
Ollama刚刚宣布正式支持Llama 3.2视觉模型。Llama 3.2视觉模型有两种尺寸:110亿和900亿参数。在这篇文章里,我会谈谈它们在不同情况下的表现,并分享我的一些看法。
Llama 3.2-Vision 经过指令优化,适用于视觉识别、图像推理、图像描述以及回答关于图像的通用问题。在常用的行业基准测试中,模型的表现超过了大多数现有的开源和闭源多模态模型。
另外,这个模型支持多种语言,如英语、中文等。
评估对于仅包含文本的任务,官方支持的语言有英语、德语、法语、意大利语、葡萄牙语、印地语、西班牙语和泰语。Llama 3.2 的训练数据覆盖了比这些8种支持语言更广泛的语言范围。提示:对于图像加文本的应用程序,仅支持英语。
我将使用这篇论文中的方法来进行评估,该论文实际上认为视觉语言模型是“盲的”。它在几个任务上对模型进行了测试。
VLMs有盲点。研究表明,尽管这些任务对人类来说很简单,VLMs在简单视觉任务上却失败了。vlmsareblind.github.io- 任务 1:线段相交问题
- 任务 2:两个圆
- 任务 3:圆圈内字母
- 任务 4:重叠的形状
- 任务 5:嵌套正方形
- 任务 6:计数网格
- 任务 7:地铁地图
我会从每个任务中选择最具有挑战性的部分,看看模型能否正确处理其中的任何一部分。此外,我将运行代码大约10次到20次,计算准确回答的平均值,并找出任何错误的结果。
泰国任务1:线交叉注:原文中的“#”符号保留,但需注意在中文中通常不使用此符号,此处保留是为了保持与英文原文格式的一致性。
提示:
-
“蓝色和红色的线碰面几次?用大括号填上数字,比如{5}。”
- “数一数蓝色和红色的线碰面的地方。用大括号填上数字,比如{2}。”
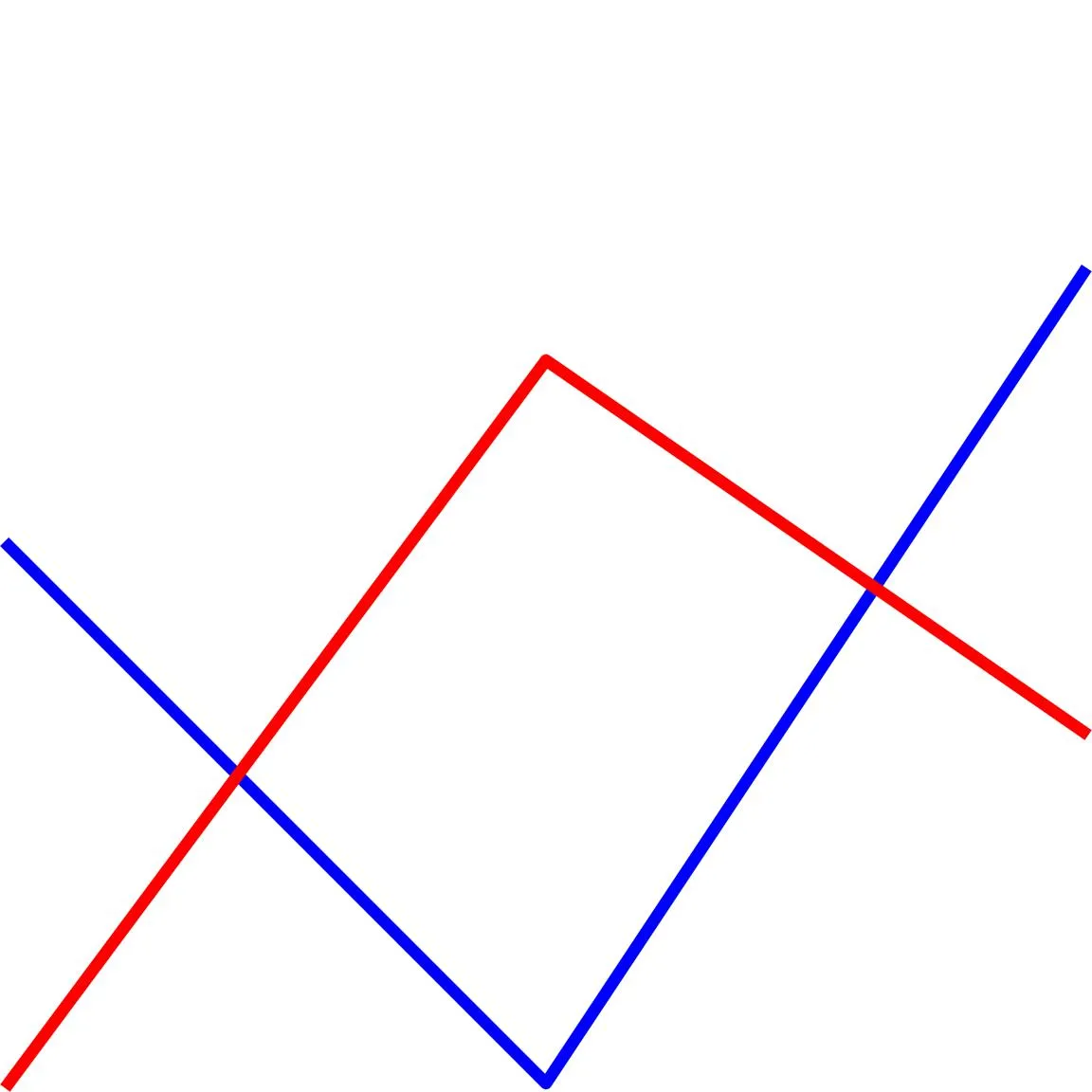
蓝色和红色的线有两处相交。因此,它们在两个点上碰到了两次。
蓝色和红色的线在三个地方相交,因此,答案是 {3}。超过 60%
任务2:两个圆
提示语:
-
“这两个圆碰在一起了吗?请回答是或否。”
- “这两个圆叠在一起了吗?请回答是或否。”
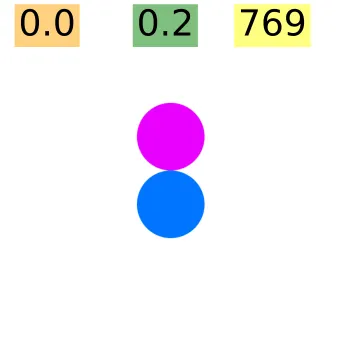
**步骤1:识别圆圈**
图像中有一个蓝色的圆和一个红色的圆。
**步骤2:确定圆圈是否相切**
要确定圆圈是否相切,我们需要检查它们是否恰好在一个点相交。如果它们完全不相交,那么它们就没有接触。如果它们相交于多个点,说明它们重叠了,但不一定是接触的。
**步骤3:检查相交点**
仔细观察图像,发现这两个圆恰好在一个点上相交。这意味着这两个圆确实相切了。
**结论:**
是的 图中展示了一个包含两个圆圈的示意图,一个红色,一个蓝色。图中,红色圆在左侧,蓝色圆在右侧。
要判断这两个圆圈是否接触,我们需要分析它们的位置和大小。仔细观察后发现,这两个圆圈在任何地方都没有重叠或接触。相反,它们之间似乎保持着一小段距离。
所以,根据以上分析,**不**,这两个圆圈并不接触。超过80%
基于专家建议,翻译如下: 任务3:圈起来的字母提示如下:
- “哪个字母被圈住啦?”
- “哪个字给红圈圈出来了?”

答案:字母 'n' 被圈出来并标成红色。
成功率达到100%
第4个任务:计数重叠的图形提示:
- “图片里有几种{形状}? 请直接回答数字就好。”
- “数一数图片里有几种{形状}。请用数字回答,并用大括号括起来,例如{3}。”

模型回答的要么是6,要么是7,要么是8,但从没给过正确的答案9。而且更搞笑的是,就连GPT-4也搞不定!
成功几率:零%
提示如下:
- “从A到C有多少条单色路径?请直接用大括号里的数字回答,比如{3}。”
- “数一下从A到C的单色路径有几条。请直接用大括号里的数字回答,比如{3}。”
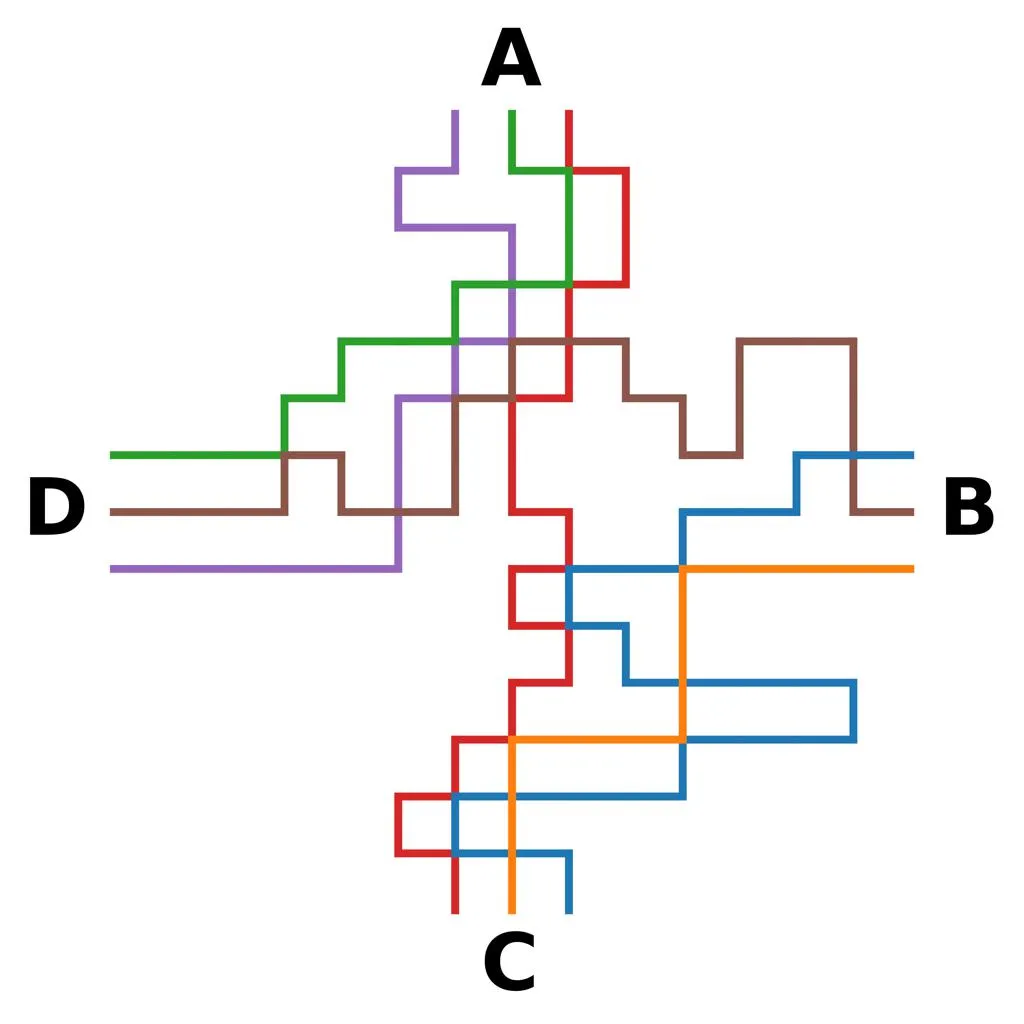
为了找到从点A到点C的单色路径的数量,我们需要计算那些全程仅使用一种颜色的不同的路径。
**第一步:识别图中使用的颜色**
查看提供的图,我们可以看到使用了四种不同的颜色:
* 红色
* 蓝色
* 绿色
* 紫色
但是,仔细检查后发现,并不是所有的颜色都被用来创建从A到C的路径。我们只关注那些从A到C直接或间接连接且没有中断的颜色。
**第二步:确定相关的路径**
仔细检查图中从A到C仅使用单色的路径:
* 有一条路径从A直接到B(使用红色),然后沿着另一段路径继续。
* 另一条路径从A到D,再到C,但这条路径涉及两种颜色。
根据这一分析,只有一条路径从A到C全程使用单色,
因此,从点A到点C的单色路径的数量为{1}。
因此,答案是{1}。为了找出从点A到点C的单色路径数量,我们需要分析给定的图,并计算符合该标准的不同路径。
步骤1:识别单色路径
单色路径是指所有边都属于同一种颜色的路径。在此上下文中,单色路径是指由全部红色边组成的路径。
步骤2:计算从A到C的不同红色路径
从点A到点C,有两条不同的红色路径形成了直接路径:
- 一条边直接连接A和C。
- 另一组边组成了一条更长的路径,通过中间节点,但最终得出相同的单色路径结论。
步骤3:考虑替代路径
仔细检查后发现,虽然从A到C有多种路径,但只有两条路径由全部红色边组成。这是因为任何包含不同颜色的路径将不被视为单色路径。
结论
根据以上分析,正确的答案是从点A到点C的单色路径(全部红色)的数量。
答案:{2}
成功率大于60%
无论是GPT-4o还是Claude 3.5在这项任务上都没能完成。
玩了一段时间后,我没有发现明显的差异;可以与GPT-4o和Sonnet-3相比。不过它还是比不上Gemini-1.5 Pro,我觉得现在Gemini-1.5 Pro可能是最好的视觉语言模型(VLM)。这里指的是11B版本的模型。如果你有足够的资源去测试90B版本,只需将以下代码中的“11B”替换为“90B”即可。
试一试 安装Ollama吧 !curl -fsSL https://ollama.com/install.sh | sh# 导入操作系统模块
import os
# 修改 IPython 系统调用
get_ipython().system = os.system
# 在后台启动 ollama 服务
!ollama serve & !ollama pull llama3.2-vision 拉取llama3.2-vision模型。
试试吧import ollama
def extract_document_info(image_path):
response = ollama.chat(
model='llama3.2-vision',
messages=[{
'role': 'user',
'content': '你对图片的问题',
'images': [image_path]
}]
)
return response
# 例如
image_path = "/kaggle/input/image.jpg"
result = extract_document_info(image_path)
print(result['message']['content'])就是这样!这是一次对LLA MA 3.2 Vision(11B版本)的快速回顾。它在OCR识别方面也很出色,我在一些极具挑战性的图像上测试过它。当然,90B版本更好,但运行它需要很多资源。一旦我找到好的资源,我会附上的!
llama3.2-vision:90bLlama 3.2 Vision 是一个集合了 11B 和 90B 大小的指令微调图像推理模型的集合。 VLMs是盲的:研究表明,这些模型在人类容易完成的简单视觉任务上表现不佳。更多详情,请参阅:vlmsareblind.github.io




