
更新 10/2024:自本文撰写以来,情况发生了很大变化。Snowflake_在 2024_05 版本之后停止生成 version-hint.txt 文件,因此下面部分内容不再适用。Snowflake 还发布了_您可以查看 Polaris,如果您想从不同引擎访问 Snowflake 数据,可以考虑使用它。
Snowflake 最近发布了对开源表格式 Iceberg 的广泛支持。使用这些开源格式可以增强数据的灵活性并减少锁定。本文探讨了如何利用这种灵活性,通过使用 DuckDB 查询 Snowflake 管理的数据来降低 Snowflake 的高昂计算成本。

Apache Iceberg(https://iceberg.apache.org/)是由Netflix在2017年创建的表格格式规范。2018年,Netflix 开源了Iceberg项目,并将其捐献给了Apache软件基金会。
Netflix 设计了 Iceberg 来克服包含简单分区数据文件和少量元数据的数据湖的限制——也称为 Hive 格式的表。这些问题包括多个文件列表、大量分区以及有限的分区裁剪,以及数据仓库中常见的功能缺失,比如时间旅行、模式演变和 ACID 事务。
表格格式要求表格式元数据规范是一种书写元数据以定义表格的标准方式。元数据让工具可以在不读取所有数据的情况下了解数据集的内容,同时也可以给数据赋予不同的含义——例如,将其标记为非当前状态。
Apache Iceberg 并不是一种存储格式。你可以将 Iceberg 表的数据存储为 Parquet、ORC 或 Avro 等格式;Iceberg 是一种组织这些数据文件相关元数据的标准方式。
开启工具箱和互操作性的大门许多引擎和工具都支持 Iceberg 规范。支持相同规范的工具都可以与同一个 Iceberg 表格交互,这就是 Apache Iceberg 被称为“多引擎”的原因。诸如 AWS Athena(https://aws.amazon.com/athena/)、Trino(https://trino.io/)(Starburst,https://www.starburst.io/)、DuckDB 和 Snowflake 等大多数主流引擎都支持 Iceberg 表格。
这种互操作性方法与过去的常规做法大不相同。诸如 Oracle、Vertica、BigQuery 等数据库将元数据和数据存储在专有的格式中,这给无缝互操作性带来挑战,需要大量的数据复制,并可能导致供应商锁定问题。
范式转变通过一个与计算引擎无关的中心化格式进行工作,计算引擎因此变得可以互换。这使我们能够为特定任务选择最适合的计算引擎,而无需移动这些数据。由一个工具写入的数据可以立即被另一个工具读取。
这种架构带来了范式转移,更倾向于数据共享而非在各个计算引擎之间重复数据。
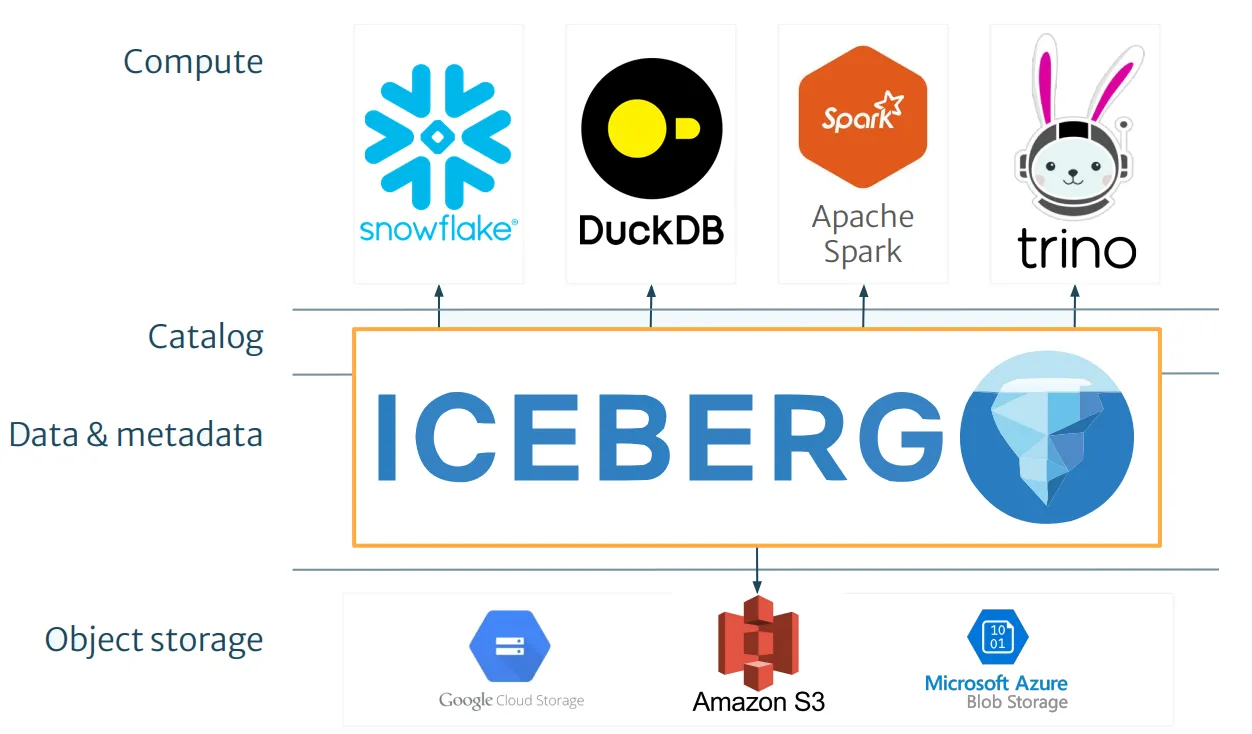
图片改编自https://www.youtube.com/watch?v=_GW3GYZK66U
有特色的湖畔小屋除了促进互操作性之外,Apache Iceberg 还提供越来越多的 特性,以填补数据湖和数据仓库之间的功能空白,从而产生了所谓的 lakehouse。其中包括 时间旅行,ACID 事务,分区演化,隐藏分区,模式演化,节省存储成本 等。这篇文章只探讨互操作性。
Apache 冰山 (Bīngshān) 和 Snowflake (雪片 Xiěpiàn)2023年12月4日,Snowflake发布了一篇博客文章,宣布他们的Apache Iceberg集成正在公开预览中。
Snowflake 现在 ,用户可以 采用两种方式操作 Iceberg 表格:
- 外部目录。这些表是由诸如Apache Spark、Apache Flink或Trino等工具写入到对象存储中,并在诸如Hive元数据存储、AWS Glue 数据目录或Nessie等外部目录中注册。在这种模式下,这些表仅供Snowflake读取**。
- Snowflake的数据目录。在Snowflake的数据目录中,这些表在Snowflake中是可读写的,而在外部则仅供读取。
在这两种情况下,Snowflake会将所有数据和Iceberg元数据存储在您的(云)对象存储中。这两种使用Iceberg的方法都有各自的好处。根据您的情况,您应该能清楚地判断哪种更适合。
所有数据和 Iceberg 的元数据都在您自己的(云)对象存储里,哦,对了,
当您使用Iceberg表时,Snowflake目录会与之配合;它保持“零运维”的状态,您可以在Snowflake进行存储维护(如压缩、过期快照和清理孤儿文件)时,继续轻松无忧。Iceberg表的行为几乎与Snowflake原生表一致,不过,有一些限制您需要注意,详情请参阅此处。
这篇文章假设你的数据在Snowflake中非常活跃,并且你在Snowflake上进行大规模处理。因此,使用Snowflake目录是正确的做法。
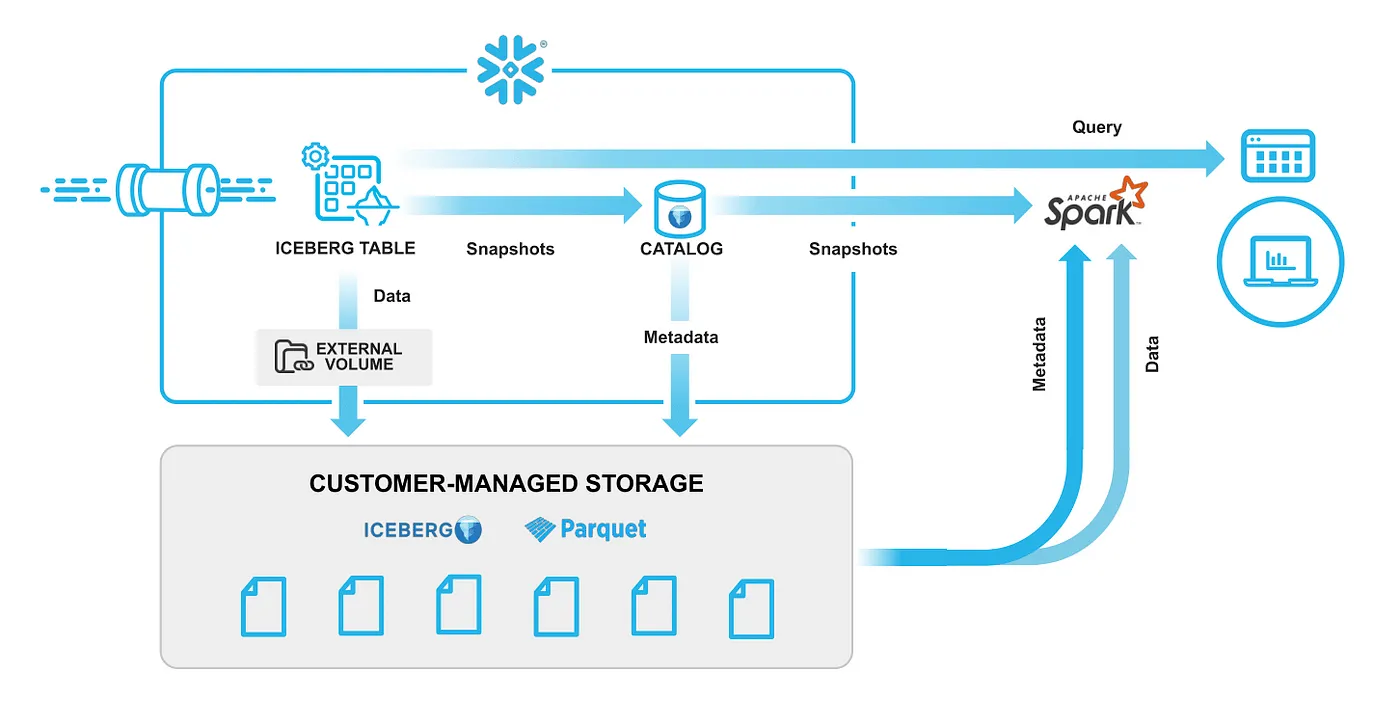
图片来源于 https://www.snowflake.com/blog/unifying-iceberg-tables/ (网站)
冰山目录表在使用Iceberg表和Snowflake目录时,“目录”仍然在Snowflake这边。为了确定这是否妨碍我们直接与数据交互,我们应该了解元数据目录的作用;毕竟,表的元数据不是存放在Iceberg的元数据文件中吗?目录至少提供了两个方面的好处(双关,原文为英文中的“bring to the table”,意为提供或带来好处):
- 数据库抽象。Iceberg 是一种在表级别上定义了的技术元数据规范,Iceberg 元数据文件会与您的数据文件一起存储。表规范并不关心表名、模式、数据库或集合等概念。元数据目录允许您将“一堆表格”视为数据库,通过引入层次结构和存储表名映射到前缀来实现。
- 指向当前表版本的指针。当修改 Iceberg 表时,新的数据和元数据文件会被添加并存储在旧文件旁边。目录不仅跟踪表前缀,还需要知道哪些元数据文件是“当前”的。
TL;DR:你需要访问目录来了解当前的表版本,并通过表名访问表,像平常那样编写查询。

伯格斯在元数据目录中需要细心归档。
Iceberg目录SDK插件如果你想要用Spark读取Iceberg表,那你可就走运了!Snowflake 发布了适用于Spark的Iceberg目录SDK,该SDK实现了Spark的目录接口功能,并使用了一个(未被官方文档记录的)Snowflake目录API。目前,这项Snowflake功能是免费提供的,不需要运行Snowflake仓库,也不会消耗“无服务器积分”或产生“云服务”费用。
Snowflake的公告提供了可以直接使用的示例代码,如下:确认Spark可以直接从客户管理的存储账户中读取Iceberg表的元数据和Parquet文件。
一旦通过 Iceberg 目录 SDK 初始连接到 Snowflake 后,Spark 可以直接读取存储账户中的 Iceberg metadata 和 Parquet 文件。这样配置下,多个引擎可以一致地读取同一个数据副本。
不幸的是,这对从DuckDB进行查询并没有直接的帮助。DuckDB没有可用的Snowflake目录SDK,但我们可以直接读取数据。幸运的是,我们可以直接使用文件系统来读取数据。

图片稍作修改,源自https://www.snowflake.com/blog/unifying-iceberg-tables/
冰山文件系统目录表如果觉得可以通过简单的命名规则在文件系统或对象存储上实现目录,那是因为的确可以实现!确实,Iceberg's Hadoop catalog 就是这样的。其相关文档如下所述:
HadoopCatalog […] 使用指定文件系统中的特定目录作为仓库目录,并组织多个层级的目录,分别对应数据库、命名空间和表。HadoopCatalog 使用一个位置作为仓库目录。当创建如 $db.$tbl 这样的表时,在仓库目录下创建 $db/$tbl 目录,并将表的元数据存储在该目录中。
为了确定哪个元数据是最新的,冰山期望文件系统表的元数据文件名由递增的版本号决定。它还会查找一个可选的 version-hint.text 文件,以指向最新版本。
注意:作者通过遵循此处记录的方案(此处)来保持一致性和版本递增。不幸的是,这要求存储系统支持原子性的重命名,而许多存储引擎,尤其是S3、Google Cloud Storage 和 Azure Blob Storage,并不支持这一功能。这也是为什么其中一位原始作者Ryan Blue曾将其描述为“他最大的错误之一”的原因之一。即使在支持原子性重命名的存储系统上,你可能会发现性能不如使用“适当的”元数据目录时好。因此,一般不建议在生产环境中使用HadoopCatalog。
雪flake 可能使用其后端高性能的专用目录实现。不过,它足够友好地以兼容 Hadoop 目录的方式在客户管理的对象存储上实现数据和元数据——他们甚至维护了一个当前版本的 version-hint.text 文件!这种兼容性意味着任何支持 Iceberg Hadoop 目录的读取器都可以直接通过指向对象存储系统上的 Iceberg 仓库根目录来读取雪flake 的数据。
DuckDB 对 Iceberg Hadoop 目录和文件系统表提供了部分支持。虽然目前 DuckDB 还不支持读取整个仓库,不过你可以指定一个表前缀。DuckDB 会找到 version-hint.text 文件并读取表的最新版本。
让 Snowflake 在您的云上创建一个 Iceberg 表需要一些配置。下面的例子使用 S3 作为存储层,但 Snowflake 也支持 Google Cloud Storage 和 Azure Storage。您可以在这里找到 S3 的指南:
GitHub - datamindedbe/platform-quack-quack-ka-ching: 鸭子带着积分逃走了。一起帮忙开发 datamindedbe/platform-quack-quack-ka-ching。github.com总的来说,我们需要做到的是:
- 配置存储:创建一个 S3 存储桶和一个用于 Snowflake 的 IAM 角色,并确保该 IAM 角色有权限访问该存储桶。
- 将 Snowflake 连接到存储:在 Snowflake 中创建一个外部存储卷 External Volume。在 S3 的情况下,外部存储卷会创建一个 IAM 用户在 Snowflake 的账户上。你需要建立一个信任关系,使 IAM 用户可以访问你的 S3 存储桶。
现在终于可以在 Snowflake 中使用 [CREATE ICEBERG TABLE](https://docs.snowflake.com/en/sql-reference/sql/create-iceberg-table#examples) 创建原生的 iceberg 表,并且可以在 S3 存储桶中找到你的 Parquet 和 Iceberg 元数据文件。
在建立了 S3 和 Snowflake 之间的安全连接并创建了 Iceberg 表格后,我们终于可以来看看 DuckDB 如何方便地查询这些表格了。
我们使用DuckDB的iceberg扩展直接从S3读取我们在Snowflake中创建的Iceberg表。您可以在此链接找到操作指南。主要功能由以下iceberg_scan方法提供。
select * from iceberg_scan('s3://chapter-platform-iceberg/icebergs/line_item');The iceberg_scan 方法从 S3 获取表数据。你无需显式指定当前的 manifest.json 文件,因为 version-hint.text 文件指定了表的当前版本。
我们现在真正释放了开放表格式技术的强大功能:我们享受到了Snowflake的便利及其目录功能,同时通过在DuckDB上执行单节点查询来节省成本。
瑞典快乐雪flake公司为什么这样做?目前,DuckDB 只能读取 Iceberg 表,没有写入功能。不过,你可以将数据导出为 parquet 格式,例如,将文件导出到 S3 的某个位置,使用命令
COPY <表名> TO 's3://bucket/file.parquet'。然而,即使 DuckDB 支持写入 Iceberg 表,Snowflake 仍然不支持这一点——但是你可以将 DuckDB 的输出注册为 Snowflake 中外部目录里的 Iceberg 表。
如果在 Snowflake 上使用 Iceberg 表有点像是既可以吃蛋糕又不用放弃蛋糕,那么为什么 Snowflake 要构建这种集成呢?在 Databricks 等竞争对手的压力下,这样做显得非常合理。两家巨头都在试图开放自己的系统,以吸引更多的客户。

雪花告诉其(潜在)客户,选择雪花不会将您锁定在单一供应商上,没有绑定风险,您随时都可以根据需要更换计算引擎。Databricks 也采取了类似的做法,还开放了其 Delta Lake 格式,并通过 UniForm 更好地支持 Hudi 和 Iceberg。
雪花仍然希望能够在其系统上保留尽可能多的计算能力。将外部元数据迁移到Iceberg目录有一个明确的迁移路径,但反之则困难得多。通过掌控元数据目录,雪花能够保持其计算引擎的地位,并且是唯一的写入者。如果雪花没有开放其系统,它可能会失去许多担心被锁定在系统中的客户。
结论部分类似于 Iceberg 这样的开放表格式能够实现计算与存储的真正分离。通过使用 Snowflake 的 Iceberg 表,您可以继续享受 Snowflake 强大且免操作的特性,同时也能偶尔摆脱其“封闭环境”。由于 Iceberg 结合 Parquet 具有类似于原生 Snowflake 表的特性,比如高效的压缩、分区裁剪、模式演进等,并且 Snowflake 已支持这些特性,因此您可以使用 Iceberg 表代替原生表而不会显著影响其性能或功能。因此,我们推荐默认使用 Snowflake 的 Iceberg 表。
这篇帖子展示了如何通过直接指向您自己的对象存储中的Snowflake管理的数据,轻松地在DuckDB上执行查询,而不是在昂贵的Snowflake计算资源上执行查询。在那里,您甚至可以将其与不在您Snowflake仓库中的数据结合起来。知道您可以在成本仅为相似功能的Snowflake仓库的10%的实例上运行DuckDB,这种方法可以带来显著的成本节省。当然,我们并不是说DuckDB可以替代Snowflake。我们认为这是数据互操作性强大功能的一个很好例证。
这篇文章是由Jelle De Vleminck, Robbert, Moenes Bensoussia和Jonathan Merlevede共同撰写的。
- 👏 如果你喜欢这篇文章,别忘了点赞
- 🗣️ 在评论区分享你的见解,我们会回复你
- 🗞️ 关注我并订阅 datamindedbe,获取更多关于云、平台、数据和软件工程方面的文章。
- 👀 更多关于 Data Minded 的信息,请访问我们的 网站。

链接: 前往链接






