
想象一个学步的小朋友。他们迈出一步可能会摔倒,但每次尝试,他们会根据前一步的成功或失败来调整动作。随着时间的推移,他们通过不断调整自己的行动以实现稳步前行的目标,避免摔倒。这种通过试错来学习的过程就是强化学习(RL)的本质。所有动物都在通过与环境互动的经验中学习,调整行为以达到期望的结果。
受这一概念启发,人工智能中的强化学习技术使机器能够与其环境互动,并从经验中学习到最佳行为。这是机器学习中最令人兴奋(也是最具挑战性)的领域之一。2016年,谷歌的DeepMind开发了AlphaGo,一个在围棋比赛中击败世界冠军的人工智能代理。围棋是一种复杂且以抽象策略闻名的棋盘游戏。AlphaGo不是通过模仿专家的走法,而是通过与自己进行数百万次对战,达到了超人类水平的表现。许多人认为这是强化学习解决一度被认为只有人类才能解决的问题的里程碑式成果。
尽管关于强化学习(RL)的兴奋情绪很高,但相关资源可能非常有限且很难理解,这使得许多人难以接触。在这篇文章中,我打算提供一个谦虚的RL入门介绍,涵盖其数学基础的要点,并通过一个例子来说明其设置;教一个代理学会如何优化操作一个简化的发电厂。因为我正在学习和使用RL,所以这里的很多内容将是我学习的总结。
强化学习:入门强化学习的核心在于训练一个智能体在环境中做出决策,以最大化其累积奖励。与监督学习在每个输入提供正确的标记输出的情况下不同,强化学习依赖于智能体通过行为后果学习,即通过经验学习。在深入探讨数学之前,让我们先了解一下强化学习框架中的关键组成部分和概念。
- 代理 : 决策者。
- 环境 : 代理与其互动的系统,用来确定其行为的后果。
- 状态 (s) : 环境中某一情况的描述或表示。
- 行动 (a) : 代理可执行的所有行动。
- 奖励 (r) : 从一个状态转换到另一个状态后立即得到的奖励。
- 策略 (π) : 代理根据当前状态决定下一步行动的策略。
此框架也在下图中示意:

图片来自TechVidvan(https://techvidvan.com/tutorials/reinforcement-learning/)
马尔可夫决策过程 —— MDP
为了定义强化学习问题,使用马尔可夫决策过程(MDP)。MDP 提供了一个数学模型,用于决策制定,其中结果部分是随机的,部分则受代理人控制。
马尔可夫决策过程(MDP)定义为:状态空间(S)、动作集(A)、状态转移概率(P)、奖励函数(R)、折扣因子(γ),其中:
- S: 一组状态。
- A: 一组动作。
- P(s′|s,a): 从状态 s 转移到状态 s′ 的概率,给定执行动作 a。
- R(s,a): 在状态 s 执行动作 a 后预期收获的奖励。
- γ ∈ [0,1] : 折扣因子;平衡了即时奖励和未来奖励。数值接近 0 会让智能体更重视眼前利益(优先考虑即时奖励),而数值接近 1 则鼓励智能体考虑长期利益。
马尔可夫性是马尔可夫决策过程中的一个关键假设,它指出下一状态只依赖于当前的状态和所采取的动作,而不依赖于之前的状态和动作的历史。“无记忆”的属性使强化学习算法的设计变得简单。
目标:争取最大累积奖励
代理的目标是找到一个最优化策略π*,以最大化其预期的长期累计奖励。该策略将状态映射到动作,π:S→A,确定代理在每个状态下将采取的动作。
累计奖励/回报定义为未来奖励折现后的总和。
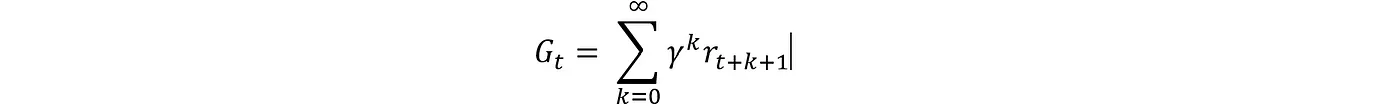
· Gt:时间步t的返回
· r(t+k+1): 在时间步$t+k+1$收到的奖励。
· γ:折扣率( 0≤γ≤1)。
效用函数
为了做出决策,代理会估算状态和动作的价值。价值函数量化了代理处于特定状态以及在该状态下执行特定动作的好度。
状态价值函数:
状态值函数 ( V^{\pi}(s) ) 表示从状态 ( s ) 开始,按照策略 ( \pi ) 行动后的预期回报,用数学形式可以表示为:

这个函数衡量了在当前状态 s 下,在策略 π 下的长期效益。
动作价值函数:
行动-价值函数 $Q^{\pi}(s, a)$ 是在状态 $s$ 下采取行动 $a$ 并随后按照策略 $\pi$ 行事的所有后续状态中的预期回报:
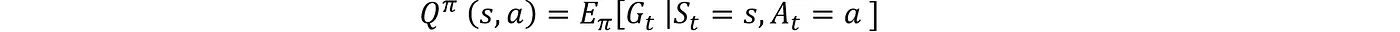
这个函数衡量了在当前状态$s$下,在策略$\pi$的指导下执行动作$a$的价值量。
贝尔曼方程组
这些价值函数具有递归性,其中每个状态-动作的价值本质上是立即行动的即时奖励加上从新状态开始的后续价值。这就是所谓的贝尔曼方程。
状态价值函数($V^{\pi}(s)$)的贝尔曼方程:

在状态$s$下,代理可以采取的每个可能动作,以策略$\pi$下采取动作的概率$\pi(a|s)$作为权重:
· 即时奖励:R(s,a) 表示在状态 s 下采取行动 a 的期望奖励
· 未来的价值:γ∑P(s′|s,a)V^π(s′) 是状态 s 转到 s′ 的预期价值,加权系数为 P(s′|s,a) 的权重。
用简单的话来说,这个方程基本上说明状态 𝑠 的价值。这个价值等于即时的预期奖励加上下一个状态的预期折现值,考虑到所有可能的动作和状态转换。
最优政策和效用函数
最优策略 π* 在所有状态下都能提供最高的回报:

同样地,最优的动作值函数是:

大多数RL算法的目标是找到Q(s,a)或V(s),这两个值定义了最优策略。例如,对于任何给定的状态,一个确定性的最优策略可以让代理人选择具有最大动作价值的动作。

但显然我们可以采取两种不同的方法,一种是优化状态和行动值函数,另一种是直接优化策略。我们将会简要讨论这两种方法。
价值函数时间差分学习
就像正常的神经网络训练在每批数据后使用反向传播一样,强化学习也需要根据所采取行动的结果来更新价值函数。根据具体问题的性质,有不同的方法来实现这一点。一种流行的方法是时序差分(TD)学习,这种方法既可用于具有明确开始和结束状态的分段任务,也可用于没有结束状态的持续任务。TD在每一步后更新价值估计。TD学习根据预测奖励与实际奖励之间的差异来更新价值估计。这可以表示为
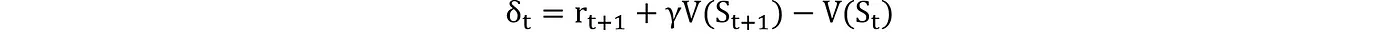
· r_{t+1}:在状态 S_t 执行动作 A_t 后得到的奖励。
· V(S_{t+1}):下一状态的估计值。
· V(S_t): 当前状态 S_t 的估值
TD误差 $\delta_t$,衡量当前状态预期值与实际观察值的差异。价值函数的更新规则为:。

其中 α 是学习率。价值估计 V(S_t) 向观察到的即时奖励加上下一个状态的折扣值进行更新。这种方法使智能体能够直接从原始经验中学习价值函数,而无需了解环境模型。
策略梯度法
相比之下,策略梯度方法不估计价值函数,而是直接优化参数设定的策略θ。目标是最大化基于θ的期望回报。

政策参数接着就用标准的梯度下降法来更新(实际上是为了最大化目标,这里用的是梯度上升法)。

但计算∇_θ J(θ) 却很棘手。由于 J(θ) 对所有可能的动作序列的期望,直接计算这个值并不容易。这就是策略梯度定理可以帮我们计算这个梯度的地方。

符号 ∇_θlnπ_θ(a∣s) 是在状态 s 下采取动作 a 的概率对策略 π_θ 的梯度。这个公式的意思是调整策略的参数,以便增加那些能带来更高奖励的动作的概率。
近端策略优化(Proximal Policy Optimization,PPO)
在实践中,会使用诸如PPO(近端策略优化)之类的方法来稳定训练过程,并提升性能。PPO的目标函数是:
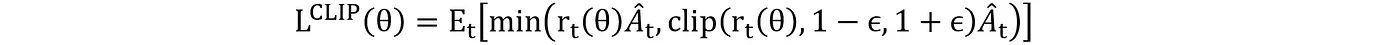
其中,r_t(θ) 表示新策略相对于旧策略的概率比。

Ā 是时间 t 时的优势评估,衡量动作 a_t 相比状态 s_t 中的平均动作有多大的优势。ϵ 是一个控制裁剪范围的超参数。裁剪函数的作用是确保更新不会太偏离之前的策略,有助于保持训练的稳定性。这个裁剪的代理目标实际上防止了可能导致训练不稳定的过大更新。
优势函数 $Ā_t$ 表示动作比平均水平好到什么程度。它这样计算:

如果 Ā_t > 0,行动比预期的好,因此策略应该增加其几率;如果 Ā_t < 0,行动比预期的差,因此策略应该减少其几率。
将强化学习(Reinforcement Learning, RL)应用到发电厂运行中有了对强化学习及其数学基础的简单了解,让我们用强化学习来指导一个代理,以最优地运营一个发电厂。发电厂运营涉及多个目标的平衡决策,比如安全、满足电力需求、降低运营成本、遵守排放规定和安排维护。我明白这简化了发电厂运营的过程,这只是为了演示RL提供一个简单的例子。
设定环境
状态 ( s ) 是由外部因素和内部状态共同构成的。状态 ( s_t ) 包含:
- 外部因素:
- 需求预测(d_t)
- 燃料价格(p_coal,t,p_gas,t)
- 效率参数(e_boiler,t,e_turbine,t)
- 其他外部因素;如图所示。
- 内部状态:
- 功率输出(P_t)
- 燃料消耗率(F_t)
- 排放水平(E_t)
- 维护状况(M_t)
- 储能水平(S_t)
外部变量是合成数据,这里列举了一些变量的例子。生成这些合成数据的代码是为了通过一天中的时间和一年中的季节来封装这些变量在现实世界中的季节性行为。在这里不提供代码,但你可以在github上轻松找到。

这些动作(a)指的是控制变量,比如涡轮机输出、燃油混合比率和排放控制的设定值。在时间点t,动作列表包括:
- 主涡轮功率输出 (a1,t)
- 次级涡轮功率输出 (a2,t)
- 燃料混合比例 (a3,t)
- 发电机励磁程度 (a4,t)
- 排放控制力度 (a5,t)
这些行为是受操作限制的连续变量。
我们开始写环境代码吧。我们将使用gymnasium库来创建我们的环境‘gym’。这部分代码主要是设置类中所有参数,也就是运行开始时用到的参数。
import gymnasium as gym
from gymnasium import spaces
import numpy as np
import pandas as pd
from pydantic import Field, BaseModel, ConfigDict
from src.utils.logger import logger
from typing import Dict, List
class EnvironmentConfig(BaseModel):
Data: pd.DataFrame = Field(..., description="外部因素的输入数据")
actions_list: Dict = Field(..., description="可以采取的操作列表")
internal_states_initialValue: Dict = Field(..., description="所有内部状态")
environment_variables: Dict = Field(..., description="其他环境变量")
model_config = ConfigDict(arbitrary_types_allowed=True)
class TheEnvironment(gym.Env):
def __init__(self, config:EnvironmentConfig):
super(TheEnvironment, self).__init__()
self.config = config
# 特征数量
self.external_conds_data = config.Data
self.ExternalDfeatures = len(self.external_conds_data.columns)
# 环境变量
self.EnvironVariables = config.environment_variables
# 定义动作空间和观察空间:
possible_actions = config.actions_list
Number_actions = len(possible_actions)
self.action_space = spaces.Box(
low=0, high=1,
shape=(Number_actions,),
dtype=np.float32
)
self.internal_states_initial_value = config.internal_states_initialValue
self.obs_shape = self.ExternalDfeatures + len(self.internal_states_initial_value)
self.observation_space = spaces.Box(
low=-np.inf,
high=np.inf,
shape=(self.obs_shape,), dtype=np.float32
)
# 初始化当前步骤:
self.current_step = 0
self.max_steps = len(self.external_conds_data) - 1 # 初始化最大步骤
# 初始化内部状态:
self.current_power_output = self.internal_states_initial_value['current_power_output']
self.fuel_consumption_rate = self.internal_states_initial_value['fuel_consumption_rate']
self.emissions_levels = self.internal_states_initial_value['emissions_levels']
self.current_operating_costs = self.internal_states_initial_value['current_operating_costs']
self.emissions_quota = self.internal_states_initial_value['emissions_quota']
self.hours_main_turbine_since_maintenance = self.internal_states_initial_value['hours_main_turbine_since_maintenance']
self.hours_secondary_turbine_since_maintenance = self.internal_states_initial_value['hours_secondary_turbine_since_maintenance']
# 初始化当前燃料混合比:
self.current_fuel_mixture_ratio = self.internal_states_initial_value['current_fuel_mixture_ratio']
# 环境变量:
self.Main_turbineOffCount = 0
self.SecondTurbineOffCount = 0
self.EnergyStorage = self.internal_states_initial_value['Initial_storage']
self.Total_reward = 0动作到状态的映射
为了正确评估强化学习代理的行为并准确映射状态转换,我们需要定义一个模型。该模型可以预测动作及其对应的状态。环境将根据当前状态和动作过渡到状态 s_(t+1)。
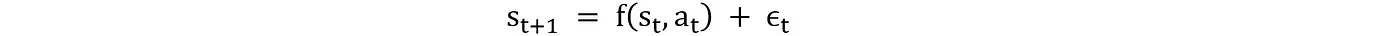
其中 f 代表环境动态的确定性部分(也就是模型),而 ϵ_t 则表示随机变化。例如,内部状态如功率输出 P_t(这里的 P_t 是指)可以根据动作这样定义:
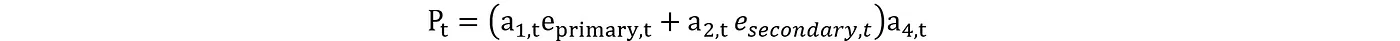
我们定义了所有行动和内心状态之间类似的关系。
从上面的代码继续,ObservationSpace 函数(注:观察空间函数)获取当前状态的快照;它会收集当前步骤的所有外部变量和内部变量(如当前输出的功率和储存的能量等)放入一个列表里,供智能体用来预测应采取的动作。
def 观测空间(self):
"""获取环境当前的状态"""
观测帧列表 = []
# 外部条件数据
for 变量 in self.external_conds_data.columns:
df = self.external_conds_data[变量]
最小值 = min(df)
最大值 = max(df)
平均值 = np.mean(df)
if self.current_step < len(df):
# print(f"列: {变量}, 值: {df.iloc[self.current_step]}, 类型: {type(df.iloc[self.current_step])}")
参数标准化 = (df.iloc[self.current_step]-平均值)/(最大值-最小值)
# 如果当前步长超过了数据帧长度
# 则添加最后一个给定数据
else:
参数标准化 = (df.iloc[-1]-平均值)/(最大值-最小值)
观测帧列表.append(df.iloc[-1])
# 内部状态数据
# 这些值目前进行了近似的标准化处理,将来需要进行精确的标准化处理
观测帧列表.append(self.current_power_output/400)
观测帧列表.append(self.fuel_consumption_rate/400)
观测帧列表.append(self.current_fuel_mixture_ratio)
观测帧列表.append(self.emissions_levels/500)
观测帧列表.append(self.current_operating_costs/1000)
观测帧列表.append(self.emissions_quota/6000)
观测帧列表.append(self.hours_main_turbine_since_maintenance/10) # 主涡轮机自上次维护以来的运行时间
观测帧列表.append(self.hours_secondary_turbine_since_maintenance/10) # 次级涡轮机自上次维护以来的运行时间
观测帧列表.append(self.EnergyStorage/6000)
return np.array(观测帧列表)我们现在定义一个步骤函数,该函数在收到代理执行的一系列行动后,将从中执行一步,以观察这些行动的结果,即奖励。它还将计算所有内部状态和观察空间(如上所述),以便计算下一步的动作。
def step(self, actions):
self.current_step += 1
# 检查步骤是否已超过最大限制
done = self.current_step >= self.max_steps
if done:
reward, accum_reward = self.RewardCalculation()
return self.ObservationSpace(), reward, done, False, {}
# 观察, 奖励, 完成标志, 信息
# 所有动作
self.main_turbine_output = (actions[0]+ self.config.actions_list['main_turbine_output'][0])*self.config.actions_list['main_turbine_output'][1]
self.secondary_turbine_output = (actions[1]+ self.config.actions_list['secondary_turbine_output'][0])*self.config.actions_list['secondary_turbine_output'][1]
self.current_fuel_mixture_ratio = (actions[2]+ self.config.actions_list['current_fuel_mixture_ratio'][0])*self.config.actions_list['current_fuel_mixture_ratio'][1]
self.generator_excitation = (actions[3]+ self.config.actions_list['generator_excitation'][0])*self.config.actions_list['generator_excitation'][1]
self.emissions_control_intensity = (actions[4]+ self.config.actions_list['emissions_control_intensity'][0])*self.config.actions_list['emissions_control_intensity'][1]
# 计算内部状态:
self.CalculateInternalStates()
observation = self.ObservationSpace()
reward, accum_reward = self.RewardCalculation()
info = {
"power_difference": self.current_power_demand - self.current_power_output,
"emissions_quota": self.emissions_quota,
"energy_storage": self.EnergyStorage,
"reward": reward
}
return observation, reward, done, False, info # False 表示未被截断给定观察空间,代理根据观察空间确定一系列动作,这些动作进而决定了状态的变化。为了映射动作对内部状态的影响,定义了一个名为CalculateInternalStates的函数来在采取一步行动后更新内部状态。这些更新是遵循简单的守恒规则定义的。
# 环境代码用于状态转换
def CalculateInternalStates(self):
# 功率计算
主涡轮的效率 = self.external_conds_data['main_turbine_efficiency'].iloc[self.current_step]
次涡轮的效率 = self.external_conds_data['secondary_turbine_efficiency'].iloc[self.current_step]
基础功率 = self.main_turbine_output * 主涡轮的效率 + self.secondary_turbine_output * 次涡轮的效率
生成功率 = 基础功率 * self.generator_excitation
if self.current_step < self.max_steps:
功率需求 = self.external_conds_data['demand'].iloc[self.current_step + 1]
else:
功率需求 = self.external_conds_data['demand'].iloc[-1]
# 剩余电量用于储能,不足部分从储能中补足
self.current_power_demand = 功率需求
功率差 = 生成功率 - 功率需求
# 储能容量
存储容量 = self.EnvironVariables['Energy_storage_capacity']
if 功率差 >= 0:
if self.EnergyStorage < 存储容量:
self.EnergyStorage += 功率差
self.current_power_output = 功率需求
else:
if self.EnergyStorage + 功率差 >= 0: # 即实际有足够的储能
self.EnergyStorage -= 功率差
self.current_power_output = 功率需求
else: # 即储能不足
self.current_power_output = self.EnergyStorage + 生成功率
self.EnergyStorage = 0
# 燃料消耗
锅炉的效率 = self.external_conds_data['boiler_efficiency'].iloc[self.current_step]
生成功率 = self.main_turbine_output + self.secondary_turbine_output
天然气消耗 = 生成功率 * (1 - self.current_fuel_mixture_ratio) / 锅炉的效率
煤消耗 = 生成功率 * self.current_fuel_mixture_ratio / 锅炉的效率
self.fuel_consumption_rate = 天然气消耗 + 煤消耗
# 排放
基础排放 = self.fuel_consumption_rate * (
self.current_fuel_mixture_ratio * 2 +
(1 - self.current_fuel_mixture_ratio)
)
self.emissions_levels = 基础排放 * (1 - self.emissions_control_intensity / 100)
self.emissions_quota -= self.emissions_levels
if self.current_step % (24 * 28) == 0: # 每4周重置排放配额
self.emissions_quota = self.internal_states_initial_value['emissions_quota']
# 每小时运营费用
煤价 = self.external_conds_data['coal_price'].iloc[self.current_step]
天然气价 = self.external_conds_data['gas_price'].iloc[self.current_step]
self.current_operating_costs = self.fuel_consumption_rate * (
self.current_fuel_mixture_ratio * 煤价 +
(1 - self.current_fuel_mixture_ratio) * 天然气价
)
# 更新涡轮机运行时间
if self.main_turbine_output > 0:
self.hours_main_turbine_since_maintenance += 1
# 维护周期
维护周期 = self.EnvironVariables['Turbine_maintenance_time']
if self.main_turbine_output == 0:
self.Main_turbineOffCount += 1
if self.Main_turbineOffCount >= 维护周期:
self.hours_main_turbine_since_maintenance = 0
self.Main_turbineOffCount = 0
if self.secondary_turbine_output > 0:
self.hours_secondary_turbine_since_maintenance += 1
if self.secondary_turbine_output == 0:
self.SecondTurbineOffCount += 1
if self.SecondTurbineOffCount >= 维护周期:
self.hours_secondary_turbine_since_maintenance = 0
self.SecondTurbineOffCount = 0奖励机制
让我们定义一个奖励机制,它将涵盖这些运营目标,包括满足电力需求、运营成本、排放成本、维护成本和减排成本等。
针对功率需求,我们可以对任何偏离需求的行为进行处罚。对于任何偏离功率需求的情况,我们有权进行处罚。

运营成本方面,我们只算燃油费用:

其中 F 代表燃料消耗率,上角标表示燃料来源。排放费用,如果排放量超出配额,则会对模型进行扣罚。

为了防止模型中的任何仪器在无维护的情况下长时间运行,我们可以添加一个惩罚因子。
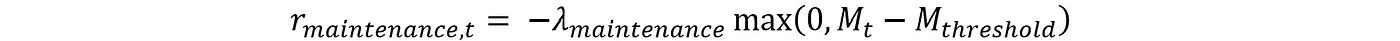
排放控制措施的实施费用:

所有这些都可以结合起来定义一个包含所有不同对象的奖励函数的:

这些方程在代码中都是这样定义的,如下所示。
def 计算奖励(self):
# 确保满足电力需求
电力差异 = self.current_power_demand - self.current_power_output
# 涡轮机维护:
涡轮使用上限 = self.EnvironVariables['Turbine_use_b4_maintenance']
# 主涡轮机
if self.hours_main_turbine_since_maintenance > 涡轮使用上限:
主涡轮机超出维护 = np.exp(self.hours_main_turbine_since_maintenance - 涡轮使用上限)
else:
主涡轮机超出维护 = 0
# 次级涡轮机
if self.hours_secondary_turbine_since_maintenance > 涡轮使用上限:
次级涡轮机超出维护 = np.exp(self.hours_secondary_turbine_since_maintenance - 涡轮使用上限)
else:
次级涡轮机超出维护 = 0
# 满足排放限额
if self.emissions_quota < 0:
超额排放 = -self.emissions_quota
else:
超额排放 = 0
# 与排放控制相关的成本
排放控制成本 = self.emissions_control_intensity * 1000 * np.exp(self.emissions_control_intensity)
# 包括运营及燃料成本
当前电价 = self.external_conds_data['electricity_price'].iloc[self.current_step]
奖励 = (5 * self.current_power_output * 当前电价 -
self.current_operating_costs - 电力差异 * 1000 -
主涡轮机超出维护费用 * 20000 - 次级涡轮机超出维护费用 * 20000 -
超额排放 * 5 -
排放控制成本)
self.current_step_reward = 奖励 / 1e6 # 奖励调整以确保数值稳定性
self.累计奖励 += self.current_step_reward
return 奖励, self.累计奖励定义代理人:
我们现在可以开始用stable_baseline3库定义智能体了。智能体被定义为一个包含多种功能的整体类中的一部分,这些功能允许智能体进行训练、用于进行推理预测,并通过在验证数据上运行来检查训练过程中的过拟合。
class AgentConfig(BaseModel):
total_timesteps: int = Field(..., description="总步数")
environment: DummyVecEnv = Field(..., description="代理运行的环境")
validation_timesteps: int = Field(..., description="验证步数")
train_timesteps:int = Field(default=100, description="训练步数")
model_config = ConfigDict(arbitrary_types_allowed=True)
class PPOAgent:
def __init__(self, config: AgentConfig):
self.callback = PolicyGradientLossCallback()
self.Agent = PPO(
"MlpPolicy",
config.environment,
verbose = 1,
learning_rate=1e-5,
gamma=0.99) # batch_size=256
self.config = config
def train(self):
self.Agent.learn(total_timesteps=self.config.total_timesteps, callback = self.callback)
logger.info("完成训练")
def predict(self, observation):
action,_ = self.Agent.predict(observation)
return action
def validate(self):
environment = self.config.environment
observation = environment.reset()
Rewards = []
rewards_accum =0
accumulative_reward = np.zeros(self.config.validation_timesteps)
for ii in range(self.config.validation_timesteps):
actions, _ = self.Agent.predict(observation)
observation, reward, done, _ = environment.step(actions) # 这是当前DummyVecEnv版本的问题
Rewards.append(reward)
rewards_accum += reward
accumulative_reward[ii] = rewards_accum
# 检查模拟是否已完成
if done:
observation = environment.reset()
print(f"{self.config.validation_timesteps} 步验证后的累积奖励: {accumulative_reward[-1]}")
logger.info(f"{self.config.validation_timesteps} 步验证后的累积奖励: {accumulative_reward[-1]}")
return np.array(Rewards), accumulative_reward训练智能代理
我们现在可以训练和测试这个代理了。训练和测试的代码非常相似;它将上面的代理代码与定义的环境结合起来,并对代理进行预定义步数的训练,然后进行验证或测试。
class ModelEvaluationConfig(BaseModel):
# 数据路径
training_data_path: str = Field(default="data/processed/train.csv", description="训练数据的路径")
val_data_path: str = Field(default="data/processed/val.csv", description="验证数据的路径")
test_data_path: str = Field(default="data/processed/test.csv", description="测试数据的路径")
# agent 环境变量
agent_possible_actions: Dict = Field(..., description="所有可能的动作及其值范围")
train_total_timesteps: int = Field(default=20000, description="训练期间的总步数")
validation_timesteps: int = Field(default=300, description="验证过程中的步数")
test_timesteps: int = Field(default=300, description="测试过程中的步数")
# 环境变量:
internalStates_InitialVal: dict = Field(..., description="所有内部状态及其初始值的字典")
environment_variables: dict = Field(..., description="其他环境变量的字典")
# 在测试前加载预训练的代理
use_pretrained_agent: bool = Field(default=True, description="如果为True,则在测试前加载预训练的代理")
model_config=ConfigDict(arbitrary_types_allowed=True)
class Model_train:
def __init__(self, config:ModelEvaluationConfig):
self.config = config
def train_agent(self):
## 训练阶段
# 训练数据
train_data = pd.read_csv(Path(self.config.training_data_path))
# 创建环境配置
env_config = EnvironmentConfig(
Data=train_data,
actions_list=self.config.agent_possible_actions,
internal_states_initialValue=self.config.internalStates_InitialVal,
environment_variables=self.config.environment_variables
)
train_environment = DummyVecEnv([lambda: TheEnvironment(env_config)])
agent_config = AgentConfig(total_timesteps=self.config.train_total_timesteps,
environment=train_environment,
validation_timesteps=self.config.validation_timesteps
)
agent = PPOAgent(agent_config)
# 训练代理:
agent.train()
# 代理验证阶段
val_data = pd.read_csv(Path(self.config.val_data_path))
val_env_config = EnvironmentConfig(
Data=val_data,
actions_list=self.config.agent_possible_actions,
internal_states_initialValue=self.config.internalStates_InitialVal,
environment_variables=self.config.environment_variables
)
val_environment = DummyVecEnv([lambda: TheEnvironment(val_env_config)])
# 评估代理性能
Reward, accumulative_reward = agent.validate()
# 保存训练完毕的代理模型
agent.save_trained_agent()
return train_environment, val_environment, agent, Reward, accumulative_reward
def test_agent(self):
test_data = pd.read_csv(Path(self.config.test_data_path))
# 创建环境配置
env_config = EnvironmentConfig(
Data=test_data,
actions_list=self.config.agent_possible_actions,
internal_states_initialValue=self.config.internalStates_InitialVal,
environment_variables=self.config.environment_variables
)
test_environment = DummyVecEnv([lambda: TheEnvironment(env_config)])
agent_config = AgentConfig(total_timesteps=self.config.test_timesteps,
environment=test_environment,
validation_timesteps=self.config.validation_timesteps,
train_timesteps=self.config.train_total_timesteps
)
agent = PPOAgent(agent_config)
# 加载预训练的代理
if self.config.use_pretrained_agent:
agent.load_trained_agent()
accum_reward = np.zeros(self.config.test_timesteps)
Rewards = np.zeros(self.config.test_timesteps)
accum_reward_perstep = 0
observation_space = []
obs = test_environment.reset()
for ii in range(self.config.test_timesteps):
action = agent.predict(obs)
obs, reward, done, info = test_environment.step(action)
Rewards[ii] = reward
accum_reward_perstep += reward
accum_reward[ii] = accum_reward_perstep
observation_space.append(obs)
if done:
obs = test_environment.reset()
return accum_reward,Rewards, observation_space完整的代码和流程可在github上获取。我们可以通过将仅训练了10k步的智能体作为基线,并与训练了500k步的智能体的表现进行对比,来测试智能体处理测试数据的能力。下面是一张显示累积奖励的图,显示了两者的显著差异。仅训练了10k步的智能体的行为几乎等同于随机行动,累积奖励持续下降。而训练了500k步的智能体已经学会了如何操作以增加累积奖励,使发电厂运行在盈利而非亏损状态。

即使没有对模型的超参数设定进行微调,它实际上已经做得相当不错了。我们还可以进一步优化模型,以获得更好的效果。
这标志着本文的结束。强化学习是人工智能中最令人兴奋且尚不成熟的发展之一,看到这一领域的发展及其在解决不同问题中的应用将会非常令人激动。最后,感谢您花时间阅读本文,希望本文能对您理解强化学习或其数学背景有所帮助。本文仅是一篇简要的介绍,还有很多关于支持强化学习的基本概念可以阅读。
除非特别说明,所有照片都是作者拍的





