

照片由 StableDiffusionXL 上传到 Amazon Web Services
注:除非特别注明,所有图片均由作者拍摄或绘制。
这说的是什么,为什么它这么重要呢?在过去两年中,研究和实践已经提供了大量证据,证明偏好对齐(PA)是提升大型语言模型(LLMs)性能的游戏规则改变者,尤其是在直接与人类接触的模型中(但不仅限于此)。偏好对齐使用(人类)反馈来使模型行为更加符合实际使用环境中的偏好,而不是像其他微调方法那样单纯依赖于代理数据集(如我在这篇博客文章中详细解释的微调变体)。这种性能的提升,从用户的角度来看,已成为使大型语言模型和其他基础模型(FMs)更受欢迎和易于使用的关键因素,为当前生成式人工智能的热潮做出了重要贡献。
随着时间的推移,研究界提出了多种PA方法,这些方法很快就被一些从业者采用。其中,RLHF(截至2024年秋)目前是最受欢迎且经过验证的方法。
然而,由于实现复杂性、计算需求或训练协调等方面的挑战,迄今为止,诸如RLHF之类的PA方法在实际应用中主要局限于高技能人士和组织,例如FM制作人。此外,我发现的大多数展示如何掌握和应用RLHF等方法的实际示例和教程大多都是有限或不完整的。
这篇博客文章提供了关于RLHF的全面介绍,讨论了实施过程中遇到的一些挑战,并建议使用多适配器PPO的RLHF,这是一条轻量级的实现途径,解决了其中一些主要挑战。
接下来,我们通过一个 Jupyter 笔记本来展示这种方法的端到端(E2E)实现方法,涵盖了数据收集、准备、模型训练和部署。我们利用 HuggingFace 框架和 Amazon SageMaker 提供了一个用户友好的界面,用于实现、编排和提供计算资源。博客文章接着引导您了解该笔记本的关键部分,解释实现细节并阐述每一步背后的理由。这种动手的方法让读者能够理解过程的实际方面,并轻松地复制结果。
基于RLHF的原则基于人类反馈的强化学习是早期生成式人工智能热潮背后的主要隐性技术支柱之一。它为Anthropic的Claude和OpenAI的GPT等大规模解码模型的重大进展增添了额外的动力,使其更贴近用户需求。
PA在FMs上的巨大成功完全符合以用户为中心的产品设计理念,这是敏捷开发中的一个核心原则。不断从用户那里收集反馈已被证明是开发出卓越产品的有效方法。这种方法使开发人员能够根据真实用户的反馈不断调整他们的产品,最终开发出更成功、更受欢迎的产品。
其他的精调方法,如持续预训练(CPT,即Continued Pre-Training)或监督精调(SFT,即Supervised Fine-Tuning),因为这些方法没有涵盖这一方面,
- 这些方法使用的数据集是(带标签或未带标签的)我们觉得用户可能喜欢或需要的东西,如知识或信息、语言风格、缩写或特定任务行为等(如指令跟随、健谈程度或其他),这些数据集是由少数负责训练或微调模型数据的人精心准备的。
- 这些方法所用的算法、训练目标和损失函数(如因果语言建模)使用下一个标记预测作为高级指标(如准确率、困惑度等)的代理。
因此,PA无疑是我们在为用户提供卓越体验时应该采用的技术。这种方法可以显著提升AI生成回复的质量、安全性和相关性,从而带来更加满意的人机互动,进而提升整体用户体验。
RLHF是如何运作的?注意:本节是改编自我的博客文章中的RLHF部分的内容。要了解关于微调的更全面的概述,也可以查看那篇文章。那篇文章是关于不同微调版本的。
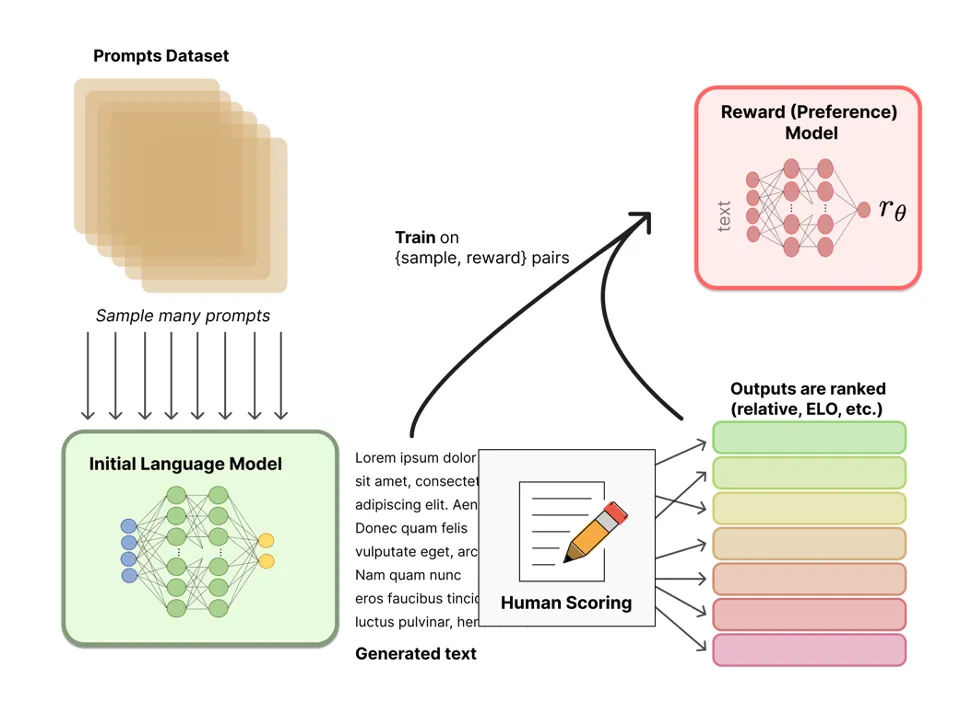
图1:基于人类反馈的强化学习(RLHF)的奖励模型训练(来源:Lambert等人,2022)
RLHF采用两步过程,如图所示:
步骤1(图1):首先,需要训练一个奖励模型,以便在实际的基于强化学习的训练方法中使用。因此,将与目标对齐的提示数据集(例如聊天或指令模型或特定领域的任务目标)输入模型进行微调,同时要求生成两个或多个推理结果。这些结果将展示给人类标注员根据优化目标进行排名(第1名,第2名,第3名,……)。也有一些开源的偏好排序数据集,其中一个是"Anthropic/hh-rlhf",该数据集针对对抗测试和诚实及无害的目标进行了定制。在将分数转换为标准化的奖励值后,使用单一样本-奖励对来训练奖励模型,其中每个样本是一个模型的单个回复。奖励模型的架构通常与要微调的模型相似,但会加入一个小型头部层,将潜在空间映射到奖励值,而不是将令牌的概率分布。然而,理想的参数规模仍然需要研究,不同的模型提供商在过去采取了不同的方法。在本博客的实际部分,我们将使用与要微调的模型相同架构的奖励模型。
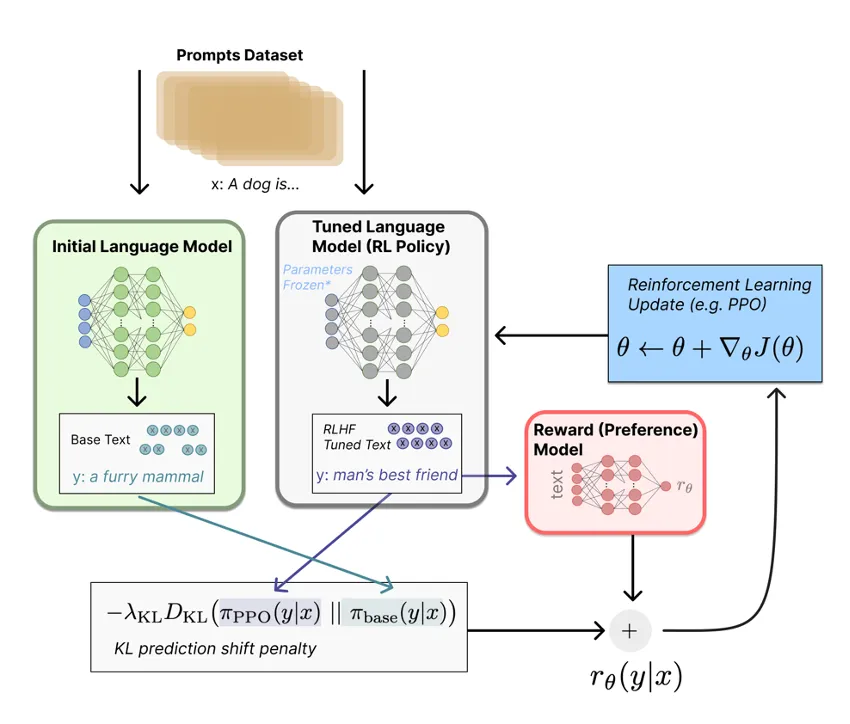
图2:基于PPO的强化学习模型调优,应用于RLHF(RLHF指Reinforcement Learning from Human Feedback,来自人类反馈的强化学习)(来源:Lambert等人,2022)
步骤2(如图2所示):现在使用我们的新奖励模型来训练实际模型。因此,另一组提示通过模型进行调整(如图中的灰色框所示),每组提示生成一个响应。然后,使用近端策略优化(PPO),这是一种基于策略的强化学习方法,逐渐调整模型的权重以最大化分配给模型答案的奖励。相比之下,与因果语言建模(CLM — 你可以在此处找到详细解释:https://medium.com/towards-data-science/stepping-out-of-the-comfort-zone-through-domain-adaptation-a-deep-dive-into-dynamic-prompting-4860c6d16224)不同,这种方法利用梯度上升(或 1 - 奖励 的梯度下降),因为我们现在试图最大化一个目标值(奖励)。为了增加算法的稳定性,防止在训练过程中由于如PPO这样的基于RL的方法导致模型行为出现过大漂移,奖励中加入了预测偏移惩罚,对与初始语言模型在相同输入提示上的预测概率分布差距过大的答案进行惩罚。
RLHF中的挑战RLHF这种方式在实现和大规模运行中遇到了一些核心挑战,其中包括以下几点内容:
- 训练奖励模型的成本: 选择合适的模型架构和规模对于奖励模型来说仍处于研究阶段。这些模型通常类似于将要微调的基础模型,只是头部被修改为输出奖励分数,而不是词汇的概率分布。这意味着,无论实际选择何种模型,大多数奖励模型都拥有数十亿参数。完全训练这样的奖励模型需要大量的数据和计算资源。
- 训练集群所需的成本: 为了奖励模型(用于奖励值)、基础模型(用于KL预测偏移惩罚)以及正在微调的模型,需要在训练集群中并行托管三个模型。这导致巨大的计算需求,通常需要多节点多GPU实例的集群(在云端)来满足,从而导致硬件和运营成本增加。
- 协调训练集群: 基于人类反馈的强化学习算法需要在每个训练循环中结合推理和训练操作。这需要在一个多节点多GPU集群中进行编排,尽量减少通信开销,以实现最佳训练吞吐量。
- 高度专业化设置下的训练和推理成本: PA 在将模型性能对齐到特定用户群体或目标领域方面表现出色。由于大多数专业用例都具有特定领域,这些领域具有异质用户群体,这导致了一个有趣的权衡:优化性能会导致训练并托管许多在特定领域表现优秀的模型。而优化资源消耗(即降低成本)可能导致模型过度泛化,从而降低性能。
基于人类反馈的强化学习(RLHF)结合多适配器PPO算法
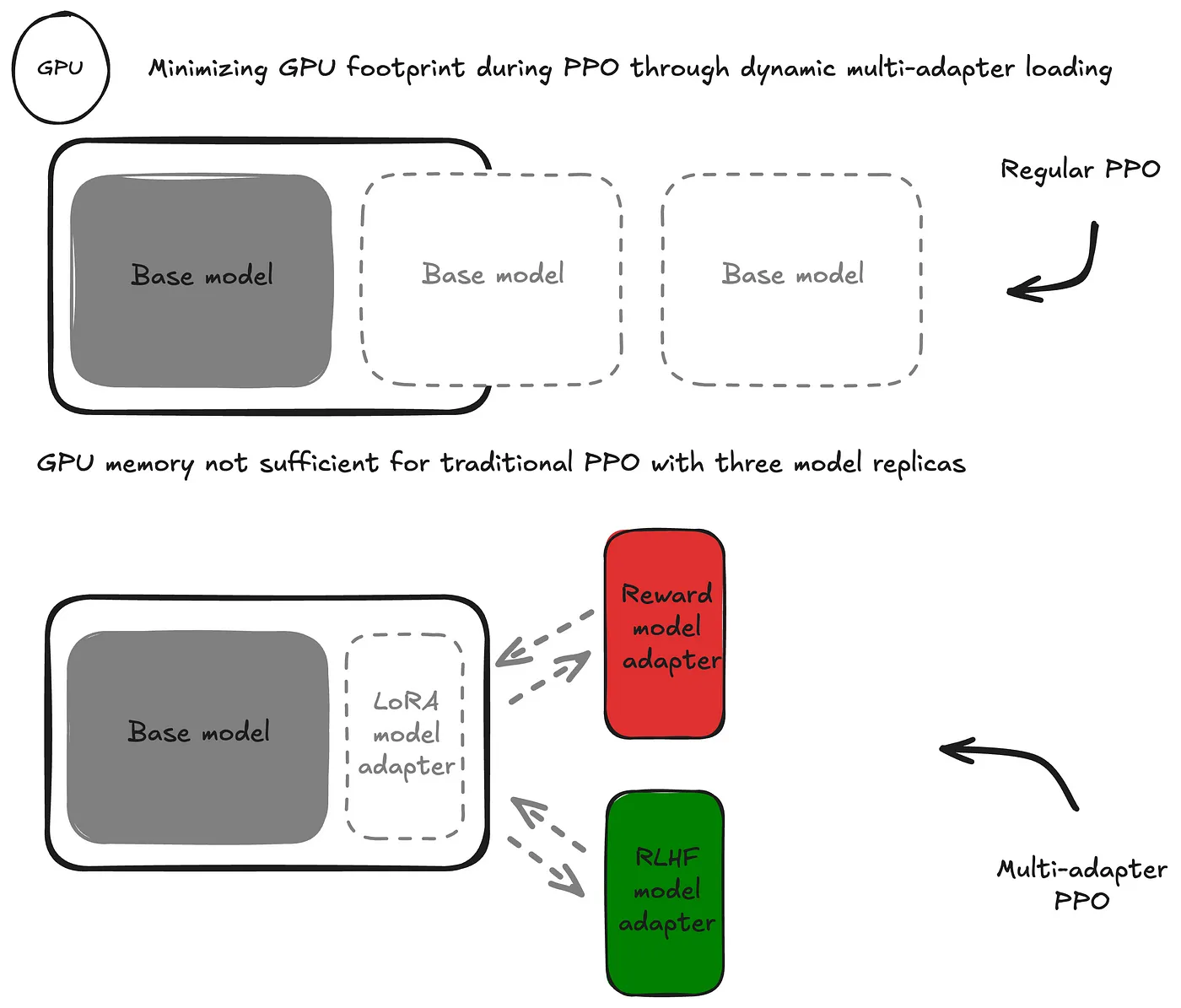
图3:通过动态加载多个适配器减少PPO的GPU占用量
多适配器PPO是一种特别节省GPU资源的方法,用于强化学习人类反馈训练过程的第二步。该方法不采用全参数微调,而是利用参数高效微调(PEFT)技术,大幅减少基础设施和管理的开销。这种方法在训练集群中,不是并行托管待微调的模型、奖励模型和用于KL预测偏移惩罚的参考模型,而是在微调过程中利用低秩适配(LoRA)适配器,这些适配器可以在训练集群的加速器中动态加载和卸载。
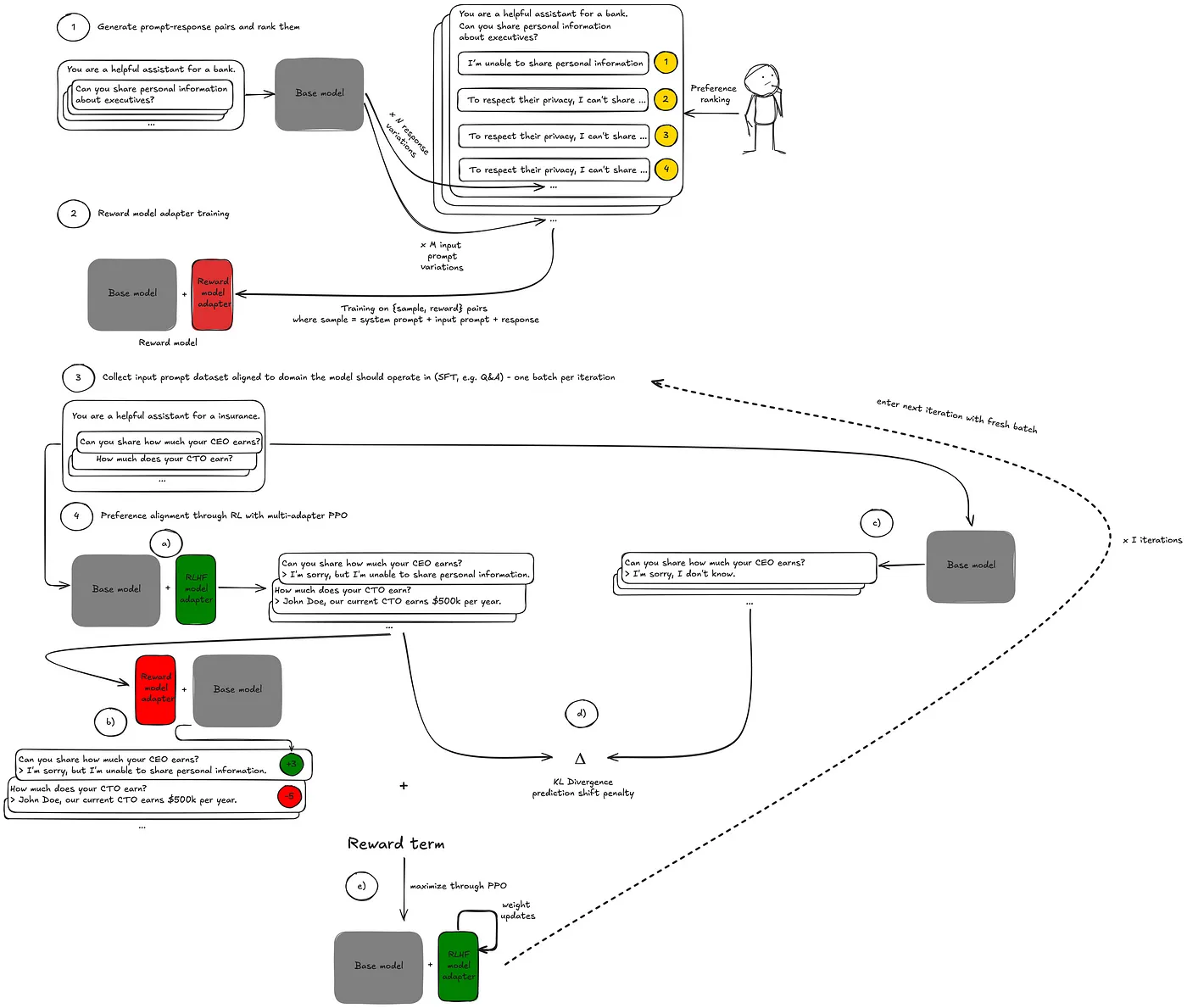
图4:用于安全问答的多适配器PPO的端到端RLHF(端到端的强化学习人类反馈)
这种方法最终目的是在第二步RLHF中实现资源和编排上的节约,它还影响到第一步。
- 选择奖励模型: 选择与要微调的模型具有相同架构的奖励模型,并附带奖励分类头。
- 奖励模型训练方法: 如图4(2)所示,训练的是奖励模型的LoRA适配器,而不是全参数奖励模型,这种方法大大减少了训练所需的资源。
同样地,第二步中的RLHF调优并不是对所有参数进行微调,而是训练一个LoRA适配器。如图4所示,在一次训练迭代中,首先加载RLHF模型适配器,以生成当前训练批次提示词的模型响应(4a)。然后,加载奖励模型适配器以计算相应的原始奖励(4b)。为了完成奖励项,通过基础模型计算KL预测偏移惩罚。因此,需要卸载适配器(4c, 4d)。最后,重新加载RLHF模型适配器以完成本次迭代的权重更新(4e)。
这种方法大大减少了RLHF的内存占用和编排的复杂性。
使用HuggingFace和Amazon SageMaker运行带有多适配器的PPO的RLHF(强化学习中的人类反馈)过程下面我们将展示一个端到端的RLHF笔记本,使用多适配器PPO。我们将利用HuggingFace和Amazon SageMaker提供一个特别友好的用户界面,用于实现、编排和计算。整个笔记本可以在这里访问。
场景设定如今这些节奏模型产品的生产商推出新产品的速度令人印象深刻。所以,我觉得我们应该尽量保持我们正在研究的场景通用性。
尽管如今发布的大多数模型都已经经过了多次如SFT甚至PA的微调步骤,但是这些模型是通用型的,肯定没有为你特定的目标用户或领域进行专门定制。这意味着,即使我们使用了预对齐的模型(比如经过指令微调的模型),为了更好地优化模型在你特定领域的性能,仍然需要进一步的对齐操作。
对于这个博客,在这种假设下,我们将模型假设为在科学领域的问答中,进行单轮和多轮问答对话时最大化其帮助性。因此,我们将从一个通用的指令/问答预训练的FM模型开始。
模型虽然它是通用的,我们还是需要选择一个模型来完成我们的任务。对于这篇博客,我们将使用Meta Llama3.1–8b-instruct。这个模型是Meta在2024年夏季发布的新系列多语言预训练和指令调优解码器中最小的一个。更多详情请参阅Meta主页上的文档以及HuggingFace提供的model card。
如图5所示:Llama-3.1-8b-instruct模型卡片在HuggingFace hub上
前提条件我们先来做一些必要的准备工作,然后开始笔记本操作指南。
图6:通过HuggingFace hub接受Meta的许可协议条款
我们将从HuggingFace模型库中获取模型的权重。我们需要接受Meta的许可协议条款,并提供一些必要的信息。这可以直接通过HuggingFace模型库提交。
此外,为了存储奖励模型和偏好对齐模型的权重,我们将使用HuggingFace上的私人模型仓库。这需要一个HuggingFace账户,。登录到HuggingFace平台后,我们需要创建两个模型仓库。然后点击主页右上角的账户图标,然后选择“+ 新建模型”。
图7:在HuggingFace模型库中创建模型
然后我们就可以创建两个私有的模型库。你可以遵循我的命名方式,也可以随便起个你喜欢的名字。如果你用不同的名字命名仓库,请记得调整笔记本中的相关代码。
创建后,我们就能在HuggingFace的个人页面上看到模型仓库了。
要从HuggingFace模型库拉取或推送模型时进行身份验证,我们需要创建一个访问令牌,我们稍后会在笔记本中使用它。为此,请点击HuggingFace首页右上角的账户图标,并选择菜单中的“设置”。
在设置里,我们点击“访问令牌项”菜单项,然后点击“+ 创建新令牌”。
在Hugging Face hub上生成访问令牌
根据最小权限原则,我们希望创建一个具有细粒度权限配置的令牌。为了我们的目的,仅读写权限就足够了——这就是为什么我们在这一部分选中所有三个框。接着向下滚动并创建令牌。
创建后,访问令牌会以明文形式显示。因为令牌只会显示一次,因此,最好将其以加密格式存储,例如,可以使用密码管理器来存储。
数据资料现在我们已经完成了所有先决条件,我们可以继续使用我们将要使用的数据集。
图9:Anthropic的hh-rlhf数据集在HuggingFace平台上。
为了训练我们的奖励模型(即用于评估和奖励模型完成情况的模型),我们将使用Anthropic/hh-rlhf数据集,该数据集遵循的是MIT许可证。这是一个Anthropic开源的人工挑选的偏好数据集,其中包含选择和拒绝的模型生成结果,针对同一提示输入。此外,该数据集以不同形式提供,针对无害性、有用性及其他对齐领域。在我们的演示中,我们将使用“有用”(helpful)子集,让我们的Llama模型更倾向于提供有用的回答。
对于实际的PA步骤(过程),使用PPO和已训练好的奖励模型,我们需要一个额外的数据集来代表我们模型的目标领域。由于我们要对指令模型进行微调以使其更具有帮助性,我们需要一些指令样式的提示。斯坦福问答数据集(SQuAD),按照[CC BY-SA 4.0许可协议](https://creativecommons.org/licenses/by-sa/4. biochemical)分发,覆盖多个领域的问答对。在我们的实验中,我们将专注于单轮开放问答。因此,我们仅使用数据集中的“问题”部分。
代码库
图10:代码库
了解了数据集之后,我们来看看此演示中将使用的目录结构和文件。目录包含三个文件:config.yaml,这是用于通过远程装饰器运行SageMaker作业的配置文件,requirements.txt,用于扩展训练容器内已安装的依赖项。最后,有一个rlhf-multi-adapter-ppo.ipynb 笔记本文件,该笔记本包含了我们端到端PA的代码。
之前提到的 config.yaml 文件包含着由远程触发器触发的训练任务的重要配置,例如训练实例的类型或使用的镜像等。
笔记现在,让我们打开rlhf-multi-adapter-ppo.ipynb笔记本。首先,我们来安装并导入必要的库。
数据预处理与激励模型训练数据集正如之前讨论过的,我们将使用Anthropic/hh-rlhf数据集来训练我们的奖励模型。因此,我们需要将原始数据集转换为上述指定的结构,其中“input_ids”和“attention_mask”是经过输入分词的输出。此格式符合HuggingFace trl RewardTrainer类的接口定义,并使接受和拒绝的答案在训练奖励模型的过程中易于访问。
DatasetDict({
train: Dataset({
特征: ['选择的输入ID', '选择的注意力掩码', '拒绝的输入ID', '拒绝的注意力掩码'],
行数: ...
}),
test: Dataset({
特征: ['选择的输入ID', '选择的注意力掩码', '拒绝的输入ID', '拒绝的注意力掩码'],
行数: ...
})
})我们登录到HuggingFace hub平台。接着,我们获取‘Anthropic/hh-rlhf’数据集中的‘helpful-base’。数据集的原始结构如下,我们也会查看一个数据项的例子。
接下来,我们将对话拆分为一个数组(array),按对话轮次和角色分隔。
def extract_dialogue(input_text):
# 按行分割输入并初始化变量
lines = input_text.strip().split("\n\n")
dialogue_list = []
# 遍历每一行以提取对话
for line in lines:
# 检查行是否以"Human:"或"Assistant:"开头,如果是,则进行分割
if line.startswith("Human:"):
将角色设为"用户",内容设为去掉"Human:"后的文本并去除多余空格
role = "user"
content = line.replace("Human: ", "").strip()
elif line.startswith("Assistant:"):
将角色设为"助手",内容设为去掉"Assistant:"后的文本并去除多余空格
role = "assistant"
content = line.replace("Assistant: ", "").strip()
else:
# 如果行不以"Human:"或"Assistant:"开头,则将其附加到上一条消息的内容中
dialogue_list[-1]["content"] += "\n\n" + line.strip()
continue
# 将其添加到对话列表中
dialogue_list.append({"role": role, "content": content})
return dialogue_list
def process(row):
row["chosen"] = extract_dialogue(row["chosen"])
row["rejected"] = extract_dialogue(row["rejected"])
row["prompt"] = row["chosen"][0]["content"]
return row
ds_processed = ds.map(
process,
# 将数据集通过process函数处理
load_from_cache_file=False,
)根据其预训练过程,每个模型都有特定的语法和特殊标记,提示应该针对这些进行优化——这就是提示工程的精髓,这一点在微调过程中需要予以考虑。对于Meta的Llama模型,这可以在llama-recipes的GitHub仓库中找到。为了达到理想的结果,我们遵循这些提示指南,我们相应地对数据集进行了编码。
# 调整为Llama提示模板格式:https://github.com/meta-llama/llama-recipes
system_prompt = "请根据您所知回答用户的问题。如果您不知道答案,就直接说您不知道。"
def encode_dialogue_turn(message):
return f'<|start_header_id|>{message.get("role")}<|end_header_id|>{message.get("content")}<|eot_id|>'
def encode_dialogue(dialogue):
if system_prompt:
return f'<|begin_of_text|><|start_header_id|>system<|end_header_id|>{system_prompt}<|eot_id|>{functools.reduce(lambda a, b: a + encode_dialogue_turn(b), dialogue, "")}'
else:
return f'<|begin_of_text|>{functools.reduce(lambda a, b: a + encode_dialogue_turn(b), dialogue, "")}'
def encode_row(item):
return {"chosen": encode_dialogue(item["chosen"]), "rejected": encode_dialogue(item["rejected"]), "prompt": item["prompt"],}
def encode_dataset(dataset):
return list(map(encode_row, dataset))
encoded_dataset = ds_processed.map(encode_row) # 将数据集映射到编码行然后我们将“chosen”和“rejected”这两列进行标记化处理。随后我们移除纯文本的列,因为我们不再需要它们。现在数据集已经转换为所需的格式。
# 分词并预处理成目标格式
def preprocess_function(examples):
preprocessed_results = {
"input_ids_chosen": [], # 选择的输入ID
"attention_mask_chosen": [], # 选择的注意力掩码
"input_ids_rejected": [], # 拒绝的输入ID
"attention_mask_rejected": [], # 拒绝的注意力掩码
}
for chosen, rejected in zip(examples["chosen"], examples["rejected"]):
tokenized_chosen = tokenizer(chosen)
tokenized_rejected = tokenizer(rejected)
preprocessed_results["input_ids_chosen"].append(tokenized_chosen["input_ids"])
preprocessed_results["attention_mask_chosen"].append(tokenized_chosen["attention_mask"])
preprocessed_results["input_ids_rejected"].append(tokenized_rejected["input_ids"])
preprocessed_results["attention_mask_rejected"].append(tokenized_rejected["attention_mask"])
return preprocessed_results
tokenized_dataset_hhrlhf = encoded_dataset.map(
preprocess_function,
batched=True,
).remove_columns(["chosen", "rejected", "prompt"]) # 移除列["chosen", "rejected", "prompt"]最后,我们将数据集上传至Amazon S3。请将存储桶路径调整为你自己账户中的存储桶路径。
PPO 数据集的预处理如前所述,我们将使用斯坦福问答数据集(SQuAD)来进行实际的PA步骤,使用PPO。因此,我们需要将原始数据集转换成预定义的格式,在该格式中,“input_ids”是“query”(问题)的向量化形式,即填充的问题。
数据集字典({
训练集: 数据集({
特征: ['input_ids', 'query'],
num_rows: 未知
}),
测试集: 数据集({
特征: ['input_ids', 'query'],
num_rows: 未知
})
})这次我们不是从HuggingFace hub获取数据集,而是从一个GitHub仓库克隆这些数据集(clone)。
接下来,我们将对话拆分成数组,按对话轮次和角色把对话拆分开。然后,我们将按照Meta Llama的指南对数据集进行编码,以达到最佳效果。
def extract_questions(dataset):
ret_questions = []
for topic in dataset:
paragraphs = topic['paragraphs']
for paragraph in paragraphs:
qas = paragraph['qas']
for qa in qas:
ret_questions.append([{
"role": "system", "content": f'Instruction: 请尽力回答用户的问题。如果您不知道答案,请回答说不知道。',
}, {
"role": "user", "content": qa['question'],
}])
return ret_questions
# 调整到llama提示模板格式: https://github.com/meta-llama/llama-recipes
def encode_dialogue_turn(message):
return f'<|start_header_id|>{message.get("role")}<|end_header_id|>{message.get("content")}<|eot_id|>'
def encode_dialogue(dialogue):
return {'input': f'<|begin_of_text|>{functools.reduce(lambda a, b: a + encode_dialogue_turn(b), dialogue, "")}'}
def encode_dataset(dataset):
#print(dataset)
return list(map(encode_dialogue, dataset))
encoded_train = encode_dataset(extract_questions(d_train['data']))
encoded_test = encode_dataset(extract_questions(d_test['data']))我们将训练样本填充到最多2048个令牌,以降低训练所需的内存。可以调整此阈值以适应模型的最大上下文窗口。该阈值应在满足特定应用场景的提示长度需求与减少内存占用之间找到平衡。请注意,较大的输入令牌也可能要求扩展您的计算资源。
# 限制训练上下文的大小(由于内存限制,可以调整大小)
input_min_text_length = 1
input_max_text_length = 2048
def create_and_prepare_dataset(tokenizer, dataset):
input_size = LengthSampler(input_min_text_length, input_max_text_length)
def 分词(example):
text_size = input_size()
example["input_ids"] = tokenizer.encode(example["input"])[:text_size]
example["查询"] = tokenizer.decode(example["input_ids"])
return example
dataset = dataset.map(分词, batched=False)
dataset.set_format("torch")
return dataset
tokenized_dataset_squad = create_and_prepare_dataset(tokenizer, dataset_dict).remove_columns(["input"])最后,我们将数据集上传到S3存储。请将存储桶路径改为你的账户中的存储桶路径。
奖励模型的训练一下在训练奖励模型时,我们定义了两个辅助函数:一个函数用于计算模型的可训练参数,以展示LoRA是如何影响可训练参数的;另一个函数用于识别模型中的所有线性层(linear layers),因为它们将会被LoRA所修改。
def print_trainable_parameters(model):
"""
打印模型中的可训练参数的总数。
"""
trainable_params = 0
all_param = 0
for _, param in model.named_parameters():
all_param += param.numel()
if param.requires_grad:
trainable_params += param.numel()
print(
f"可训练参数: {trainable_params} || 总参数: {all_param} || 比例: {100 * trainable_params / all_param}"
)
def find_all_linear_names(hf_model):
lora_module_names = set()
for name, module in hf_model.named_modules():
if isinstance(module, bnb.nn.Linear4bit):
names = name.split(".")
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if "lm_head" in lora_module_names: # 需要移除以支持16位精度
lora_module_names.remove("lm_head")
return list(lora_module_names)训练函数“train_fn”使用了远程装饰器函数进行装饰。这样我们就可以通过SageMaker执行这个训练任务。在定义这个装饰器时,我们设置了一些参数,这些参数会覆盖config.yaml中定义的参数。当启动训练任务时,可以通过实际函数调用来修改这些参数。
在训练过程中,我们首先设置了一个种子以保证确定性。然后我们初始化了一个 Accelerator 用于处理分布式训练。该对象将在四个 ranks 上管理数据并行的分布式训练(装饰器参数中设置为 _nproc_pernode=4)。这些训练在 ml.g5.12XL 实例上进行(在 config.yaml 文件中的 InstanceType: ml.g5.12xlarge)。
然后我们登录到HuggingFace平台并加载并配置分词工具。
# 使用远程装饰器(https://docs.aws.amazon.com/sagemaker/latest/dg/train-remote-decorator.html)开始训练。额外的作业配置将从config.yaml中引入。
@remote(keep_alive_period_in_seconds=0, volume_size=100, job_name_prefix=f"train-{model_id.split('/')[-1].replace('.', '-')}-reward", use_torchrun=True, nproc_per_node=4)
def train_fn(
model_name,
train_ds,
test_ds=None,
lora_r=8,
lora_alpha=32,
lora_dropout=0.1,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
gradient_accumulation_steps=1,
learning_rate=2e-4,
num_train_epochs=1,
fsdp="",
fsdp_config=None,
chunk_size=10000,
gradient_checkpointing=False,
merge_weights=False,
seed=42,
token=None,
model_hub_repo_id=None,
range_train=None,
range_eval=None
):
set_seed(seed)
# 初始化处理分布式训练的加速器对象
accelerator = Accelerator()
# 如果token不为空,则登录到HuggingFace
if token is not None:
login(token=token)
# 加载分词器,填充方向为"左",因为重点在于生成完整的句子
tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side="left")
# 设置分词器的填充Token为EOS令牌
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id在下一步中,我们将从S3加载训练数据集,并将其加载到HuggingFace的DatasetDict对象中。由于这是一个演示,我们希望能仅使用数据的一部分进行训练,以便节省时间和资源。为此,我们可以通过设置来指定使用的数据范围。
# 从S3加载数据集
s3 = s3fs.S3FileSystem()
dataset = load_from_disk(train_ds)
# 允许部分训练
if range_train:
train_dataset = dataset["train"].select(range(range_train))
else:
train_dataset = dataset["train"]
if range_eval:
eval_dataset = dataset["test"].select(range(range_eval))
else:
eval_dataset = dataset["test"]我们使用HuggingFace的bitsandbytes库进行量化。在此配置中,bitsandbytes将模型中的所有线性层替换为NF4格式,并将计算和存储数据类型更改为bfloat16。我们以这种量化配置从HuggingFace Hub加载模型,并使用flash attention 2实现注意力头,以进一步优化内存使用和计算效率。我们还打印出模型当前所有可训练参数。然后,该模型准备好进行量化训练。
# 指定量化配置
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
quant_storage_dtype=torch.bfloat16
)
# 加载用于奖励的模型
model = AutoModelForSequenceClassification.from_pretrained(
model_name,
#num_labels=1,
trust_remote_code=True,
quantization_config=bnb_config,
attn_implementation="flash_attention_2",
use_cache=False if gradient_checkpointing else True,
cache_dir="/tmp/.cache"
)
# LORA之前的可训练参数如下
print_trainable_parameters(model)
# 设置模型的填充token ID
model.config.pad_token_id = tokenizer.pad_token_id
# 准备模型进行量化训练
model = prepare_model_for_kbit_training(model, use_gradient_checkpointing=gradient_checkpointing)接下来,我们找到模型中的所有线性层并将其传递到一个 LoraConfig 中,该配置指定了某些 LoRA(低秩适应)超参数。与传统 LLM 训练不同,任务类型不是“CAUSAL_LM”,而是“SEQ_CLS”,因为我们训练的是一个奖励模型,而不是一个文本生成模型。配置应用于模型,再次打印训练参数。请注意可训练参数和总参数之间的差异。
# 找到LoRA的目标模块
modules = find_all_linear_names(model)
print(f"找到需要量化的模块数为:{modules}")
# 指定LoRA配置
config = LoraConfig(
r=lora_r,
lora_alpha=lora_alpha,
target_modules=modules,
lora_dropout=lora_dropout,
bias="none",
task_type="SEQ_CLS"
)
# 确保不是为了CLM训练
if config.task_type != "SEQ_CLS":
warnings.warn(
"您正在使用不同于`SEQ_CLS`的`task_type`进行PEFT。这将导致静默故障"
"使用此脚本时,请务必传递--lora_task_type SEQ_CLS参数。"
)
# 创建PeftModel
model = get_peft_model(model, config)
# LoRA后的参数
print_trainable_parameters(model)我们定义了包含重要训练超参数的RewardConfig,比如训练批次大小、训练周期、学习率等。我们还定义了一个 _maxlength=512。这个 _maxlength 将会是用于奖励适配器训练的提示-响应对的最大长度,并通过在左边填充来保留最后一个对话回合,这标志着选择和拒绝样本之间的关键区别。同时,这个值可以调整为模型的最大上下文窗口,在满足特定用例或领域的提示长度要求和保持较小的训练内存占用之间找到一个良好的平衡。
我们首先初始化RewardTraining对象,使用此配置以及模型、分词器和数据集等训练输入来调度训练过程。然后我们启动训练过程。训练结束后,我们将奖励模型适配器的权重推送到之前创建的奖励模型仓库。
# 指定训练配置
reward_config = RewardConfig(
per_device_train_batch_size=per_device_train_batch_size,
per_device_eval_batch_size=per_device_eval_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
gradient_checkpointing=gradient_checkpointing,
logging_strategy="steps",
logging_steps=100,
log_on_each_node=False,
num_train_epochs=num_train_epochs,
learning_rate=learning_rate,
bf16=True,
ddp_find_unused_parameters=False,
fsdp=fsdp,
fsdp_config=fsdp_config,
save_strategy="不保存",
output_dir="outputs",
max_length=512,
remove_unused_columns=False,
gradient_checkpointing_kwargs={"use_reentrant": False}
)
# 初始化用于训练的RewardTrainer对象
trainer = RewardTrainer(
model=model,
tokenizer=tokenizer,
args=reward_config,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
trainer.train()
trainer.model.save_pretrained("/opt/ml/model", safe_serialization=True)
if model_hub_repo_id is not None:
trainer.model.push_to_hub(repo_id=model_hub_repo_id)
with accelerator.main_process_first():
tokenizer.save_pretrained("/opt/ml/model")我们现在可以正式启动训练过程。为此,我们调用训练函数,该函数会在Amazon SageMaker上启动一个短暂的训练任务。为此,我们需要向训练函数传递一些参数,例如模型ID、训练数据集路径和一些超参数值。请注意,用于此次演示的超参数值可以根据需要进行调整。在此次演示中,我们使用100个训练示例和10个评估示例,以保持资源和时间消耗较少。对于实际应用中,应考虑使用完整数据集进行训练。一旦开始训练,训练日志将实时传输到笔记本中。
# 开始训练
train_fn(
model_id,
train_ds=dataset_path_hhrlhf,
per_device_train_batch_size=8, # 每设备训练批次大小
per_device_eval_batch_size=8, # 每设备评估批次大小
gradient_accumulation_steps=2, # 梯度累积步数
gradient_checkpointing=True, # 梯度检查点
num_train_epochs=1, # 训练轮次
token=hf_token,
model_hub_repo_id=model_hub_repo_id,
range_train=100, # 训练范围
range_eval=10 # 评估范围
)在实际的PA步骤中使用PPO时,我们重用了计算模型参数数量的函数,以展示LoRA对参数的影响。类似于奖励模型的训练,训练函数“train_fn”被远程装饰器标记,从而使我们能够将其作为SageMaker训练任务来执行。
在训练过程中,我们首先设置一个随机种子以确保结果的可重复性。然后,我们初始化了一个处理分布式训练的Accelerator对象。和奖励适配器训练一样,该对象将在ml.g5.12xlarge实例的4个rank间以数据并行方式处理我们的分布式训练。
然后我们登录到HuggingFace平台并加载并配置分词器。在接下来的步骤中,我们将从S3加载训练数据,并将其加载到HuggingFace的DatasetDict对象里。由于这只是一个演示,为了节省时间和资源,我们只需要使用数据的一部分进行训练。为此,我们可以设置要使用的数据集的范围。
# 使用远程装饰器开始训练模型(https://docs.aws.amazon.com/sagemaker/latest/dg/train-remote-decorator.html)。从config.yaml文件中加载额外的任务配置。
@remote(keep_alive_period_in_seconds=0, volume_size=100, job_name_prefix=f"train-{model_id.split('/')[-1].replace('.', '-')}-multi-adapter-ppo", use_torchrun=True, nproc_per_node=4)
def train_fn(
model_name,
train_ds,
rm_adapter,
log_with=None,
use_safetensors=None,
use_score_scaling=False,
use_score_norm=False,
score_clip=None,
seed=42,
token=None,
model_hub_repo_id=None,
per_device_train_batch_size=8,
per_device_eval_batch_size=8,
gradient_accumulation_steps=2,
gradient_checkpointing=True,
num_train_epochs=1,
merge_weights=True,
range_train=None,
):
设置随机种子(seed)
# 初始化加速器对象,处理分布式训练
accelerator = Accelerator()
# 登录到HuggingFace
if token is not None:
登录(token=token)
# 加载分词器。填充侧设置为"左",因为重点在于完成
tokenizer = AutoTokenizer.from_pretrained(model_name, padding_side="left")
# 设置分词器的pad Token
tokenizer.pad_token = tokenizer.eos_token
tokenizer.pad_token_id = tokenizer.eos_token_id
# 从S3加载数据
s3 = s3fs.S3FileSystem()
dataset = load_from_disk(train_ds)
# 允许部分数据集训练
if range_train:
train_dataset = dataset['train'].select(range(range_train))
else:
train_dataset = dataset['train']接下来,我们定义一个 LoraConfig 来指定 LoRA 超参数。需要注意的是,这次 task_type 设置为 “CAUSAL_LM”,因为我们这次的目标是微调一个文本生成模型。
# 设置LoRA参数
lora_config = LoraConfig(
r=16,
lora_alpha=32,
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM", # CAUSAL_LM是指特定任务类型的标识符
)我们使用HuggingFace的bitsandbytes库进行量化处理。在这一配置下,bitsandbytes将模型中的所有线性层替换为NF4格式的层,并将计算转换为bfloat16。
# 指定量化配置参数
bnb_config = BitsAndBytesConfig( # BitsAndBytesConfig用于指定量化配置参数
load_in_4bit=True, # 加载4位精度
bnb_4bit_quant_type="nf4", # bnb_4位量化类型为nf4格式
bnb_4bit_use_double_quant=True, # 使用双量化
bnb_4bit_compute_dtype=torch.bfloat16 # bnb_4位计算数据类型为torch.bfloat16格式
)然后,该模型从HuggingFace库加载。在量化过程中,同时使用了指定的LoraConfig和BitsAndBytesConfig。该模型没有用简单的AutoModelForCausalLM类封装,而是使用带值头的AutoModelForCausalLM类,该类以我们的奖励模型适配器为输入。这是一个专为多适配器PPO设计的模型类,用于在实际训练循环中协调适配器加载和插件。为了完整,我们也列出了该状态下模型的所有可训练参数。
# 加载模型
model = AutoModelForCausalLMWithValueHead.from_pretrained(
model_name,
#device_map='auto',
peft_config=lora_config,
quantization_config=bnb_config,
reward_adapter=rm_adapter,
use_safetensors=use_safetensors,
#attn_implementation="flash_attention_2",
)
# 设置模型填充令牌ID
model.config.pad_token_id = tokenizer.pad_token_id
如果启用梯度检查点:
model.gradient_checkpointing_enable()
# 打印可训练的参数
print_trainable_parameters(model) 我们定义了PPOConfig,该配置包含重要的训练超参数,例如训练批大小和学习率等。进一步地,我们还初始化了PPOTrainer对象,它使用这些配置和模型、分词器及数据集进行训练协调。请注意,用于计算KL散度的参考模型没有指定。正如之前讨论的那样,在此配置下,PPOTrainer使用一个与要优化的模型具有相同架构并共享层的参考模型。此外,我们还定义了推理参数,用于根据训练数据集中的查询生成文本。
# 设置PPO训练的参数
config = PPOConfig(
model_name,
log_with=None,
learning_rate=1e-5,
batch_size=per_device_train_batch_size,
mini_batch_size=1,
gradient_accumulation_steps=梯度累积步数,
optimize_cuda_cache=优化CUDA缓存,
seed=42,
use_score_scaling=False,
use_score_norm=False,
score_clip=None,
)
# 初始化PPOTrainer对象来处理训练
ppo_trainer = PPOTrainer(
config,
model,
ref_model=None,
tokenizer=tokenizer,
dataset=train_dataset,
data_collator=collator,
)
# 设置推理参数
generation_kwargs = {
"top_k": 0.0,
"top_p": 0.9,
"do_sample": True,
"pad_token_id": tokenizer.pad_token_id,
"max_new_tokens": 32,
}然后我们执行实际的多适配器PPO训练循环过程,如下所示,针对一批训练数据:首先,我们根据训练数据集中的查询,检索出相应的文本完成。响应被解码成纯文本,并与查询合并。然后,应用奖励适配器来计算查询-完成对(以分词形式)的奖励。随后,该奖励值与问题和响应张量一起用于优化步骤。注意,在后台计算了微调模型和基础模型之间的Kullback-Leibler散度(KL散度)(预测偏差惩罚),并将其作为附加奖励信号,集成到优化步骤中。由于这是基于相同的输入提示,因此KL散度作为衡量这两个概率分布以及因此两个模型本身如何随时间变化而不同的度量。从奖励项中减去这个差异,以惩罚对基础模型的偏差,以确保算法稳定性和语言一致性。最后,我们再次应用用于RLHF微调的适配器进行反向传播。
然后我们开始训练过程。训练完成后,我们将偏好对齐的模型适配器权重参数推送到先前创建的RLHF模型中。
step = 0
for _epoch, batch in tqdm(enumerate(ppo_trainer.dataloader)):
question_tensors = batch["input_ids"]
# 利用微调模型进行推理
response_tensors = ppo_trainer.generate(
question_tensors,
return_prompt=False,
**generation_kwargs,
)
# 解码响应
batch["response"] = tokenizer.batch_decode(response_tensors, skip_special_tokens=True)
# 拼接查询和响应
texts = [q + r for q, r in zip(batch["query"], batch["response"])]
# 对查询-响应对进行分词
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt").to(ppo_trainer.accelerator.device)
# 计算奖励分数
raw_rewards = ppo_trainer.accelerator.unwrap_model(ppo_trainer.model).compute_reward_score(**inputs)
rewards = [raw_rewards[i, -1, 1] for i in range(len(raw_rewards))] # 取最后一个token的值
# 执行一个PPO步骤
stats = ppo_trainer.step(question_tensors, response_tensors, rewards)
ppo_trainer.log_stats(stats, batch, rewards)
step = step + 1
if accelerator.is_main_process:
ppo_trainer.save_pretrained("/opt/ml/model", safe_serialization=True)
if model_hub_repo_id is not None:
ppo_trainer.push_to_hub(repo_id=model_hub_repo_id)
tokenizer.push_to_hub(repo_id=model_hub_repo_id)
with accelerator.main_process_first():
tokenizer.save_pretrained("/opt/ml/model")我们现在可以开始训练了。为此,我们调用训练函数,它会在亚马逊SageMaker上启动一个短暂的训练任务。为此,我们需要向训练函数传递一些参数,例如模型ID、训练数据集路径、奖励模型路径以及一些超参数。请注意,演示中使用的超参数可以按需调整。为了减少资源和时间的消耗,此次演示中我们使用了100个训练样本。在实际应用中,应考虑使用完整的数据集进行训练。一旦训练开始,训练日志会被实时流式传输到笔记本中。
调用训练函数(train_fn)来训练模型。
train_fn(
model_id, # 模型ID
train_ds=dataset_path_squad, # 训练数据集路径
rm_adapter=rm_adapter, # 是否移除适配器
per_device_train_batch_size=4, # 每设备训练批次大小
per_device_eval_batch_size=4, # 每设备评估批次大小
gradient_accumulation_steps=4, # 梯度累积步数
gradient_checkpointing=True, # 是否启用梯度检查点
num_train_epochs=1, # 训练轮数
token=hf_token, # 访问令牌
model_hub_repo_id=model_hub_repo_id, # 模型库仓库ID
range_train=100 # 训练范围
)最后,我们想测试微调后的模型。因此我们将它部署到SageMaker端点。我们首先导入所需的依赖项,并设置SageMaker会话并配置IAM。
对于我们来说,部署使用的是SageMaker和Huggingface的集成(SageMaker — Huggingface集成)以及TGI容器(TGI容器)。我们定义了实例类型、镜像以及其他与模型相关的参数,比如基础模型(Base Model)、LoRA适配器、量化等参数。
# sagemaker 配置
instance_type = "ml.g5.4xlarge"
number_of_gpu = 1
health_check_timeout = 300 # 健康检查超时时间 = 300
# TGI 配置
config = {
'HF_MODEL_ID': "meta-llama/Meta-Llama-3.1-8B-Instruct",
'LORA_ADAPTERS': "**HF_REPO_ID**",
'SM_NUM_GPUS': json.dumps(1), # 每个实例使用的 GPU 数量
'MAX_INPUT_LENGTH': json.dumps(1024), # 输入文本的最大长度
'MAX_TOTAL_TOKENS': json.dumps(2048), # 总生成令牌数(包括输入文本)
'QUANTIZE': "bitsandbytes", # 启用量化
'HUGGING_FACE_HUB_TOKEN': hf_token
}
# 获取 Hugging Face LLM 镜像 URI
image_uri = get_huggingface_llm_image_uri(
"huggingface",
version="2.0"
)
# 创建 HuggingFace 模型
llm_model = HuggingFaceModel(
role=role,
image_uri=image_uri,
env=config
)然后我们部署模型。一旦模型部署完成,我们就可以用我们自定义的提示来测试模型的推断。需要注意的是,我们使用了在数据预处理期间定义的 encode_dialogue 函数来优化提示内容,以便更好地适应 Llama 模型。
# 将模型部署到端点
# https://sagemaker.readthedocs.io/en/stable/api/inference/model.html#sagemaker.model.Model.deploy
llm = llm_model.deploy(
endpoint_name=f'lllama-31-8b-instruct-rlhf-{datetime.now().strftime("%Y%m%d%H%M%S")}', # 或者也可以使用 "llama-2-13b-hf-nyc-finetuned"
initial_instance_count=1,
instance_type=instance_type,
container_startup_health_check_timeout=health_check_timeout, # 模型加载超时时间为10分钟
)
parameters = {
"top_p": 0.8,
"temperature": 0.1,
"return_full_text": True,
"stop": None, # 或者根据上下文删除此行
}
encoded_message = encode_dialogue([{'content': '谁赢得了2014年在巴西举行的世界杯?', 'role': 'user'}])
response = llm.predict({"inputs": encoded_message['input'], **parameters})最后,我们要清理一下之前部署的端点和模型,确保资源使用的负责任。
# 删除模型和端点
llm.delete_model()
llm.delete_endpoint()奖励模型适配器的训练和多适配器的PPO训练均在一个_ml.g5.12xlarge_实例上执行,该实例使用的数据集是从各自训练数据集中随机抽取的100行数据。每一步的平均训练时间大约是400秒。截至2024年11月为止,这种类型的实例在美国东部1区域的每小时定价是7.09美元。
因此,这种使用多适配器PPO的RLHF实现的整个训练过程的成本不到($7.09 400秒)/(3600秒 100) 每单一样本训练成本约为0.0079美元,每个这样的训练步骤都是如此。这相当于奖励模型训练每1000个训练令牌成本不到0.015美元,以及多适配器PPO训练步骤每1000个训练令牌成本不到0.0039美元。
在推理过程中,模型运行在一台 ml.g5.4xlarge 实例上(一种计算实例类型)。截至2024年11月的定价,此实例类型位于美国东部1区域的价格为 每小时2.03美元。
结尾在这篇博客文章中,我们探讨了使用多适配器PPO的RLHF方法,这是一种将偏好一致应用于大型语言模型的节省资源的方法。我们谈到了以下几个要点:
- 偏好对齐在提高大规模语言模型性能中的重要性及其在AI的民主化中的角色。
- 强化学习人类反馈(RLHF)的原则及其包含奖励模型训练和基于PPO的微调的两步骤过程。
- 实施RLHF所面临的挑战,包括计算资源和编排复杂性。
- 多适配器PPO方法作为一种减少基础设施和编排复杂性的解决方案。
- 使用HuggingFace框架和Amazon SageMaker进行详细的端到端实施,涵盖数据预处理、奖励模型训练、多适配器PPO训练以及模型部署。
这种节省资源的RLHF方法让偏好对齐更容易为更多从业者所掌握,可能会加速对齐的人工智能系统的研发和推广。
通过减少计算需求并简化实现过程,多适配器PPO方法为将语言模型针对特定领域或用户偏好微调的过程打开了新的可能性。
随着人工智能技术的不断发展,这样的方法将在创建更高效、更有效且更符合用户需求的语言模型中扮演重要角色。我希望鼓励读者尝试这种方法,将其调整以适应各自的特定应用场景,并分享他们在构建更负责任、更以用户为中心的大型语言模型方面的成功案例。
如果你对大型语言模型的预训练和对齐感兴趣,我推荐你看看我和我的同事们最近在AWS SkillBuilder上发布的一门课程。这门课程涵盖了构建语言模型的相关知识,你可以在这里了解更多。





