN)。此算法必须在其他并发控制算法之上使用,例如读已提交(Read-Committed,RC)、带有锁定的读已提交(Read-Committed with Locking,RCL)或快照隔离(Snapshot-Isolation,SI)。通过在这些算法之上运行SSN,这样你就可以在并发性能上做一些妥协,从而实现可串行化的隔离级别,如图1所示:
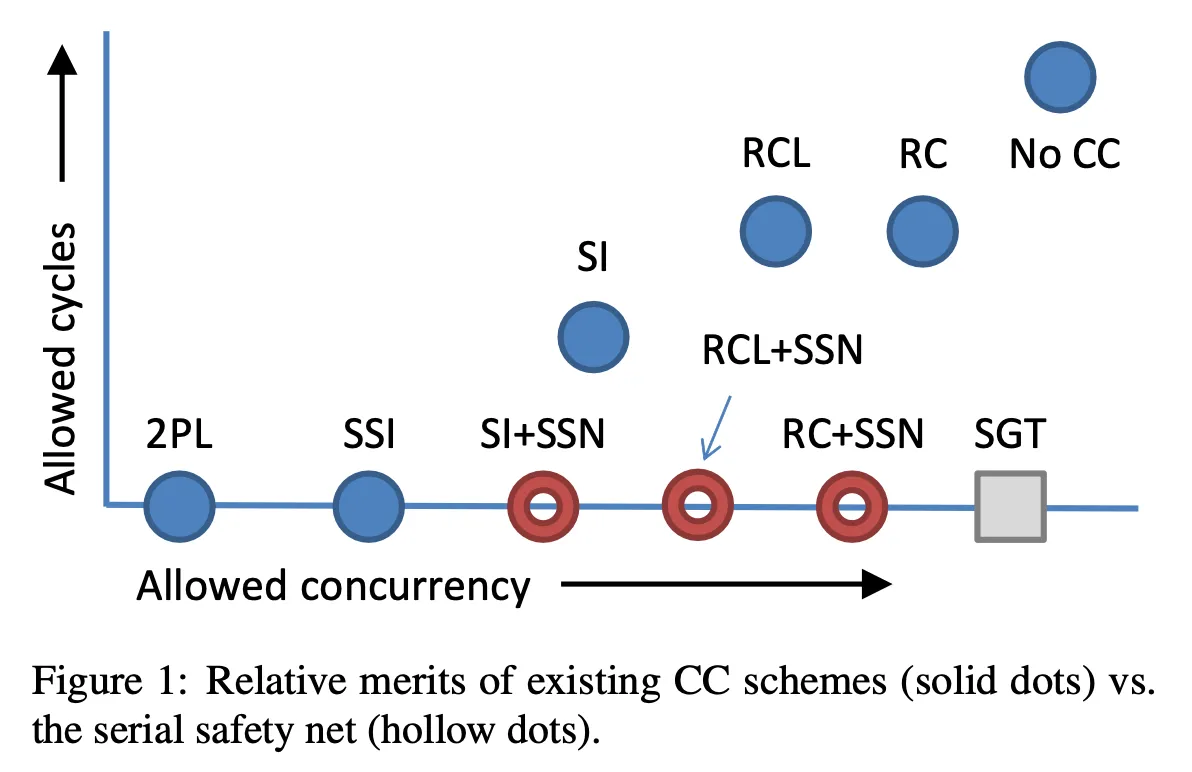
SSN(社会安全号)需要一个外部的并发控制算法来避免两种常见的并发问题,即脏读取和脏写入。
注:该论文反复提到“lost writes”。但我认为作者实际上指的是“脏写”而非“lost writes”。在经典的1995年论文《ANSI SQL隔离级别的批判》中,该论文正式定义了“脏写”,用来描述一个事务覆盖了另一个未提交事务写的情况。还有一个异常叫丢失更新,但描述的是不同的情况。本文将使用“脏写”这一术语。
脏读就是读取还未提交的值,比如:

T1 把 A 更新为 1,紧接着 T2 就读到了 “脏” 值 1,尽管 T1 还没提交。大多数数据库都支持 “读已提交” 的事务隔离级别,因此,脏读在这种情况下是不允许的。
阻止脏读后,T1 <-w:r- T2 依赖不能是反向的:这表明 T1 必须在 T2 之前已经提交。
同样,‘读已提交’(Read Committed)(或更强的算法)也防止了‘脏写’:它们不允许写入未提交的值,例如,写入一个还未在事务中提交的值。
这防止了向后的_w:w_依赖关系,比如当_T1 <-w:w- T2_时,T1必须在T2之前提交完成。
因此,后向依赖也必须是一个读取反依赖(T1 <-r:w- T2)。换句话说,这是SSN所依赖的核心属性。
最古老的后续者 π(T) 和 最新的前驱 η(T)这篇论文用正式的数学术语定义了某个交易 T 的 π(T)(读作 pi of T)和 η(T)(读作 eta of T)。我将跳过数学部分,用更直观的方式来解释它们。
一个事务可能有多个前驱和后继,每个也可能有传递性的后继。对于一个事务 T,π(T) 表示其最老的传递性反向读依赖(r:w)前驱的提交时间。例如,我们可以看到:
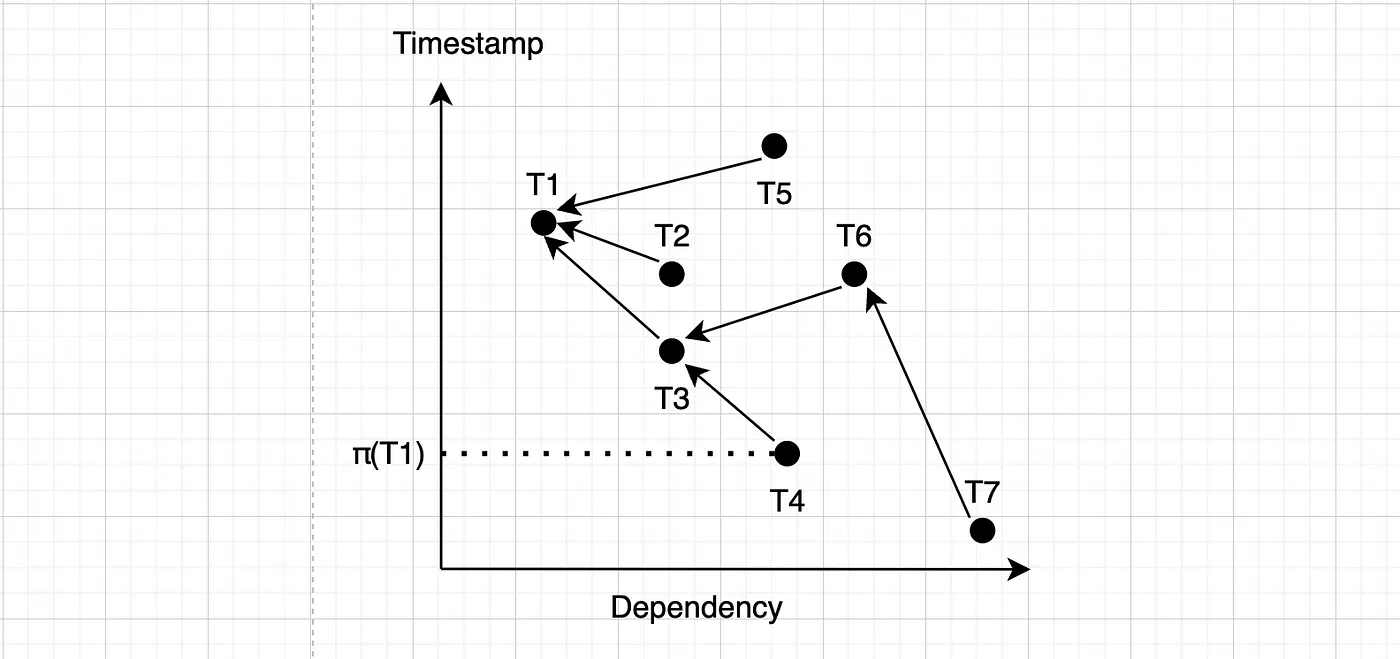
在这里,事务T1有两个_反向_读写后续事务T2和T3。T3还有一个反向依赖T4。π(T1)等于T1的最老传递反向后续事务T4的提交时间。T5是一个正向后续事务,所以它不计入。T6是T3的一个正向后续事务,我们也不需要关心T6及其传递后续事务。如果一个事务没有反向后续事务,例如T2,那么π(T2)也与T2的提交时间相同。
η(T) 表示 T 的最新 向前 前驱节点的提交时间。比如说:
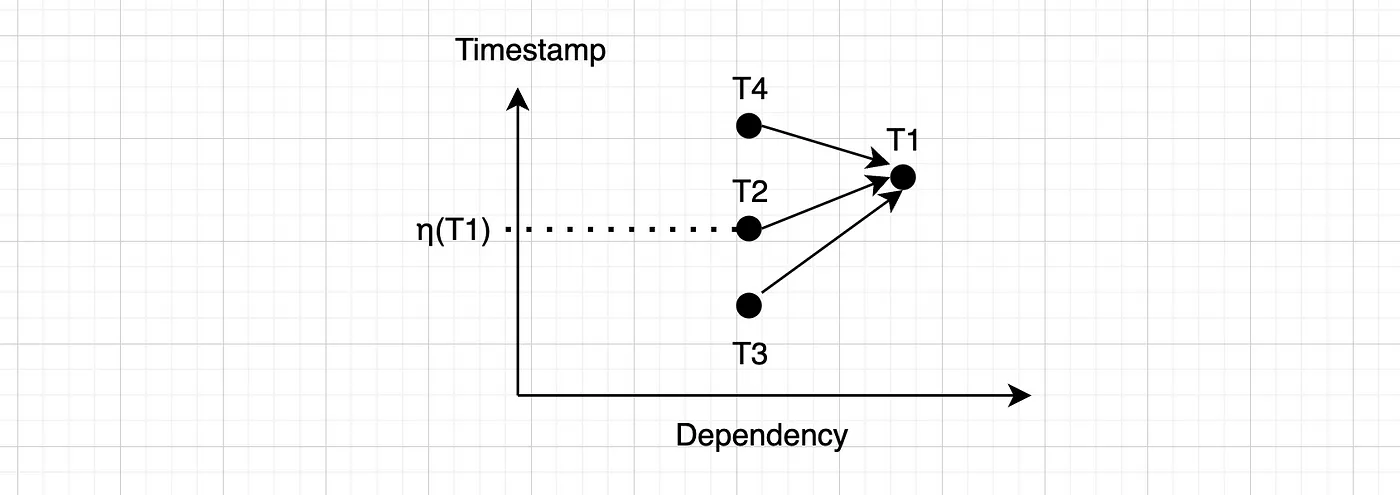
T1 有 3 个 前驱任务,分别是 T2、T3 和 T4。η(T1) 和 T2 的 提交时刻 一致。T4 是 后向任务,因此不予计算。
如果一个交易记录没有前置交易,则 η(T) == −∞。
SSN验证很简单:如果η(T) ≥ π(T),事务T必须终止,因为存在串行化违规的可能。我们试着可视化一下。
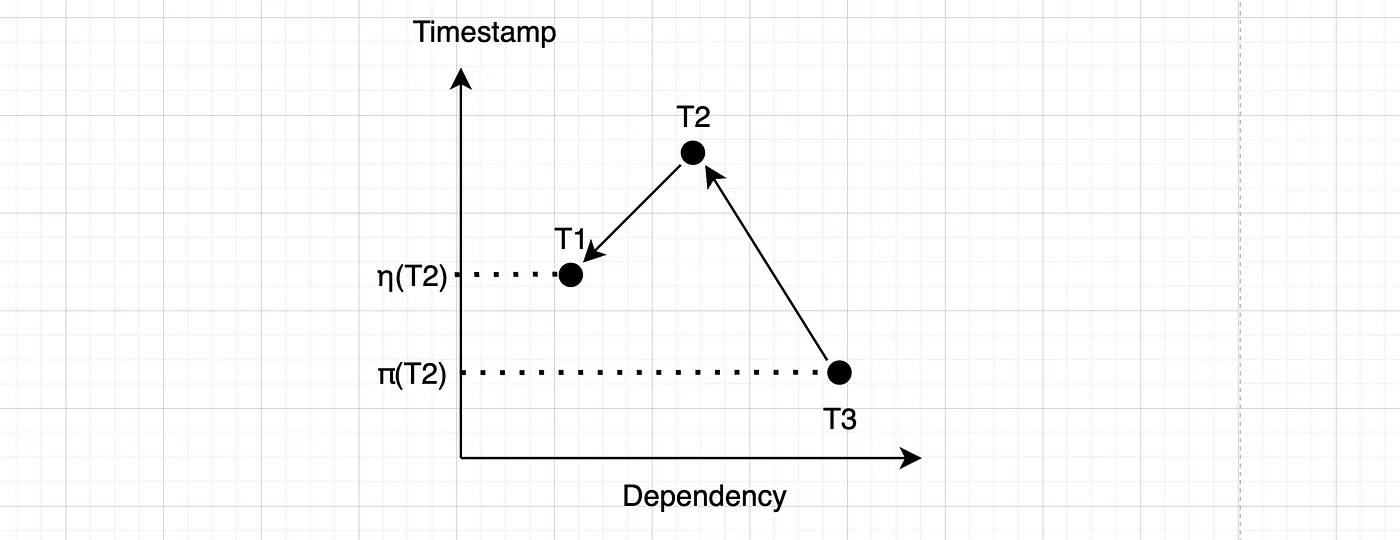
如果算法检测到如上所示的“峰值”交易 T2,其中最新的向前前置交易 T1 比最旧的向后(传递性)后继交易 T3 更新或相同。这种情况被称为“危险结构”,因为它可能,存在误报的可能性,T1 也可能成为 T3 的向前后继交易,从而形成依赖循环。
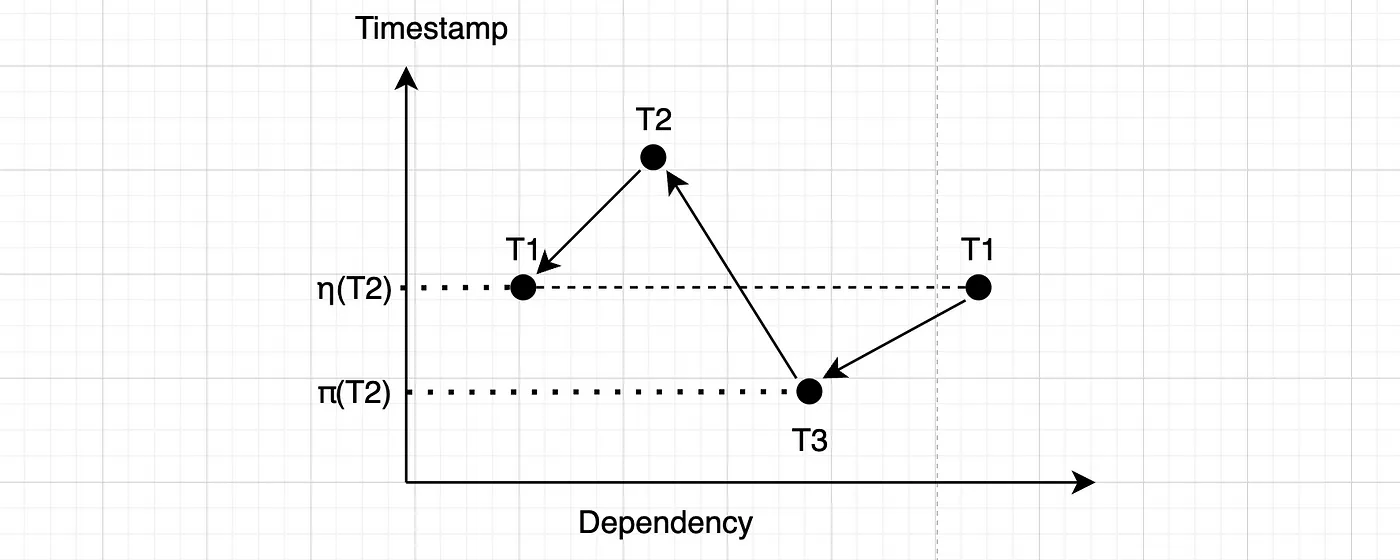
根据SSN算法,由于 η(T2) ≥ π(T2) ,因此SSN将其视为违规,并且T2必须终止。
我们来看一个具体的实例:
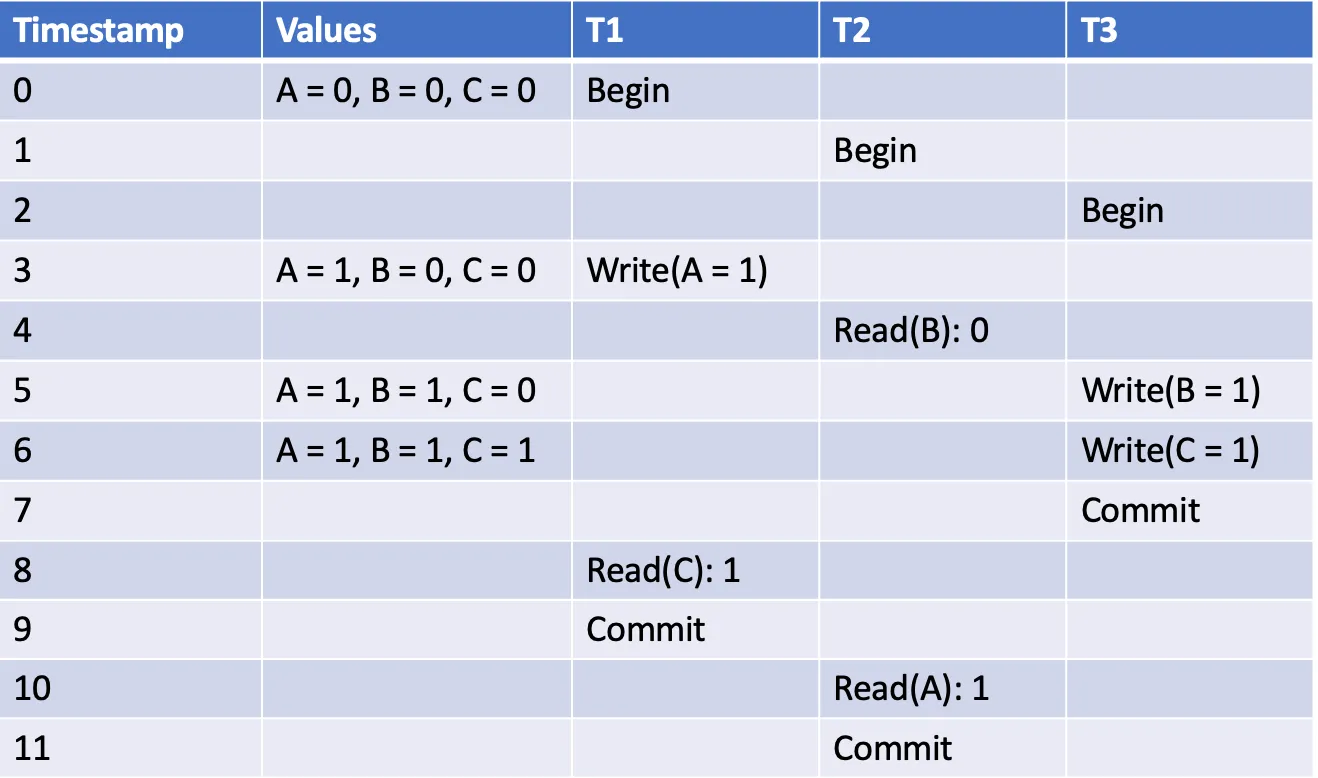
在 A 中,T1 <-w:r- T2,这是一个前向依赖关系,因为 T1 首先提交。T2 <-r:w- T3,由于 B,这是一个后向依赖,因为 T3 在 T2 之前提交。T3 <-w:r- T1,由于原因 C,这是一个前向依赖关系。依赖图如下:
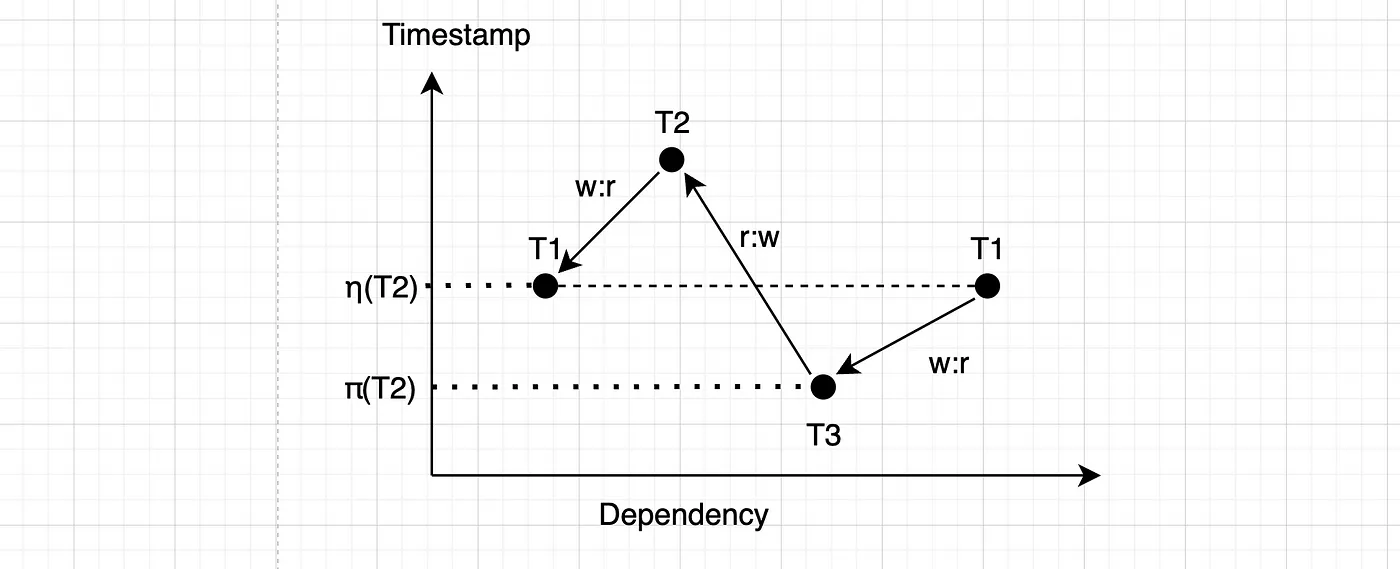
看一个更简单的例子,比如 T1 和 T2 互相依赖:
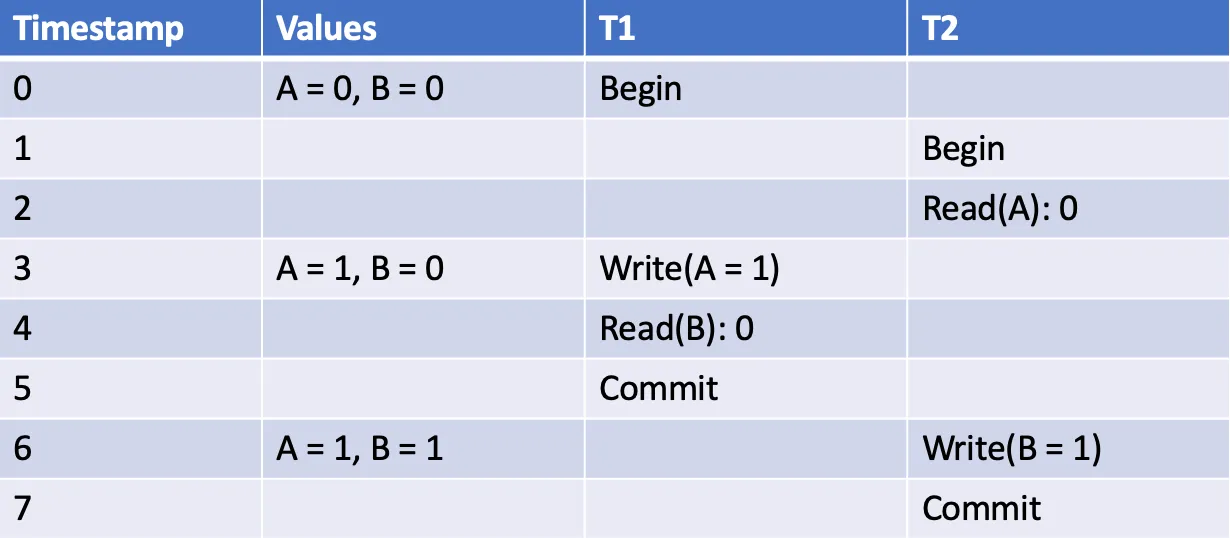
相应的依赖关系图如下。
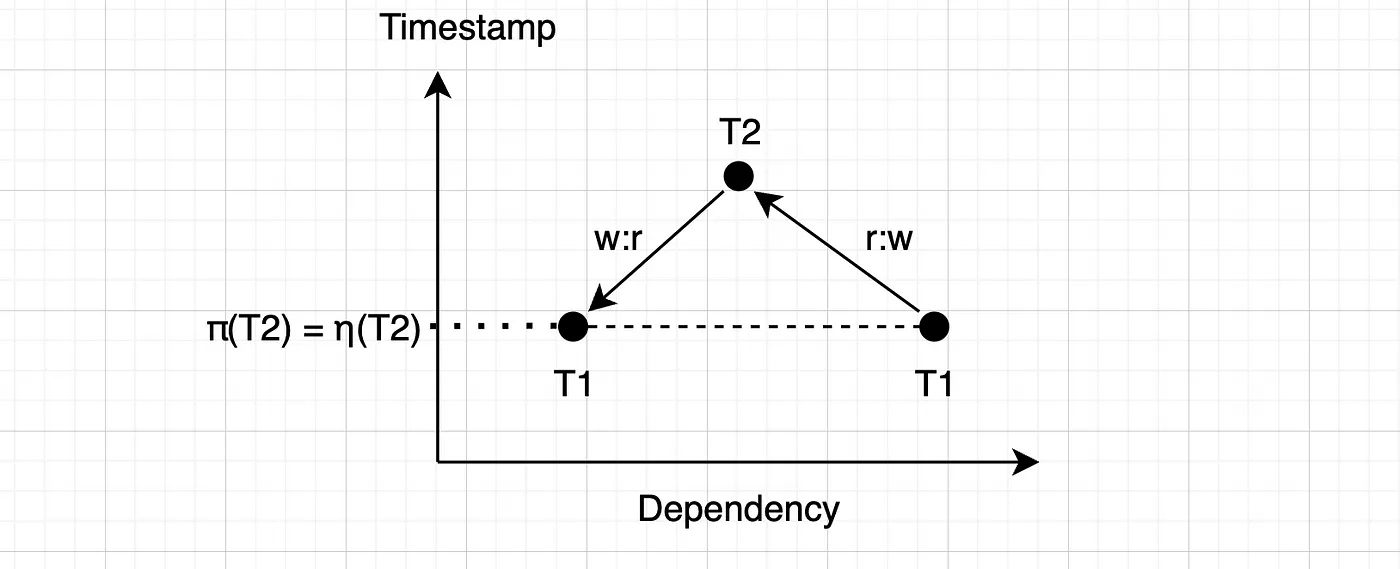
再次,因为 η(T2) ≥ π(T2) ,所以 SSN 检测到此违规,T2 必须终止运行。
好的,但是关于 (\eta(T2) < \pi(T2)) 这种情况呢?为什么不能违反这种情况呢?让我们来看看下面的例子:
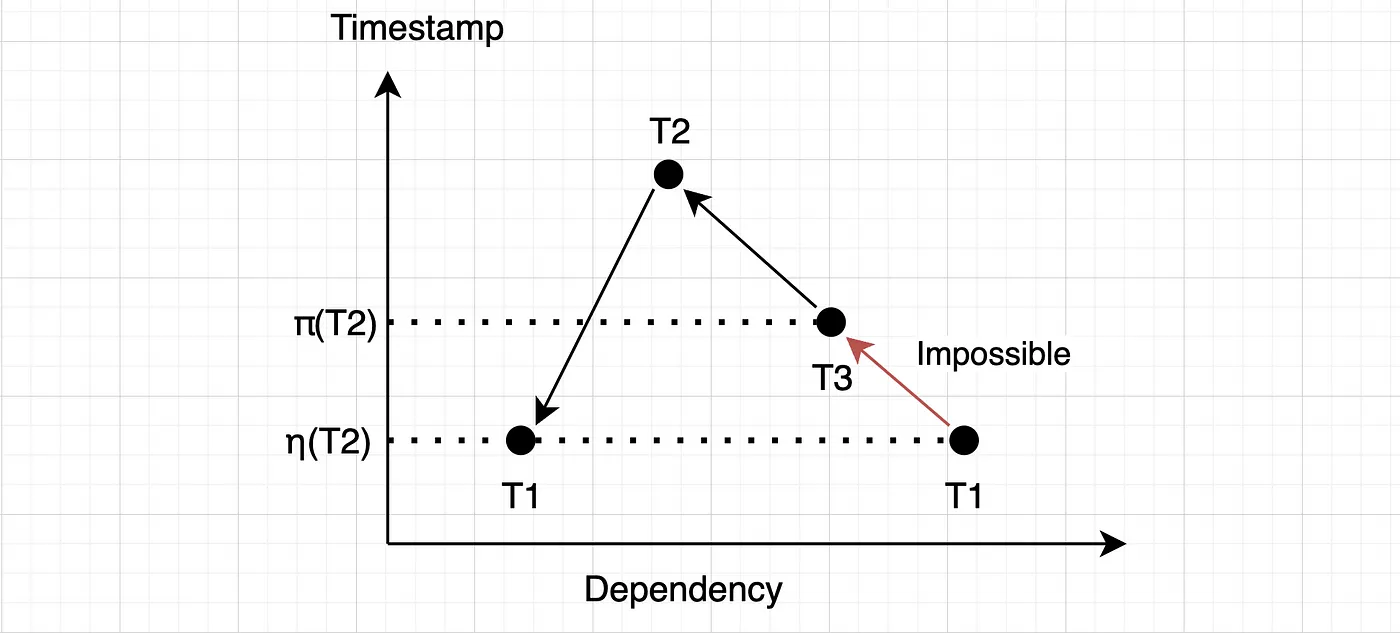
在这种情况下,T1 比 T3 更早提交。T1 不能同时作为 T3 的依赖,因为正如我们之前提到的,它必须是一个读取反依赖关系(r:w,由底层并发控制算法保证)。根据定义,如果这种反向依赖关系确实存在,那么 π(T2) 应该更新为 T1 的提交时间,而不是 T3,这与我们最初的假设 η(T2) < π(T2) 是矛盾的。
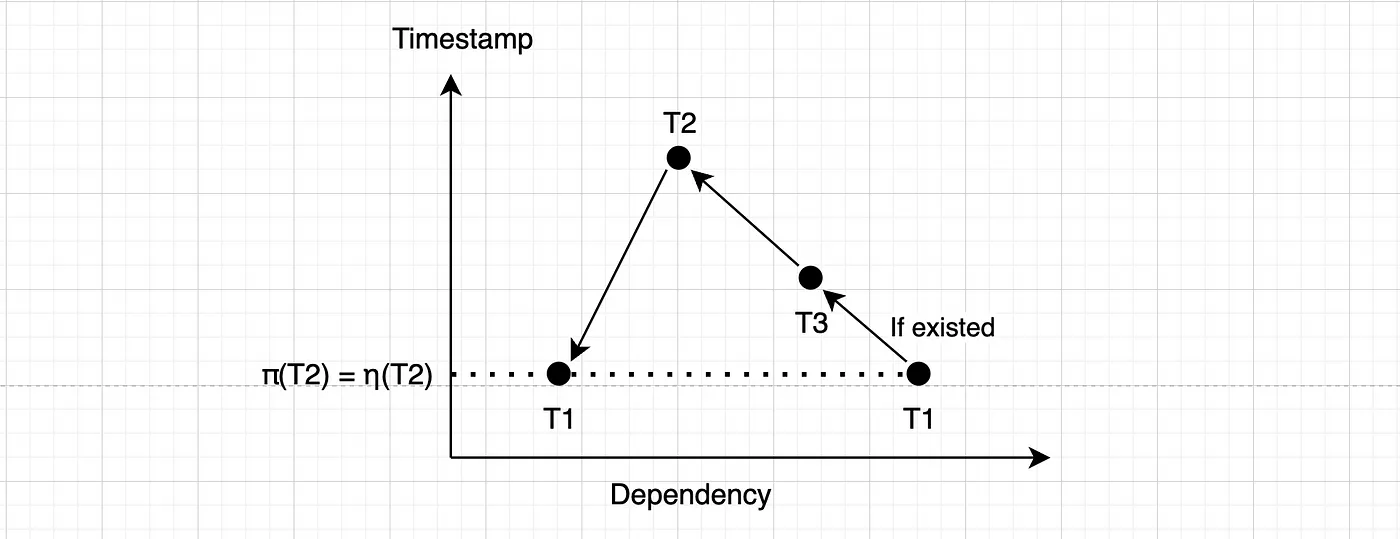
那这样不会形成循环吗?
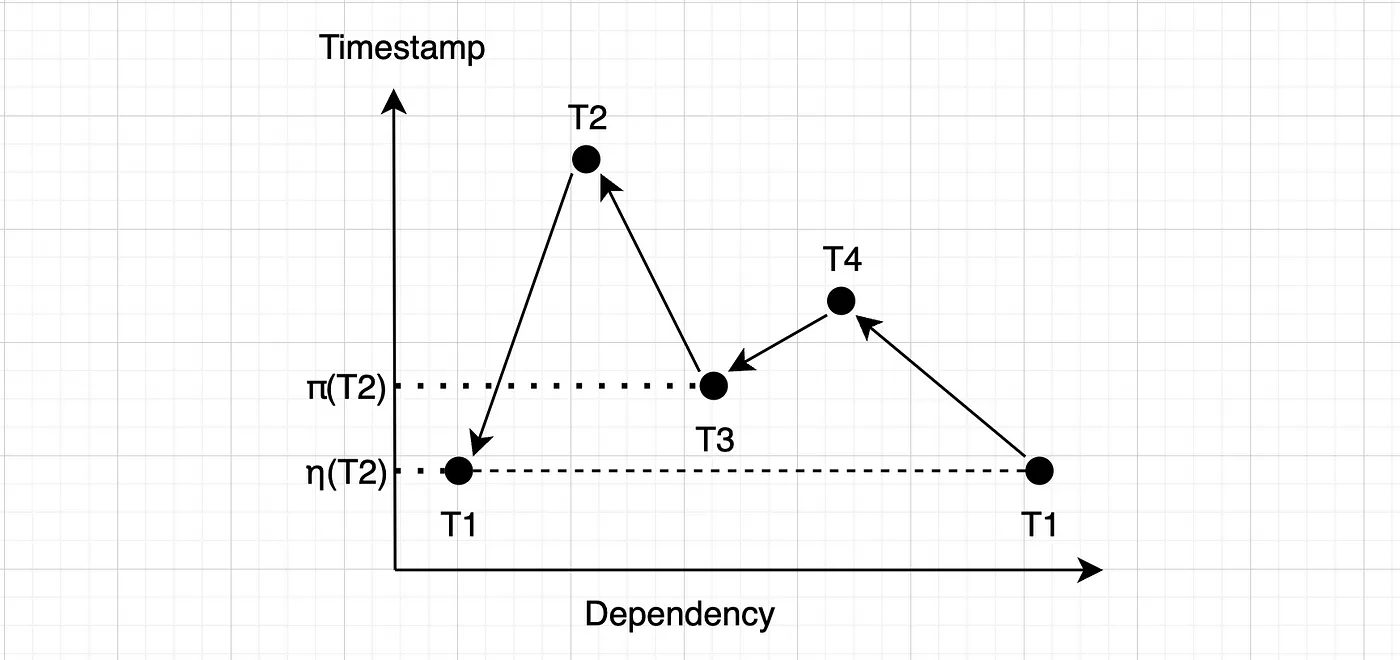
是的,但看一下T4:显然η(T4) ≥ π(T4),因此T4会被更早地终止,这样循环就会被打断。当轮到T2被认证时,就可以提交了。
如果 T2 在 T4 之前完成,其他情况也一样:
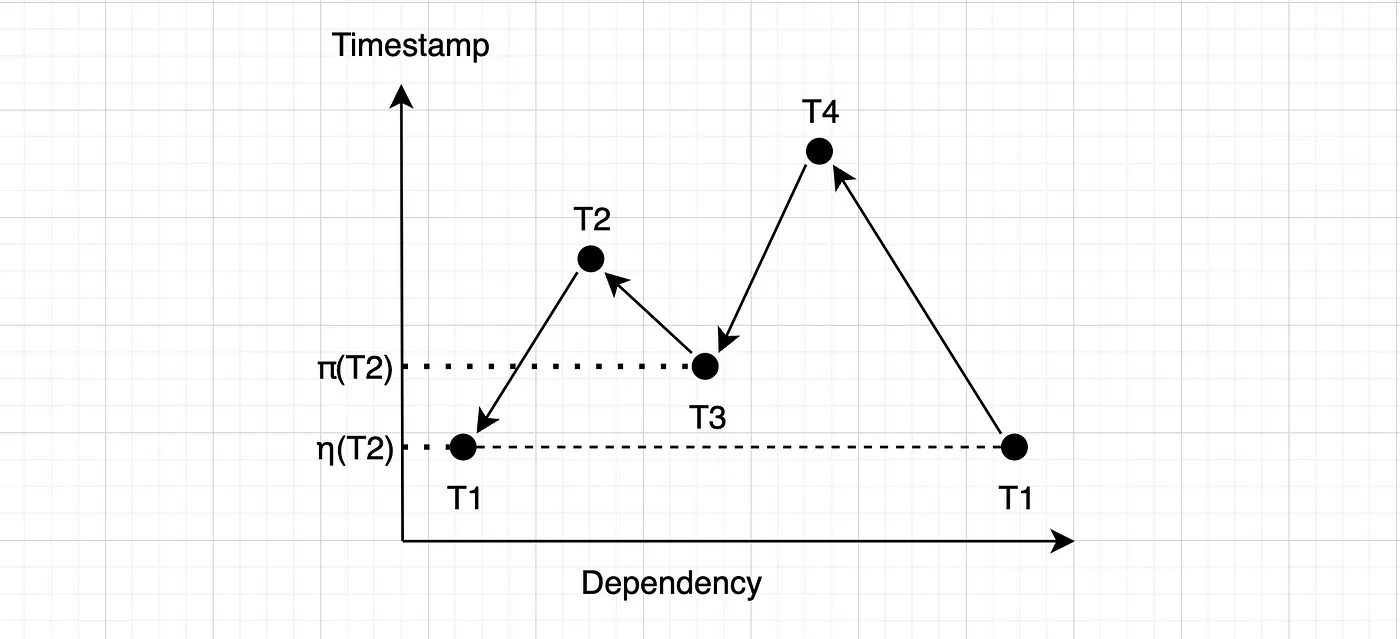
T2将首先执行,然后T4将取消,从而终止循环。
实施步骤论文的4.1节提供了SSN的一种可能实现。每个事务都维护其提交时间的内存记录,以及显然的 η(T) 和 π(T)。此外,SSN在每个数据库记录中跟踪4个值(见表1中的说明)。

v.cstamp是版本v的提交时间戳。v.pstamp是版本的最新访问时间戳:版本首次写入时(即v.cstamp),或最后一次读取时。v.sstamp是记录版本被新版本覆盖时的时间戳。v.prev是指向记录版本之前版本的指针。
如果事务 T 读取了记录 v,在 T 提交时,它需要更新 v.pstamp。同样,在覆盖版本 v 的情况下,在 T 提交时,它会更新旧版本的 v.sstamp,并为新版本设置 v.cstamp、v.pstamp 和 v.prev。
这些记录版本的元数据也会反过来更新事务 T 的 η(T) 和 π(T) 参数:当事务 T 读取一个记录时,它会创建一个潜在的 w:r 或 r:w 依赖,从而通过 v.cstamp 更新 η(T) 参数,如果适用,还会通过 v.sstamp 更新 π(T) 参数。
同样,当一个事务 T 覆盖一条记录时,它会创建潜在的 r:w 或 w:w 依赖关系,因此需要根据被覆盖记录的 v.pstamp 更新其自身的 η(T)(算法 2,第 11 行)。无需更新 π(T),因为当 T 写入数据时,其可能的后续者仅是 w:w 和 w:r,而 π(T) 只关心 r:w 的反向依赖。
第4.2节介绍了一种更复杂的无锁SSN的实现方式,我没有深入研究这一部分。
我的一些想法首先,你必须理解它如何提供了一个潜在的工具,用于为现有的数据库系统添加可序列化的隔离级别,特别是当这些系统仅支持一些基本的隔离级别,如读已提交的或快照隔离时。
SSN的另一个好处是它相对便宜地进行追踪。你不需要跟踪所有交易及其依赖关系,只需关注每个交易和每个记录的时间戳,这样会更自然流畅。每个交易只需要两个时间戳,每个记录只需要四个时间戳,这大大减少了开销。(如果你感兴趣,第5.2节还提供了一些针对读取集特别大的交易的优化建议。)
Redshift 中的应用我在我阅读另一篇论文时,最初发现了这篇论文:Amazon Redshift 重新发明(Nikos Armenatzoglou 等,SIGMOD 22)

这是一个很好的现实世界案例,展示了SSN的两个优点:可以在现有数据库之上轻松实现SSN,以添加可串行化支持,而且它的性能更优越。
声明所有观点均为个人观点,这篇文章完全基于公开资料,而非我所在公司的内部信息。
这周我将离开亚马逊RDS(在那里工作了5年!)并加入Redshift团队。对我来说,现在正好写点关于Redshift和分布式系统的内容,真是好时机!
你可以在这里下载并编辑我的图:https://tinyurl.com/4p5h9euc




