
检索增强生成(RAG)在大型语言模型的工作流程中增加了一个检索步骤,使模型能够从私人文档等额外来源中查询相关数据,以回答问题和查询[1]。这种工作方式不需要对额外文档进行昂贵的训练或微调大型语言模型(LLM)。文档被分割为片段,这些片段随后被索引并存储,通常使用紧凑的机器学习生成的向量表示(嵌入)。内容相似的片段在嵌入空间中彼此靠近。
RAG应用将用户提供的问题投影到嵌入空间中,根据问题与文档片段的距离来检索相关文档片段。大型语言模型可以使用检索到的信息来回答问题,并通过引用片段来支持其结论。
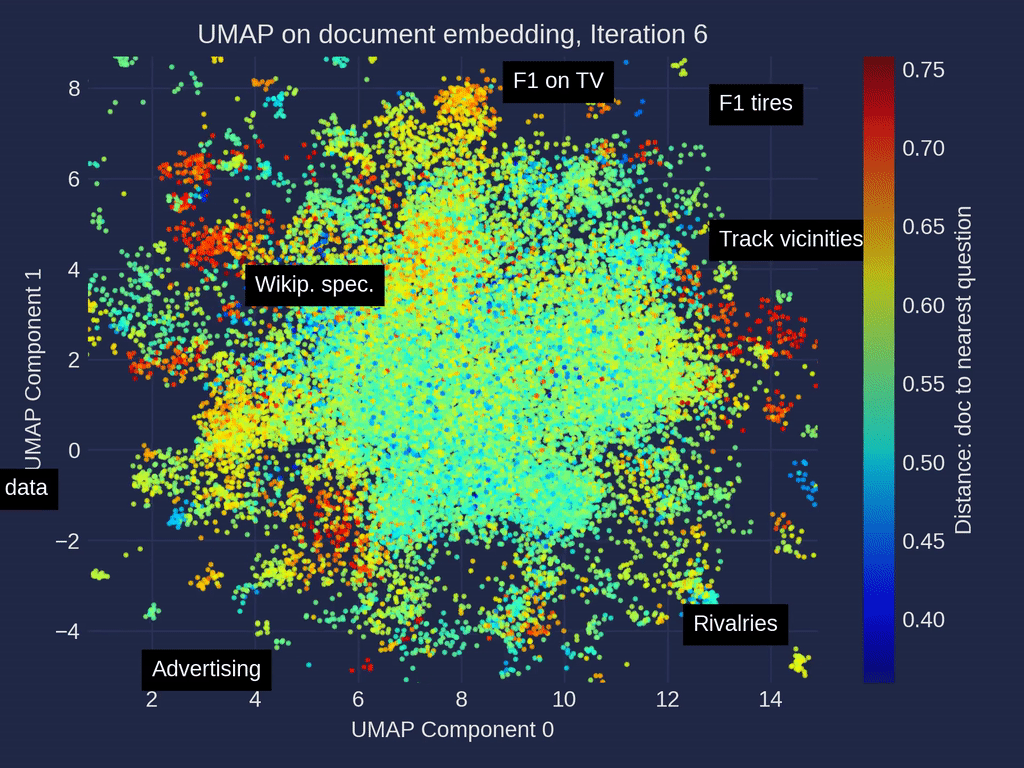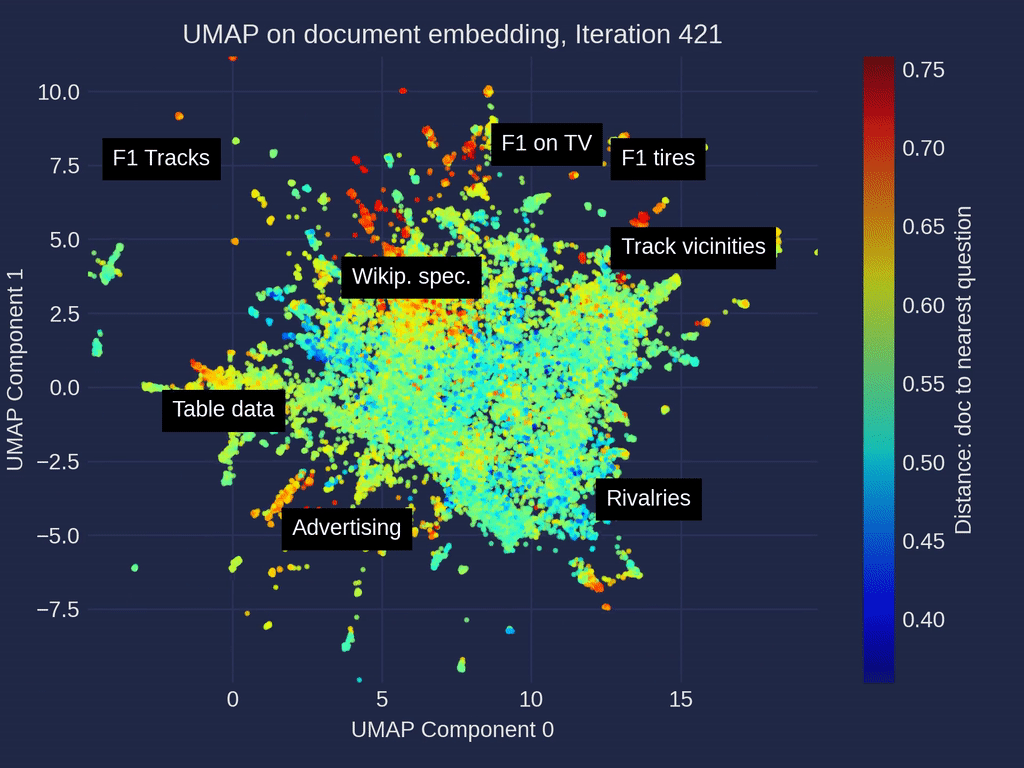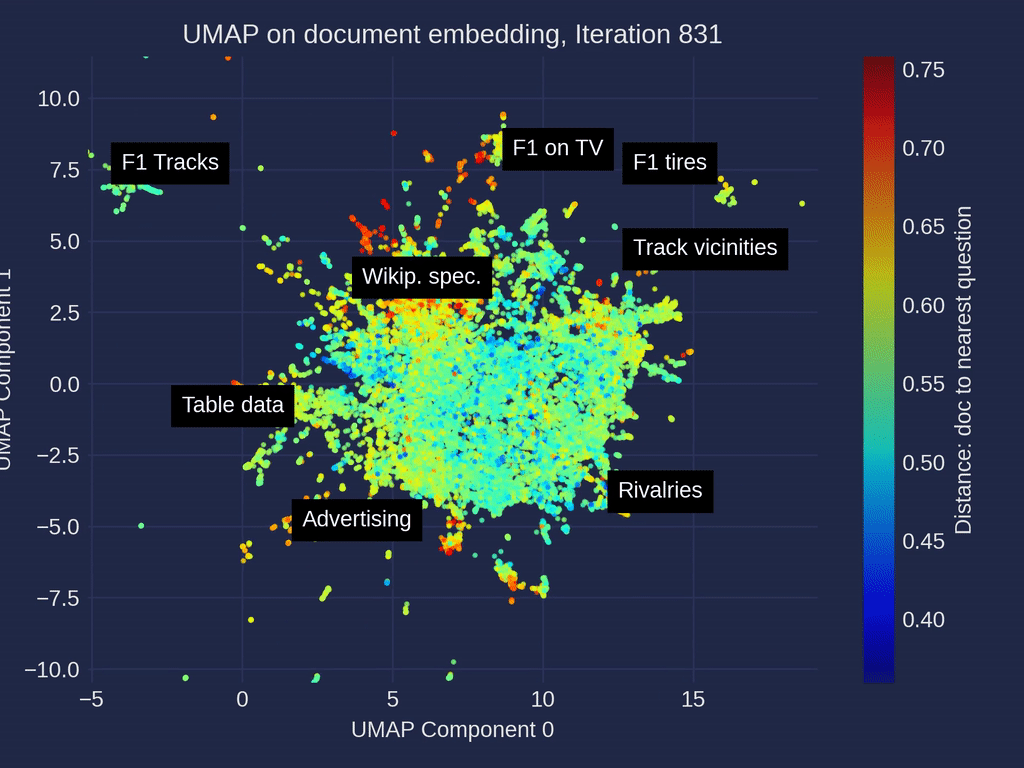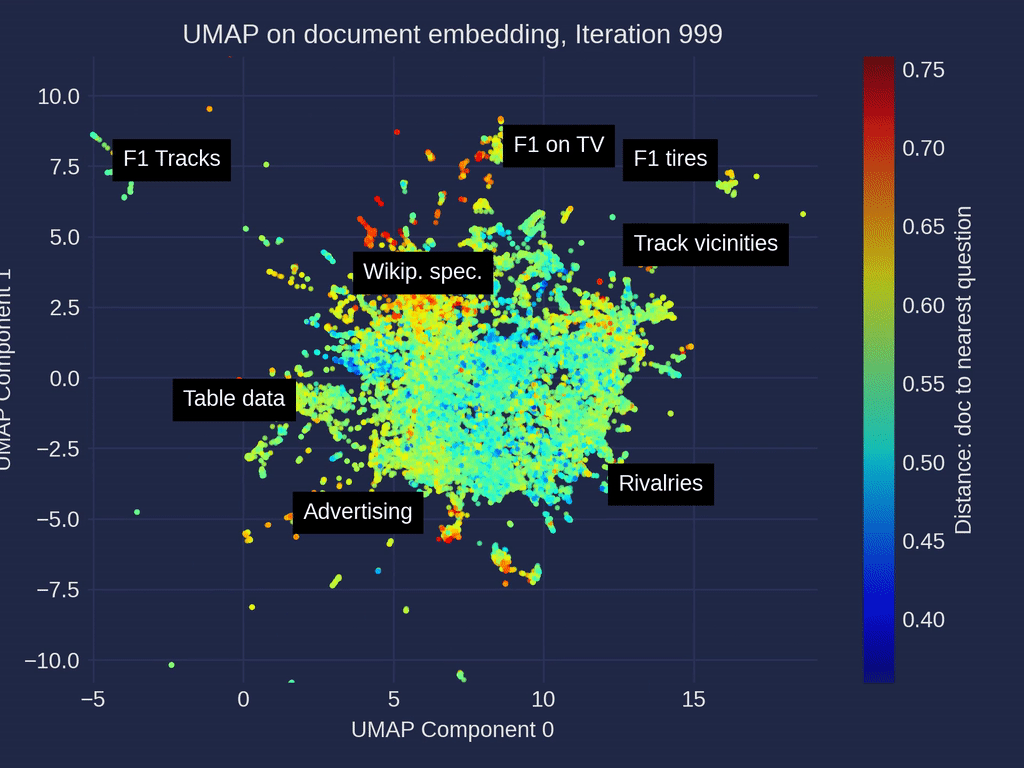
维基百科一级方程式相关文章的UMAP [3]降维迭代的动画——在嵌入空间里,带有手动标注的聚类,由作者制作。
评估一个RAG应用是有挑战性的[2]。存在不同的方法:一方面,答案作为真实基准的答案必须由开发者提供;另一方面,答案(以及问题)也可以由另一个大型语言模型生成。其中一个最大的开源系统之一是Ragas[4](https://medium.com/Retrieval-Augmented Generation Assessment),它提供的增强检索生成评估。
- 基于文档生成测试数据的方法(或过程)
- 根据不同的指标分别评估检索和生成步骤,以及整体的端到端评估
注:星号在Markdown中表示项目列表,但在纯文本中可以移除星号。
在这篇文章中,你将学到
- 如何简要地构建一个用于一级方程式赛车(参见前文可视化你的RAG数据——用于检索增强生成的EDA以获取详细描述)的RAG系统
- 生成问题和答案
- 使用Ragas评估RAG系统的效果
- 最重要的是如何使用Renumics Spotlight来可视化和解释结果。
准备好你的环境吧代码可在Github上找到,具体地址为这里[https://github.com/Renumics/renumics-rag/blob/main/notebooks/visualize_rag_tutorial_qs.ipynb]_
开启一个笔记本并安装所需的Python库。
!pip install langchain langchain-openai chromadb renumics-spotlight
%env OPENAI_API_KEY=<你的-api-key> # 请替换为你的实际API密钥本教程将使用以下 Python 包:
- Langchain: 一个集成语言模型和RAG组件的框架,使设置过程更加简单流畅。
- Renumics-Spotlight: 一个交互式探索非结构化的机器学习数据集的可视化工具。
-
Ragas: 一个帮助你评估RAG管道框架的工具。
本文声明:本文作者也是Spotlight的开发者。
你可以跳到下面的部分,了解如何评估、提取和展示结果。使用自己的RAG应用。
或者你可以使用上文提到的 RAG 应用程序,该应用使用了我们准备的包含所有维基百科一级方程式相关文章的数据集(链接)。你可以使用该应用来处理你的数据,也可以将自己的文档插入该应用中的‘docs/’文件夹。
该数据集基于来自维基百科的文章,并根据CC 知识共享 署名-相同方式共享许可协议授权。原始文章及其作者名单可在相应的维基百科页面上查看。
你现在可以用Langchain的DirectoryLoader加载docs子目录中的所有文件,并将其分割成片段。使用OpenAIEmbeddings,你可以创建嵌入并向量存储在ChromaDB中。对于Chain部分,你可以使用LangChain的ChatOpenAI和ChatPromptTemplate。
本文的相关代码包含了所有必需的步骤,你可以在我们之前的文章中找到所有步骤的详细说明内容。
重要的一点是,你应该使用哈希为 ChromaDB 中的内容创建 id。这样如果你只有文档的内容及元数据,就能在数据库中找到相关嵌入。这样就能跳过数据库中已有的文档。
import hashlib
import json
from langchain_core.documents import Document
def 生成稳定的元数据哈希值(doc: Document) -> str:
"""
根据文档的元数据生成稳定的哈希值。
"""
return hashlib.sha1(json.dumps(doc.metadata, sort_keys=True).encode()).hexdigest()
...
splits = text_splitter.拆分文档(docs)
splits_ids = [
{"doc": split, "id": 生成稳定的元数据哈希值(split.metadata)} for split in splits
]
existing_ids = docs_vectorstore.get()["ids"] # 获取已存在的文档ID
new_splits_ids = [split for split in splits_ids if split["id"] not in existing_ids]
docs_vectorstore.add_documents(
documents=[split["doc"] for split in new_splits_ids],
ids=[split["id"] for split in new_splits_ids],
)
# 保存向量存储到持久化存储中
docs_vectorstore.persist()对于像一级方程式这样的热门话题,也可以直接用ChatGPT来生成一些问题。本文使用了四种提问的方法如下:
- GPT4 : 使用ChatGPT 4根据提示“写30个关于一级方程式的问题”,生成了30个问题
– 随机示例: “哪个一级方程式车队以其跃马标志而闻名?” - GPT3.5 : 使用ChatGPT 3.5根据提示“写100个关于一级方程式的问题”生成了199个问题,然后再次请求生成100个问题
– 示例: “哪位车手赢得了1950年首届一级方程式世界锦标赛?” - Ragas_GPT4 : 使用Ragas利用文档及其嵌入模型构建了一个向量数据库,然后利用GPT4生成问题。
– 示例: “乔丹198一级方程式赛车在1998年世界锦标赛中的表现如何?” - Rags_GPT3.5 : 使用Ragas和GPT3.5生成了226个额外问题
– 示例: “2014年比利时大奖赛中发生了什么事件导致汉密尔顿退出比赛?”
from ragas.testset import TestsetGenerator
generator = TestsetGenerator.from_default(
openai_generator_llm="gpt-3.5-turbo-16k",
openai_filter_llm="gpt-3.5-turbo-16k"
)
testset_ragas_gpt35 = generator.generate(docs, 100)这些问题没有经过任何审查或修改。所有问题都合并到一个数据帧中,,包含的列有 id,question,ground_truth,question_by 和 answer。

接下来,这些问题将被提交给RAG系统处理。当问题数量超过500个时,这可能需要一段时间且会产生费用。如果你一次只问一个问题,你可以随时暂停和继续,或者在出现问题后恢复而不会丢失已有的结果。
遍历数据帧 `df_questions_answers` 中的每一行:for i, row in df_questions_answers.iterrows():
如果 row["answer"] 为 None 或 pd.isnull(row["answer"]):
response = rag_chain.call(row["question"])
df_questions_answers.loc[df_questions_answers.index[i], "answer"] = response["answer"]
df_questions_answers.loc[df_questions_answers.index[i], "source_documents"] = [stable_hash_meta(source_document.metadata) for source_document in response["source_documents"]]其中,`rag_chain.call(row["question"])` 表示调用 `rag_chain` 对问题进行处理,并获取回答。`df_questions_answers.loc[df_questions_answers.index[i], "answer"]` 表示更新数据帧中的回答,`df_questions_answers.loc[df_questions_answers.index[i], "source_documents"]` 表示更新数据帧中的源文档哈希值。不仅答案被存储,还存储了检索到的文档片段的源ID(原文ID)及其文本内容作为上下文信息。

此外,所有问题的嵌入也被生成并存储在数据帧中。这使得我们可以将它们与文档一起进行可视化。
基于拉加斯的评估用拉加斯进行评估
Ragas 提供了评估您 RAG 管道中每个部分的指标,以及用于整体性能的端到端评估指标:
- 上下文精确度: 使用
问题和检索到的上下文来衡量信噪比值。 - 上下文相关性: 使用
问题和上下文来计算检索到的上下文与问题的相关性。 - 上下文召回: 根据
真实情况和上下文来检查是否检索到了所有与答案相关的信息。 - 忠实度: 利用
上下文和答案来衡量生成答案的事实准确度。 - 答案相关性: 通过
问题和答案来评估答案与问题的相关性(不考虑事实准确性)。 - 答案语义相似度: 使用
真实情况和答案来评估生成的答案与正确答案的语义相似度。 - 答案正确性: 根据
真实情况和答案来衡量生成的答案与正确答案的准确性。 - 方面批评: 通过分析
答案来基于预定或自定义的方面对提交进行评估。
目前,我们的重点是端到端的答案正确性指标。数据框中的列名和内容会复制并调整,以符合Ragas API的命名和格式要求。
# 准备问题和答案的数据框进行评估
df_qa_eval = df_questions_answers.copy()
# 将真实答案数据调整为ragas的命名和格式
df_qa_eval.rename(columns={"ground_truth": "ground_truths"}, inplace=True)
# 将数据框列名从“ground_truth”更改为“ground_truths”
df_qa_eval["ground_truths"] = [
[gt] if not isinstance(gt, list) else gt for gt in df_qa_eval["ground_truths"]
]这可能还需要更多的时间和金钱,甚至超过单纯查询你的RAG模型。让我们逐行评估,以确保在系统崩溃后能够恢复而不会丢失之前的结果。
# 如果没有评估答案正确性的话,现在就评估一下
fields = ["question", "answer", "contexts", "ground_truths"]
for i, row in df_qa_eval.iterrows():
if row["answer_correctness"] is None or pd.isna(row["answer_correctness"]):
evaluation_result = evaluate(
Dataset.from_pandas(df_qa_eval.iloc[i : i + 1][fields]),
[answer_correctness],
)
df_qa_eval.loc[i, "answer_correctness"] = evaluation_result["答案正确性"]之后,你可以将结果存储在 df_questions_answer 这个数据框中:
df_questions_answers["answer_correctness"] = df_qa_eval["answer_correctness"] # 将df_qa_eval中的'answer_correctness'列赋值给df_questions_answers中的'answer_correctness'列。为了将文档片段包含在可视化中,我们为文档添加引用,这些引用指向了将该文档作为来源的问题。此外,引用该文档的问题数量也被记录下来。
# 将 'source_documents' 展开,使每个文档 ID 都单独成一行并与问题 ID 对应
df_questions_exploded = df_qa_eval.explode("source_documents")
# 按展开后的 'source_documents'(文档 ID)分组并聚合
agg = (
df_questions_exploded.groupby("source_documents")
.agg(
num_questions=("id", "count"), # 引用文档的问题数
question_ids=(
"id",
lambda x: list(x), # 引用该文档的问题 ID 列表
),
)
.reset_index()
.rename(columns={"source_documents": "id"})
)
# 将聚合后的信息合并回 df_documents
df_documents_agg = pd.merge(df_docs, agg, on="id", how="left")
# 使用 apply 函数将 'question_ids' 中的缺失值替换为列表
df_documents_agg["question_ids"] = df_documents_agg["question_ids"].apply(
lambda x: x if isinstance(x, list) else []
)
# 将 'num_questions' 中的缺失值替换为 0
df_documents_agg["num_questions"] = df_documents_agg["num_questions"].fillna(0)现在把问题数据和文档数据合并在一起。
# 将df_qa_eval和df_documents_agg按行合并到df中
df = pd.concat([df_qa_eval, df_documents_agg], axis=0)此外,让我们准备一些不同的UMAP [3]映射方法。你也可以在稍后的Spotlight GUI中做类似的操作,但提前准备好可以节省时间。
- umap_all: UMAP 对所有文档和问题嵌入同时应用 fit 和 transform
- umap_questions: UMAP 只对问题嵌入应用 fit,然后对文档和问题嵌入都应用 transform
- umap_docs: UMAP 只对文档嵌入应用 fit,然后对文档和问题嵌入都应用 transform
我们这样准备每个UMAP变换的步骤:
umap = UMAP(n_neighbors=20, min_dist=0.15, metric="cosine", random_state=42).fit
umap_all = umap.transform(df["embedding"].values.tolist())
df["umap"] = umap_all.tolist() 对于每个文档片段来说,另一个有趣的指标是它与最接近的问题嵌入之间的距离。
question_embeddings = np.array(df[df["question"].notna()]["embedding"].tolist())
df["nearest_question_dist"] = [ # 可以考虑用ChromaDB来进行优化,而不是使用暴力法
np.min([np.linalg.norm(np.array(doc_emb) - question_embeddings)])
for doc_emb in df["embedding"].values
]这个指标可以帮助找到没有被问题引用的文档。

如果你之前没有完成这些步骤,你可以下载数据文件并使用以下代码加载它。
import pandas as pd # 这里我们导入pandas库,并读取一个名为“df_f1_rag_docs_and_questions.parquet”的parquet文件
df = pd.read_parquet("df_f1_rag_docs_and_questions.parquet")然后启动Renumics Spotlight,用它来进行可视化。
from renumics import spotlight
spotlight.show(df)
spotlight.show(
df,
layout="/home/markus/Downloads/layout_rag_1.json",
dtype={x: Embedding for x in df.keys() if "umap" in x},
)它将打开一个新的浏览器标签页。
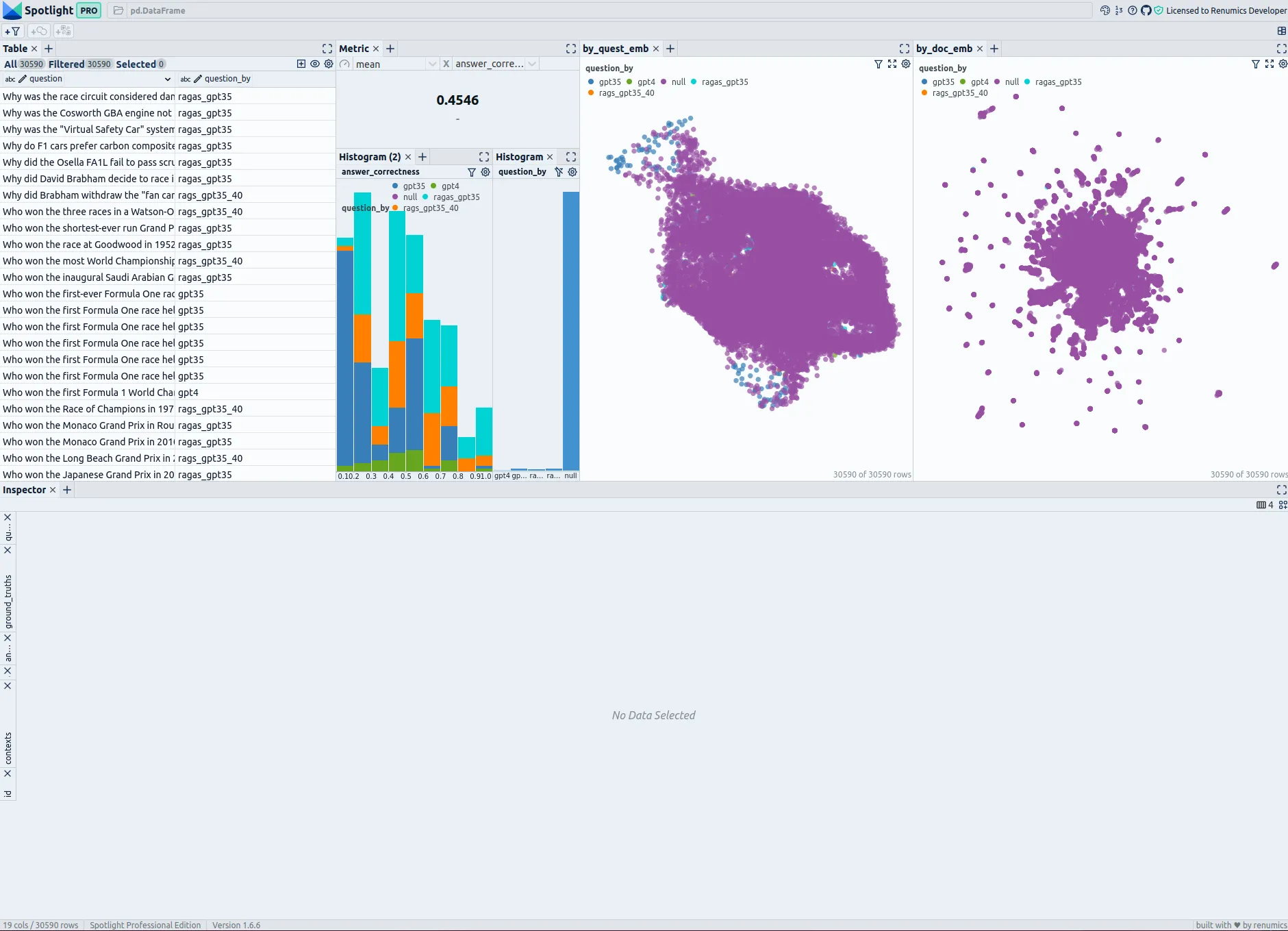
一级方程式文档和评估问题统计资料及相似性地图及相似度分析——由作者使用Renumics Spotlight工具创建。
在左上角,你可以看到一个包含所有问题及其文档片段的表格。你可以使用“显示列”按钮来控制哪些列在表格中显示。创建一个直接筛选问题的筛选器非常有用,这样你可以在可视化中选择显示或隐藏问题:先选中所有问题,然后通过“从选定行创建筛选器”按钮创建筛选器。
表格的右侧显示了所有问题的正确率作为指标。下方有两个柱状图;左边的柱状图展示了按不同生成方法划分的正确率分布,而右边的柱状图展示了不同的生成方法。如果你需要查看某个特定的问题,建议使用筛选按钮,只显示你需要的问题。
在右方,有两个相似性图。第一个使用了 umap_questions 列,展示了仅对问题进行转换后的问题和文档。这有助于独立查看问题的分布,不受相关文档的影响,这种方法让分析人员能够识别问题中的模式或聚类。
第二个相似度映射仅基于只应用于文档(umap_docs)的变换,展示问题和文档。它有助于在相关文档的背景下更好地理解问题。同时对问题和文档进行变换的相似度映射在问题数量较多时效果较差,因为更多的或更少的问题会被聚类,与文档分离。因此,这里不再展示这种表示方法。

一级方程式的评估统计和相似性地图:由作者利用该工具Renumics Spotlight创建
文档嵌入相似度图:一些观察在相似性映射 umap_docs 中,你可以识别出文档嵌入空间中没有邻近问题的区域。当使用 nearest_question_dist 进行着色时,这些区域在这种情况下更容易被识别。

一级方程式文档和问题的相似度图(高亮部分)——由作者, 使用Renumics Spotlight创建
一些集群可以被识别,包括仅包含标题的片段或页面中仅含数字的表格数据,在分割过程中这些片段会失去其意义。此外,许多维基百科特有的文本添加,例如其他语言的链接或编辑注释,这些文本包含无关信息,形成了没有相邻的问题的集群。
使用维基百科 API 删除与维基百科相关的文本噪音非常简单。这可能并不是特别必要,因为它主要占用了一些空间——并不期望 RAG 的结果会因此显著恶化。然而,大型表格中的数据很难被 RAG 系统捕获到,使用高级预处理方法提取这些数据并与 RAG 系统连接可能会有所帮助。
你还可以观察到 umap_docs 相似度地图中,不同来源的问题是如何分布的状况。


左边:ChatGPT(GPT-3.5 和 GPT-4)产生的问题,右边:用 ragas 和 GPT-3.5、GPT-4 生成的问题 — 作者用 Renumics Spotlight 创建
ChatGPT(GPT-3.5,GPT-4)直接生成的问题集中在中心的一个较小区域,相比之下,基于文档的问题则覆盖了更大的范围。
答案正确率分布图直方图可以作为一个起点,帮助我们初步了解数据的整体统计情况。例如,所有问题的答案正确性为0.45。对于未使用ragas生成的问题,该值为0.36,而对于使用了ragas生成的问题,该值为0.52。预期系统对由ragas生成的问题表现更好,因为这些问题是基于可用数据创建的,而直接由ChatGPT生成的问题则可能基于它训练的所有数据。

根据答案正确性绘制的直方图,按问题的来源着色,由作者制作。
快速浏览了一些问题和答案后发现,根据标准答案,在answer correctness值在0.3至0.4之间的区间内,大多数问题仍然被正确回答了。在0.2至0.3区间内,许多答案不正确。在0.1至0.2区间内,大多数答案错误。值得注意的是,这个范围内几乎所有的问答都是由GPT-3.5生成的。然而,在这个区间,虽然由GPT-4生成的两个问题的answer correctness低于0.2,它们也被正确回答了。
问题相似性嵌入图通过分析相似问题集群来深入探究答案正确性,有助于我们更好地理解这些问题。
- 集群“与驾驶员/进程/汽车相关的术语”: 平均
答案正确性0.23:答案通常不够精确。例如,悬挂调校与底盘弯曲或刹车偏置调整与刹车分配调整的区别。似乎很难评估这些问题是否适合系统评估。 - 集群“燃油策略的术语”: 平均
答案正确性0.44,与全局答案正确性相似。 - 集群“赛道名称”: 平均
答案正确性0.49,与全局答案正确性相似。 - 集群“谁保持了…”的记录: 平均
答案正确性0.44,与全局答案正确性相似。 - 集群“使用…赢得冠军”: 平均
答案正确性0.26 — 看起来很有挑战性。例如,“唯一持有英国赛车执照、为意大利车队驾驶、使用美国引擎赢得F1世界冠军的是谁?”可以尝试使用多查询等扩展RAG方法来提高正确率。 - 集群“唯一驾驶带有编号<编号>的汽车赢得冠军的车手”: 平均
答案正确性0.23 — GPT-3.5在这里似乎表现得不够认真,重复相同的问题,尽管大多数正确的答案都未被正确识别!

由作者创建的一级方程式问题(如需查看,高亮显示)与文档的相似性图
结论部分总之,利用UMAP基础的可视化提供了一种有趣的方法,可以深入分析,而不仅仅是依赖全局指标的分析。文档嵌入相似性地图提供了一个很好的概览,显示了相似文档的聚类以及它们与评估问题的关系。问题相似性地图揭示了模式,这些模式允许我们结合质量指标对问题进行区分和分析,从而产生新的见解。请跟随“可视化结果”部分,在您的评估策略中应用这些可视化工具——您将会发现什么?
我是一名专业人士,擅长为非结构化数据的互动探索开发高级软件解决方案。我写关于非结构化数据的文章,并利用强大的可视化工具进行分析,从而做出明智的决策。
参考资料[1] 高云凡,熊云,高欣宇,贾康翔,潘锦流,毕宇曦,戴伊,孙佳蔚,郭千语,王梦,王浩矾. 《大型语言模型中检索增强生成的综述》, arxiv (2024)
[2] 汤逸轩, 杨懿: MultiHop-RAG: 多跳问题的检索增强生成基准测试 (2024), arXiv
[3] Leland McInnes, John Healy, James Melville: UMAP: 流形均匀近似和投影降维 (2018), arXiv
[4] Shahul Es, Jithin James, Luis Espinosa-Anke, Steven Schockaert: RAGAS: 检索增强生成的自动化评估 (2023 年), arXiv





