
接下来,我们将使用Terraform为您的EKS控制平面节点使用CloudWatch进行监控和警报设置。我们将重点关注ETCD和APIserver实例。
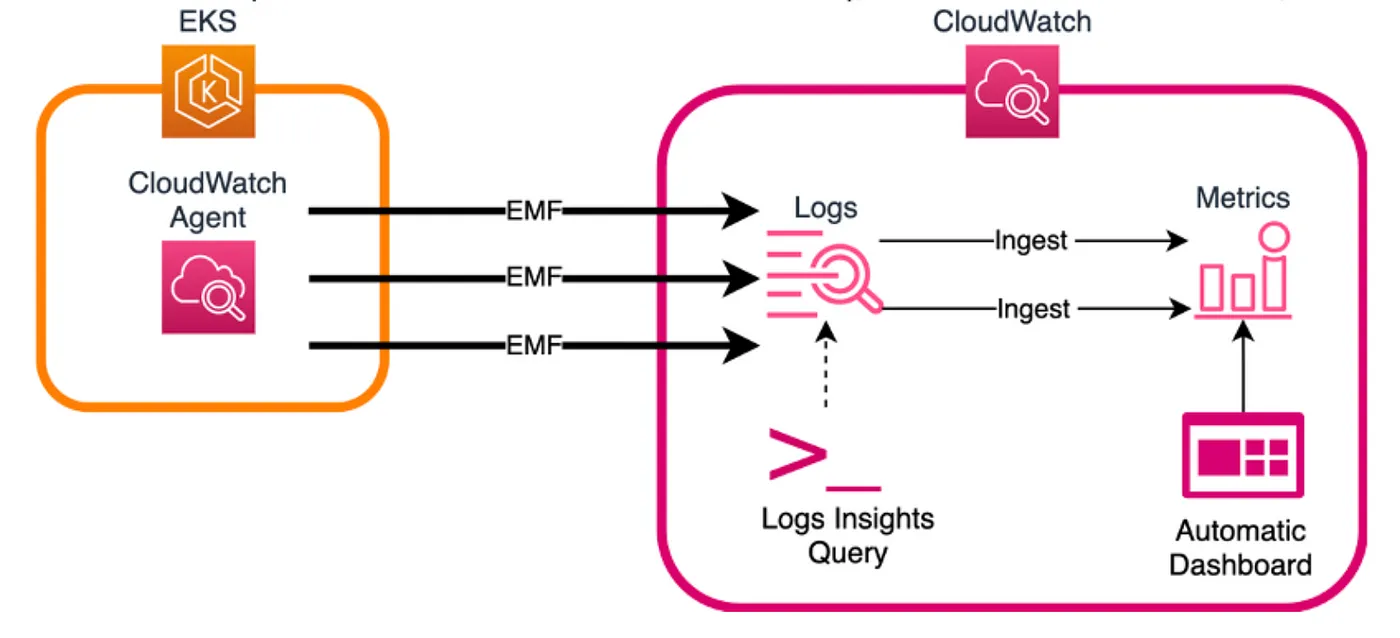
在这个故事中,我将介绍如何使用 Terraform 轻松实现 K8s 控制平面的重要指标的监控和告警。直到最近,我还以为控制平面会有很好的覆盖,然而,最近在我遇到我的生产 EKS 集群完全锁死的情况后,这改变了我的想法,这是由于 ETCD 数据库已满并导致锁死。关于这次事故的更多细节,可以在我的另一篇文章中找到。了解更多 -> Amazon EKS- 管理和修复 ETCD 数据库大小
常用工具和应用
- Amazon EKS 1.30
- Terraform 1.6
- Terraform aws provider 5.54.0
- EKS 容器洞察功能(通过 EKS 插件部署/启用)
- CloudWatch 日志、指标、警报及仪表盘
- SNS 与 SQS
我正在使用 Amazon CloudWatch Observability EKS 插件功能来为 Amazon EKS 启用 Container Insights 的增强观测功能。这使我们能够从 Amazon EKS 集群收集基础设施指标、应用程序性能数据和容器日志。
locals {
amazon_cloudwatch_observability_config = file("${path.module}/configs/amazon-cloudwatch-observability.json")
}
resource "aws_eks_addon" "amazon_cloudwatch_observability" {
cluster_name = aws_eks_cluster.cluster.name
addon_name = "amazon-cloudwatch-observability"
addon_version = "v1.7.0-eksbuild.1"
# 配置值从本地变量amazon_cloudwatch_observability_config中获取
configuration_values = local.amazon_cloudwatch_observability_config
} #amazon-cloudwatch-observability.json
{
"agent": {
"config": {
"logs": {
"metrics_collected": {
"kubernetes": {
"enhanced_container_insights": true
}
}
}
}
},
"containerLogs": {
"enabled": false
}
}如你所见,我开启了enhanced_container_insights,因为这些指标包含了我想要的控制平面度量。你也注意到我关闭了containerLogs,因为我使用的是其他的集中式日志解决方案。如果你想开启容器日志,确保你有足够的预算来承担这个费用,我觉得这非常贵。
一旦完成上述部署,你将能够看到集群的容器洞察仪表盘,仪表盘将如下图所示:
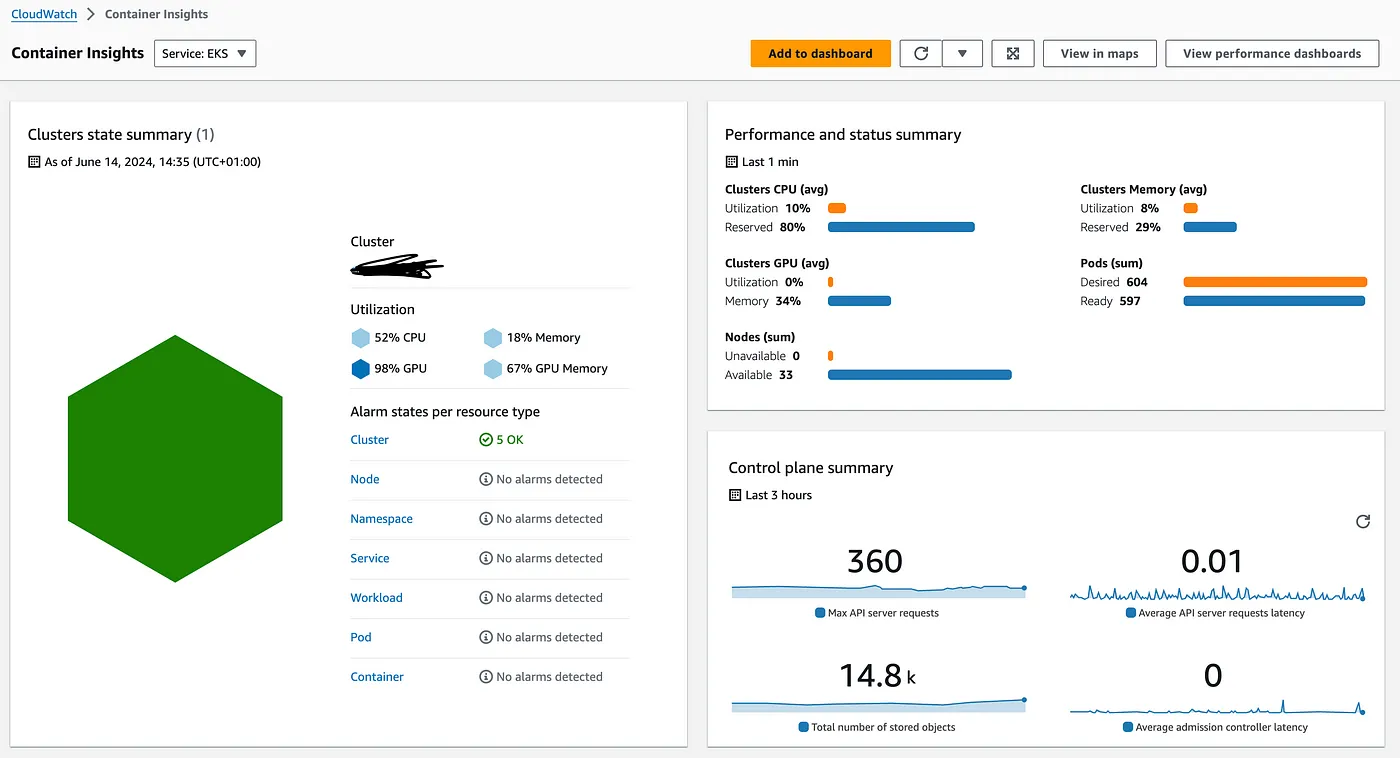
如你所见,这里有关于你的控制节点以及工作节点的数据,它们是EKS集群的一部分。进入性能仪表盘,可以查看更多信息。
EKS 控制面板为了控制层面的度量,我创建了自己的仪表板,因为AWS提供的那些已经过时,并且使用了不准确的度量。下面我来展示给你看四个我感兴趣的图表。
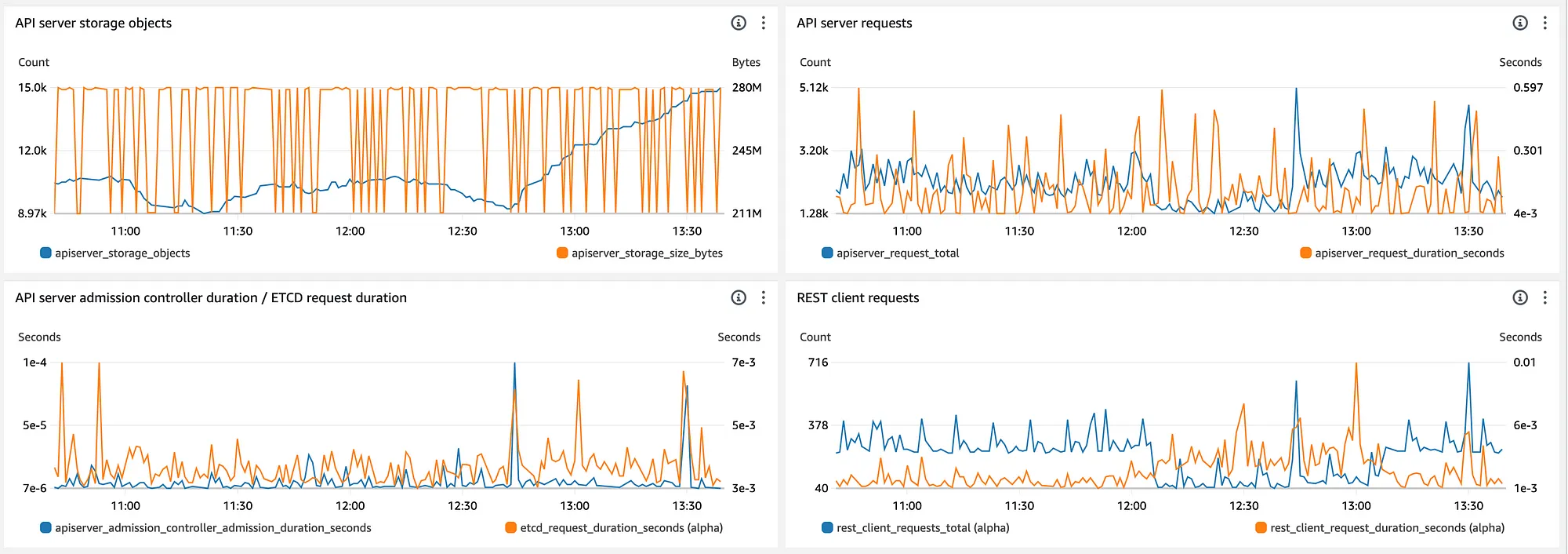
如果你想快速部署它们的话,这里有一段代码,你可以导入。记得把你的ACCOUNT_ID的值和CLUSTER_NAME的值替换掉。
{
"widgets": [
{
"height": 6,
"width": 12,
"y": 0,
"x": 12,
"type": "metric",
"properties": {
"region": "eu-west-2",
"title": "API 服务器的请求",
"legend": {
"position": "底"
},
"timezone": "LOCAL",
"metrics": [
[ "ContainerInsights", "apiserver_request_total", "ClusterName", "CLUSTER_NAME", { "id": "mm1m0", "stat": "Sum", "yAxis": "left", "accountId": "ACCOUNT_ID" } ],
[ ".", "apiserver_request_duration_seconds", ".", ".", { "id": "mm2m0", "stat": "Average", "yAxis": "right", "accountId": "ACCOUNT_ID" } ]
],
"liveData": false,
"period": 60,
"yAxis": {
"left": {
"label": "计数",
"showUnits": false
},
"right": {
"label": "秒",
"showUnits": false
}
}
}
},
{
"height": 6,
"width": 12,
"y": 6,
"x": 0,
"type": "metric",
"properties": {
"region": "eu-west-2",
"title": "API 服务器准入控制器持续时间和 ETCD 请求持续时间",
"legend": {
"position": "底"
},
"timezone": "LOCAL",
"metrics": [
[ "ContainerInsights", "apiserver_admission_controller_admission_duration_seconds", "ClusterName", "CLUSTER_NAME", { "id": "mm1m0", "stat": "Average", "yAxis": "left", "accountId": "ACCOUNT_ID" } ],
[ ".", "etcd_request_duration_seconds", ".", ".", { "id": "mm2m0", "label": "etcd 请求持续时间 (alpha)", "stat": "Average", "yAxis": "right", "accountId": "ACCOUNT_ID" } ]
],
"liveData": false,
"period": 60,
"yAxis": {
"left": {
"label": "秒",
"showUnits": false
},
"right": {
"label": "秒",
"showUnits": false
}
}
}
},
{
"height": 6,
"width": 12,
"y": 0,
"x": 0,
"type": "metric",
"properties": {
"metrics": [
[ "ContainerInsights", "apiserver_storage_objects", "ClusterName", "CLUSTER_NAME", { "id": "mm1m0", "stat": "Maximum", "yAxis": "left", "accountId": "ACCOUNT_ID", "region": "eu-west-2" } ],
[ "ContainerInsights", "apiserver_storage_size_bytes", "ClusterName", "CLUSTER_NAME", { "id": "mm2m0", "stat": "Maximum", "yAxis": "right", "accountId": "ACCOUNT_ID", "region": "eu-west-2" } ]
],
"region": "eu-west-2",
"title": "API 服务器的存储对象",
"legend": {
"position": "底"
},
"timezone": "LOCAL",
"liveData": false,
"period": 60,
"yAxis": {
"left": {
"label": "计数",
"showUnits": false
},
"right": {
"label": "字节",
"showUnits": false
}
},
"view": "timeSeries",
"stacked": false
}
},
{
"height": 6,
"width": 12,
"y": 6,
"x": 12,
"type": "metric",
"properties": {
"region": "eu-west-2",
"title": "REST 客户端的请求",
"legend": {
"position": "底"
},
"timezone": "LOCAL",
"metrics": [
[ "ContainerInsights", "rest_client_requests_total", "ClusterName", "CLUSTER_NAME", { "id": "mm1m0", "label": "REST 客户端请求总数 (alpha)", "stat": "Sum", "yAxis": "left", "accountId": "ACCOUNT_ID" } ],
[ "ContainerInsights", "rest_client_request_duration_seconds", "ClusterName", "CLUSTER_NAME", { "id": "mm2m0", "label": "REST 客户端请求持续时间 (alpha)", "stat": "Average", "yAxis": "right", "accountId": "ACCOUNT_ID" } ]
],
"liveData": false,
"period": 60,
"yAxis": {
"left": {
"label": "计数",
"showUnits": false
},
"right": {
"label": "秒",
"showUnits": false
}
},
"view": "timeSeries",
"stacked": false
}
}
]
}在这里你会看到用Terraform实现的Cloudwatch警报及邮件通知的完整方案。我重点关注了以下指标值的警报设置。
- apiserver存储大小(字节)
- apiserver存储对象
- apiserver请求持续时间(秒)
- REST客户端请求持续时间(秒)
- etcd请求持续时间(秒)
locals {
eks_cluster_name = "YOUR CLUSTER_NAME"
}
resource "aws_cloudwatch_metric_alarm" "eks_apiserver_storage_size_bytes" {
alarm_name = "eks-${local.eks_cluster_name}-apiserver-storage-size-bytes"
comparison_operator = "GreaterThanOrEqualToThreshold"
period = "300"
evaluation_periods = "5"
threshold = "6000000000" # 6GB (最大为8GB)
alarm_description = "检测 ${local.eks_cluster_name} 集群中 ETCD 存储使用量达到 75% 以上的情况。"
alarm_actions = [aws_sns_topic.eks_alerts.arn]
statistic = "Maximum"
namespace = "ContainerInsights"
metric_name = "apiserver_storage_size_bytes"
dimensions = {
ClusterName = local.eks_cluster_name
}
}
resource "aws_cloudwatch_metric_alarm" "eks_apiserver_storage_objects" {
alarm_name = "eks-${local.eks_cluster_name}-apiserver-storage-objects"
comparison_operator = "GreaterThanOrEqualToThreshold"
period = "300"
evaluation_periods = "5"
threshold = "100000"
alarm_description = "检测 ${local.eks_cluster_name} 集群中 ETCD 存储对象达到 100000 个及以上的情况。"
alarm_actions = [aws_sns_topic.eks_alerts.arn]
statistic = "Maximum"
namespace = "ContainerInsights"
metric_name = "apiserver_storage_objects"
dimensions = {
ClusterName = local.eks_cluster_name
}
}
resource "aws_cloudwatch_metric_alarm" "eks_apiserver_request_duration_seconds" {
alarm_name = "eks-${local.eks_cluster_name}-apiserver-request-duration-seconds"
comparison_operator = "GreaterThanOrEqualToThreshold"
period = "300"
evaluation_periods = "5"
threshold = "1"
alarm_description = "API 服务器请求时长超过 1 秒,在 ${local.eks_cluster_name} 集群中。"
alarm_actions = [aws_sns_topic.eks_alerts.arn]
statistic = "Average"
namespace = "ContainerInsights"
metric_name = "apiserver_request_duration_seconds"
dimensions = {
ClusterName = local.eks_cluster_name
}
}
resource "aws_cloudwatch_metric_alarm" "eks_rest_client_request_duration_seconds" {
alarm_name = "eks-${local.eks_cluster_name}-rest-client-request-duration-seconds"
comparison_operator = "GreaterThanOrEqualToThreshold"
period = "300"
evaluation_periods = "5"
threshold = "1"
alarm_description = "REST 客户端请求时长超过 1 秒,在 ${local.eks_cluster_name} 集群中。"
alarm_actions = [aws_sns_topic.eks_alerts.arn]
statistic = "Average"
namespace = "ContainerInsights"
metric_name = "rest_client_request_duration_seconds"
dimensions = {
ClusterName = local.eks_cluster_name
}
}
resource "aws_cloudwatch_metric_alarm" "eks_etcd_request_duration_seconds" {
alarm_name = "eks-${local.eks_cluster_name}-etcd-request-duration-seconds"
comparison_operator = "GreaterThanOrEqualToThreshold"
period = "300"
evaluation_periods = "5"
threshold = "1"
alarm_description = "ETCD 请求时长超过 1 秒,在 ${local.eks_cluster_name} 集群中。"
alarm_actions = [aws_sns_topic.eks_alerts.arn]
statistic = "Average"
namespace = "ContainerInsights"
metric_name = "etcd_request_duration_seconds"
dimensions = {
ClusterName = local.eks_cluster_name
}
}
resource "aws_sns_topic" "eks_alerts" {
name = "eks-${local.eks_cluster_name}-alerts"
}
resource "aws_sns_topic_subscription" "email_eks_alerts" {
topic_arn = aws_sns_topic.eks_alerts.arn
protocol = "email"
endpoint = "eks_alerts@gmail.com"
}最终部署的状态应为如下所示,在 AWS 的控制台中。
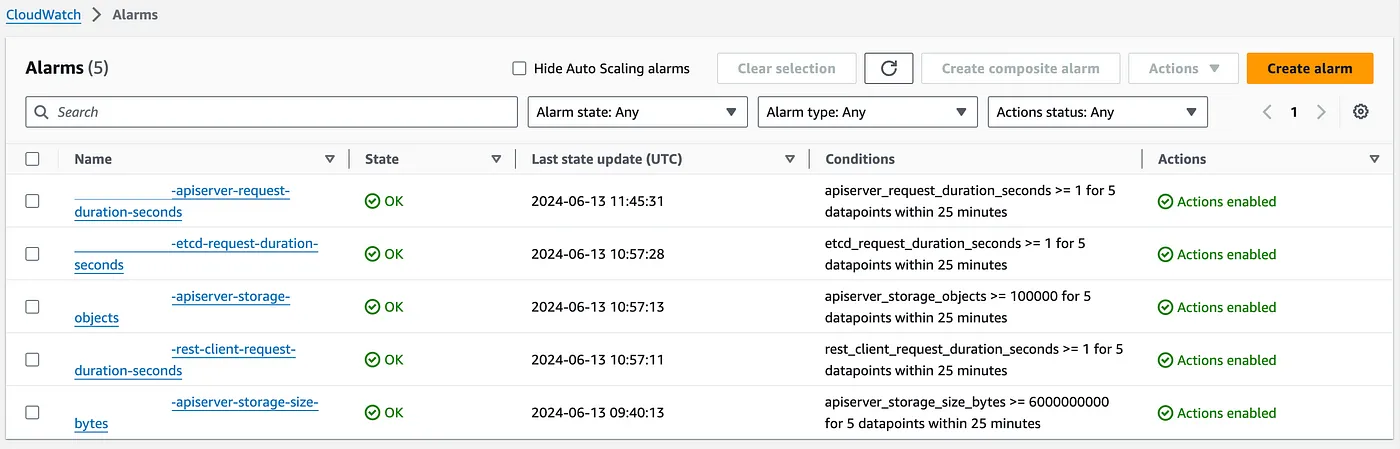
这完成了设置,希望你可以利用我的工作来加快你的进度。请监控你的 EKS 控制平面,并配置告警,因为它可能出现故障,如果不及时清理 ETCD,可能会导致很多问题。
赞助我 赞助 @marcincuber 在 GitHub SponsorsHi 大家好,我是 Marcin,我是一名专注于 DevOps 的资深工程师。我也是 AWS 认证解决方案架构师。和我在Medium上写的其他任何故事一样,我完成了文中记录的任务。这是我自己的研究过程中遇到的问题。
谢谢大家的阅读,Marcin Cuber。



