
构建对话式AI系统超级难!!!
这是可行的,但也很复杂、耗时且耗资源。
挑战在于设计能够理解和生成像人一样的回复的系统,并确保这些系统能有效地与用户互动,适应对话中的细微差别。
广受欢迎的RAG(检索增强生成)通过将外部知识与大规模语言模型的内部知识无缝集成,彻底改变了对话式AI的面貌。结合RAG和您的业务数据,客户可以用自然语言查询他们的数据,实现无缝的交互体验。(注:LLM即大规模语言模型)。
但是有一个需要注意的地方: 使用(RAG,即检索增强生成)时会发现,并非每个问题都需要从“外部资料”中寻找答案。过度依赖外部资料会打断真正的互动。这就像是与人交谈时,对于每个问题都去书里找答案,即使你已经对这个话题有了深入的理解。更糟糕的是,没有相关的书可以找到,最终只能回答“我不知道”,虽然你实际上有内部知识可以给出更深入的回答。
使用RAG时,需要一个机制来确定推理时何时使用“外部知识”与“已有的知识”。显然,这是必要的。
输入 RAGate — 一个开关,用于动态决定何时使用外部知识以及何时依靠内部洞察。该技术由 Xi Wang、Procheta Sen、Ruizhe Li 和 Emine Yilmaz 提出,并在 2024 年 7 月发布在 ArXiv(用于对话系统的自适应检索增强生成方法)。
我们通过例子来学更多吧。
会话人工智能到底是什么?对话是个人之间思想、情感和信息的交流,根据语气、情境和细微暗示来引导互动。人类天生适合对话,因为我们有情感智能、社交化和文化熏陶等特质,这些特质帮助我们理解细微差异,并适应不同的社交场合。
对话式人工智能技术旨在通过使用技术来理解和生成自然、符合上下文且有趣的回应,从而模拟这种类似人类的互动。它根据用户的输入进行调整,让互动更加流畅和生动,就像人在对话一样。
什么是AI系统中的外部知识和内部知识?在开篇段落中,我提到了两个关键术语——外部知识和内部知识。我们稍微停一下,澄清这两个概念,因为理解它们会使学习RAGate更容易。
外部知识包括从外部来源获取而非模型内部固有的信息。这些来源包括结构化数据仓库和API接口,以及非结构化知识库,如指南、FAQ和网络上的资源。外部知识的主要作用是提供事实准确、时效性强且与上下文紧密相关的信息,从而增强AI响应的准确性和丰富性。
内部知识指的是AI模型根据训练数据嵌入的内置知识和处理能力。这些来源包括语言模式、语法知识、共享事实和一般世界知识,从过去交互记忆中获得的上下文理解,以及AI的语义理解能力。
RAG 和 Guardrails — 强力搭档,但也有限制?!RAG结合了两个强大的功能:(1)大型语言模型(LLMs)理解并处理自然语言的能力,能够生成类似人类的文本。(2)检索并增强最新的外部信息的能力。
许多RAG(检索增强生成)实现包含限制措施、约束或规则,以引导系统行为,使之更负责任且符合特定领域的AI标准。这些限制措施通常更倾向于使用外部知识而非模型内部的知识,以确保响应更加可预测。严格应用这些限制措施有时会导致次优的结果:
- 过度依赖外部来源: 即使对于通用问题,系统也可能被迫依赖外部信息,而内部知识已经足够。
- 潜在的响应不流畅: 通过限制内部知识,系统在某些情况下可能会产生不自然或脱离上下文的回应。
- 增加延迟: 不断获取外部信息可能会比依赖内部知识减慢响应时间。
- 错失机会: 大型语言模型中丰富的知识可能会未能充分利用,从而可能错过有价值的见解或联系。
RAGate,即检索增强生成门控,通过自适应地决定何时将外部知识纳入响应,增强对话式AI系统。
RAGate研究 探讨了对话系统中适应性增强的必要性,并提出了作为控制何时检索外部知识的模型的RAGate,用以预测何时检索外部知识的时机是有益的。论文详细介绍了实验和分析,展示了RAGate在提升回应质量和增加生成自信方面的有效性。
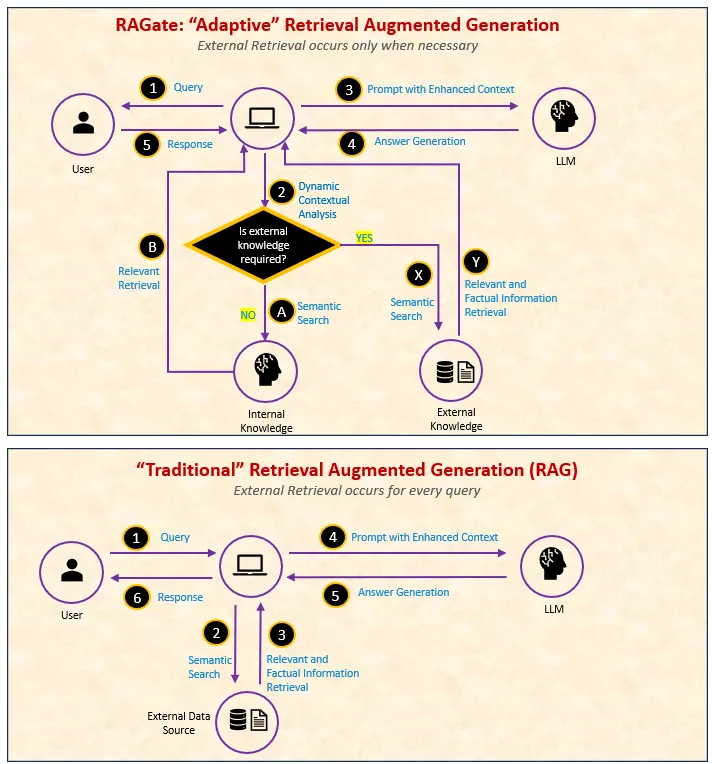
RAGate 流与传统 RAG 流有何不同?图片来源:作者
RAGate 示例演示
情景: 用户正在与一个AI健康助手互动,这个AI健康助手专注于根据一般健康原则和医学知识提供个性化的健康建议。
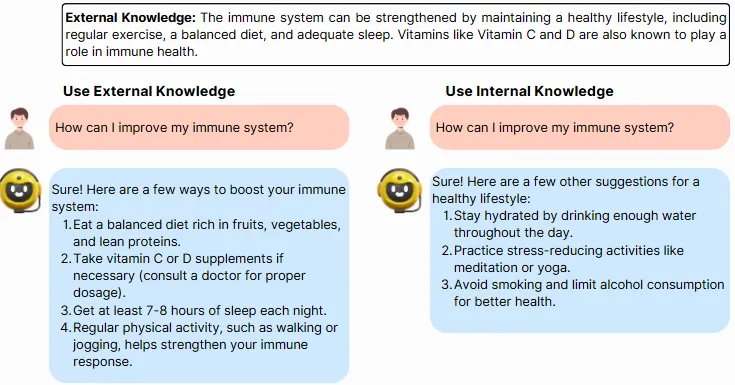
这里举一个例子来说明RAGate如何通过利用内部知识提供无需参考外部信息的通用健康建议,从而提高AI的响应质量。图片来自作者
RAGate 可以通过平衡内部和外部知识进一步提升对话质量。它允许 AI 使用内部的医疗知识提供通用信息,同时检索最新的研究。它甚至可以智能地综合多个来源的数据进行综合分析,根据患者细节提供个性化建议,并过滤外部信息以优先展示最相关的信息,从而减少信息过载的影响。
RAGate的不同变种正如论文中所述,RAGate 提供了 3 个版本 — RAGate-Prompt,RAGate-PEFT 参数高效微调,和 RAGate-MHA 多头注意力。
RAGate 的每个变体 —— Prompt、PEFT 和 MHA —— 采用不同的方式来融合外部信息,共同目标是提高 AI 响应的相关性和准确性。
这里有一个简单的对比表格:
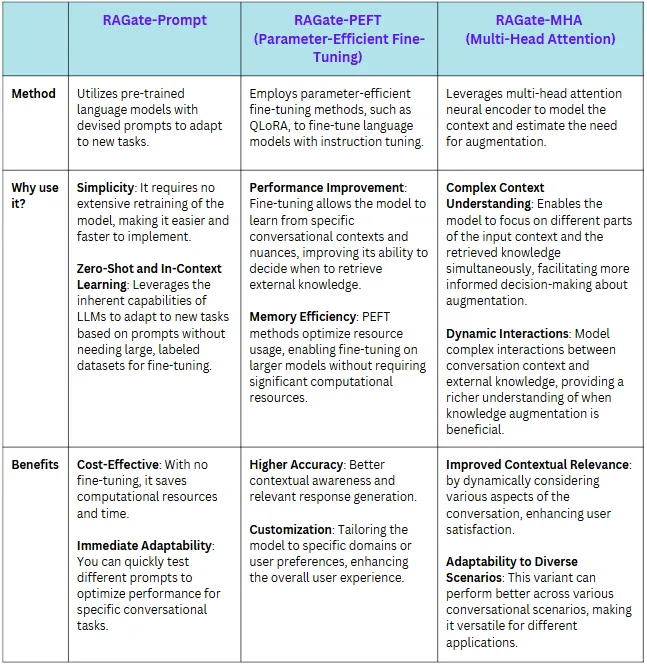
RAGate各个变体之间的比较 — RAGate-Prompt,RAGate-PEFT(PEFT),和 RAGate-MHA(MHA)。图片来源:作者
怎么使用RAGate?这篇论文提供了一个实施RAGate的指南。
- 定义问题:这一步至关重要,因为它涉及到识别您希望用RAGate增强的具体对话任务。确定对话的范围以及您想要涵盖的具体领域(例如,餐厅推荐,旅行规划)。
- 选择语言模型:选择一个合适的大规模语言模型(LLM)作为您对话系统的骨干。选项包括像Llama、GPT-2或其他基于Transformer的架构。
- 收集和标注数据:收集与您的对话领域相关的数据集。包含标注对话和知识片段的KETOD数据集是很好的例子。确保您的数据集具有明确的标签,以表明何时需要知识增强。
- 开发知识检索系统:实现一种知识检索机制,以在需要时检索相关的外部信息。可以考虑流行的技术,如密集段落检索或基于图的知识库。
- 实现RAGate机制:创建二进制知识门控函数(RAGate),以确定何时用外部知识增强响应。这涉及到上下文分析和门控函数的设计。
- 探索RAGate变体:根据论文中讨论的方法开发RAGate的不同变体。
- RAGate-Prompt : 使用自然语言提示和预训练的语言模型来确定是否需要增强。
- RAGate-PEFT : 使用参数高效微调技术(如QLoRA,一种参数高效微调技术)训练语言模型,以做出更好的决策。
- RAGate-MHA : 利用多头注意力机制评估上下文并互动检索知识。
7. 训练模型: 使用标注的数据集对LLM进行微调,利用各种RAGate变种。将门控机制的训练过程纳入其中,从而增强模型预测需要增强知识的能力。
8. 评估它的性能:通过一系列广泛的实验来验证RAGate的有效性,看看它是否真的有效。分析比如以下指标:
- 精确度、召回率、F1分数:用于评估门控函数的分类表现。
- BLEU、ROUGE、BERTScore:用于评估生成响应与真实值的匹配度。
- 置信度分数:衡量生成输出的可信度,确保高质量的回复。
9. 部署系统:将启用了RAGate功能的对话系统集成到您的应用程序或服务中,并动态选择知识提升。确保系统能够处理实时查询。
10. 不断迭代和改进:持续收集用户反馈和交互数据以优化模型性能。分析系统在处理上下文或相关性时的弱点,并相应调整模型的训练或检索方法。
基于专家建议的修改翻译: 重点总之,RAGate 通过智能地平衡内部和外部知识,实现了在对话式人工智能方面的重要进展,提供更相关、更高效和更个性化的回应。RAGate 的应用范围广泛,包括但不限于医疗、客户支持、教育、法律服务、金融等行业。通过增强 AI 提供定制实时信息的能力,RAGate 有潜力彻底改变企业和个人与技术互动的方式,从而改善决策制定、用户体验和整体系统性能。





