
今天,我们将暂时放下我们关于视觉变换器的系列,讨论构建一个基本的GPT变体。
更准确地说,我们将构建一个自回归(如二元)模型,即每次生成一个标记都会参考之前的所有标记。自回归模型通常会依次生成标记(如字符或单词),并参考之前的标记。例如,在句子“I like to eat”中,“I like to eat” 后面的标记可能是 <ice-cream>, <cookies> 等。
统计和经典的自回归模型表明,输出变量值线性地依赖于其之前的值以及一个随机误差项(难以完全预测的成分)。
这个不可完全预测的随机性可以大致与我们在“我喜欢吃”例子中下一个预测的令牌相关联,通过让它随机选择下一个预测令牌(比如<ice-cream>,<cookies>等),让模型在选择时更不确定,我们将在稍后的文章中进一步解释这种做法。
我们正在实现一个非常基础的自回归模型,所以我们从头开始做每一件事,使用一个数据集来生成类似威廉·莎士比亚风格的文本。这将是我写过的最长的文章之一,所以先深吸一口气,需要时随意休息。让我们直接开始吧。

图片由作者利用GPT生成。注:GPT是英文“Generative Pre-trained Transformer”的缩写,是一种生成式预训练变换模型。
内容
- 加载数据 — 创建数据批加载器和拆分数据。
- Bigram语言模型 — 实现Bigram语言模型。
- 训练 — 训练模型并生成文本内容。
注意:本文中的代码遵循了Andrej Karparthy关于GPT的讲解视频。事实上,他的视频是我实现注意力机制的起点,从那时起,我参考了各种卷积注意力、移窗技术等架构和相关论文。
如果你之前看过的话,这篇文章除了代码有一些小改动外,并没有太多不同,所以你可以用它快速复习一下。如果没有看过……我们直接开始吧。
加载数据# 导入 torch 特定模块
import torch
import torch.nn as nn
from torch.nn import functional as F
# 首先我们下载莎士比亚的文本文件(保存为 input.txt)
! wget https://raw.githubusercontent.com/karpathy/char-rnn/master/data/tinyshakespeare/input.txt # 下载文件,这里的`*`符号通常用来表示忽略某些内容,但在这里可能不适用
# 接下来,读取文本文件并进行编码解码
text = open('input.txt', 'r',).read()
vocab = sorted(list(set(text)))
encode = lambda s: [vocab.index(c) for c in s] # 编码函数:将文本转换为词汇表中的索引
decode = lambda l: [vocab[c] for c in l] # 解码函数:将索引转换回文本我们不使用外部的分词器,而是使用自定义的lambda函数来进行我们数据的字符级别分词任务。
ids = encode("我喜欢吃饭")
txt = decode(ids)
print(f"ids: {ids}")
print(f"txt: {txt}")
print(f"".join(txt))
# 输出:
ids: [21, 1, 50, 47, 49, 43, 1, 58, 53, 1, 43, 39, 58, 55]
txt: ['我', ' ', '喜', '欢', ' ', '吃', ' ']
我喜欢吃饭 将数据拆分为90/10的比例
x = int(0.9 * len(text))。# text 是一个包含我们所有数据的大字符串。
text = torch.tensor(encode(text), dtype=torch.long)。
train, val = text[:x], text[x:]。# train 和 val 分别表示训练集和验证集。记住,因为我们在字符级别上进行分词,生成也将是在字符级别上。一个明智的做法是,从语料库中随机抽取一些句子批次,用来训练模型。
batch_size = 32 # 这表示我们将并行处理多少个独立序列吗?
block_size = 8 # 表示预测时的最大上下文长度
device = 'cuda' if torch.cuda.is_available() else 'cpu'
def get_batch(split):
# 生成一个小批量的输入 x 和目标 y
data = train if split == 'train' else val
ix = torch.randint(len(data) - block_size, (batch_size,))
x = torch.stack([data[i:i+block_size] for i in ix])
y = torch.stack([data[i+1:i+block_size+1] for i in ix])
return x.to(device), y.to(device)
xb, yb = get_batch('train') # 从训练集获取小批量数据该批次是这样创建的。
我们想要从语料库中获取块大小为(8)的随机片段,所以我们生成批次大小为(32)的索引(ix),对于每个索引(ix),我们取接下来的8个token id,并将它们堆叠在一起。然而,我们的目标(y)是通过在x的基础上增加一个索引(i+1 或 i + 块大小 + 1)来生成的,因为我们需要预测序列中的下一个token。
例子:
ix = [33]
for i in ix:
print(train[i:i+18])
print(train[i+3:i+18+3]) # 这里我选择 +3 而不是 +1,仅仅是为了示例
for i in ix:
print("".join(decode(train[i:i+18])).replace("\n", ""))
print("".join(decode(train[i+3:i+18+3])).replace("\n", ""))
# 输出:
tensor([39, 52, 63, 1, 44, 59, 56, 58, 46, 43, 56, 6, 1, 46, 43, 39, 56, 1])
tensor([1, 44, 59, 56, 58, 46, 43, 56, 6, 1, 46, 43, 39, 56, 1, 51, 43, 1])
再听我说一点
多一点,听我讲 一个二元组(n-gram,其中 n=2)代表文本中连续的两个词或字符的序列。
- 1-gram (一元模型) for “i like to eat”:
["我", "喜欢", "吃", "东西"] - 2-gram (二元模型) for “i like to eat”:
["我 喜欢", "喜欢 吃", "吃 东西"] - 3-gram (三元模型) for “i like to eat”:
["我 喜欢 吃", "喜欢 吃 东西"]
因为我们正在执行自回归的任务,所以我们需要像之前提到的那样以二元组格式加载数据。
现在我们来谈谈文章的核心——多头注意力机制。我已经在十几篇关于视觉变换器的文章中提到过这一部分,我会尽量简短,不浪费你的时间,直接讲概念。(天……我完全可以把这篇文章讲得更长,分成两部分,但管他呢,直接做吧)
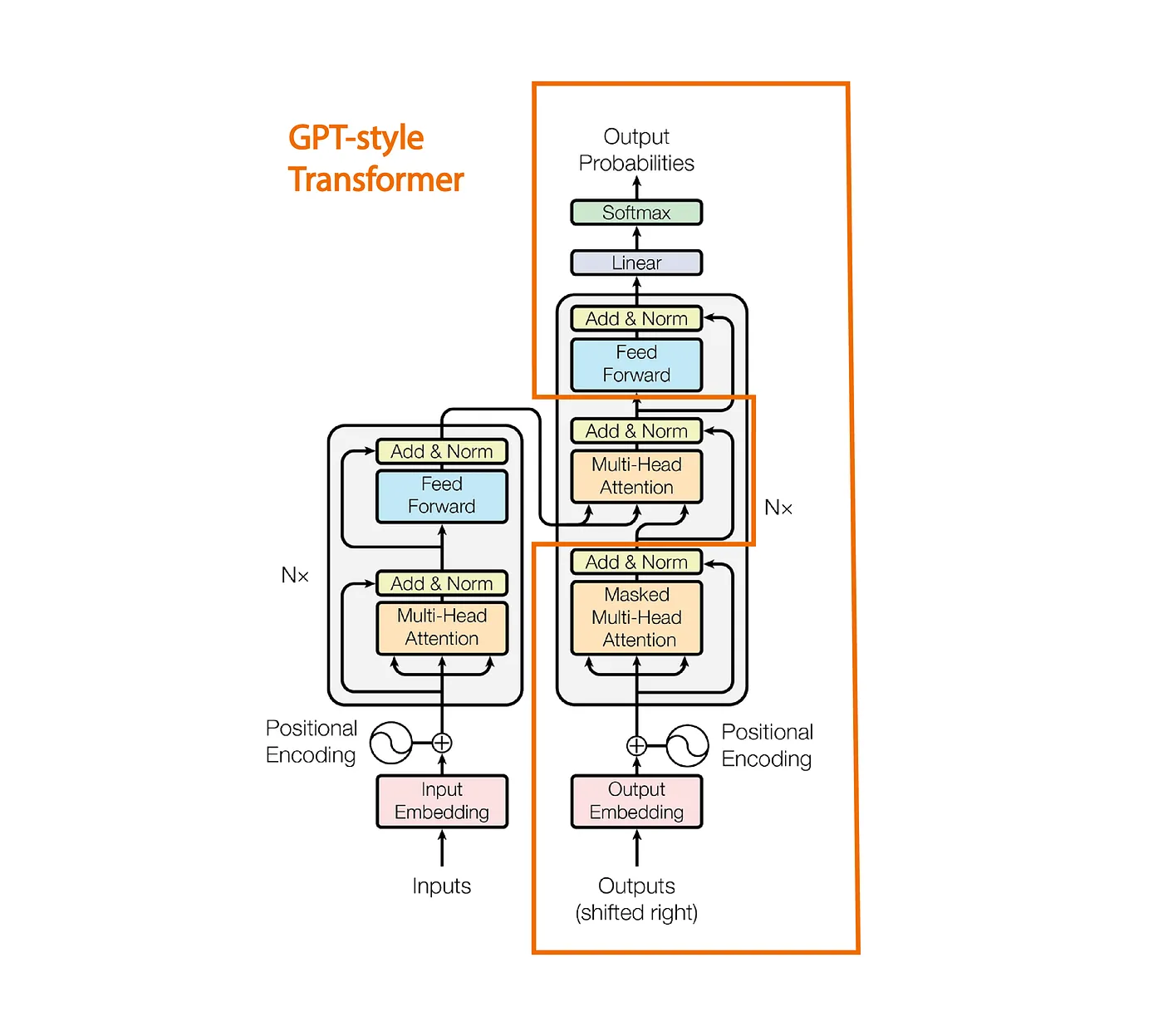
图1:这里(来自这里的图片链接)的图片。
我们看到GPT采用了《注意力机制就是一切》论文中提出的Transformer架构。然而,它但不同之处在于,它仅仅堆叠了多头注意力,而不是整个解码器部分。
二元语言模型。
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
# 每个 token 直接从查找表中读取表示下一个 token 的 logits
self.token_embedding_table = nn.Embedding(vocab_size, embed_size)
self.possitional_embedding = nn.Embedding(block_size, embed_size)
self.linear = nn.Linear(embed_size, vocab_size)
self.block = nn.Sequential(*[Block(embed_size, num_head) for _ in range(num_layers)])
self.layer_norm = nn.LayerNorm(embed_size)
def forward(self, idx, targets=None):
B, T = idx.shape
# idx 和 targets 都是 (B, T) 的整数张量
logits = self.token_embedding_table(idx) # (B, T, C)
ps = self.possitional_embedding(torch.arange(T, device=device))
x = logits + ps #(B, T, C)
logits = self.block(x) #(B, T, C)
logits = self.linear(self.layer_norm(logits)) # 这应该将 embed_size 映射到 vocab_size
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss在这里,输入的 idx 是我们之前生成的一批处理数据,其形状为 (B, T),其中 T 是块大小(Block Size)或标记长度。
前向传递首先为每个标记生成形状为 (B, T, C) 的嵌入。如上图所示,我们需要将位置嵌入添加到标记嵌入中。我们为输入 (idx) 创建位置嵌入,以便将标记所包含的信息表示为固定嵌入维度,但这并不提供有关标记位置的信息,因此我们需要额外添加位置嵌入以确保模型对标记的位置有所了解。如果您有任何疑问,我建议您直接参考我之前的博客,我在那里详细解释了所有内容。
在 PyTorch 中,
nn.Embedding是一个层,用于将离散、分类值(如单词索引)映射为连续、密集向量。该层接受整数索引作为输入,其中每个索引表示一个唯一的分类项目(例如,一个单词、标记,甚至是其他分类数据)。内部,nn.Embedding维护一个形状为num_embeddings, embedding_dim的嵌入矩阵,以便为每个标记创建密集表示。由于我们正在简化 GPT 的实现,因此直接使用nn.Embedding生成位置嵌入,而不是使用其他标准方法。接下来的步骤就简单了……我们有一个块(解码器模块的堆叠),最后我们生成具有相同形状的新注意力矩阵,其中每个标记包含关于其之前所有标记的信息。
最后,我们应用层归一化(这是稳定训练的常见做法),然后将其传递给线性层以将嵌入 C 映射到我们的词汇表维度。词汇表维度只是输入.txt 文件中所有唯一字符的总数。定义我们预测准确度的一种常见方法是,比较块(注意力模块)输出与目标索引。
输出的 logits 实际上是词汇表大小 V 上的概率分布,用于预测序列中的下一个标记(目标)。因此,我们使用交叉熵损失来生成一个损失值,以确定我们的输出与目标标记序列有多接近。
既然我们已经完成了Bigram的实现,是时候看看Block是如何利用多头注意力(MHA)机制来进行注意力计算的。
多头注意力机制
使用多头注意力机制的主要原因是,我们可以直接将输入(B, T, embedding_size)传递给注意力模块,但是更快的方法不是直接生成维度为embedding_size的Q、K和V并计算注意力权重,而是将注意力权重的计算划分为几个部分,分别计算各部分的注意力权重,最后将结果合并。
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.head_size = head_size
self.key = nn.Linear(embed_size, head_size, bias=False)
self.query = nn.Linear(embed_size, head_size, bias=False)
self.value = nn.Linear(embed_size, head_size, bias=False)
def forward(self, x):
B, T, C = x.shape
k = self.key(x)
q = self.query(x)
v = self.value(x)
wei = q @ k.transpose(2, 1) / self.head_size ** 0.5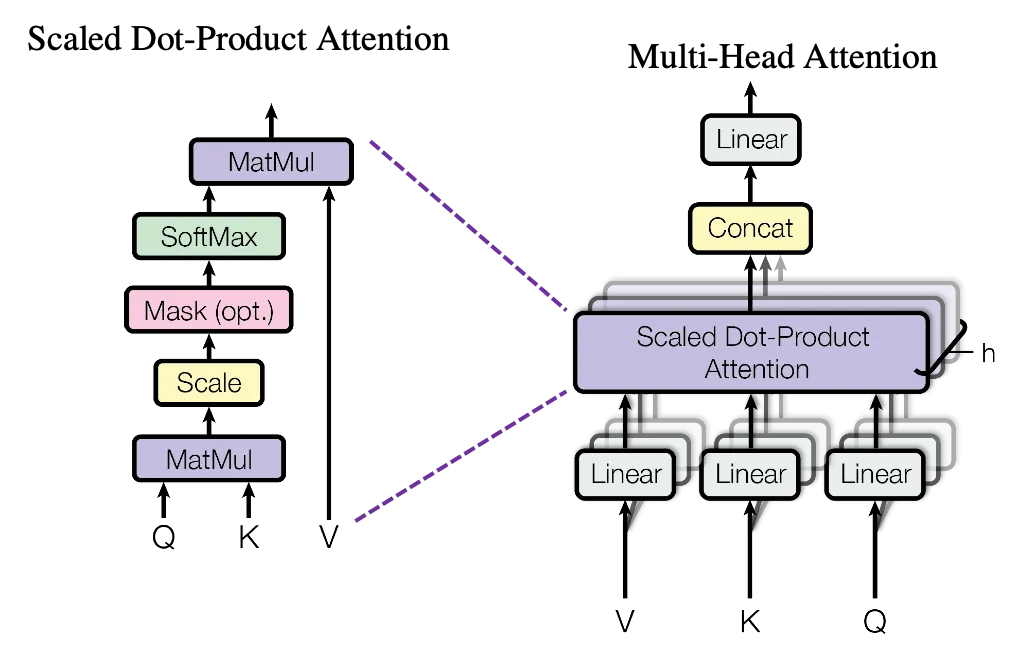
图2:注意力机制!| 来源:图片
因此,根据上述逻辑,我们创建了一个注意力头。现在让我们开始理解它的意义。
输入的维度是 (批次大小, 词元长度, 嵩入维度),在添加了位置嵌入之后。在这里,输入中的每个词元由一个嵌入维度(64)表示。但是,每个词元都没有关于之前所有词元的信息。
为了创建包含此类信息的嵌入,我们通过生成键、查询和值向量来使用注意力机制。
Head类中的注意力机制旨在帮助模型在生成输出时专注于输入序列的不同部分,这在语言建模等任务中特别有用。
key、query和value的投影源自查询每个词元的上下文相关信息的概念。每个词元由一个向量(x)表示,通过将其线性变换为key、query和value向量,我们可以计算序列中的哪些词元应该相互关注。当 q (查询) 与 k (键) 点乘时,结果 (wei) 告诉我们每个词元与其他词元之间的“相关性”或“注意力”分数。更高的分数意味着一个词元在该上下文中与其他词元更相关或“重要”。缩放因子
1 / sqrt(head_size)防止这些分数变得过大,这会使得 softmax 分布过于尖锐,从而更难优化。
class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
self.head_size = head_size
self.key = nn.Linear(embed_size, head_size, bias=False)
self.query = nn.Linear(embed_size, head_size, bias=False)
self.value = nn.Linear(embed_size, head_size, bias=False)
self.register_buffer('tril', torch.tril(torch.ones(block_size, block_size)))
self.dropout = nn.Dropout(dropout)
def forward(self, x):
B, T, C = x.shape
k = self.key(x)
q = self.query(x)
v = self.value(x)
wei = q@k.transpose(2, 1)/self.head_size**0.5
wei = wei.masked_fill(self.tril[:T, :T] == 0, float('-inf'))
wei = F.softmax(wei, dim=2) # (B , block_size, block_size)
wei = self.dropout(wei)
out = wei@v
return out因果掩码 tril 用于确保每个 token 只能“看到”它自己和之前的 token。这对于像文本生成这样的自回归任务至关重要,因为模型在预测下一个 token 时不应该查看未来的 token。将无关位置设置为负无穷 masked_fill,这些位置在通过 softmax 处理后会变为零,从而不会影响最终的注意力计算。这可以防止模型作弊,通过查看未来的 token。最后,我们计算权重和值之间的点积,并返回结果。
你可以看看这个示例输出,更好地了解转换过程。
q = torch.randint(10, (1, 3, 3))
v = torch.randint(10, (1, 3, 3))
print("Query:\n",q)
print("Value:\n",v)
wei = q@v.transpose(2, 1)/3**0.5
print("权重:\n", wei)
tril = torch.tril(torch.ones(3, 3))
print("下三角矩阵:\n",tril)
wei = wei.masked_fill(tril == 0, float('-inf'))
print("掩码权重:\n", wei)
print("Softmax ( e^-inf = 0 )\n", F.softmax(wei, dim=2))
# 输出:
Query:
tensor([[[2, 8, 8],
[4, 2, 4],
[1, 2, 9]]])
Value:
tensor([[[9, 5, 7],
[3, 1, 4],
[6, 2, 9]]])
权重:
tensor([[[65.8179, 26.5581, 57.7350],
[42.7239, 17.3205, 36.9504],
[47.3427, 23.6714, 52.5389]]])
下三角矩阵:
tensor([[1., 0., 0.],
[1., 1., 0.],
[1., 1., 1.]])
掩码权重:
tensor([[[65.8179, -inf, -inf],
[42.7239, 17.3205, -inf],
[47.3427, 23.6714, 52.5389]]])
Softmax ( e^-inf = 0 )
tensor([[[1.0000e+00, 0.0000e+00, 0.0000e+00],
[1.0000e+00, 9.2777e-12, 0.0000e+00],
[5.5073e-03, 2.8880e-13, 9.9449e-01]]])我们将采用多头注意力机制,因为我们将这样实现它。
class MultiHeadAttention(nn.Module):
def __init__(self, head_size, num_head):
super().__init__()
self.sa_head = nn.ModuleList([Head(head_size) for _ in range(num_head)])
self.dropout = nn.Dropout(dropout)
self.proj = nn.Linear(embed_size, embed_size)
def forward(self, x):
x = torch.cat([head(x) for head in self.sa_head], dim=-1)
x = self.dropout(self.proj(x))
return x我们在这里将输入 x (B, T, E) 传递给不同的注意力头,每个注意力头返回大小为 (B, T, head_size) 的最终向量,其中 head_size = E (64) / num_heads (4) = 16。我们在 num_heads(4) 的 for 循环中进行操作,再将这些结果拼接回原来的大小 (B, T, 4*16)。
多头注意力在当嵌入维度更大时,被认为更快且效率更高得多。
拼接之后,我们将最终输出传递给线性投影,这样做的目的是让它们在最终向量中更好地体现注意力权重计算过程中学到的信息。然后它被送入dropout层并返回。
把所有内容放在一起,标准解码器模块如上图1所示。
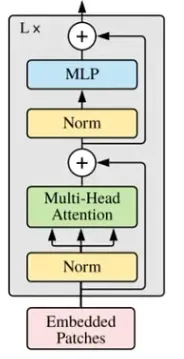
图:3|来源:注意力就是你所需要的
class FeedForward(nn.Module):
def __init__(self, embed_size):
super().__init__()
self.ff = nn.Sequential(
nn.Linear(embed_size, 4 * embed_size),
nn.ReLU(),
nn.Linear(4 * embed_size, embed_size),
nn.Dropout(dropout)
) # 前馈网络,包含线性变换,ReLU激活函数和Dropout层
def forward(self, x):
return self.ff(x) # 前向传播方法
class Block(nn.Module):
def __init__(self, embed_size, num_head):
super().__init__()
head_size = embed_size // num_head # 头部尺寸
self.multihead = MultiHeadAttention(head_size, num_head) # 多头注意力机制
self.ff = FeedForward(embed_size) # 前馈网络
self.ll1 = nn.LayerNorm(embed_size) # 层归一化
self.ll2 = nn.LayerNorm(embed_size) # 层归一化
def forward(self, x):
x = x + self.multihead(self.ll1(x)) # 多头注意力机制
x = x + self.ff(self.ll2(x)) # 前向传播前馈网络
return x头部大小的计算方法如前所述,输入先经过一个层归一化,之后通过我们的多头注意力网络,接着再经过一个层归一化,最后通过一个前馈网络。
我们再来看看二元模型
class BigramLanguageModel(nn.Module):
def __init__(self, vocab_size):
super().__init__()
# 每个词元直接从查找表中读取下一个词元的 logits 值
self.token_embedding_table = nn.Embedding(vocab_size, embed_size)
self.possitional_embedding = nn.Embedding(block_size, embed_size)
self.linear = nn.Linear(embed_size, vocab_size)
self.block = nn.Sequential(*[Block(embed_size, num_head) for _ in range(num_layers)])
self.layer_norm = nn.LayerNorm(embed_size)
def forward(self, idx, targets=None):
B, T = idx.shape
# idx 和 targets 都是 (B,T) 的整数张量
logits = self.token_embedding_table(idx) # (B,T,C)
ps = self.possitional_embedding(torch.arange(T, device=device))
x = logits + ps #(B, T, C)
logits = self.block(x) #(B, T, c)
logits = self.linear(self.layer_norm(logits)) # 这一步是将 head_size 映射到 vocab_size
if targets is None:
loss = None
else:
B, T, C = logits.shape
logits = logits.view(B*T, C)
targets = targets.view(B*T)
loss = F.cross_entropy(logits, targets)
return logits, loss
def generate(self, idx, max_new_tokens):
# idx 是当前上下文中的 (B, T) 索引
for _ in range(max_new_tokens):
# 裁剪索引到最后的 block_size 个 token
crop_idx = idx[:, -block_size:].to(device)
# 获取预测结果
logits, loss = self(crop_idx)
# 只关注最后一个时间步
logits = logits[:, -1, :] # 变为 (B, C) 从 (B, T, C)
# 应用 softmax 获取概率
probs = F.softmax(logits, dim=-1) # (B, C)
# 从概率分布中采样一个索引
idx_next = torch.multinomial(probs, num_samples=1).to(device)
# 将采样的索引附加到当前序列
idx = torch.cat((idx, idx_next), dim=1) # (B, T+1)
return idx这里我们看到,Block是在Sequential层中按照层数范围被调用的。
生成 token…
我们首先将单维度的 idx 张量(表示我们token的索引)传递给_generate_函数,同时传递我们希望生成的新token的最大数量。由于我们的模型是构建为块大小8的,我们一次只能传递8个token,因此我们裁剪idx中的最后8个token(如果idx长度小于块大小,则选择所有token)。
我们将裁剪后的idx传递给我们的BigramLanguageModel,因为我们生成的logits代表了目标token的可能性分布,我们只关注最后一个token,因为目标序列(y)的最后一个token是序列(x)中要预测的下一个token(在批处理加载器部分中已解释)。
当前的logits形状为(B, C),其中C是词汇表大小,表示最后一个token索引在整个词汇表上的概率分布,即每个词汇在该索引位置出现的可能性。现在我们只需对其应用softmax,将其转换为概率向量,即向量中的所有元素之和为1。
现在,还记得我们在文章开头提到的那些不完全可预测或者随机的术语,以及我们如何让模型随机选择序列中的下一个词元吗?这样做时,我们使用了torch.multinomial,这是一种统计方法,用于从给定的概率分布中随机抽取样本。在这里,它会根据给定的概率随机抽取索引。
然后我们最终得到下一个预测的索引值,并将其与之前的索引值连接起来。我们继续循环执行,根据之前的索引值生成下一个索引值,直到达到最大token数量限制。
培训幸好训练这部分还挺直接的。
m = BigramLanguageModel(65).to(device)
optimizer = torch.optim.AdamW(m.parameters(), lr=1e-3)
# 训练这个模型,因为我不会轻易投降
批处理大小 = 32
for epoch in range(5000):
# 打印训练和验证损失
if epoch % 1000 == 0:
m.eval()
进行评估并计算损失
Loss = 0.0
Val_Loss = 0.0
for k in range(200):
x, y = 获取批次(True)
val_, val_loss = m(x, y)
x1, y1 = 获取批次(False)
_, train_loss = m(x1, y1)
Loss += train_loss.item()
Val_Loss += val_loss.item()
avg_loss = Val_Loss / (k + 1)
avg_train_loss = Loss / (k + 1)
m.train()
print("Epoch: {} \n 验证损失为:{} 损失为:{}".format(epoch, avg_loss, avg_train_loss))
# 前向
data, target = 获取批次(False)
logits, loss = m(data, target)
# 反向
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()在这里,我们让模型训练5000个epochs,这在配备4GB VRAM的Nvidia RTX 3050显卡上大约需要2分钟。
我们从正向传播开始,首先从_get_batch()获取批量数据并传递给BigramLanguageModel,然后调用optimizer.zero_grad(),调用loss.backward(),最后执行optimizer.step()。我们使用的是AdamW优化器,这完全足够满足我们的需求。
现在你期待的那一刻终于来了
我们为下面这个句子创建一个数据结构:
ids = torch.tensor(encode(「我喜欢吃饭」), dtype=torch.long).unsqueeze(0) # 将文本编码为张量并添加维度id的形状是(1, 18)(批量大小,令牌数)。从最初的18个令牌开始,生成超过2000个字符。为了说明背景,我们的词汇表由输入文件input.txt中的所有唯一字符构成,我们在前面的数据加载部分实现了这一点,即vocab = sorted(list(set(text))),如前面的数据加载部分所述。
print("".join(decode(m.generate(torch.zeros([1,1], dtype=torch.long), max_new_tokens=2000)[0].tolist())))输出:
我爱吃东西,noBANIO:
这里和
我通过这种方式向女性摇晃以结识你,你不介意吗?
就像他在烈日下的样子。
LUCENTIO:
双重女主人真是不错。
不记得你了,你是主人,在你命令下,那些为了清扫房间而工作的人,Petruchio?
可怜这个人,他这么老了还在做这些,我对此感到困惑和不解,
确信你不会参加,无人知道这些事情的发生,
Pitedame,这是我第一次。
ANDO:
哦,多么高尚的人,那至少不是那种会用力量来统治的人,你,
我会继续等待,Signior to paptista 吗?
你开心吗?
BIANCA:
女人这样对待他真是奇怪,对吧?
PROSPERO:
我,就像一种成功的体验,
这一切都不是从这个岛上的好心人那里来的;
要结婚。
TRANIO:
是的,伙计。
GRUCHIO:
我将展示我是如何出生的。
PROSPETRUCHIO:
那是我的;它就是这样。
我知道……这听起来不合常理。但我们必须意识到,语言模型的训练并不是仅仅基于莎士比亚作品的数据集。更高效的分词方法和海量的数据集,这需要大量的GPU算力。
尽管我们用的是一个小模型训练,性能还算可以,输出依然有逻辑,并且学会了用实际的英语单词,而不是随机生成的乱七八糟的话。
你可以尝试调整模型,比如使用不同的数据集、Token数量、批处理量、层数量等等。
谢谢!这个博客的主要目标是详细地告诉你如何从零开始构建你的语言模型并在你的数据集上训练……好了,现在你明白了!!!
真的非常感谢您给我学习的机会,并读到了这里,希望您喜欢这篇内容。整个代码在我的GitHub仓库ML-Models中,您可以在这里找到here,在那里我从零开始实现各种深度学习架构。
如果你喜欢这篇文章或觉得它很有帮助,请给我点个赞并关注我。如果你有任何疑问,欢迎随时联系我哦。
感谢您的阅读!
参考文献:
[1] 大型语言模型虽然被称作自回归模型,但它们并不像经典自回归模型那样线性,因为它们不具备线性的特性,因此不能算作真正的自回归模型。阅读更多(了解更多关于自回归模型的信息)。





