
 ,作者制作的这张图片。
,作者制作的这张图片。
简介这篇文章两周前发表在我的通讯中。免费订阅我的通讯,这样您可以更早地收到我的文章发送到您的邮箱。
这一周,我们将探索最著名的OLAP系统之一:ClickHouse。我打算写一篇文章专门介绍ClickHouse的MergeTree存储引擎,并简要介绍ClickHouse。
在进行研究时,我意识到最好先写一个单独的文章介绍ClickHouse,然后再深入探讨它的各个部分。
动机篇我参考了他们去年八月发布的这篇论文paper以及Clickhouse官方文档。
ClickHouse 是一个高性能的列式 SQL OLAP 系统,可作为开源解决方案和云服务使用。它专为处理 PB 级数据的高性能分析处理而设计,并具有异常高的数据摄入速度。
该系统最初于2009年内部开发,以支持Yandex Metrica分析平台的运作。Yandex Metrica 允许客户创建定制报告,提供基于用户点击次数和会话的实时分析。这通常涉及使用近乎实时的用户点击和会话数据构建复杂的聚合。
在2014年4月,Yandex Metrica 每天记录大约120亿个事件(页面浏览和点击),所有这些事件都需要存储以生成自定义报告。一个查询可能在几百毫秒内扫描数百万行记录。ClickHouse 被设计用来直接从原始数据生成自定义报告。
ClickHouse 于 2016 年 开源了,并自此发展成为一个更加强大和通用的 OLAP 系统。

ClickHouse开发时间线图,图1,ClickHouse — 适合每个人的闪电般快速分析(2024)
ClickHouse 目标是解决现代分析数据管理中的关键问题:
- 高吞吐量: 数据驱动的应用程序(如网络分析、金融和电子商务)会产生大量数据。分析型数据库需要更高效的索引、压缩以及跨多个节点支持数据分布。此外,最近的数据通常比历史数据更具有实时洞察的价值。这使得数据库需要以高且一致的速率摄入新数据——即使在突发情况下——同时高效处理旧数据。这种平衡确保了即使在数据量增加的情况下,报告查询应能平稳运行,而不会导致性能下降。
- 低延迟的同时查询: 查询通常分为两类:即席查询(ad-hoc查询),如探索性数据分析,或定期查询,如定期仪表板查询。查询越交互性,期望的查询延迟就越低,这引入了优化和执行的挑战。然而,定期查询使定制数据库物理布局成为可能,使修剪技术对于高效数据处理至关重要。此外,数据库必须根据查询的优先级合理分配共享资源(如CPU、内存、磁盘和网络I/O)。这确保了即使在高查询负载下,每个查询也能获得公平或优先访问,从而保持同时操作的性能。
- 适应性: 现代分析数据库必须高度适应,能够与现有数据架构无缝整合。这意味着它们应该能够轻松地跨各种系统、位置和格式读取和写入外部数据,保持在不同环境下的灵活性和兼容性。
- 部署:鉴于商品硬件的不可靠性,数据库必须包括数据复制以抵御节点故障的风险。它们还应足够灵活,可以在各种硬件上运行,从旧笔记本电脑到高性能服务器。
在下一节里,我们将了解Clickhouse架构。
建筑

Clickhouse的整体架构图如下,由作者绘制。Reference
ClickHouse,用 C++ 编写,分为三个主要层次:查询处理层、存储层和集成层。此外,一个访问层管理用户会话并支持通过多种协议进行通信。除了这些核心层之外,ClickHouse 还包括线程管理、缓存、基于角色的访问权限控制、备份和持续监控功能等组件。
这一层用于查询处理查询处理层负责解析传入的查询请求,构建并优化逻辑和物理查询计划,同时进行执行。ClickHouse 使用向量化执行模型(类似于 DuckDB、BigQuery 或 Snowflake),并结合按需编译代码。

向量化模型图。作者绘制
ClickHouse 在多个层次上并行执行查询,包括数据元素、数据段以及表分片(如果表在多个节点之间进行了分片)。
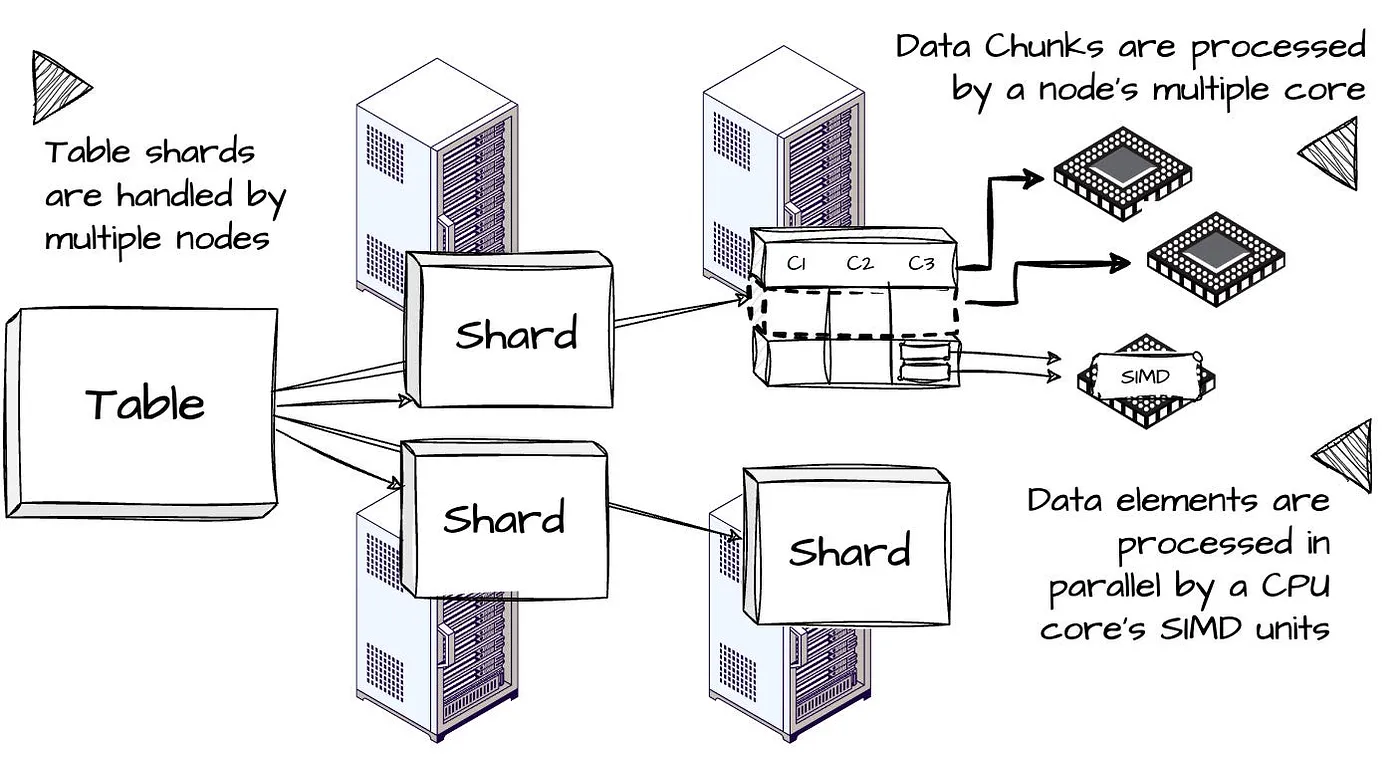
本文作者制作的图片。
- 表碎片:多个节点可以同时扫描分片。因此,所有硬件资源都能得到充分利用,并且可以通过增加节点进行水平扩展,通过增加核心进行垂直扩展以处理查询。
- 数据块:在一个节点上,查询引擎可以在多个线程中同时执行操作。ClickHouse 使用向量化模型来处理操作,从而生成、传递并消费多行(数据块),而非单行,以减少虚拟函数调用的开销。
- 数据元素:可以在单个 CPU 核心中的 SIMD 单元内同时处理多个数据元素。

作者绘制的
与大多数在线分析处理数据库不同,ClickHouse的存储层配备了多种表引擎,每种表引擎都设计用于特定的应用场景和需求。表引擎可以分为三大类:
- 第一类是 MergeTree 家族 的表引擎,这是 ClickHouse 中的主要引擎:基于 LSM 树表的思想(但略有不同),表被划分为水平的数据片段,并且每个片段中的数据都是排序过的,这些片段随后会被后台进程不断合并。每个 MergeTree 引擎在合并其输入片段的方式上有所不同。例如,行可以被聚合(例如 AggregatingMergeTree)或替换(例如 ReplacingMergeTree)。

这是作者自己画的图片。
我接下来的文章会讲到 MergeTree 引擎。
- 第二类包括特殊用途的表引擎,这些引擎旨在加速查询执行或分发查询结果。这类表引擎包括内存中的键值对表引擎,称为字典,它们会定期缓存从内部或外部数据源获得的查询结果。
- 第三类是虚拟表引擎,用于与外部系统(如关系数据库(例如 PostgreSQL、MySQL)、发布/订阅系统(例如 Kafka)或键值存储(例如 Redis))进行数据交换。这些引擎还可以处理如 Iceberg、DeltaLake 或 Hudi 这样的表格式数据,或如 AWS S3 或 Google GCP 这样的对象存储中的数据。
ClickHouse支持在集群节点间对表的数据进行分片和复制。分片会使用分片表达式将一个表分割成多个分片。每个分片都可以看作是一个独立的表;用户可以直接操作分片,将其视为独立的表,或者使用分布式表引擎来获取所有分片的统一视图。分片的最终目的是处理单机无法处理的大量表数据。
另一种分片的用途是将表的读写操作分散到多个节点。此外,可以将分片跨节点复制以增强容错性。Clickhouse 为每个 MergeTree 表引擎提供了对应的 ReplicatedMergeTree 表引擎。
复制的ReplicatedMergeTree使用基于Raft共识算法的多主协调机制,该机制由ClickHouse Keeper(一个Apache Zookeeper的C++替代品)实现,以确保每个分片都能维持一个可配置数量的副本。
集成层注:在相关技术社区中,“集成层”一词已被广泛理解和使用。在OLAP数据库中,使外部数据可用有两种方法:推送式和拉取式。在推送式方法中,第三方组件将外部来源的数据推送至数据库。在拉取式模型中,数据库连接到远程数据源并从这些数据源拉取数据。ClickHouse采用拉取式的数据集成方式。
- 外部连接性:ClickHouse 提供了 50 多种连接外部系统和存储位置的表格函数和引擎,包括 MySQL、PostgreSQL、Kafka、Hive 或 S3/GCP/Azure 对象存储。
- 数据格式:ClickHouse 支持超过 90 种格式,包括 CSV、JSON、Parquet、Avro、ORC、Arrow 和 Protobuf。一些专为分析设计的格式,如 Parquet,已与查询处理进行了集成,这使得查询优化器可以利用内置的 Parquet 统计信息,从而直接在压缩数据上评估过滤器。
- 兼容性接口:客户端可以通过 MySQL 或 PostgreSQL 兼容的网络协议接口与 ClickHouse 交互。这种兼容性对于从尚未为 ClickHouse 提供原生连接的应用程序中启用访问非常有用。
这周的内容到这里就结束了。
在这篇文章中,我们讨论了ClickHouse背后的原因和动机、其架构以及查询处理层的简要介绍。
有了这些基础,我们下一期文章再见,一起看看 MergeTree 表引擎,敬请期待。
参考Ryadh Dahimene, Alexey Milovidov, ClickHouse — 闪电般快速的分析工具,适合每个人 (2024)





