
使用SQLModel、Alembic和Pydantic V2这些工具,将您的FastAPI应用程序连接到PostgreSQL数据库中。

照片由 Gautam Arora 拍摄,来自 Unsplash
全栈应用部署指南系列这是系列文章的第五篇,详细介绍了如何使用Pulumi在AWS上搭建一个生产级别的全栈Web应用,以满足我们的基础设施即代码(IaC)要求。第一篇文章包含代码和设置指导,我们会在后续的文章中进一步发展这些内容。我尽量使每篇文章都能独立阅读,但有时你可能需要参考其他文章中的代码和背景信息。
本文将仅介绍如何在本地环境中设置FastAPI应用和PostgreSQL数据库。数据库集成是一项复杂的工作,将在后续的文章中详细讨论。本文不是FastAPI或其他所用工具的入门介绍。如果您是首次接触这些工具,我建议查看FastAPI的官方文档和许多入门教程。相反,我将重点讲述如何连接数据库,并介绍一些在开发较大规模FastAPI项目时的简便方法。
- 使用Route53、CloudFront和S3在AWS上部署生产级别的静态站点(使用Pulumi基础设施即代码(IaC))
- 简化无服务器——使用AWS Lambda函数URL部署基于Docker的API服务。无需API网关!
- 保护无服务器——使用API网关和WAF通过Pulumi IaC保护Lambda应用
- 使用Pulumi IaC通过AWS托管规则为WAF v2保护您的应用
- 这篇文章
- 待定——也许添加集成测试数据库功能
- 待定——也许将数据库添加到AWS
- 待定——也许添加CI/CD工具
- 待定——也许添加一个身份验证即服务(Auth-as-a-Service)提供商
∘ 全栈应用部署系列
∘ 先决条件
∘ 我们要构建的应用
∘ 大的改动意味着小的头痛
∘ 项目结构
∘ 添加基础模型和你的第一个模型
∘ FastAPI 应用及数据库连接设置
∘ Docker Compose 和 Makefile(构建工具)
∘ 数据库迁移由 Alembic 来管理
∘ 创建 API 和数据库相关功能
∘ 见证神奇时刻
- 这是一个中级到高级的教程,要求你已经有使用Python、数据库和API的经验。
- 熟悉FastAPI、SQLModel、Pydantic、SQLAlchemy和Alembic(或愿意通过网络搜索了解这些工具)
- 熟悉Docker和Docker Compose的使用
- 本地运行的、基于 Docker 的 FastAPI Python 应用
- 本地运行的、基于 Docker 的 PostgreSQL 数据库
- 使用 Alembic 进行数据库迁移
SQLModel,根据其文档所述,是“建立在Pydantic和SQLAlchemy之上的轻薄层,精心设计以兼容两个库。”它由FastAPI的作者创建并维护,并旨在成为FastAPI的ORM。从我开始写这个博客系列到现在,Pydantic和SQLAlchemy都发布了它们库的新主要版本。SQLModel现已集成了这两个新版本,导致了一些不兼容变更。这篇博客将展示如何使用SQLModel的最新版本(发布时为v.0.0.22)。
项目结构完成本教程后,在项目根目录下你会看到以下内容:
<PROJECT-ROOT>
├── Dockerfile
├── docker-compose.yml
├── Makefile
├── .env
├── .example.env
├── alembic
│ ├── README
│ ├── env.py
│ ├── script.py.mako
│ └── versions
│ ├── 52306dc8a73f_create_item_table.py
├── alembic.ini
├── local.Dockerfile
├── requirements.txt
└── src
├── __init__.py
├── api
│ ├── __init__.py
│ ├── deps.py
│ ├── items.py
│ └── schemas
│ ├── __init__.py
│ ├── base.py
│ └── item.py
├── crud
│ ├── __init__.py
│ ├── base.py
│ └── item.py
├── main.py
├── models
│ ├── __init__.py
│ ├── base.py
│ ├── item.py
│ └── session.py
└── utils
├── __init__.py
├── config.py
├── exception_handling.py
└── service_logging.py几年前,我复制了官方的 FastAPI 全栈项目。从那以后,我根据自己的需求和偏好对其进行了调整,但大部分的组织结构,特别是 crud/base.py 文件里的代码,都是直接从那个项目中来的。FastAPI 文档中仍然有一个全栈模板,可能更适合您的需求。您可以在那里找到:https://fastapi.tiangolo.com/project-generation/
先让我们把FastAPI装上,并准备好初始的文件和目录。使用pip或您喜欢的包管理工具安装以下这些包。
在 requirements.txt 文件中添加以下行,然后运行 pip install -r requirements.txt 命令。查找并替换为列出的包的最新版本,以确保使用最新版本的包。
下面是项目的依赖项列表:
alembic==1.13.2
fastapi==0.115.0
mangum==0.18.0
psycopg2-binary==2.9.9
pydantic[email] # pydantic的email插件
pydantic-settings==2.5.2
pytest==8.3.3
python-json-logger==2.0.7
SQLAlchemy==2.0.35
sqlmodel==0.0.22
uvicorn==0.30.6在 /models/base.py 中,我定义了两个基础模型类。一个用于一般的 SQLModel 场景,另一个则是定义数据库表的模型。它们在所有模型中标准化了一些行为和规则,使某些操作更加方便。
import uuid
from datetime import datetime
from pydantic import ConfigDict
from sqlalchemy import Column, DateTime, func
from sqlmodel import Field, SQLModel
class BaseSQLModel(SQLModel):
model_config = ConfigDict(
arbitrary_types_allowed=True, from_attributes=True, extra="ignore"
)
class BaseDatabaseModel(SQLModel):
model_config = ConfigDict(
arbitrary_types_allowed=True, from_attributes=True, extra="ignore"
)
id: uuid.UUID = Field(default_factory=uuid.uuid4, primary_key=True)
created: datetime | None = Field(
sa_column=Column(DateTime(timezone=True), server_default=func.now())
)
updated: datetime | None = Field(
sa_column=Column(
DateTime(timezone=True), server_default=func.now(), onupdate=func.now()
)
)
is_active: bool = True如果你熟悉 Pydantic 和/或 SqlAlchemy,你会在这两个类中看到它们的元素。在两个基础模型中,我设置了 Pydantic 的 ConfigDict,以允许模型中使用任意类型。这让你可以在模型中使用非 Pydantic 类型。from_attributes 基本上是 Pydantic v1 中 from orm 的替代方案。设置 extra="ignore" 表示如果模型接收到一个不存在的属性,它会直接忽略,而不会报错。
现在有了基础模型,我们可以利用它们来帮助定义第一个模型,该模型将映射到第一个数据库表。为了保持事情有趣,我们选择第一个模型为Item模型。以下是/models/item.py文件:
from datetime import datetime
import uuid
from src.models.base import BaseDatabaseModel, BaseSQLModel
from sqlalchemy import Column, Text
from sqlmodel import Field
class ItemBase(BaseSQLModel):
title: str
description: str
class Item(ItemBase, BaseDatabaseModel, table=True):
title: str = Field(sa_column=Column(Text, unique=True))
class ItemCreate(ItemBase):
pass
class ItemRead(ItemBase):
id: uuid.UUID
is_active: bool
updated: datetime
class ItemUpdate(ItemBase):
id: uuid.UUID
is_active: boolItemBase 继承 BaseSQLModel 并定义了 title 和 description 属性,因为其他所有 Item<> 类都需要这些属性。Item 类继承自 ItemBase 和 BaseDatabaseModel,并将 table 参数设为 True。这意味着 Item 表将包含这些父类定义的所有列。我在 Item 类中重写了 title,以便可以给它加上唯一约束。
Pydantic 的 BaseSettings 被 FastAPI 用于通过环境变量来配置设置,这样你就可以根据 12 因素应用的建议将配置存储在环境中。这些设置位于 /src/utils/config.py 文件里,文件内容如下:
from typing import Any
from pydantic import (
AnyHttpUrl,
PostgresDsn,
field_validator,
)
from pydantic_core.core_schema import ValidationInfo
from pydantic_settings import BaseSettings
class Settings(BaseSettings):
PROJECT_NAME: str = "这里填写您的项目名称"
BACKEND_CORS_ORIGINS: list[AnyHttpUrl] = []
ENV_NAME: str = "local"
POSTGRES_SERVER: str
POSTGRES_USER: str
POSTGRES_PASSWORD: str
POSTGRES_DB: str
SQLALCHEMY_DATABASE_URI: PostgresDsn | None = None
@field_validator("SQLALCHEMY_DATABASE_URI")
@classmethod
def 组装数据库连接(cls, v: str | None, values: ValidationInfo) -> Any:
# 如果v是字符串类型:
if isinstance(v, str):
return v
postgres_dsn = PostgresDsn.build(
scheme="postgresql",
username=values.data.get("POSTGRES_USER"),
password=values.data.get("POSTGRES_PASSWORD"),
host=values.data.get("POSTGRES_SERVER"),
path=values.data.get("POSTGRES_DB"),
)
return postgres_dsn.unicode_string()
AWS_LAMBDA_INITIALIZATION_TYPE: str = "不是Lambda"
# 设置实例化
settings = Settings()我很喜欢你只需确保你的环境变量和 config.py 中对应的变量名一致,这样就不需要使用 os.environ.get("ENV_VAR_XYZ", "DEFAULT") 进行获取了。只要两边一致,应用会自动将变量设置为环境变量中的值。需要注意的是,环境变量只能是字符串,这意味着你需要将字符串形式的值转换为相应的数据类型,比如将 "True" 转换为布尔值 True。另外,在 Pydantic V2 中,Pydantic Settings 已经变成一个独立的库(pydantic-settings),需要将其包含在项目依赖项中。
Docker 和 Docker Compose 可以帮助简化带有数据库和其他服务的应用程序的本地开发,同时也能带来更接近生产环境的开发体验。因为我还用 Docker 打包我的应用以部署在 AWS Lambda 上,所以我用 local.Dockerfile 和 docker-compose.yml 文件。
# local.Dockerfile
FROM python:3.12.3
ENV PYTHONUNBUFFERED 1
ENV PYTHONDONTWRITEBYTECODE 1
ENV PIP_ROOT_USER_ACTION=ignore
# 更新软件包列表并安装必要的开发工具
RUN apt-get update && \
apt-get install -y \
g++ \
gcc \
make \
cmake \
unzip \
libcurl4-openssl-dev
# 创建一个名为app的目录
RUN mkdir app
# 设置工作目录为app
WORKDIR app
# 复制requirements.txt文件到工作目录
COPY requirements.txt ./
# 升级pip到最新版本
RUN python3.12 -m pip install --upgrade pip
# 使用pip安装requirements.txt中列出的所有依赖包
RUN python3.12 -m pip install -r requirements.txt --use-pep517
# 复制当前目录的所有内容到工作目录
COPY . .以及 Docker Compose 文件:
(注:此处直接介绍文件,无需添加额外说明)
version: "3.8"
services:
api:
container_name: api
tty: true
stdin_open: true
build:
context: 上下文: .
dockerfile: local.Dockerfile # 使用local.Dockerfile作为构建文件
command: 启动命令:使用uvicorn启动应用程序,并设置热重载、代理头、主机和端口
ports:
- "8000:8000"
volumes:
- .:/app # 将当前目录挂载到容器中
env_file:
- .env # 设置环境变量文件
depends_on:
- db # 依赖于数据库容器
db:
container_name: db
image: postgres:13
volumes:
- db_data:/var/lib/postgresql/data # 数据库数据持久化存储
env_file:
- .env # 设置环境变量文件
ports:
- "5432:5432"
volumes:
db_data: # 数据库持久化存储卷Makefile 实际上只是为常用的命令创建快捷方式的一种简便方法。这里有个 Makefile:
ENV_NAME ?= dev
SERVICE_NAME = <NAME OF YOUR APP>
BRANCH_NAME ?= $(shell git rev-parse --abbrev-ref HEAD)
up:
docker-compose -f docker-compose.yml up -V -d $(c)
down:
docker-compose -f docker-compose.yml down $(c)
create-migration:
ifdef message
cd backend; \
alembic revision --autogenerate -m "$(message)"
else
@printf '请使用 "make create-migration message=消息内容",例如:make create-migration message="添加用户表"\n'
endif
run-migration:
cd backend; \
alembic upgrade head
undo-migration:
cd backend; \
alembic downgrade -1运行 make up 来启动 Docker 容器实例。访问 http://localhost:8000/api/docs,你会看到 API 文档页面。访问 GET items 端点,会收到一个 500 错误。如果你想查看 Docker 容器的日志,运行 docker compose logs -f api(在根目录运行),你会看到这个错误:
api | sqlalchemy.exc.ProgrammingError: (psycopg2 错误) 表 "item" 不存在
api | 在第 2 行: FROM item ORDER BY item.created
api | ^
api |
api | [SQL: SELECT item.id, item.created, item.updated, item.is_active, item.title, item.description
api | FROM item ORDER BY item.created
api | LIMIT %(param_1)s OFFSET %(param_2)s]
api | [parameters: {'param_1': 100, 'param_2': 0}]
api | (有关此错误的更多信息,请访问: https://sqlalche.me/e/20/f405)看来有个错误显示我们的项目表不存在。所以,我们来创建它吧。
由Alembic管理的数据库迁移工作Alembic 是,正如他们所描述的,“一个轻量级的数据库迁移工具,用于与 Python 的 SQLAlchemy 数据库工具包一起使用。”我们已经为 FastAPI 应用在 Docker 容器中安装了 Alembic。要继续设置 Alembic,请运行 docker compose exec api bash 进入运行中的容器。在容器中,运行 alembic init alembic 命令来创建配置文件。
(env) ➜ exampulumi ✗ docker compose exec api bash
root@77e8d39e7b56:/app# init alembic
bash: 找不到命令: init
root@77e8d39e7b56:/app# alembic init alembic
正在生成 '/app/alembic/versions' ... 完成啦
正在生成 '/app/alembic/script.py.mako' ... 完成啦
正在生成 '/app/alembic/README' ... 完成啦
正在生成 '/app/alembic/env.py' ... 完成啦
正在生成 '/app/alembic.ini' ... 完成啦
请先编辑 '/app/alembic.ini' 中的配置、连接和日志设置再继续。
root@77e8d39e7b56:/app#你现在需要在你的IDE里编辑一些新生成的文件。在alembic目录下有一个script.py.mako文件。你需要在这个文件里添加对SQLModel的导入语句。
"""${message}
Revision ID: ${up_revision}
Revises: ${down_revision | comma,n}
Create Date: ${create_date}
"""
from typing import Sequence, Union
from alembic import op
import sqlalchemy as sa
import sqlmodel # <--- ADD THIS HERE
${imports if imports else ""}
# revision identifiers, used by Alembic.
revision: str = ${repr(up_revision)}
down_revision: Union[str, None] = ${repr(down_revision)}
branch_labels: Union[str, Sequence[str], None] = ${repr(branch_labels)}
depends_on: Union[str, Sequence[str], None] = ${repr(depends_on)}
def upgrade() -> None:
${upgrades if upgrades else "pass"}
def downgrade() -> None:
${downgrades if downgrades else "pass"}接下来要更新的文件有很多变更,是 env.py 文件。当你更新完毕后,文件应该看起来像下面的样子。我已经在变更或新增的地方加上了注释。
import os # 添加这一行
from logging.config import fileConfig
from sqlalchemy import engine_from_config
from sqlalchemy import pool
from sqlmodel import SQLModel # 添加这一行
from alembic import context
# 这是 Alembic 配置对象,提供对当前使用的 .ini 文件内容的访问。
config = context.config
# 解析 Python 日志配置文件。这行代码基本上设置了日志记录器。
if config.config_file_name is not None:
fileConfig(config.config_file_name)
# 在这里添加你的模型的 MetaData 对象,以支持自动生成功能
# from myapp import mymodel
# target_metadata = mymodel.Base.metadata
from src.models import * # noqa: F401 # 添加这一行
target_metadata = SQLModel.metadata # 添加这一行
import sqlmodel # noqa: F401 # 添加这一行
# 可以通过 env.py 获取配置文件中的其他值:
# my_important_option = config.get_main_option("my_important_option")
# ... 等等。
def get_url(): # 添加整个函数
user = os.getenv("POSTGRES_USER", "postgres") # 用户名
password = os.getenv("POSTGRES_PASSWORD", "password") # 密码
server = os.getenv("POSTGRES_SERVER", "localhost") # 主机地址
db = os.getenv("POSTGRES_DB", "app") # 数据库名称
return f"postgresql://{user}:{password}@{server}/{db}"
def run_migrations_offline() -> None:
"""以 '离线' 模式运行迁移。
该配置使用 URL 而不是 Engine 配置上下文,虽然使用 Engine 也是可以的。
通过跳过 Engine 的创建,我们甚至不需要有可用的数据库适配器。
这里的 context.execute() 调用将给定的字符串输出到脚本。
"""
url = get_url() # 添加这一行
context.configure(
url=url,
target_metadata=target_metadata,
literal_binds=True,
dialect_opts={"paramstyle": "named"},
)
with context.begin_transaction():
context.run_migrations()
def run_migrations_online() -> None:
"""以 '在线' 模式运行迁移。
在这种情况下,我们需要创建一个 Engine 并将其连接关联到上下文中。
"""
configuration = config.get_section(config.config_ini_section) # 添加这一行
configuration["sqlalchemy.url"] = get_url() # 添加这一行
connectable = engine_from_config(
configuration, # 更新为
prefix="sqlalchemy.",
poolclass=pool.NullPool,
)
with connectable.connect() as connection:
context.configure(connection=connection, target_metadata=target_metadata)
with context.begin_transaction():
context.run_migrations()
if context.is_offline_mode():
run_migrations_offline()
else:
run_migrations_online()为了简化数据库版本控制的创建和管理,将以下三个命令加入到你的 Makefile 中。
create-migration:
ifdef message
alembic revision --autogenerate -m "$(message)"
else
@printf '请使用带有消息的 "make create-migration message=" 形式:make create-migration message="添加用户表"\n'
endif
run-migration:
alembic upgrade head # 升级到最后一个版本
undo-migration:
alembic downgrade -1 # 执行回滚命令:alembic downgrade -1在你的终端,运行命令 make create-migration message="<描述性词语,用于迁移文件>",不再需要在API容器中打开bash。
(env) ➜ exampulumi ✗ make create-migration message="初始迁移 - Item 表项"
alembic revision --autogenerate -m "初始迁移 - Item 表项"
INFO [alembic.runtime.migration] Context impl PostgresqlImpl.
INFO [alembic.runtime.migration] 将假定 DDL 是事务性的.
INFO [alembic.autogenerate.compare] 检测到添加的表 'item'
生成 .../exampulumi/alembic/versions/bc3a0a09839f_initial_migration_item_table.py ... 完成.打开刚刚创建的迁移文件 alembic/versions/uuidStr_your_message.py,这个文件名中的 uuidStr 是一个自动生成的字符串。在执行迁移之前,请务必检查这个文件,确保没有错误。文件中的注释会提醒你:“请调整!”你肯定不想无视那些带有感叹号的自动生成的注释,对吧?
"""
初始迁移 - Item 表
修订 ID: bc3a0a09839f
上次修订版本:
创建时间: 2024-11-09 18:01:38.920034
"""
from typing import Sequence, Union
from alembic import op
import sqlalchemy as sa
import sqlmodel
# 修订标识符,由 Alembic 使用。
revision: str = 'bc3a0a09839f'
down_revision: Union[str, None] = None
branch_labels: Union[str, Sequence[str], None] = None
depends_on: Union[str, Sequence[str], None] = None
def upgrade() -> None:
# ### Alembic 自动生成的命令 ###
# 检查后删除这些注释以表明文件已被查看。
op.create_table('item',
sa.Column('id', sa.Uuid(), nullable=False),
sa.Column('created', sa.DateTime(timezone=True), server_default=sa.text('now()'), nullable=True),
sa.Column('updated', sa.DateTime(timezone=True), server_default=sa.text('now()'), nullable=True),
sa.Column('is_active', sa.Boolean(), nullable=False),
sa.Column('title', sa.Text(), nullable=True),
sa.Column('description', sqlmodel.sql.sqltypes.AutoString(), nullable=False),
sa.PrimaryKeyConstraint('id'),
sa.UniqueConstraint('title')
)
# ### Alembic 自动生成的命令结束 ###
def downgrade() -> None:
# ### Alembic 自动生成的命令 ###
op.drop_table('item')
# ### Alembic 自动生成的命令结束 ###现在我们通过神奇的管理型和版本化的数据库迁移来创建数据库表。运行命令 run-migration,它调用了 alembic upgrade head,这会将所有的迁移应用到目标数据库上。
(env) ➜ exampulumi ✗ make run-migration
alembic upgrade head
信息 [alembic.runtime.migration] 实现为 PostgresqlImpl。
信息 [alembic.runtime.migration] 假设为事务性 DDL。
信息 [alembic.runtime.migration] 升级迁移到 bc3a0a09839f, 初始迁移 - 条目表如果你连接到本地运行的数据库,你可以看到项表已经建好了。在你的数据库中还有一个名为 alembic_version 的表,它记录了你数据库当前的迁移版本号。正如你所见,它记录的版本号 bc3a0a09839f 与迁移文件的版本号及迁移日志中的版本号一致。
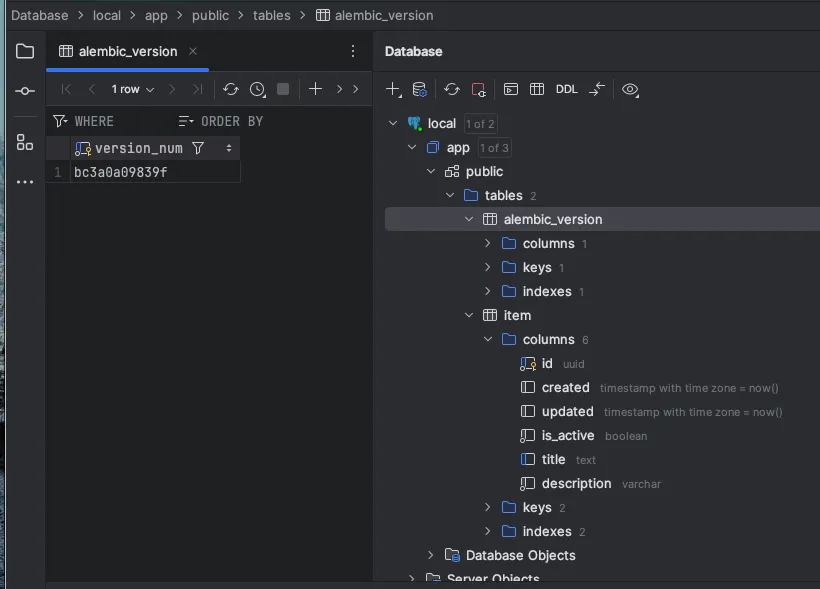
想撤销这次数据库更新吗?运行 make undo-migration,这会执行 alembic downgrade -1 并执行最后一次迁移的降级命令。Item 表就会被移除,同时 alembic_version 表中也不会有任何条目。不过不用担心,只需重新运行迁移即可,执行 make run-migration 即可。如果你不小心多次运行了 make run-migration,也没有问题,Alembic 会检查版本号,如果发现没有新的更改,就不会执行任何操作。恭喜你,你现在有一个带表的数据库了!(实际上有两个表哦。)
为了看到所有功能的实际运行,你需要在你的FastAPI应用中添加端点,以让外部用户能够安全地与数据库中的数据进行交互。首先,在srs/models目录下创建一个session.py文件。这使FastAPI应用可以通过设置中的配置连接到数据库。因为使用了设置,所以在设置生产数据库连接时,无需修改此文件。
# session.py
import sqlmodel
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from src.utils.config import settings
engine = create_engine(settings.SQLALCHEMY_DATABASE_URI, pool_pre_ping=True)
SessionLocal = sessionmaker(autocommit=False, autoflush=False, bind=engine)
sqlmodel_engine = sqlmodel.create_engine(
settings.SQLALCHEMY_DATABASE_URI, echo=False, pool_pre_ping=True
)现在在 src/api 目录下添加一个 deps.py 文件。如果你还不熟悉 FastAPI 的依赖注入系统,可以查阅 官方文档。在这里,我们设置数据库连接,为每个请求使用一个会话,并确保连接在每次请求时都能正确地打开和关闭。
# deps.py
from typing import Generator
from fastapi.security import HTTPBearer
from sqlmodel import Session
from src.models.session import sqlmodel_engine
# 这只是在交互式API文档中启用认证功能
oauth2_scheme = HTTPBearer(
auto_error=False,
)
def get_session() -> Generator: # pragma: no cover - 隐式测试
with Session(sqlmodel_engine) as session:
yield session在很多教程里,数据库操作通常出现在API函数里。在FastAPI模板的早期版本中,将数据库功能分离到了单独的代码部分。这些代码位于 /src/crud 目录下,并且包含一个 base.py 文件,提供了其他模型可使用的基础 CRUD 操作。base.py 文件内容如下。它已不再位于 https://github.com/fastapi/full-stack-fastapi-template,所以可能不再是最理想的选择。但我仍然觉得它对基本的 CRUD 操作很有帮助。
import uuid
from typing import Any, Dict, Generic, List, Optional, Type, TypeVar, Union
from fastapi.encoders import jsonable_encoder
from sqlmodel import select, Session, SQLModel
ModelType = TypeVar("ModelType", bound=SQLModel)
CreateSchemaType = TypeVar("CreateSchemaType", bound=SQLModel)
UpdateSchemaType = TypeVar("UpdateSchemaType", bound=SQLModel)
class CRUDBase(Generic[ModelType, CreateSchemaType, UpdateSchemaType]):
def __init__(self, model: Type[ModelType]):
"""
一个具有默认创建、读取、更新和删除方法的CRUD对象。
**参数说明**
* `model`: SQLAlchemy 模型
* `schema`: Pydantic 模型
"""
self.model = model
def get(self, db: Session, id: uuid.UUID) -> Optional[ModelType]:
statement = select(self.model).where(self.model.id == id)
return db.exec(statement).one()
def get_multi(
self,
db: Session,
*,
skip: int = 0,
limit: int = 100,
) -> List[ModelType]:
# TODO 更新此方法,使其可以传入 order_by 参数
statement = select(self.model).offset(skip).limit(limit)
if "created" in self.model.model_fields:
statement = statement.order_by(self.model.created)
return db.exec(statement).all()
def create(self, db: Session, *, obj_in: CreateSchemaType) -> ModelType:
obj_in_data = jsonable_encoder(obj_in)
db_obj = self.model(**obj_in_data) # 类型忽略(忽略类型检查)
db.add(db_obj)
db.commit()
db.refresh(db_obj)
return db_obj
def update(
self,
db: Session,
*,
db_obj: ModelType,
obj_in: Union[UpdateSchemaType, Dict[str, Any]],
) -> ModelType:
obj_data = db_obj.model_dump(exclude_unset=False)
if isinstance(obj_in, dict):
update_data = obj_in
else:
update_data = obj_in.model_dump()
for field in obj_data:
if field in update_data:
setattr(db_obj, field, update_data[field])
db.add(db_obj)
db.commit()
db.refresh(db_obj)
return db_obj
def delete(self, db: Session, *, id: uuid.UUID) -> ModelType:
statement = select(self.model).where(self.model.id == id)
obj = db.exec(statement).one()
db.delete(obj)
db.commit()
return obj对于 src/crud/item.py,只有寥寥数行代码。
从 src.crud.base 导入 CRUDBase 作为 CRUDBase
从 src.models 导入 Item, ItemCreate, ItemUpdate 作为 Item, ItemCreate, ItemUpdate
class CRUDItem 作为 CRUDBase[Item, ItemCreate, ItemUpdate]:
pass
item = CRUDItem(Item)我们现在可以在src/api/items.py这个API文件中把所有部分整合起来。db: Session = Depends(deps.get_session)这行代码为每个请求提供一个独立的数据库会话,这个会话由crud函数(创建、读取、更新、删除)使用以访问数据库。
我们可以看到,将数据库表定义为 FastAPI 应用中的 SQLModel 模型是多么优美和强大。以下所有这些都是由此带来的结果:
- OpenAPI 交互式文档会读取模型并将其显示为请求和响应体的模式。
- API 请求中的 JSON 数据会被反序列化,转换成 Python 对象
- 请求数据会根据模式验证,任何不符合模式的数据都会返回错误
- 在这里,SQLModel 从主要依赖 Pydantic 转向了 SQLAlchemy
- 使用该对象更新数据库表,然后将响应返回给客户端。这就像这些步骤的逆向操作一样。
你经常会需要为请求和响应创建特定的模式。但是这样做仍然避免了其他框架中常见的大量样板代码。
导入 uuid
from fastapi import APIRouter, Depends
from sqlalchemy.orm import Session
from src import crud
from src.models import ItemRead, ItemCreate, ItemUpdate
from src.api import deps
router = APIRouter()
@router.post("", response_model=ItemRead, status_code=201)
def 创建项(
*, db: Session = Depends(deps.get_session), item_in: ItemCreate
) -> ItemRead:
项 = crud.item.create(db=db, obj_in=ItemCreate(**item_in.model_dump()))
return 项
@router.get("", response_model=list[ItemRead])
def 读取项(*, db: Session = Depends(deps.get_session)) -> list[ItemRead]:
项列表 = crud.item.get_multi(db=db)
return 项列表
@router.get("/{item_id}", response_model=ItemRead)
def 读取项详情(
*, db: Session = Depends(deps.get_session), item_id: uuid.UUID
) -> ItemRead:
项 = crud.item.get(db=db, id=item_id)
return 项
@router.patch("/{item_id}", response_model=ItemRead)
def 更新项(
*, db: Session = Depends(deps.get_session), item_id: uuid.UUID, item_in: ItemUpdate
) -> ItemRead:
项 = crud.item.get(db=db, id=item_id)
# 添加备注
项 = crud.item.update(db=db, db_obj=项, obj_in=item_in)
return 项
@router.delete("/{item_id}", status_code=204)
def 删除项(*, db: Session = Depends(deps.get_session), item_id: uuid.UUID) -> None:
crud.item.delete(db=db, id=item_id)
return None去互动文档区创建一个条目吧!
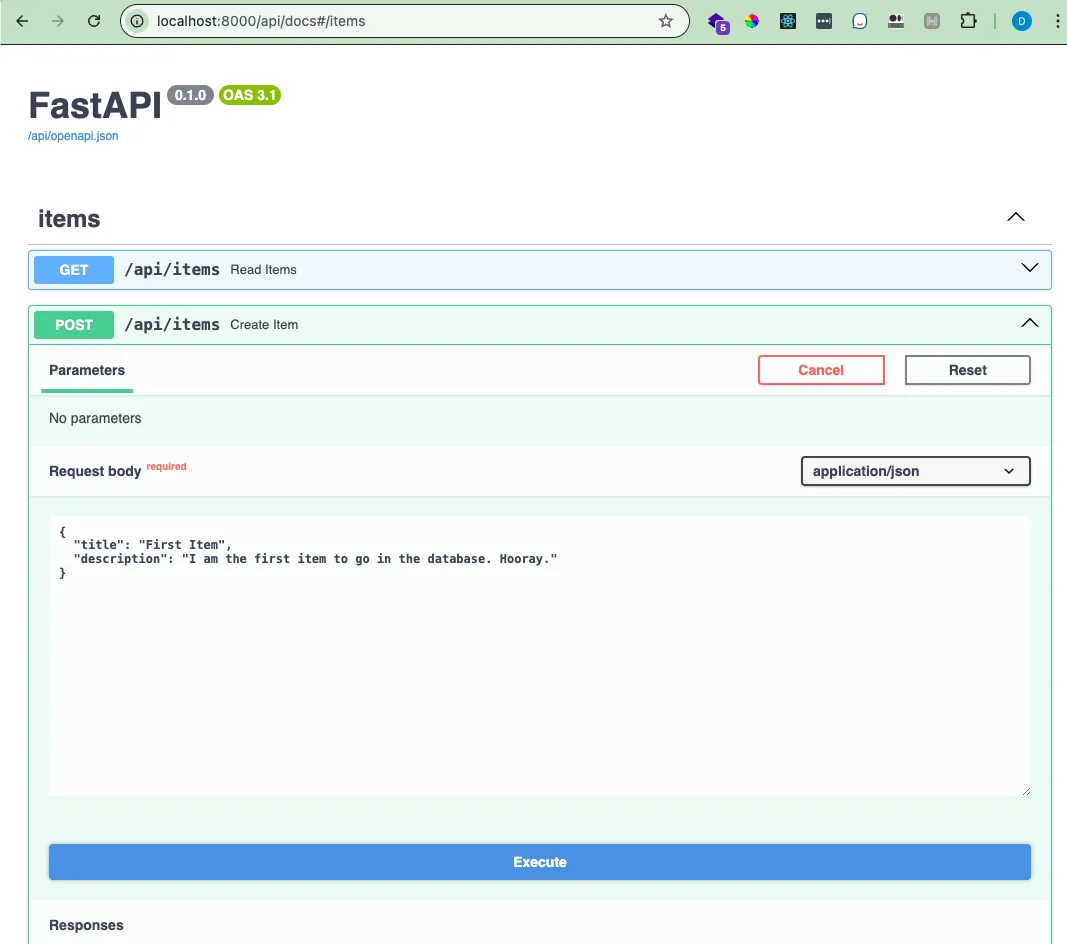
看看回复:

再核对一下数据库里的内容
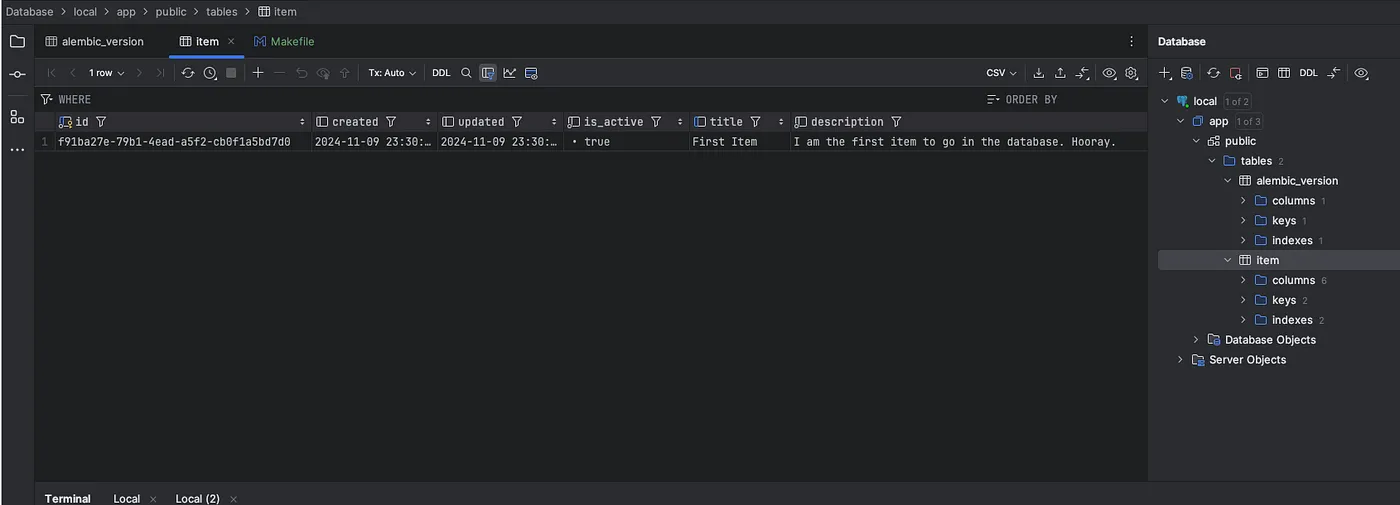
而且,搞定!搞定!你现在有了一个可以持久化数据的 API 了。去吃个三明治去,你值得奖励一下!
要简单地说 🚀感谢你成为我们的一员!在你离开之前,还想告诉你:感谢你成为In Plain English社区的一员!希望你继续支持我们!
- 记得给作者👏点赞和关注哦。
- 关注我们: X | 领英(LinkedIn) | YouTube | Discord | 电子通讯 | 播客节目
- 在Differ免费创建一个AI驱动的博客吧。
- 更多内容请访问 PlainEnglish.io





