
上周我听了 Acquired 的一期关于 Nvidia 的节目。这期节目讲的是 transformer(即 GPT 中的 'T'),并且可能是 21 世纪最重要的发明。
沿着贝肯街走着,听着,我在想,我懂transformers,对吧?在训练过程中,会掩盖一些token,注意力头来学习如何连接文本中的概念,预测下一个词的概率。我从Hugging Face体验过LLMs。早期我在Klaviyo用过GPT-3,那时“聊天”那部分还没完善。在Klaviyo我们甚至开发了其中一个最早的基于GPT的生成式AI功能,也就是我们的主题行助手。更早一些时候,我还做过一个基于较早的语言模型开发的语法检查工具。所以或许。
变压器是由一支在谷歌工作的团队在研究自动翻译(例如英语到德语)时创建的。它在2017年通过论文《Attention Is All You Need》(注意力机制就是一切)介绍给世界。我查了这篇论文,并看了看图1:
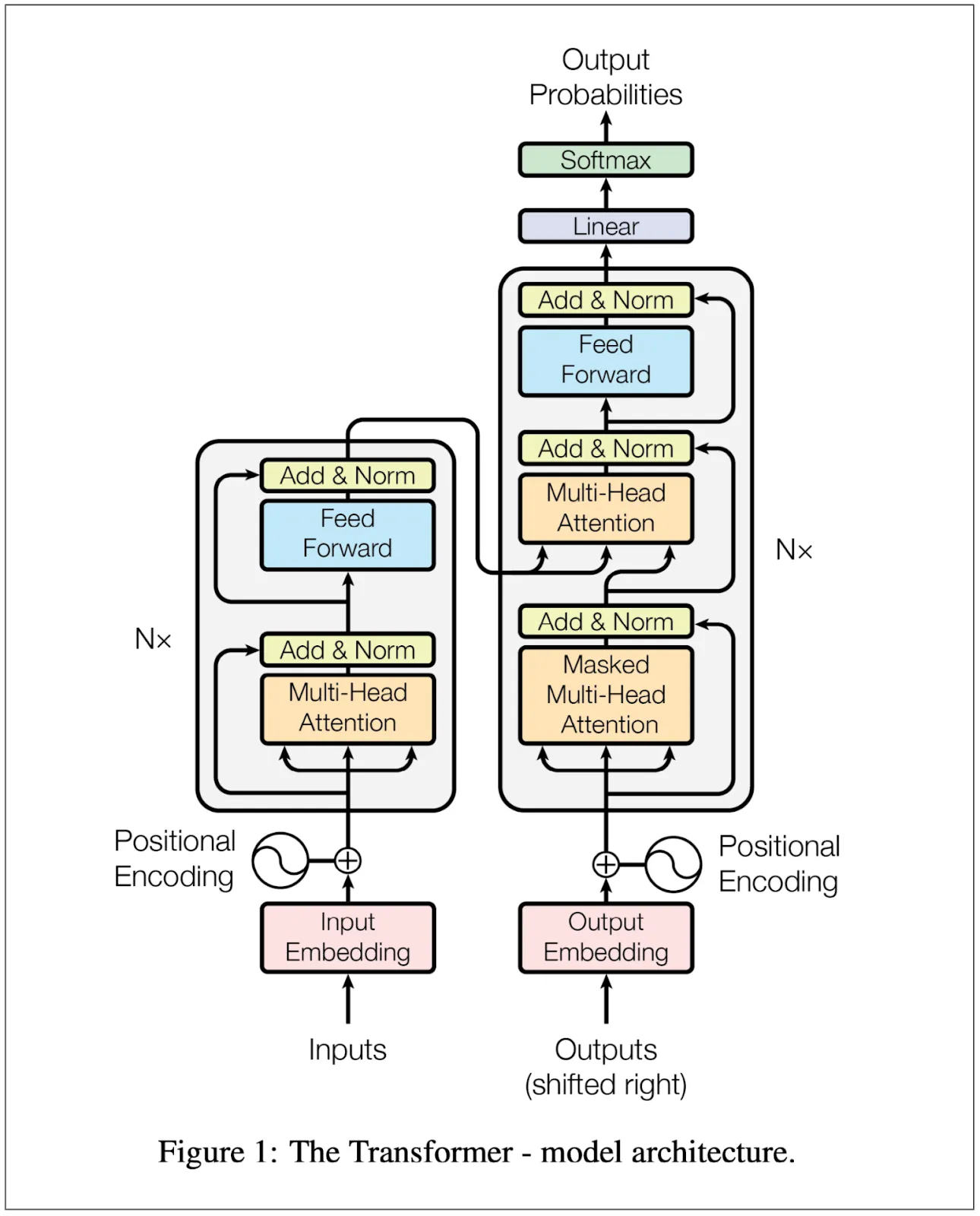
图1来自于《注意力就是一切》这篇论文(链接:https://arxiv.org/pdf/1706.03762)
嗯……如果我没理解错,也只是大致了解了一下。我越仔细看图和研究论文,就越发现细节没搞懂。下面是我记下来的一些问题:
- 在训练过程中,输入是英语的分词句子,输出是德语的分词句子吗?
- 每个训练批次里的具体项目是什么?
- 为什么要把输出输入到模型中?掩码多头注意力如何防止模型通过从输出学习到输出来作弊?
- 多头注意力具体是什么?
- 损失是如何计算的?不可能是直接翻译整个源语言句子然后计算损失,这没有道理。
- 训练完成后,具体输入什么来生成翻译?
- 为什么会有三条箭头进入多头注意力模块?
我确信这些问题对两类人来说可能显得简单且略显天真。第一类是使用类似模型(如RNN、编码器-解码器)做相似工作的人。他们读完这篇论文后肯定立刻明白谷歌团队的成就及其实现方式。第二类则是这七年里,意识到变压器重要性并花时间深入学习其细节的许多人。
好吧,我想学习,觉得最好的方法是从零开始构建模型。我很快就迷失了方向,于是决定跟踪别人写的代码。我发现了一个很棒的笔记本,它解释了这篇论文并用 PyTorch 实现了模型。我复制了代码,并用它训练了模型。我将所有内容(如输入、批次、词汇表和维度)都保持得很小,以便我可以跟踪每一步发生了什么。记录维度和张量并绘制在图示中对我理清思路很有帮助。当我完成时,我已经很好地回答了前面提到的所有问题,我会在图示完成后继续回答这些问题。
这里是我整理好的笔记。这部分的所有内容都是用来训练一个小小的批次,也就是说,不同图中的所有张量都是关联在一起的。
为了让这更加清晰,并借鉴笔记本中的一个方法,我们将训练模型来复制标记。例如,训练完成后,“dog run”应该输出为“dog run”。

也就是说,

尝试用文字描述到目前为止图表中紫色所示的张量维度意味着什么:

其中一个超参数是 d-model,在论文中的基础模型中它是 512。在这个例子中我将其设为 8。这意味着我们的嵌入向量长度变成了 8。这里是主要的图示,维度已在多处标注。

让我们仔细看看编码器的输入。
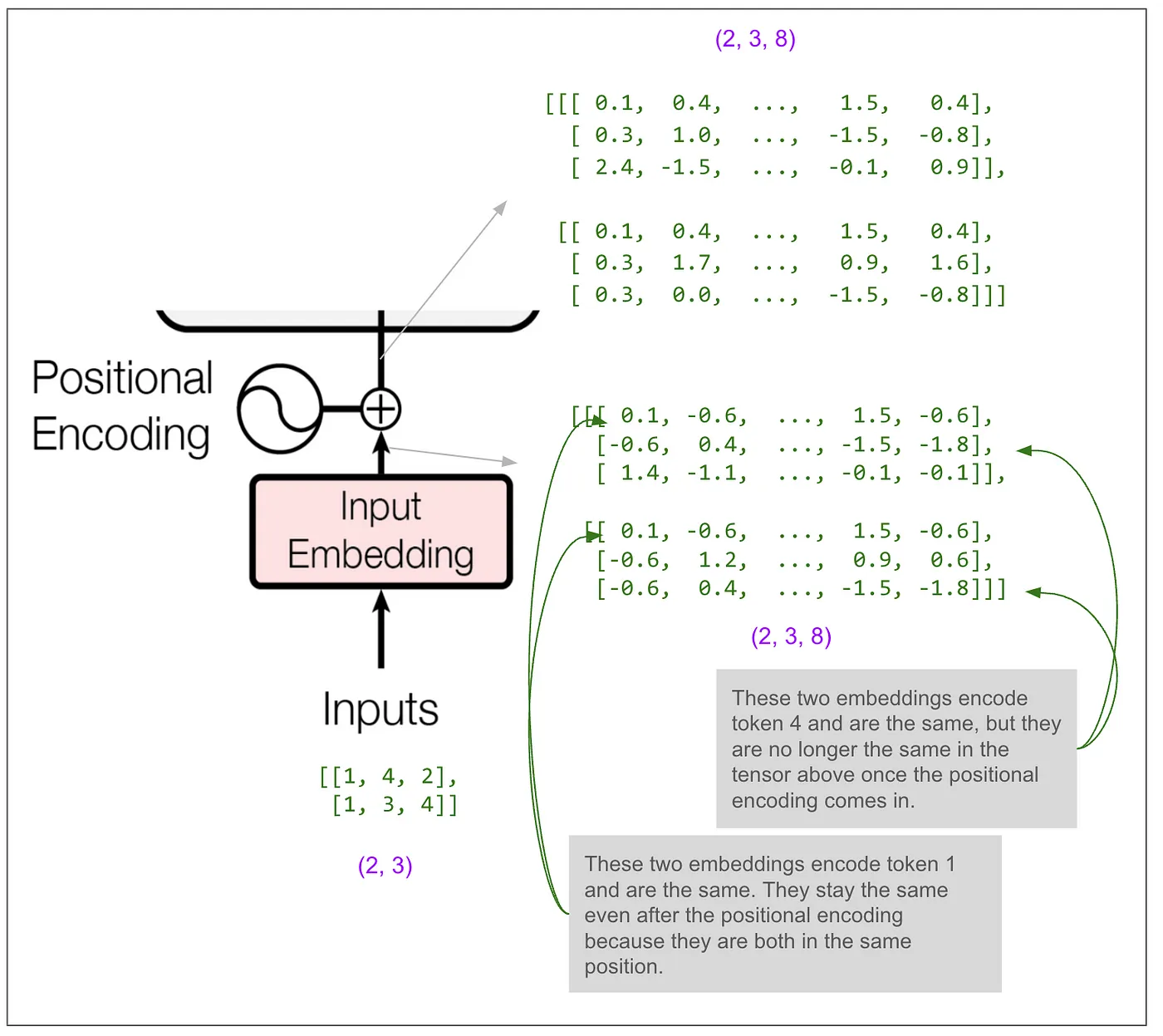

大多数图中显示的块(加法和规范化、前馈、最终的线性变换)仅作用于最后一个维度。如果是这样,模型只能使用序列中的单个位置的信息来预测单个位置。然而,必须在某个地方使“位置之间的信息混合”,而这种神奇的操作发生在多头注意力块里。
让我们仔细看看编码器中的多头注意力块。在接下来的图中,请注意在我的例子中,我将参数 h(头数)设为 2。而在论文中的基础模型中,这个参数是 8。

图2来自《Attention Is All You Need》(图来自https://arxiv.org/pdf/1706.03762),附有作者注释
(2,3,8)是如何变成(2,2,3,4)的?我们执行了一个线性变换,然后将结果分成(8 / 2 = 4)头的数量,并重新排列张量的维度,使我们的第二个维度代表头。让我们来看一些实际的张量,例如。

我们还没有将不同位置的信息混合在一起。这将发生在缩放点积注意力层。“4”维度和“3”维度最终会交汇在一起。
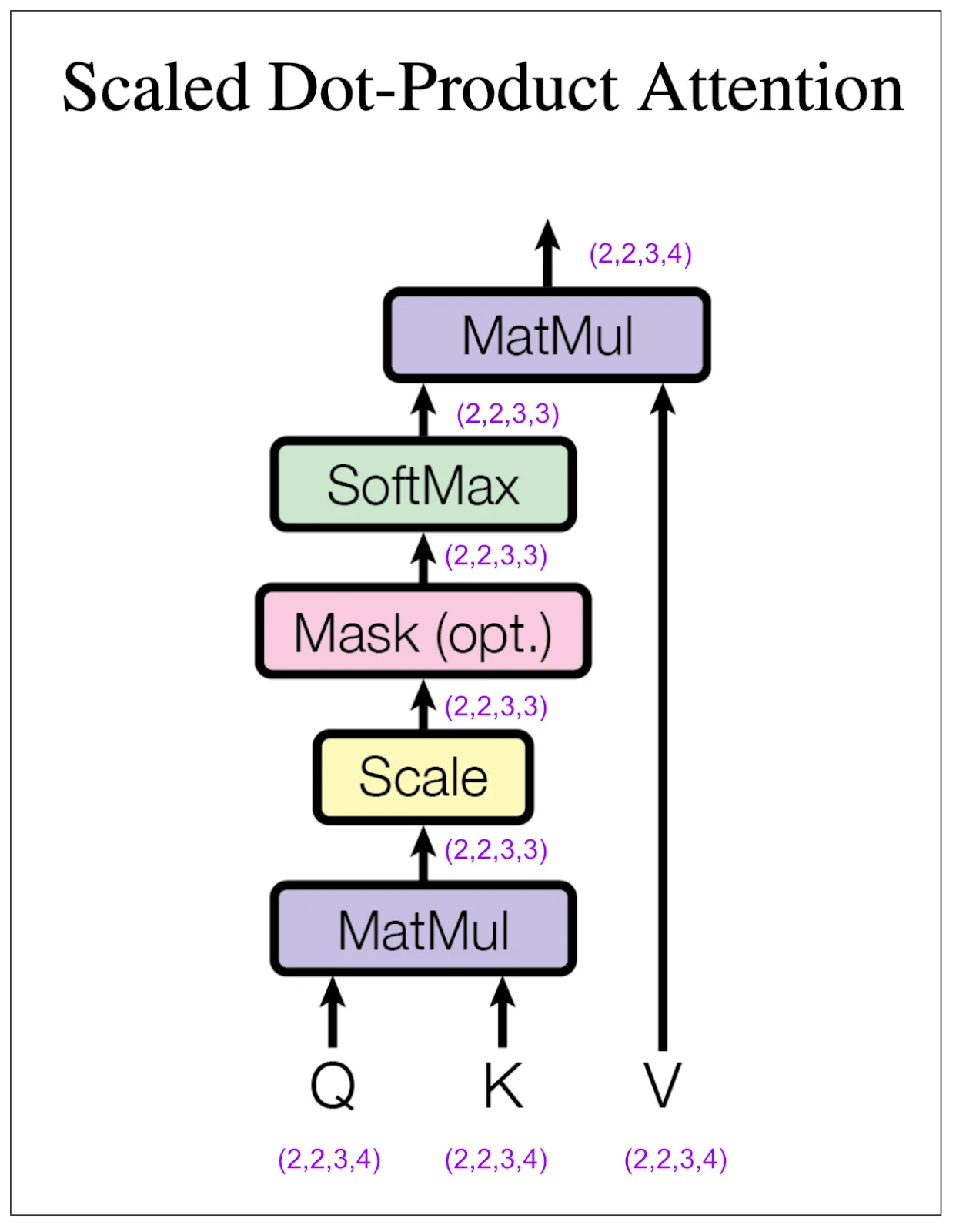
图2如下,来自Attention Is All You Need,并由作者带注释。
让我们来看一下张量,但为了更简单明了,我们只看批次中的第一个元素和第一个头。换句话说,比如 Q[0,0], K[0,0] 等。其他三个部分也会经历同样的过程。

我们现在来看softmax输出与V的最终矩阵乘法。

从一开始,我们就能看出,在进行乘法操作之前,V 中的这三个位置,一路追溯到我们最初的那个句子“<start> dog run”,每个位置都是独立处理的。这个乘法操作首次将其他位置的信息引入进来。
回到多头注意力图,我们可以看到concat将每个头的输出重新拼接在一起,这样每个位置现在都由一个长度为8的向量表示。请注意,特别是concat之后但在线性变换之前张量中的1.8和-1.1与上面提到的缩放点积注意力输出中第一个头的第一个位置的向量中的1.8和-1.1相匹配。(接下来的两个数也匹配,但它们被省略号省略了。)

现在让我们重新回到整个编码器:
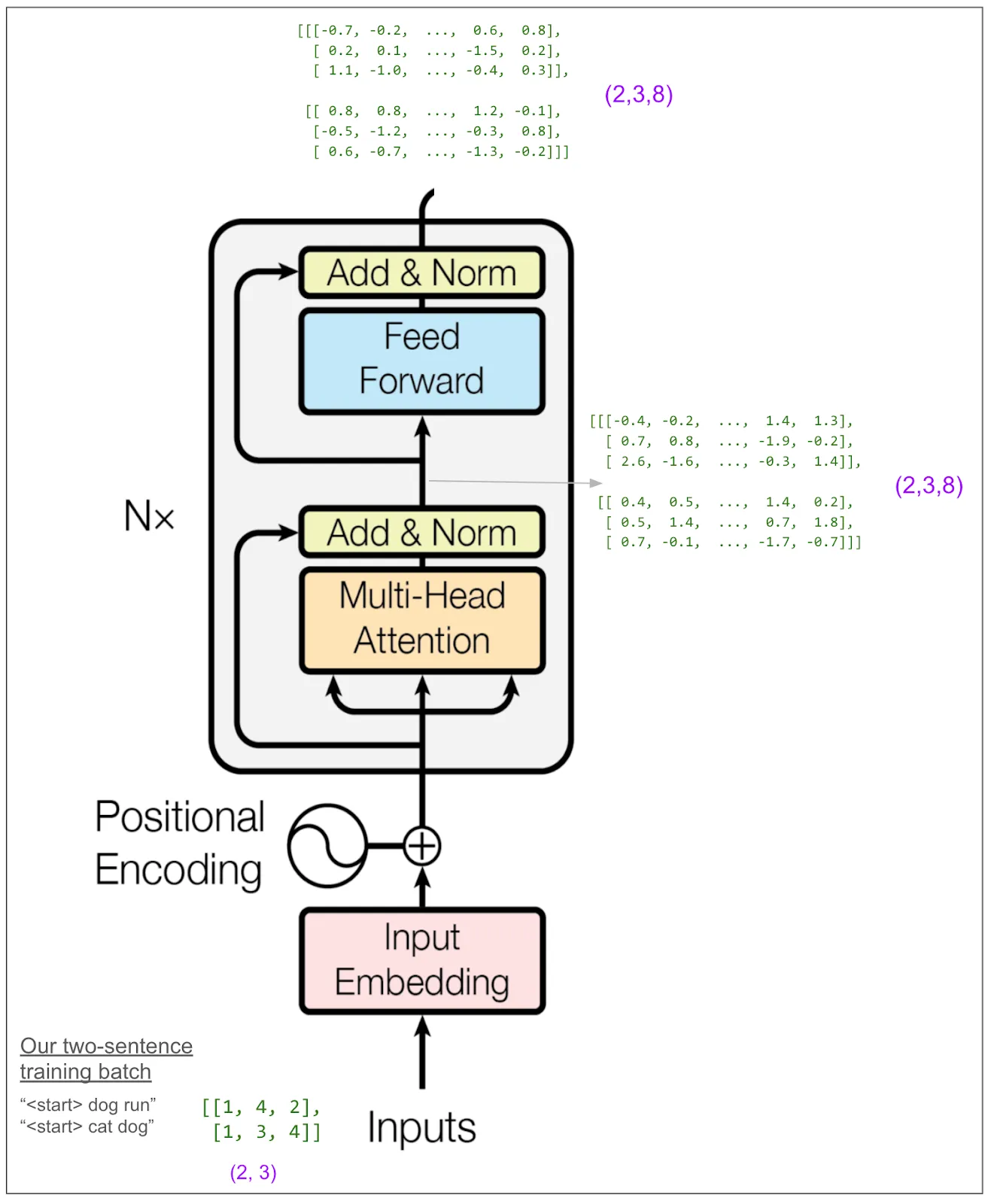
最开始我认为我会想详细追踪前向块(Feed Forward Block)。论文中称之为“位置独立的前向网络”,我原以为这意味着它可能将信息从一个位置传递到右侧的位置。但实际上并非如此。“位置独立”意味着它独立地作用于每个位置。它对每个位置进行从8个元素到32个元素的线性转换,然后进行ReLU(取0和数值的最大值),再进行一次线性转换以返回8个元素。(这是在我们的小例子中。而在论文中的基础模型中,它从512转变为2048,然后再回到512。这里有很多参数,可能大部分的学习都在这里进行。)前向传播的输出又回到了(2,3,8)的形式。
暂时先放下我们的玩具模型,论文中提到的基础模型的编码器看起来是这样的。输入和输出维度能够匹配真是太好了!
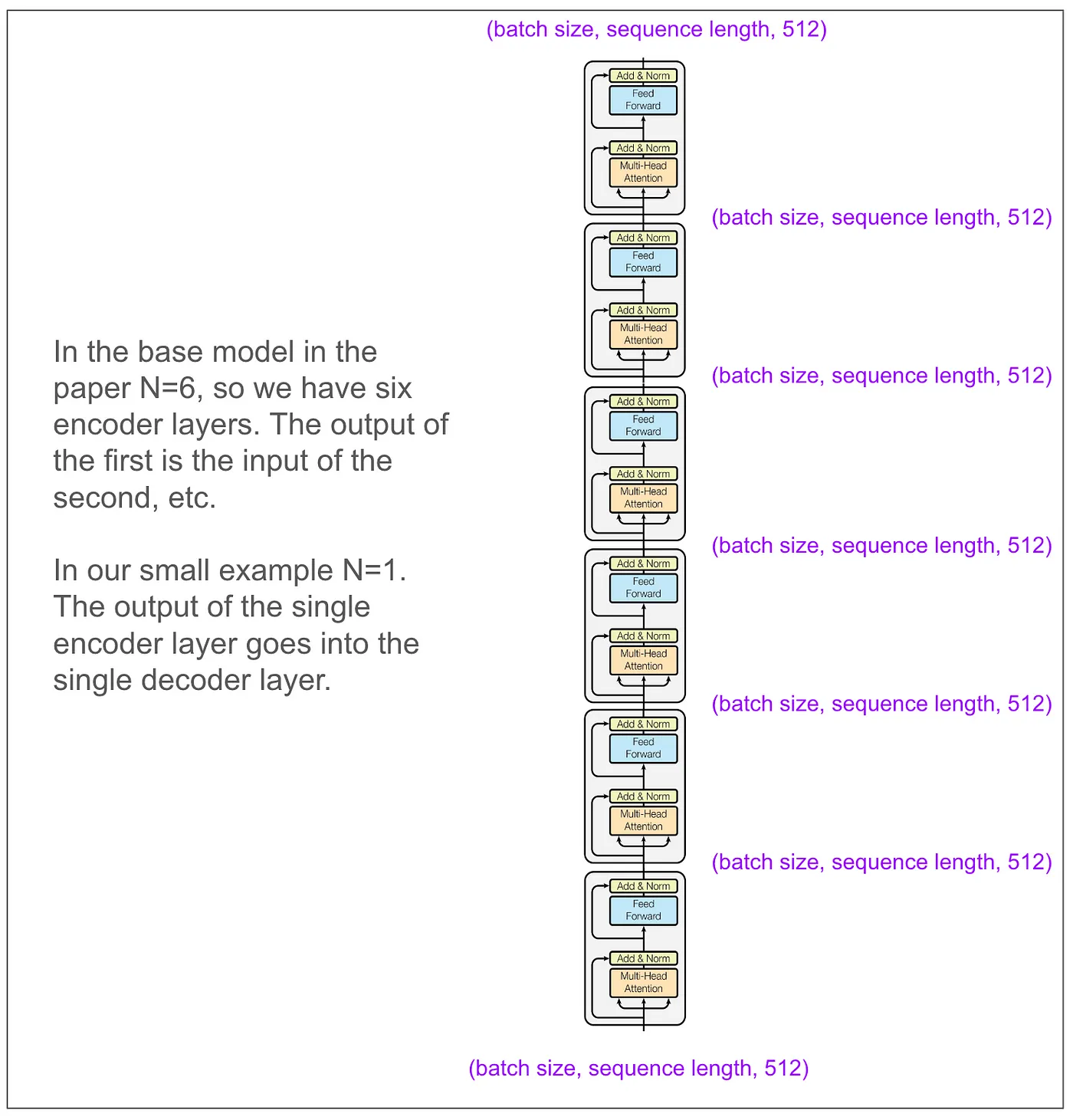
现在让我们放大范围,直到我们可以看到解码器。
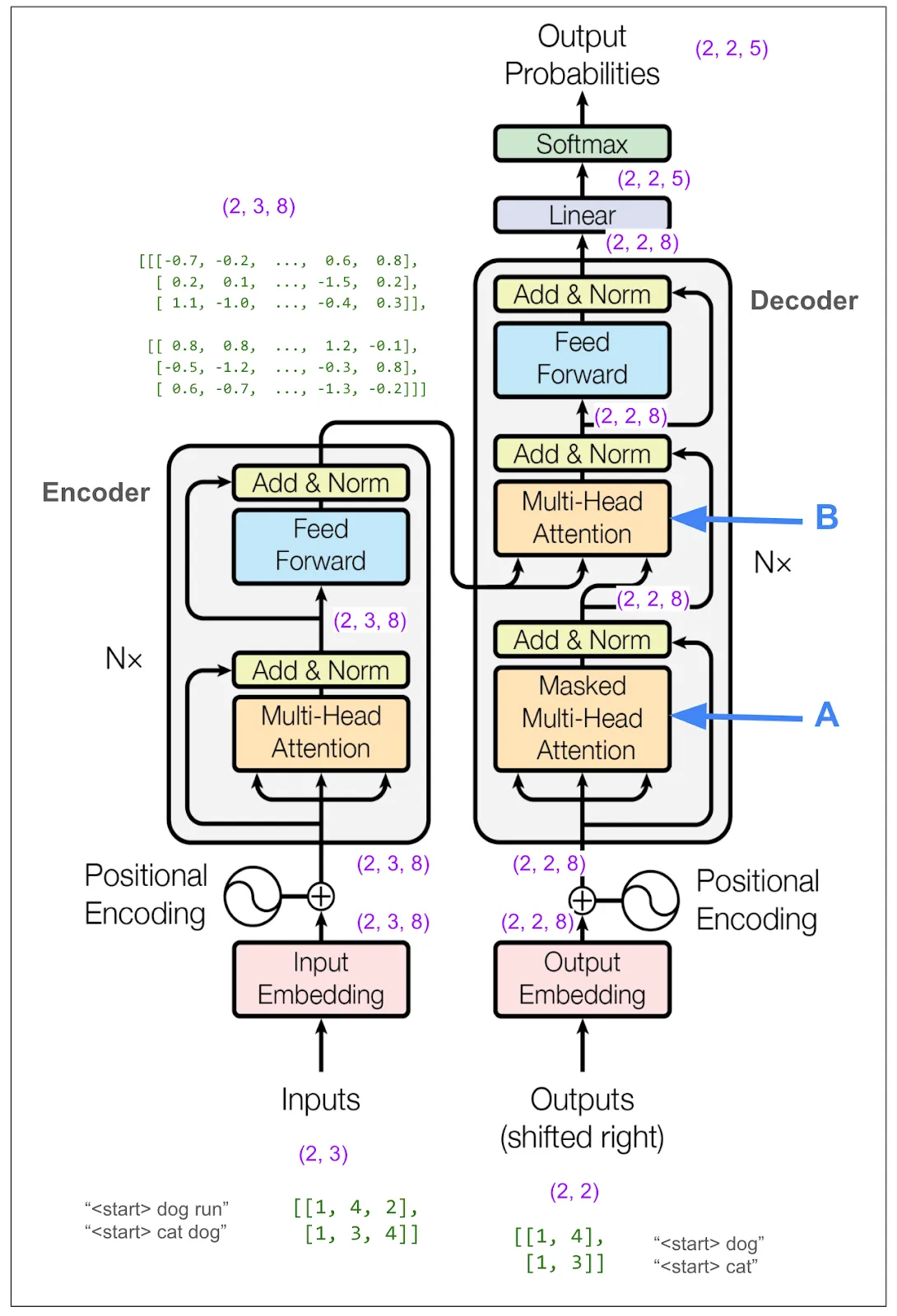
我们不需要仔细研究解码器的大部分部分,因为它与我们刚才在编码器部分看到的很相似。不过,我标记的 A 和 B 部分是不同的。A 部分不同是因为我们使用了掩码多头注意力机制。这正是防止在训练过程中“作弊”的秘诀所在。B 我们稍后再讨论。不过,先让我们暂时忽略这些内部细节,记住我们期望解码器最终输出的内容。
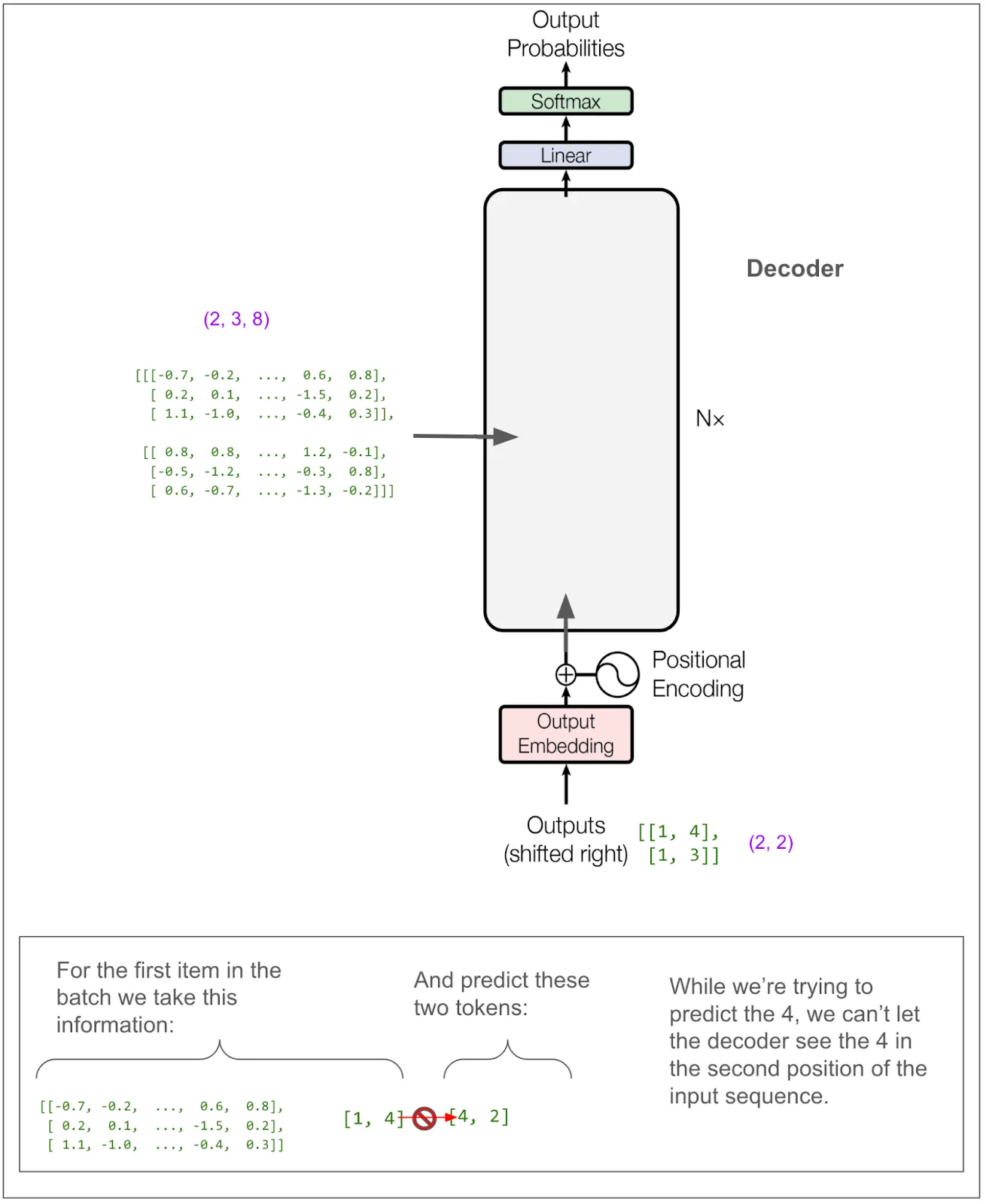
为了进一步强调这一点,假设我们的英文句子是“she pet the dog”,而翻译成猪拉丁语的句子是“eshay etpay ethay ogday atcay”。如果模型已经有了“eshay etpay ethay”并试图生成下一个词,“ogday”和“atcay”都是高概率的选择。根据原句“she pet the dog”的上下文,模型应该选择“ogday”。然而,如果在训练时模型能看到“ogday”,它就不需要学习如何利用上下文预测,而只需学习复制。
让我们看看掩码是如何做到这一点的。我们可以直接跳到后面的部分,因为A的第一部分在应用线性变换和将内容拆分成不同的头方面与之前完全相同。唯一点不同在于,进入缩放点积注意力部分的维度是(2,2,2,4),而不是(2,2,3,4),因为我们原始输入序列的长度为2。来看一下缩放点积注意力部分。就像我们在编码器中做的那样,我们只看批次中的第一个项目和第一个注意力头。

这次我们有一个面具。让我们来看看softmax输出和V的最终矩阵乘积。

现在我们来看看解码器中的第二个多头注意力机制B。与其他两个多头注意力块不同,这里的输入不是三个相同的张量,所以需要考虑V、K和Q分别是什么。我已经用红色标记了输入部分。可以看到,V和K的维度是(2,3,8),它们来自编码器的输出;而Q的维度是(2,2,8)。
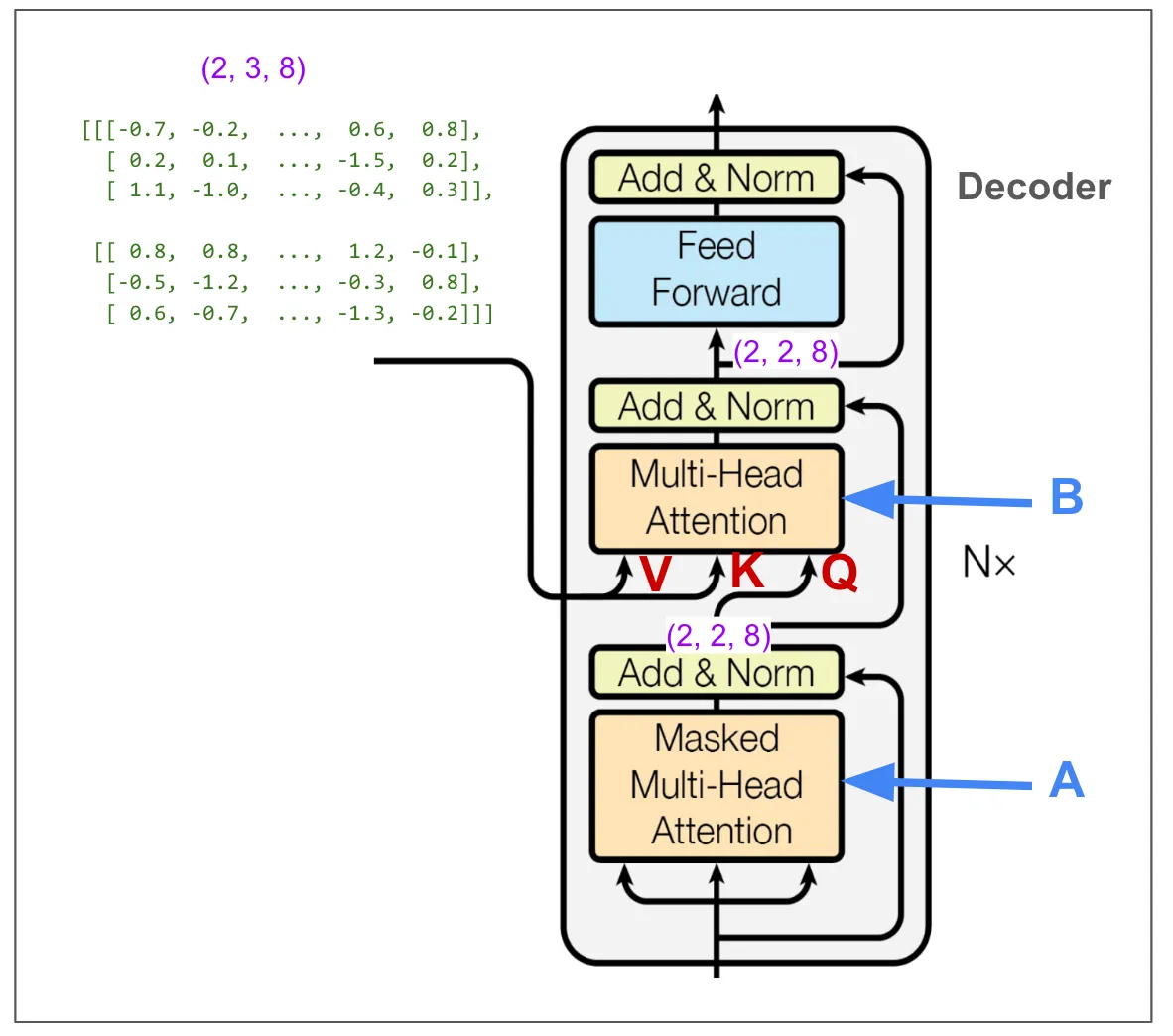
这一点也让人感到困惑,尽管有道理,但V和K的维度为(2,2,3,4)——两个批次,两个头,三个位置,长度为四的向量,而Q的维度为(2,2,2,4)。

虽然我们从编码器输出的“序列”长度为三的地方读取,经过一系列矩阵运算,我们还是得到了我们想要的维度(2,2,2,4)。让我们来看看最终的矩阵乘法过程。

每个注意力头的输出会被加在一起。我们直接看解码器的输出以及如何将它转化为预测。

线性变换将我们从(2,2,8)变换到(2,2,5)。这可以理解为反转嵌入,但与从长度为8的向量转换成单个令牌的整数标识符不同的是,我们得到的是词汇表中5个令牌的概率分布。在这样的小例子中,这些数字看起来有些奇怪。在论文中,这更像是从大小为512的向量转换到包含37,000个词汇的词汇表,当他们在进行英语到德语的翻译时。
片刻之后,我们将计算损失值。首先,你仅仅一眼就能大致看出模型的表现。
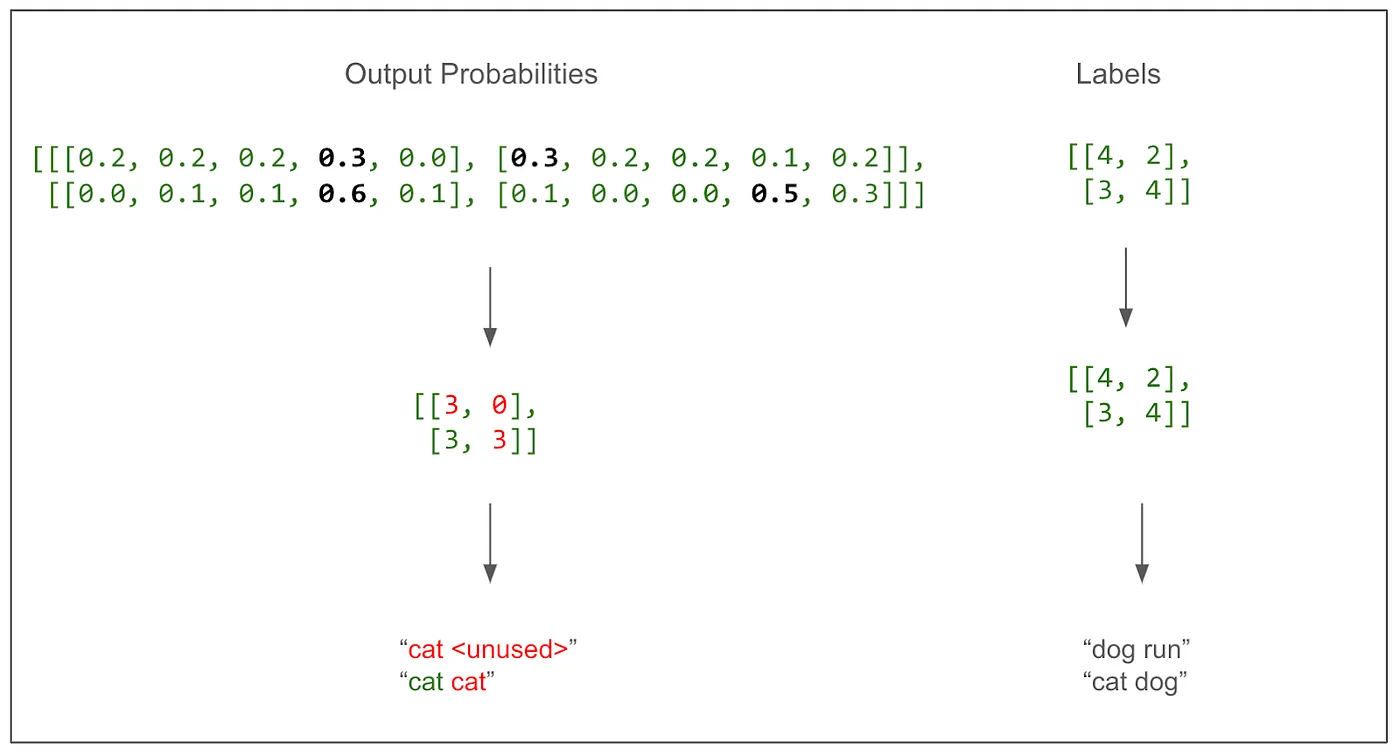
它正确地识别了一个词。这并不奇怪,因为这是我们第一次训练批次,一切都是随机的。这个图表清晰地表明这是一个多类分类问题,类别是词汇表(在这种情况中有5个类别)。这正是我之前感到困惑的地方,我们为翻译句子中的每个词进行(并评分)一次预测,而不是为整个句子进行一次预测。我们来实际计算一下损失吧。
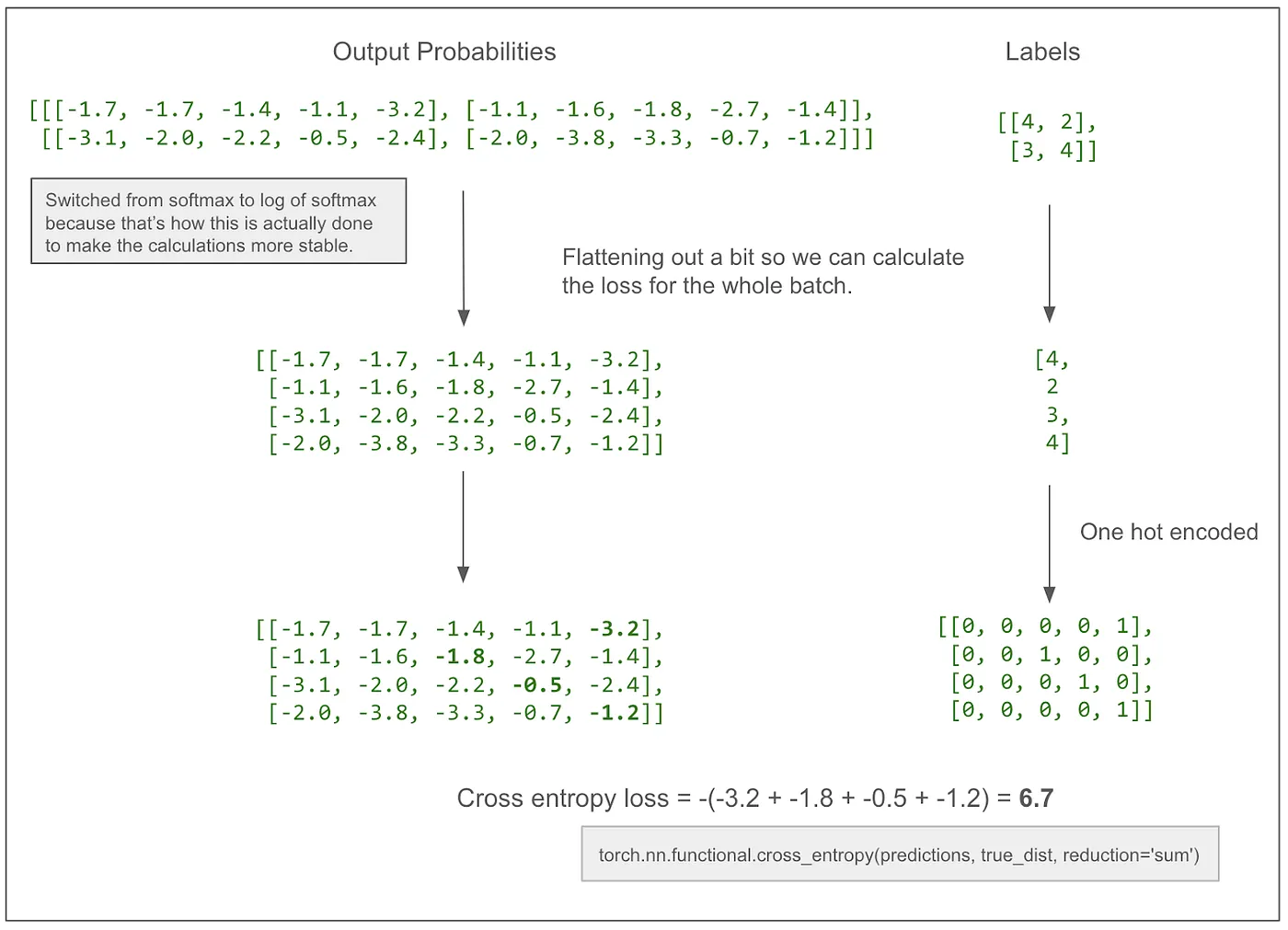
如果-3.2 变成 -2.2,损失会减少至 5.7,朝着我们期望的方向,因为这样可以让模型学会,模型应该预测第一个 token 的正确值是 4。
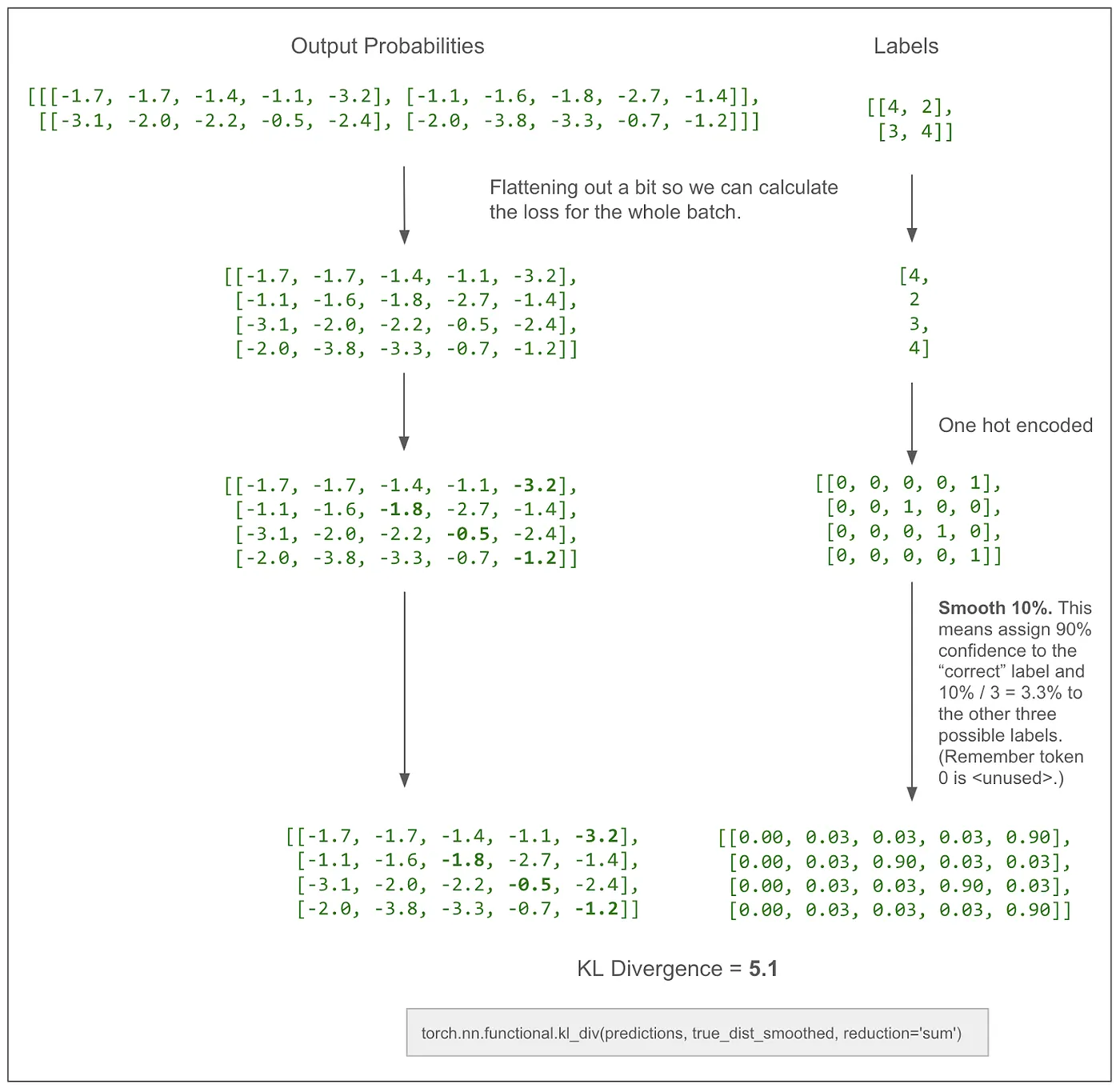
上方的图省略了标签平滑。在实际论文中,损失计算会平滑标签,并使用KL散度损失。我认为,在没有平滑的情况下,这与交叉熵的效果差不多。下面是一张加入了标签平滑的相同图表。
我们快速看一下编码器和解码器需要学习的参数数量:

作为合理性检查的一部分,我们的玩具模型中的前馈块有一个从8到32再到8的线性变换(如上所述),因此权重和偏差总共有52个参数:832(权重)+32(偏差)+328(权重)+8(偏差)。在论文中的基础模型中,_d-model_是512,_d-ff_是2048,并且有6个编码器和6个解码器,参数数量会显著增加。
使用已训练的模型现在我们来看看如何将原文输入并获取翻译输出。我仍然使用的是一个简易模型,该模型通过复制标记来实现翻译,不同于之前的模型,这次的词汇表大小为11,_d-model_为512,而之前是词汇表大小为5,_d-model_为8。
我们先翻译一下,然后再看看效果如何。

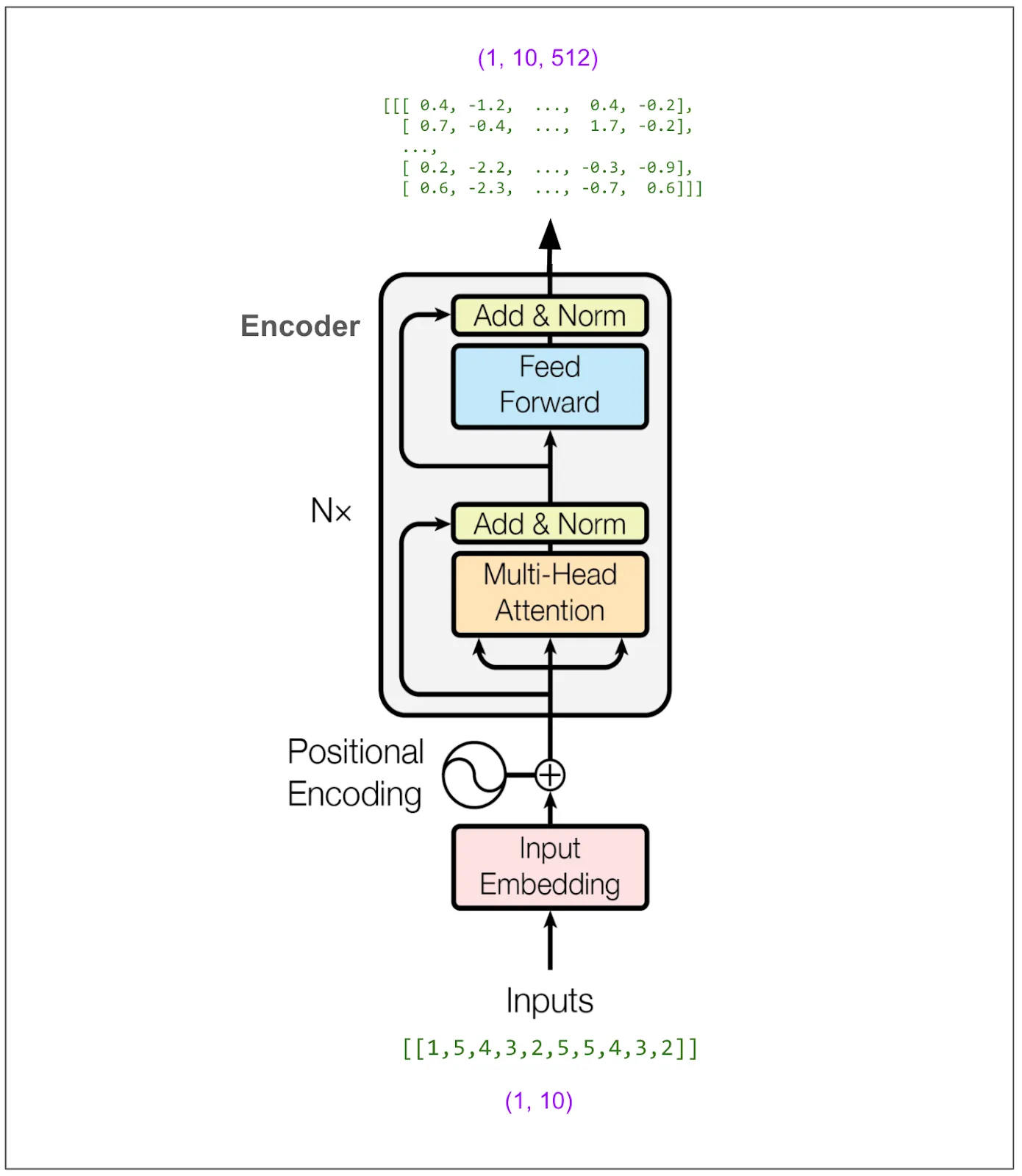
第一步是将源句子输入到编码器(encoder)中,并将其输出保存下来,在这个例子中,该输出是一个维度为(1, 10, 512)的张量(tensor)。
接下来,将输出的第一个令牌输入到解码器中,并预测第二个令牌。第一个令牌总是<start> = 1。

在论文里,他们使用了束搜索,束大小为4,意味着我们将考虑这4个概率最高的词。为了简化,我将改为使用贪婪搜索。你可以把它想象成束大小为1的情况。因此,从图的顶部开始读取,可以看出概率最高的词是编号 5。(上面的输出是对数概率。尽管最高的概率依旧是最大的数字,但这里显示的是 -0.0,实际上是 -0.004,但我只显示了一位小数。)模型对5这个选择非常确定! exp(-0.004) = 99.6%
现在我们把 [1,5] 放进解码器。如果我们进行束搜索,束宽设为 2,我们可以输入一个批次,其中包括 [1,5] 和 [1,4],也就是说,这是可能性次高的选择。
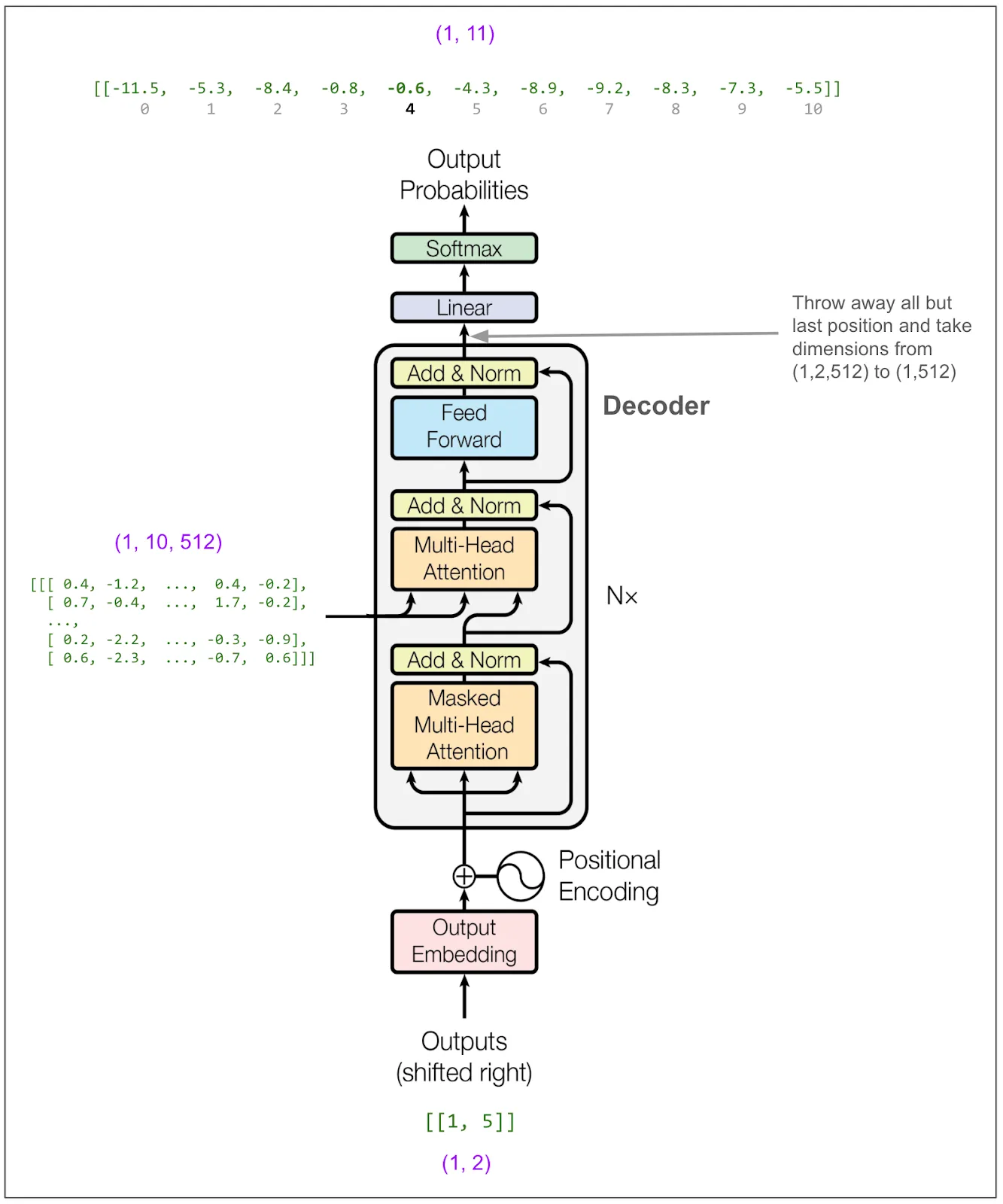
我们现在喂入 [1,5,4]:
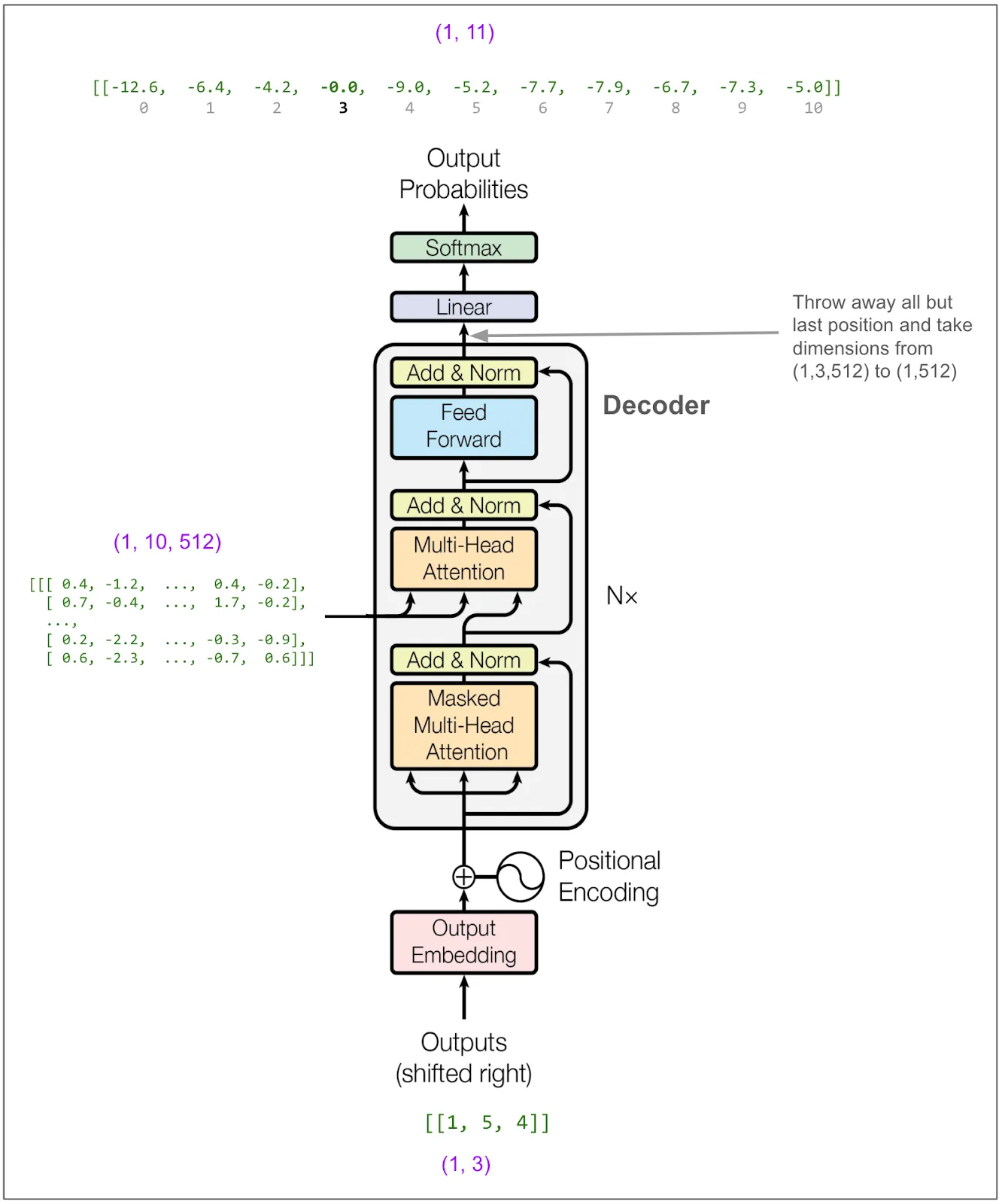
然后取出 3 这个数字。如此反复,直到遇到表示句子结束的标记(比如我们的示例词汇表中没有这个标记),或者达到规定的最大长度为止。
回到上面提到的问题现在我可以回答大部分最初的问题了。
训练时,输入是不是英文分词的句子,输出是不是德文分词的句子?嗯,差不多吧。
训练批次中的每一项都是什么呢?
每个条目都对应一个翻译过的句子。
- ‘x’项有两个部分。第一部分是源句中的所有词元。第二部分是目标句中的所有词元,除了目标句的最后一个词元。
- ‘y’标签则是目标句中的所有词元,除了第一个词元。由于源句和目标句的第一个词元始终是<start>,因此不会浪费或错失任何训练数据。
有一点微妙之处在于,如果这是一个分类任务,比如说模型需要对一张图片分类,输出一个类别(比如房子、汽车、兔子等),我们会认为,批处理中的每一项都贡献了一个“预测”到损失计算中。但是在这里,批处理中的每一项将贡献(目标句子中的词汇数减1)个“预测”到损失计算中。
为什么你要把输出输入到模型里,以及“Masked Multi-Head Attention”是如何防止模型通过学习输出信息来作弊的?首次使用时解释术语,之后用“MMH注意力”指代。你输入数据,让模型能根据原句意义和已翻译的单词来学习预测翻译。尽管模型内部有许多操作在进行,信息只在注意力步骤中传递。虽然我们确实将翻译后的句子输入解码器,但第一次注意力计算会用掩码将所有超出预测位置的信息屏蔽。
所谓的多头注意力机制到底指的是什么呢?我可能应该更详细地问问什么是注意力,因为这才是更核心的概念。多头注意力是将向量分成多个组,在这些组上分别进行注意力处理,然后再把各个组合并起来。比如说,如果向量的大小是512,有8个头,那么注意力会分别独立地在8个组上进行处理,每个组包含全批次的全位置,每个位置的向量大小为64。换句话说,每个头可能会学会关注一些相关的概念,就像著名的可视化图中展示的那样,某个头会学会代词指代哪个单词。
损失到底是怎么算的呢?不可能是简单地翻译整个原句,再计算损失,这样做根本行不通。好的。我们并不是一次性翻译一个完整的句子并计算整个句子的相似度。损失的计算就像其他多类分类问题一样。类别是词汇表中的各个词元。关键是我们独立地预测目标句子中每个词元的类别,仅使用到当前点的信息。标签是来自我们目标句子的实际词元。利用预测和标签,我们使用交叉熵计算损失。(实际上我们会“平滑处理”标签,考虑到这些标签可能不是绝对的,因为同义词有时可能同样适用。)
训练之后,你输入什么来生成翻译呢?你不能直接输入内容让模型立刻输出翻译结果。你需要多次使用模型。首先将源句子输入模型的编码部分,得到一个以某种抽象且深层次的方式表示句子意义的编码版本。然后将编码信息与<start>标记一起输入到解码部分,这样可以预测目标句子的第二个标记。然后再次输入<start>和第二个标记,以此来预测第三个标记。这样重复,直到生成完整的翻译句子。(实际上,你还需要考虑每个位置的多个高概率标记,每次输入多个候选序列,并根据总概率和长度惩罚来确定最终的翻译句子。)
为什么多头注意力模块中有三个输入箭头?我猜有三个原因。1)展示解码器中的第二个多头注意力块的一部分输入来自编码器,一部分来自解码器的前一个块。2)暗示注意力算法的运作方式。3)暗示每个输入在实际注意力操作前都会经历自己独立的线性变换。
结论太美了!如果没有这么不可思议的实用功能,我可能不会这么觉得。我现在能够感受到人们第一次看到这个东西在工作时的那种感觉。这个简洁且可训练的模型框架,仅用很少的代码就能实现各种语言的翻译,并且超越了经过多年发展的复杂机器翻译系统。它令人惊叹、聪明且不可思议。你可以想象下一步是如何说的:放弃翻译句子对,让我们用这种技术处理互联网上的每一段文字——于是大语言模型(LLMs)就诞生了。
(上面可能有些错误,请让我知道。)
如未特别注明,所有图片均为作者提供,或标注了作者的注释,这些注释是在《注意力机制无需自编码器》 中图例上的。





