

在 Mercado Libre 平台上,管理 30,000 多个微服务并支持 16,000 多名开发者需要一个强大且具有可扩展性的解决方案。为应对这些挑战,我们采用了 Kubernetes(K8s)作为我们内部平台 Fury 的核心。本文将探讨 Kubernetes 如何简化我们的基础设施管理,加快软件交付,降低成本并提高效率,让我们的开发者能够专注于创新和产品开发。
愤怒结构
由于本文重点在于在Fury平台内实现Kubernetes,因此对Fury有一些基本的了解以便更好地理解本文内容是很重要的。我们建议先读一下这篇文章。
简而言之,Fury 是一个由云应用和服务组成的内部开发者平台(IDP)。它提供了网页界面和命令行界面(CLI),使开发人员能够创建和管理资源。此外,云和平台团队使用一个后台管理界面来管理和监控平台的运行及操作。
图片1:愤怒首页。
愤怒及其抽象
简单来说,Fury 是 Mercado Libre 内部开发的一个抽象层工具。它充当桥梁的作用,连接第三方服务(例如 Amazon Web Services (AWS)、Google Cloud Platform (GCP)、Datadog 等)和用户应用程序。无论使用哪个提供商或合作伙伴,开发者通常通过 [软件开发工具包 (SDKs)] 来与服务交互,而 Fury 的 API 直接与提供商通信。
这意味着应用程序不会直接与云服务进行通信。有一个反锁定层,防止被锁定,便于版本更新,并可在无需修改代码的情况下轻松切换到类似服务。这种抽象对于支持公司多云策略来说尤为重要,确保了灵活性和成本、安全的更好管理。

图像 2:Fury(一种工具或服务)在开发者的应用和像 AWS、GCP 等外部服务之间提供了一个抽象层。
开端:计算引擎
计算引擎是Fury的一个组件,负责管理用户的工作负载。当Fury在2015年创建时,Kubernetes当时还处于早期阶段,不够成熟,无法满足Mercado Libre所需的工作负载和技术需求。因此,选择从AWS EC2和Google Compute Engine这样的云提供商那里采用基于实例的计算服务是最自然的选项。
最初开发的计算模型被命名为_Standard_。它作为平台与云提供商之间的桥梁。该模型接收来自平台的命令,例如创建或扩展实例的数量,并在提供商端执行这些操作。
下面的简化图虽然代表了该模型,但其实它的复杂性要大得多得多。其中一个例子是称为 Little Monster (LM) 的组件,它是 Standard 模块中的一个组件,负责确保分布式事务的原子性。LM 会从云提供商处请求实例,并确保这些实例准备好使用,处理创建和初始化过程中的必要等待和资源池化。

图像3:如图所示,Fury的第一个模型是标准(Standard)。
如图所示,此模型已经在多个地区和云供应商上运行。自其诞生以来,它就是为了此目的而设计的,因此所有的自动扩展管理功能都是作为计算模块的一部分内部开发的,并未依赖 AWS 的自动扩展组(ASGs)或其他云供应商的类似功能。这一决策是为了创建一个多供应商解决方案的需求,从而证明开发此抽象层的必要性。
Standard 模块一直是Fury可靠的组成部分,多年来一直在顺利运行。它帮助Mercado Libre扩展业务并应对重大商业挑战。然而,经过一段时间后,它面临了两个需要解决的问题:
- 低效率:每个应用副本都需要一个计算实例,例如 EC2,导致一对一的对应关系。尽管我们采取了预留实例、竞价型实例、节省计划以及 Graviton ARM 实例等策略来降低成本,仍有改进的空间。
- 未能充分利用原生云提供商的资源:由于开发的抽象层,该模块未能充分利用原生云提供商的资源和功能,限制了其全部潜力的发挥。
替代学习

图4:替代方案的研究以取代Standard模型。
我们进行了一项广泛的研究,寻找更高效的解决方案,评估了各种技术和方法。最初,我们探索了 AWS Batch 以实现按需激活资源,但发现它无法完全满足我们的需求。我们也考虑了 AWS Lambda,但其长时间任务的限制使其不合适。我们还研究了基于容器的解决方案,如 ECS 和 Cloud Run,但由于其复杂性和缺乏必要的功能,我们最终排除了这些方案。经过对 Kubernetes(EKS 和 GKE)和 Nomad 的测试后,我们最终放弃了 Nomad,并决定采用 EKS 和 GKE 这些管理型 Kubernetes 解决方案,因为它们更好地满足了我们的需求。
这个评估及其发现将在以后的文章中进一步讨论。
当前的实现方式:采用EKS和GKE的计算服务功能。
经过数月的规划和开发,我们达到了当前的架构模型,命名为Serverless。与通常所说的无服务器计算(如Lambda函数)的概念不同,我们采用这个名字是为了展示开发者完全不需要直接了解和管理服务器——他们仅与Fury的抽象层交互,采取了无服务器的视角。平台则透明地管理资源,Serverless作为一个独特的区别点,体现了这种全自动化理念,从而促进采用这种模式。
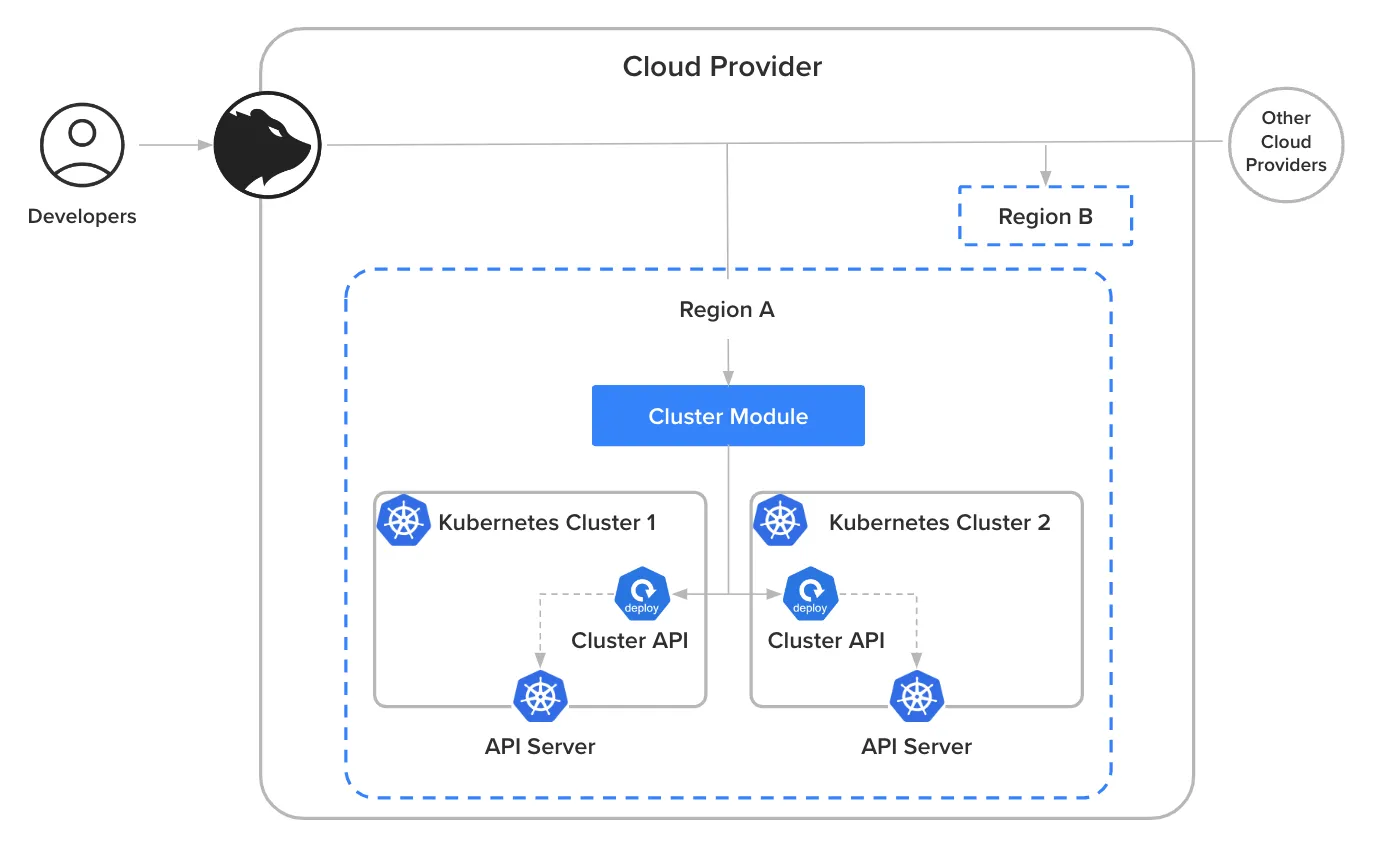
图 5:简化版的无服务器计算模型。
这一演进引入了无服务器模块,取代了旧的标准模块,同时保留了小怪兽(LM)组件,确保操作的原子性。最值得注意的是平台与云提供商之间的通信层发生了变化:新的计算模块与一个名为_集群API_的解决方案进行交互。请注意,这里的集群API与Kubernetes定义的集群API并不相同;在我们的上下文中,它抽象了Kubernetes控制平面,作为不同Kubernetes版本与计算模块之间的桥梁。
集群API(Cluster API):一个高效的抽象接口
Cluster API 是为了应对管理多个同时运行的 Kubernetes 版本日益增加的复杂性而开发的,并能有效处理常被弃用的 API。此组件旨在尽量减少这些变化对计算模块的影响,将 Kubernetes 版本的生命周期管理完全交给 Cluster API。这种方法还允许我们在必要时,用最小的迁移工作量将 Kubernetes 替换为另一个调度器。
无服务器功能模块:控制和可扩展性(控制和扩展的灵活性)
与集群 API(Cluster API)不同,集群 API 作为控制平面的封装,Serverless 模块抽象了集群引入的计算“层级”。集群将原本单一的区域数据平面分割成了多个部分。Serverless 模块需要将这一新概念适配到平台,处理诸如根据特定工作负载推断最适合的集群之类的额外复杂性。
可扩展性与可控升级
目前架构拥有超过130,000个实例,已经按照关键性、工作负载类型和地区、提供商等进行划分。这些划分在我们进行受控升级时尤为重要,特别是在数据和控制平面组件更新时。当需要进行升级时,过程会从关键性较低的集群和测试环境中开始,以确保稳定性。因此,只有在仔细验证之后,变更才会逐步推广到更高关键性的集群。这种策略可以最小化风险,确保服务连续性不被破坏。
部署步骤
现在我们已经了解了引擎的架构,让我们在Fury平台内看看应用部署流程。我们采用了GitOps(一种通过Git仓库自动部署和管理基础设施的方法)的方式来部署引擎的内部组件;然而,我们下次再详细聊聊这个话题。
在 Fury 中,有多种部署策略,如 All-in、Blue-Green 和 Canary,这些策略分别针对不同的开发场景。此外,还有两种特定于平台的策略:安全部署和迁移策略。
- 安全部署:此策略类似于蓝绿部署策略,但采取更为渐进和谨慎的方法。它持续监控指标并自动做出回滚操作或调整建议,确保安全且受控的过程。
- 迁移策略:一种更广泛的策略,允许工作负载在供应商、区域之间或甚至在不同的计算环境(从《标准》到《无服务器》和反之亦然)之间进行迁移,以满足弹性和成本需求。
部署步骤细节
在部署架构中,Fury 触发无服务器模块,该模块通过请求创建工作负载从而启动流程。此请求通过集群 API 传递,通过应用负载均衡器(Ingress ALB)分配流量,并创建所有必要的组件以正确路由应用。
接下来,Cluster API 配置所需的 Kubernetes 组件,例如 ReplicaSets 和水平 Pod 自动扩缩器 (HPAs)。我们选择使用 ReplicaSets 而不是 Deployments,因为我们的目标是确保适当的副本数量,而不需要依赖 Deployments 提供的额外资源,因为这些策略已经在平台中实现。
监控,异步控制
一旦工作负载被创建之后,无服务器模块——特别是其“Little Monster (LM)”组件——会进行持续监控,并处理发送到集群的异步请求。无服务器API控制器(一个Kubernetes控制器)通过直接观察集群中的Pod和节点的行为来扩展Kubernetes,使平台能够实时了解任何变化。该控制器通过这些对象的“观察者”来同步集群状态与外部状态,通知无服务器模块,使平台能够做出响应并进行动态调整。
这种结构使得Fury能够高效且稳健地进行部署,监控集群和工作负载的状态变化,并通过弹性和安全应对实时的变动。
蓝绿部署流程
在 Fury 中实施蓝绿部署策略时,过程遵循之前提到的基本流程,但包含了一些特定的必要细节。
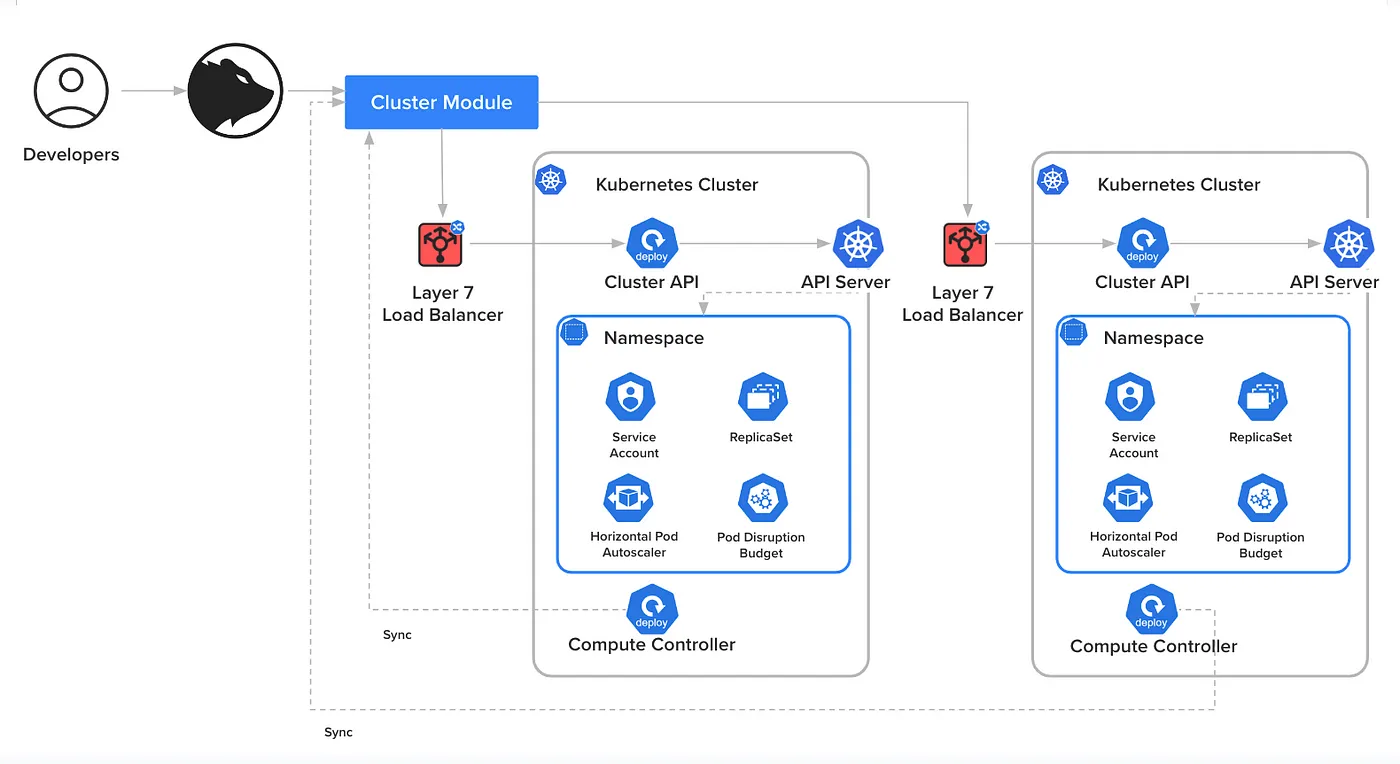
图片6:Fury中的蓝绿部署流程图,展示了当前和备选的基础设施。
在这个场景中,当前正在运行的生产工作负载(蓝色版本)会被保留,同时创建一个新的工作负载集合(绿色版本)同时运行。这个新的版本可以部署在同一集群,或者按照分片平衡策略部署在不同集群。
创建流程与标准部署相同:平台启动无服务器模块,该模块随后通过 ingress ALB 接口请求集群 API。这一步骤设置所有必要的 Kubernetes 组件,如 ReplicaSets 和 HPAs,复制当前基础架构以支持新的工作负载组。
一旦蓝绿部署过程完成,平台会自动更新其内部状态,记录所有的变更。这样,我们可以持续并详细地监控两个版本的工作负载(蓝和绿),在完成必要的检查后,确保安全并有序地过渡到新版本。
网络和流量交换
在蓝绿部署中的一个关键点是逐步将流量从当前版本重定向到候选版本。为了实现这一目标,我们采用了一种特定的方法,确保全面的网络可见性,并实现组件间的同步速度加快。
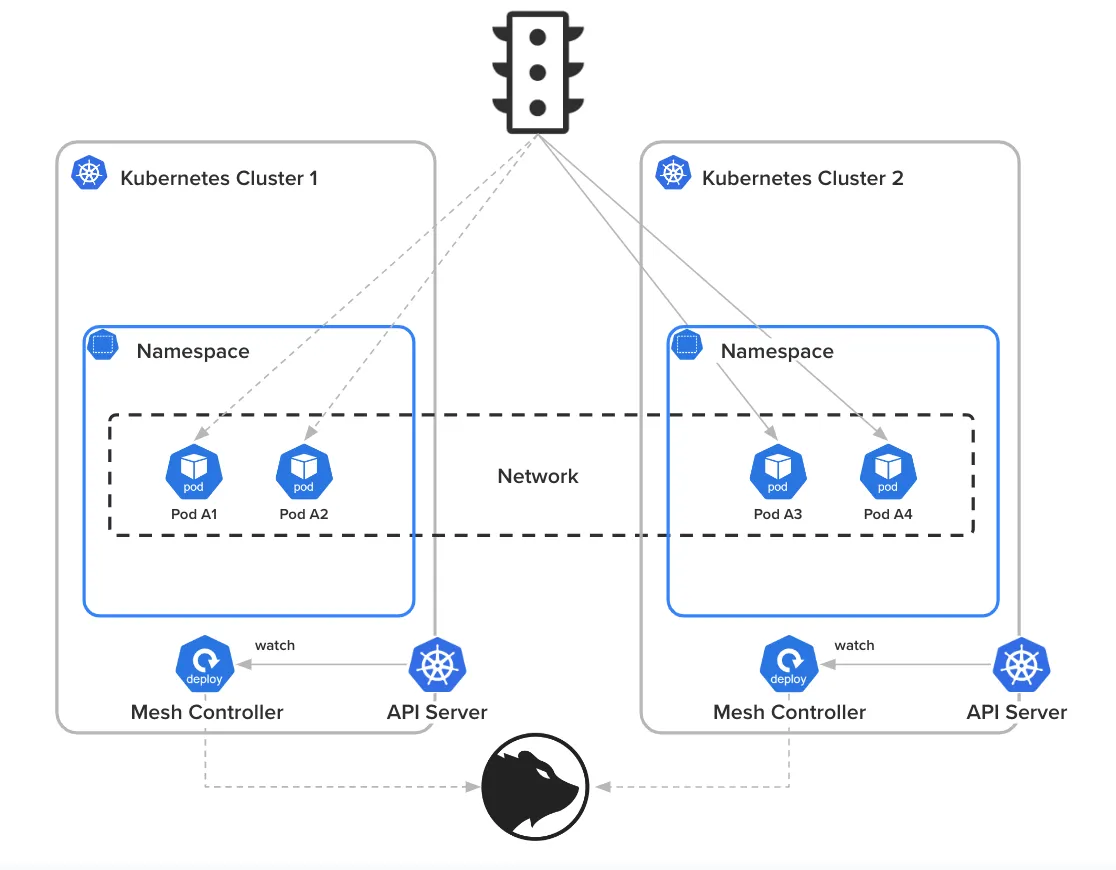
图7:在Fury中,当前与候选者间的流量互换。
每个 Pod 都拥有来自 VPC 的唯一且可路由的 IP,而不是虚拟 IP (VIP)。这使得每个 Pod 都可以直接访问网络资源,便于与其他服务进行通信,并减少了每个集群所需的入口点数量。
由于我们不使用第三方网络产品进行路由,我们开发了一个内部组件,称之为“网格控制器”。在流量交换过程中的关键角色,这个控制器响应由控制平面生成的变化。一旦发现事件,网格控制器会同步状态并将状态同步信息通知平台的控制平面的API,也就是我们的服务网格。
此通知会自动更新所有与应用程序一同部署的Envoy边车代理。因此,路由将被调整,让Envoy将流量重新定向至新的候选者,完成流量过渡到最新版本,并确保平台和应用始终知道最新的路由。
结论部分
在 Mercado Libre 上,Fury 的旅程展示了技术进步和持续创新如何帮助我们克服挑战并推动规模化效率。Fury 建立在强大的 Kubernetes 基础上,已经解决了运营复杂性,为开发人员提供了一个直观、安全且可扩展的环境。通过简化基础设施管理和优化部署流程,Fury 让我们的工程师能够专注于通过代码创造真正的价值,这也使公司能够采用多云等策略,并迅速做出具有财务影响的战略决策。这种做法使我们能够满足当前需求,并预测和克服未来的挑战,再次证明我们对提供卓越开发体验和持续演进的承诺。
感谢:
这篇文章由马尔科斯·安东尼奥·苏扎·皮尼奥与马塞洛·科德罗·德·夸德鲁斯共同撰写




