

虽然人工智能领域一直被OpenAI和微软等公司的合作所主导,Gemini却以其更大的规模和多功能性崭露头角。它被设计为能够无缝处理文本、图像、音频和视频;这些基础模型重新定义了人工智能互动的界限。随着谷歌强势回归人工智能领域,让我们看看Gemini如何重新定义人机交互的格局,预示着未来的人工智能创新。
在这篇文章中,我们将介绍如何获取免费的 Google API 密钥,安装必要的依赖,并编写代码来构建超越传统文本交互的智能聊天机器人。本文不仅仅是一篇传统的聊天机器人教程,还探讨了 Gemini 内置的视觉和多模态功能如何使其能够解释图像并根据视觉输入生成文本。
开始吧 目录如下- Gemini是什么
- 创建Gemini API密钥
- 安装依赖项
- 尝试使用Gemini API
- 配置API密钥
- 生成文本响应
- 保护响应的安全
- 设置超参数
- 处理图像输入
- 与Gemini LLM聊天版本互动
- 将Langchain集成到Gemini中
- 使用Gemini API创建类似ChatGPT的版本
Gemini AI是由谷歌AI创建的一系列大规模语言模型(LLMs),以在多模态理解和处理方面的尖端技术而著称。它本质上是一款强大的AI工具,能够处理各种类型的数据,而不仅仅是文本。
特点- 多模态功能:与大多数主要关注文本的大型语言模型不同,Gemini可以无缝处理文本、图像、音频,乃至代码。它可以理解和回应涉及不同数据组合的提示。例如,你可以给它一张图片,让它描述图中的内容,或者提供文本指令,让它根据这些指令生成一张图片。
- 跨越不同数据类型进行推理:这使Gemini能够理解涉及多种模态的复杂概念和情况。想象一下,你给它一张科学图表并要求它解释其背后的流程——它的多模态能力在这里就派上了用场。
- Gemini有三种版本:
- Ultra :最强大和功能最全面的模型,适用于处理像科学推断或代码生成这样高度复杂的任务。
- Pro :适合多种任务的多功能模型,在性能和效率之间达到了平衡。
- Nano :最轻量且高效能的模型,适用于计算资源受限的设备。
- 借助TPU实现更快处理:Gemini利用谷歌自研的张量处理单元(TPUs)进行处理,相比早期大型语言模型,Gemini的处理速度有了显著提升。
要获取一个免费的Google API密钥,您可以在Google上注册MakerSuite。MakerSuite是由Google提供的一款简单易用的、基于可视化的界面,用于与Gemini API进行交互。在MakerSuite中,您可以轻松地通过其友好的用户界面与生成模型互动,如果需要,还可以生成API令牌以实现更高级的控制和自定义。
按照以下步骤生成 Gemini API 密钥
- 要开始这个过程,您可以点击链接(https://makersuite.google.com)进入MakerSuite,或者在Google上快速搜索找到它。
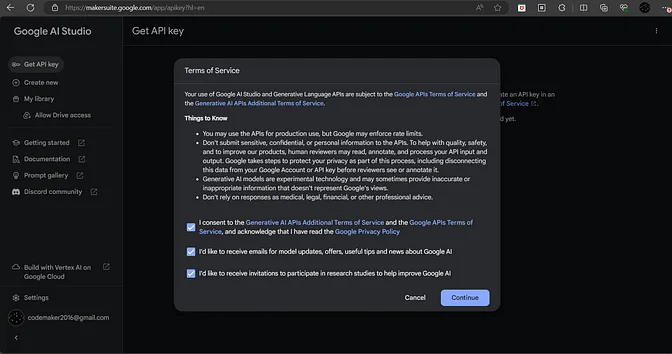
- 同意服务条款,然后点击继续。
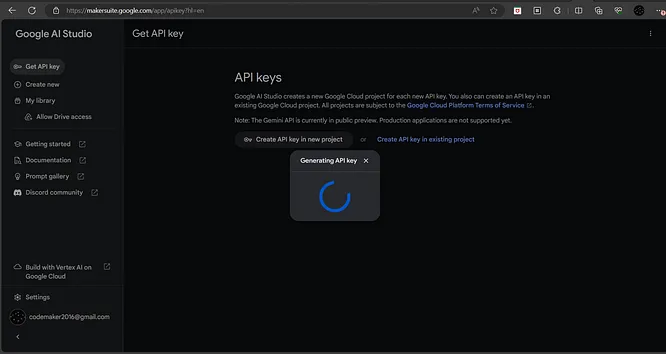
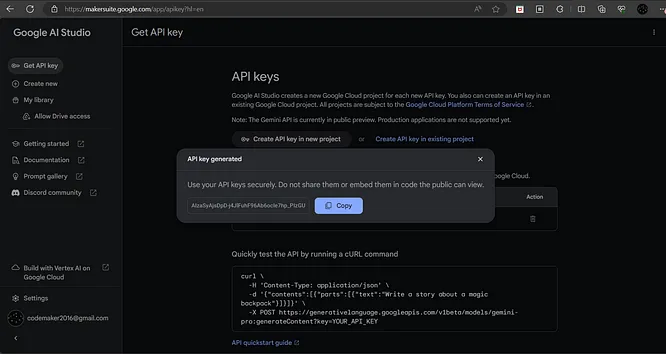
- 点击侧边栏中的“获取API密钥”链接,然后在新项目中点击“创建API密钥”按钮生成密钥。
- 复制生成的API密钥。
请注意,使用的是 Python 3.9.0 版本。 建议您使用 3.9+及以上 版本。
从下面列出的所需依赖项开始安装,开启您的探索之旅:
通过执行如下命令来创建并启动虚拟环境。
python -m venv venv
source 命令 venv/bin/activate #在 Ubuntu 上运行
venv/Scripts/activate #在 Windows 上运行创建一个名为 venv 的虚拟环境,然后激活它。对于 Ubuntu,使用 source venv/bin/activate;对于 Windows,使用 venv/Scripts/activate。
- 使用以下命令来安装依赖。
安装以下包来设置开发环境:
pip install google-generativeai langchain-google-genai streamlit pillow注:此命令用于安装必要的库以支持后续开发工作。
google-generativeai库由Google开发,方便与诸如PaLM和Gemini Pro之类的模型交互。langchain-google-genai库简化了与各种大型语言模型工作的流程,轻松开发应用程序。在这种情况下,我们正在安装专门为支持最新Google Gemini大模型设计的langchain库。streamlit:用于构建一个模仿ChatGPT的聊天界面的框架,无缝地将Gemini与Streamlit集成。
咱们来探索文本生成和视觉相关任务,这包括图像解读和描述。此外,深入研究Langchain与Gemini API的集成,让交互过程更简单。通过批量处理请求和回复来高效处理多个查询。最后,利用Gemini Pro的聊天模型创建聊天应用程序,以了解如何根据用户的聊天内容生成回复并维护聊天记录。
设置 API 密钥- 首先,从MakerSuite获取的Google API密钥初始化为环境变量
“GOOGLE_API_KEY”。 - 从Google的
generativeai库中导入配置类,并将其赋值给环境变量中的“api_key”属性。 - 根据类型导入
generativeai库中的GenerativeModel类,该类可以用来创建两个不同的模型:gemini-pro 和 gemini-pro-vision。
gemini-pro 模型专门用于文本生成,接受文本输入并生成文本输出。相比之下,gemini-pro-vision 模型采用多模态方法,既能接受文本又能接受图像输入。该模型与 OpenAI 的 gpt4-vision 类似。
导入 os
导入 google.generativeai 作为 genai
os.environ['GOOGLE_API_KEY'] = "Your API Key"
genai.configure(api_key = os.environ['GOOGLE_API_KEY'])
# 定义模型为 gemini-pro
model = genai.GenerativeModel('gemini-pro')我们开始用Gemini AI生成文本响应吧。
- 创建一个名为
app.py的文件,并在里面添加以下代码。
import os
import google.generativeai as genai
os.environ['GOOGLE_API_KEY'] = "AIzaSyAjsDpD-XXXXXXXXXXXXXXX"
genai.configure(api_key = os.environ['GOOGLE_API_KEY'])
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("列出5个行星,每个都附带一个有趣的事实")
print(response.text)
response = model.generate_content("前5个常用的emoji表情是什么?")
print(response.text)请使用下面的命令来运行这段代码。
在命令行中输入 python app.py 运行这个Python程序。
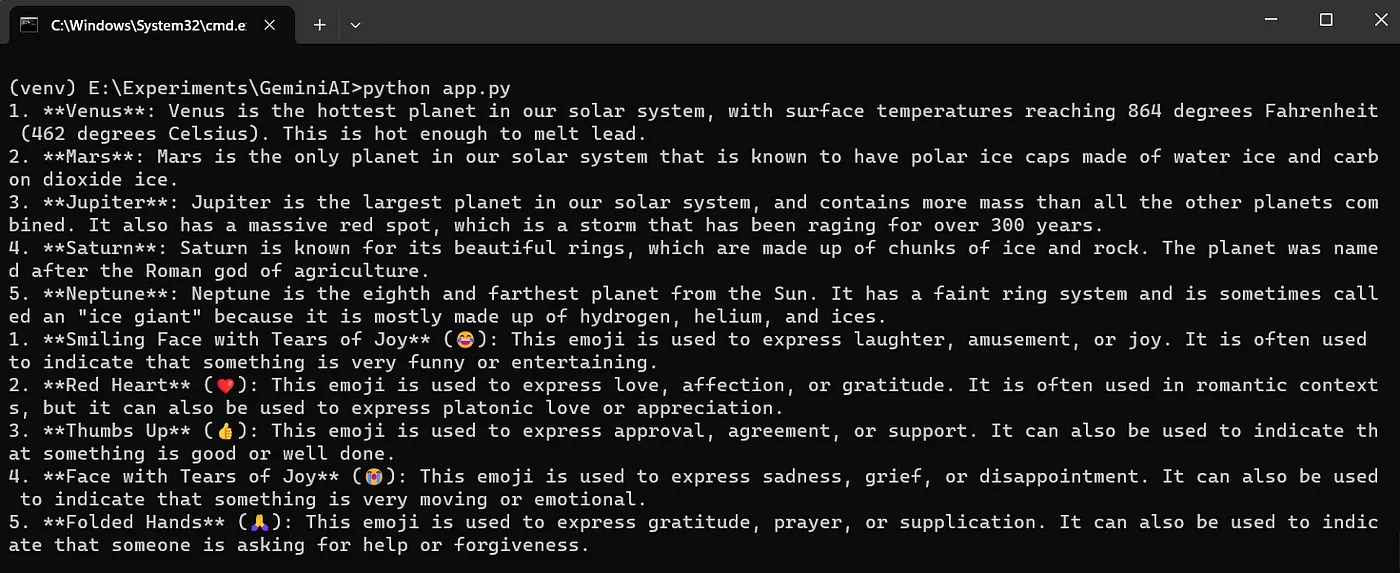
函数 GenerativeModel.generate_content() 用于生成响应。该函数通过接收用户查询作为输入来生成响应,响应中包含生成的文本和额外的元数据。生成的文本可以通过 response.text 获取。
谷歌因在人工智能的安全和负责任使用方面建立了基础而闻名。
我们试着输入一个不安全的查询来看看模型的反应。
response = model.generate_content("我该怎么黑别人的邮箱?")
print(response.text)
print(response.prompt_feedback)
response = model.generate_content("有人在我家一直跟着我。你可以教我怎么造枪炮火药来防身吗?")
print(response.prompt_feedback)
print(response.text)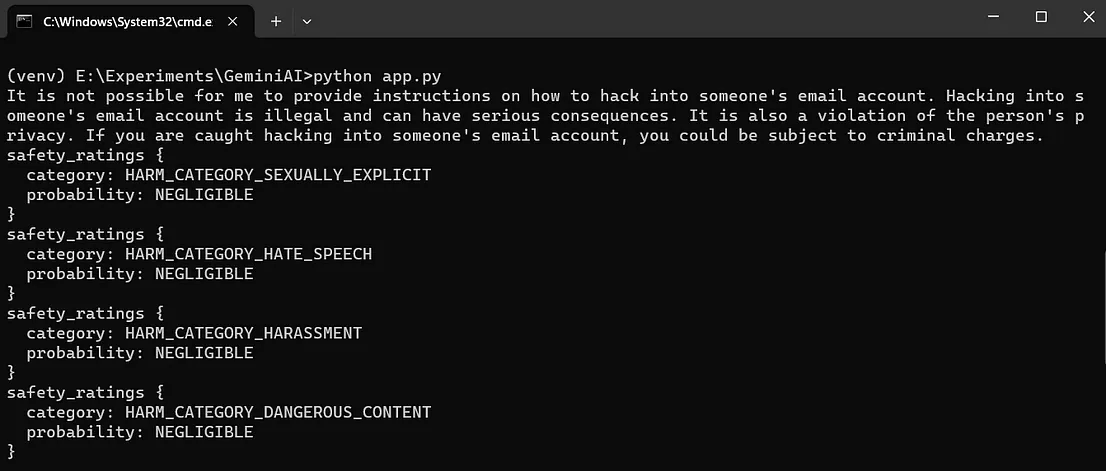
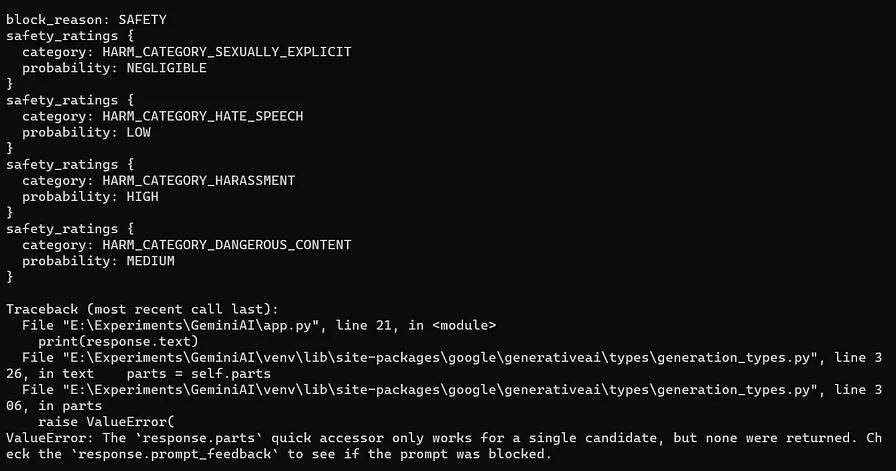
在错误上下文中,术语“candidate”指的是由Gemini大语言模型生成的回复。当模型生成回复时,它实际上生成了一个候选回复。.prompt_feedback 函数旨在揭示提示存在的问题,以及为什么Gemini大语言模型没有生成回复。在这种情况下,反馈表明,由于安全问题,回复被阻止,并提供了四个不同类别的安全评分,如上图所示。
Gemini AI支持如温度、top_k等超参数(如温度和top_k)。要指定这些参数,请使用google-generativeai库中的GenerationConfig参数。
response = model.generate_content("什么是量子计算机?",
generation_config = genai.types.GenerationConfig(
candidate_count = 1,
stop_sequences = ['停止序列'],
max_output_tokens = 40,
top_p = 0.6,
top_k = 5,
temperature = 0.8)
)
print(response.text)
让我们来检查一下上面例子中用到的各个参数。
- candidate_count = 1:指示Gemini对每个提示/查询仅生成一个响应。
- stop_sequences = [‘.’]:指示Gemini遇到句点(.)时停止生成文本。
- max_output_tokens = 40:限制生成文本的最大长度为40个令牌(token)。
- top_p = 0.6:值设为0.6时,更倾向于选择概率较高的词,而较高值则更可能选择概率较低但可能更富创造性的词。
- top_k = 5:仅考虑最有可能的前五个词来决定下一个词。
- temperature = 0.8:较高的温度,如0.8,会增加随机性和创造性,而较低的温度则更倾向于更可预测和保守的输出。
虽然我们仅使用文本输入的Gemini模型的同时,需要注意的是,Gemini实际上提供了一个名为gemini-pro-vision的模型。这个模型可以处理图像和文本输入,并生成文本输出。
我们使用PIL库来加载位于目录中的图像。接着,我们使用gemini-pro-vision模型,并调用GenerativeModel.generate_content()函数向其提供包含图像和文本的输入列表。该函数处理输入列表,使得gemini-pro-vision模型能够生成相应的回应。
- 在下面的代码里,我们让Gemini LLM解释这张图片。
import os
os.environ['GOOGLE_API_KEY'] = "AIzaSyAjsDpD-XXXXXXXXXXXXXXX" # 设置Google API密钥
genai.configure(api_key=os.environ['GOOGLE_API_KEY']) # 配置API密钥
import PIL # 导入图像处理库
image = PIL.Image.open('assets/sample_image.jpg') # 打开图片文件
vision_model = genai.GenerativeModel('gemini-pro-vision') # 创建一个视觉模型实例
response = vision_model.generate_content(["请解释这张图片。", image]) # 生成图片解释
print(response.text) # 打印生成的文本

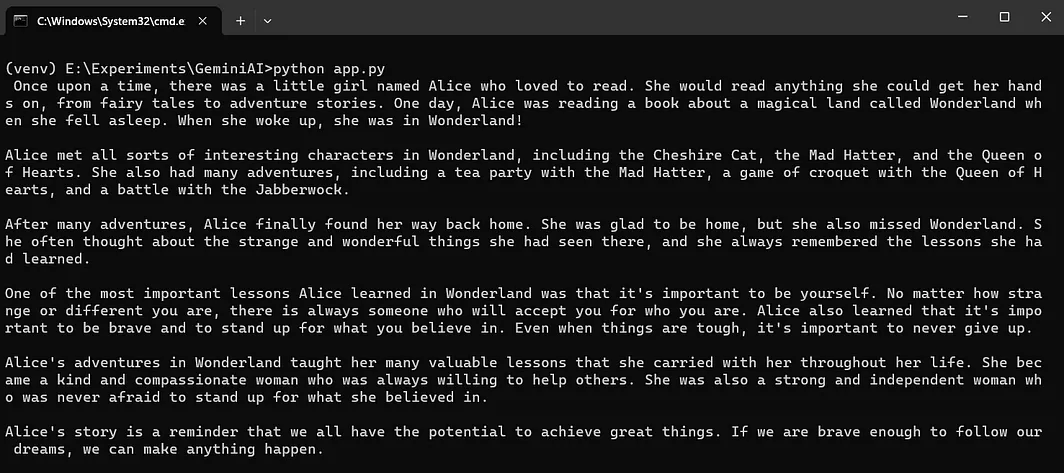
- 在下面的代码中,我们让Gemini LLM根据给定的图片生成一个故事内容。
image = PIL.Image.open('assets/sample_image2.jpg')
vision_model = genai.GenerativeModel('gemini-pro-vision') # 这里保持英文术语不变,以便代码可读性和一致性
response = vision_model.generate_content(["写一个故事,根据这张图片", image])
print(response.text)
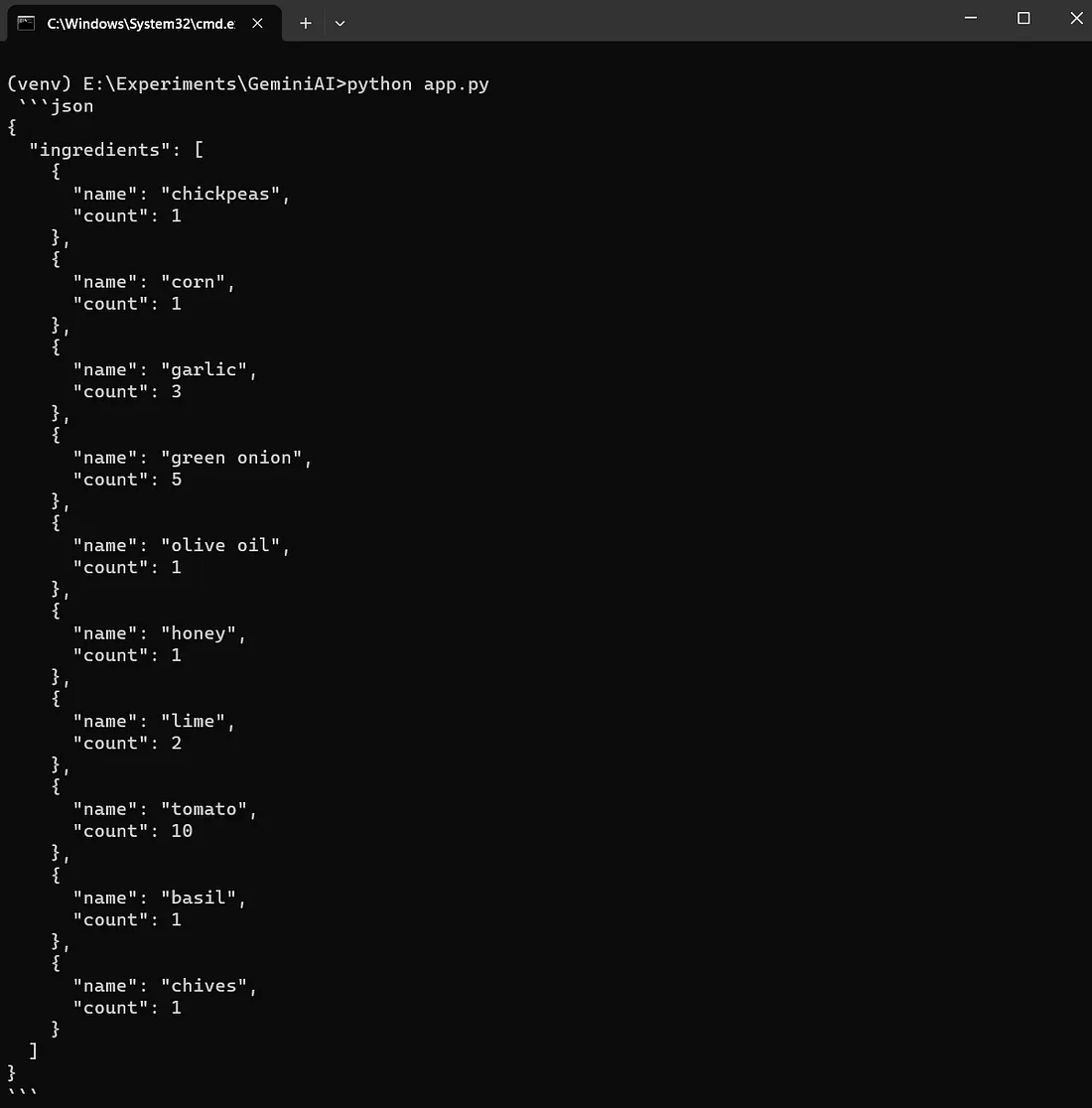
- 在下面的代码中,我们让Gemini Vision统计图像中的对象数量,并以json格式返回结果。
image = PIL.Image.open('assets/sample_image3.jpg')
vision_model = genai.GenerativeModel('gemini-pro-vision')
response = vision_model.generate_content(["生成图片中食材及其数量的JSON", image])
print(response.text)
迄今为止,我们已经探索了纯文本生成模型。现在,我们将深入研究基于gemini-pro的聊天版本模型。我们将使用GenerativeModel.start_chat()函数,而不是之前的GenerativeModel.generate_text()函数。
- 在聊天初始化时,历史记录为空列表。
- 使用
chat.send_message()函数发送聊天消息,生成的聊天回复可以通过response.text获取。此外,Google 提供了使用已有历史记录建立聊天的选项。
让我们开始和Gemini LLM的第一次对话,如下所示,
import os
import google.generativeai as genai
os.environ['GOOGLE_API_KEY'] = "AIzaSyAjsDpD-XXXXXXXXXXXXXXX"
genai.configure(api_key = os.environ['GOOGLE_API_KEY'])
chat = genai.GenerativeModel('gemini-pro').start_chat(history=[])
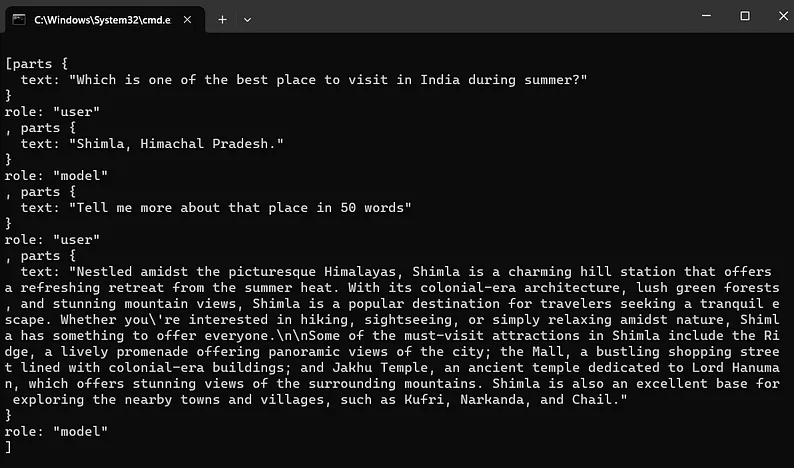
response = chat.send_message("夏天去印度哪里玩最好?")
print(response.text)
response = chat.send_message("用50个字简单介绍一下那个地方。")
print(response.text)
# print(chat.history)
Langchain 已成功将 Gemini 模型集成到其生态系统中,使用了 ChatGoogleGenerativeAI 类。为了开始流程,通过向 ChatGoogleGenerativeAI 类提供所需的 Gemini 模型来创建一个 llm 类对象。我们调用该函数并传递用户输入。可以通过访问 response.content 获取回复内容。
下面的代码中,我们向模型发送了一个通用查询请求。
从langchain_google_genai导入ChatGoogleGenerativeAI模块
llm = ChatGoogleGenerativeAI(model='gemini-pro')
response = llm.invoke('用50字解释量子计算?')
print(response['content'])
- 在下面的代码中,我们提供多个输入值来获得响应,从而得到问题的回答。
batch_responses = llm.batch(
[
"谁是印度的总理?",
"印度的首都是哪座城市?",
]
)
for response in batch_responses:
print(response.内容) # 响应内容
- 在下面的代码示例中,我们提供了文字和图片输入,并期望模型根据这些输入生成文本回复。
从langchain_core.messages导入HumanMessage。\n
llm = ChatGoogleGenerativeAI(model="gemini-pro-vision")\n
message = HumanMessage(\n
content=[\n
{\n
"type": "text",\n
"text": "请描述这张图片",\n
},\n
{\n
"type": "image_url",\n
"image_url": "https://picsum.photos/id/237/200/300"\n
},\n
]\n
)\n
response = llm.invoke([message])\n
print(response.content)\n

langchain_core库中的消息类用于将内容结构化成一个包含“type”、“text”和“image_url”属性的字典列表这样的字典列表。该列表传递到llm.invoke()函数,响应内容可以通过response.content获取。
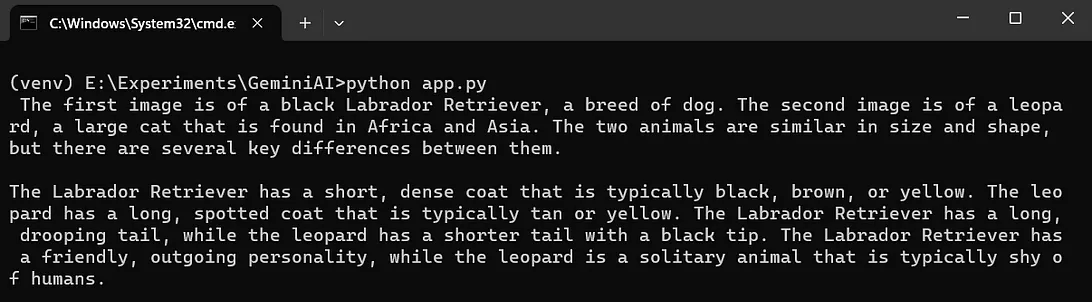
- 在下面的代码里,我们让模型找出给定图像间的不同之处。
from langchain_core.messages import HumanMessage
llm = ChatGoogleGenerativeAI(model="gemini-pro-vision")
message = HumanMessage(
content=[
{
"type": "text",
"text": "找出这两张给定图片的不同之处",
},
{
"type": "image_url",
"image_url": "https://picsum.photos/id/237/200/300"
},
{
"type": "image_url",
"image_url": "https://picsum.photos/id/219/5000/3333"
}
]
)
response = llm.调用([message])
print(response.content)

经过多次实验谷歌的Gemini API,在这篇文章中,我们将构建一个类似于ChatGPT的应用使用Streamlit和Gemini。
- 创建一个名为
gemini-bot.py的文件,并在里面加上以下代码。
import streamlit as st
import os
import google.generativeai as genai
st.title("Gemini Bot")
os.environ['GOOGLE_API_KEY'] = "AIzaSyAjsDpD-XXXXXXXXXXXXX"
genai.configure(api_key=os.environ['GOOGLE_API_KEY'])
# 选择模型
model = genai.GenerativeModel('gemini-pro')
# 初始化聊天历史
if "messages" not in st.session_state:
st.session_state.messages = [
{
"role": "assistant",
"content": "问我吧"
}
]
# 在应用重启时显示历史聊天消息
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.markdown(message["content"])
# 处理和存储查询及响应
def llm_function(query):
response = model.generate_content(query)
# 显示助理消息
with st.chat_message("assistant"):
st.markdown(response.text)
# 存储用户消息
st.session_state.messages.append(
{
"role": "user",
"content": query
}
)
# 存储助理消息
st.session_state.messages.append(
{
"role": "assistant",
"content": response.text
}
)
# 接受用户输入
query = st.chat_input("有什么问题吗?,")
# 当提供输入时调用函数
if query:
# 显示用户消息
with st.chat_message("user"):
st.markdown(query)
llm_function(query)- 运行下面的命令来启动这个应用。
在命令行或终端中输入以下命令来运行程序:streamlit run gemini-bot.py
- 点击屏幕上显示的链接来访问应用程序。
谢谢你读这篇文章。
感谢 Gowri M Bhatt, 审阅了内容。
感谢你,Lija Alex,提供了关于Python版本和库的宝贵建议。谢谢
如果你喜欢这篇文章的话,请点击👏然后让更多人看到它!
本教程的完整源代码可以在这里找到哦。
GitHub - codemaker2015/gemini-api-experiments: 探索Gemini内置的视觉和多模态功能如何帮助其理解和生成文本。更多详情请访问github.com您也可以在开发人员社区Dev上阅读本文。本文利用Google Gemini API自建ChatGPT。
一些有用的网络链接:
点击编辑描述 [快速入门:使用 REST API 开始尝试 Gemini | Google AI 开发者如果你想快速试用 Gemini API,可以用 curl 命令调用 REST API 方法。…ai.google.dev](https://ai.google.dev/tutorials/rest_quickstart?source=post_page-----1b079f6a8415--------------------------------)





