

EfficientFormer 是一组优化了推理速度的模型系列。该论文通过延迟分析法重新审视了 ViT 及其变体的设计原则,并识别出 ViT 中的低效设计和运算符,从而并提出了一个新颖的维度一致的设计范式,用于视觉变压器,并提出了一种简单而有效的延迟驱动的裁剪法,以进一步优化推理速度。
代码及模型资源可在 GitHub 查看。
视觉Transformer在设备上的延迟分析
延迟分析(或性能分析)。结果是在iPhone 12上使用CoreML得到的。
注意:使用大内核和大步幅的补丁处理过程在移动设备上会成为速度瓶颈。
最初的观察表明,传统的补丁嵌入方法,通常采用非重叠的卷积操作,其大核卷积和大步长对移动设备的速度造成了瓶颈。虽然之前认为这些大核卷积的计算成本可以忽略,但实际上大多数编译器并不高效支持这些大核卷积。建议用几个高效的3x3卷积来替换它们,以实现更快的下采样操作。
观察2:选择token混合器时,一致的特征维度很重要。MHSA不一定是一个速度瓶颈问题。
在基于ViT的模型中,选择令牌混合器对性能有着至关重要的影响。比较不同的混合器,例如MHSA(多头自注意力)和池化,可以发现虽然MHSA本身并不一定是瓶颈,但在像LeViT-256这样的模型中,其实施由于频繁的重塑操作导致了延迟。相比之下,池化更适合某些网络实现,从而加快了推理。特征维度的一致在令牌混合器的效率中起着关键作用。
观察3:CONV-BN在延迟方面优于线性归一化(LN-GN),尽管有精度损失,但这种损失通常是可接受的。
MLP(多层感知器)的实现类型,特别是在CONV-BN(带批归一化的卷积)和LN(层归一化)与线性映射之间,会影响延迟时间。CONV-BN更有利于减少延迟,因为BN可以与前面的卷积融合以提高速度。LN和其他动态归一化方法在推理过程中收集运行时统计,从而增加了延迟时间。这里的选择是在延迟时间和准确性之间做出权衡取舍,CONV-BN虽然会在一定程度上降低性能,但能带来显著的延迟减少。
观察4:非线性的时延受硬件和编译器的影响。
之前被认为效率低下的GeLU(即GeLU),在某些硬件上(例如iPhone 12)表现却很好。相比之下,HardSwish在实验中意外地变慢,可能是因为编译器支持不足。结论是,选择激活函数时应考虑具体的硬件和编译器支持情况。
EfficientFormer设计 一致的维度设计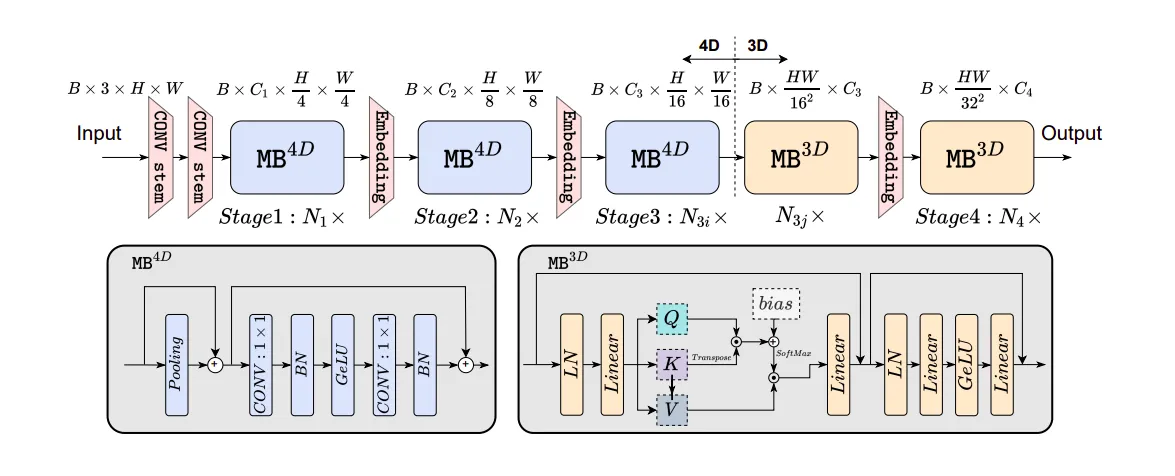
EfficientFormer 简介。
网络由补丁嵌入(Patch Embed)模块和一系列元变压器块(MB)组成:
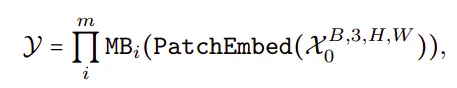
其中 X0 是批大小为 B、空间尺寸为 [H, W] 的输入图像,Y 是期望的输出 Y,总块数 m(深度)。MB 包含一个未指定的 Token 混合器(TokenMixer)和一个 MLP 块,可以表示如下:

一个阶段(或 S)是由几个处理相同空间大小特征的元块堆叠而成的模块。网络共有 4 个这样的阶段。在每个阶段之间,有一个嵌入操作来映射嵌入维度并下采样标记长度。
网络被划分为一个4D分区,在这个分区中,操作以类似卷积网络(CONV-net)的方式实现。而在另一个3D分区中,线性投影和注意力机制则是在3D张量上进行,以便在后续阶段利用多头自注意力(MHSA)的强大全局建模能力,同时保持高效。
首先,输入图像通过一个卷积stem进行处理,该stem包含两个3×3卷积(步长为2),作为图像嵌入。

其中 Cj 是第 j 个阶段的通道数量(宽度)。然后网络从带有简单池化混合器的 MB4D 开始,以提取低层次特征,
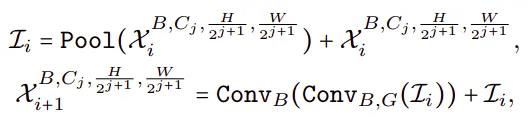
其中 ConvB,G 表示卷积操作后是否分别接上 BN 和 GeLU。在 Pool 混合器之前没有 Group 或 Layer Normalization (LN),因为 4D 分区基于 CONV-BN 设计,因此每个 Pool 混合器前面都有一个 BN。
在处理完所有MB4D块之后,进行一次重塑,以调整特征尺寸并进入3D分区。MB3D也遵循标准的ViT结构。从形式上讲,

其中,LinearG 表示先进行 Linear,再进行 GeLU。
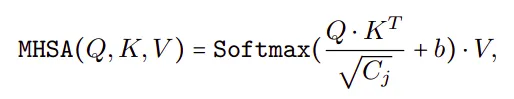
其中 Q, K, V 分别代表通过线性投影得到的查询、键和值,b 则是参数化的注意力偏差,通常用于位置编码(position embedding)。
延迟瘦身计划超网络是基于MetaPath(MP)概念设计的,MetaPath表示网络每个阶段中可能存在的不同模块。MetaPath决定了每个阶段网络架构中可用的模块选择。
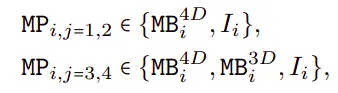
其中 I 表示身份路径 I,j 表示第 j 阶段,i 表示第 i 块。
搜索空间参数设定:
- Cj: 每个阶段的宽度(Cj)。
- Nj: 每个阶段的块数(深度Nj)。
- N: 需要应用MB3D的块数(N)。
搜索方法
梯度搜索算法用于提高效率,无需将每个候选方案部署到硬件中。
该算法包括三个步骤:
- 通过 Gumbel Softmax 采样来训练超网络,以获取每个 MetaPath 中各块的重要性得分。

- 通过收集不同块配置(如MB4D和MB3D,以及各种宽度)的设备延迟来构建一个延迟查找表。
- 基于使用查找表进行延迟评估的网络裁剪过程。这涉及通过迭代评估并逐步减少块和阶段的宽度和重要性,以适应目标延迟并达到目标延迟。
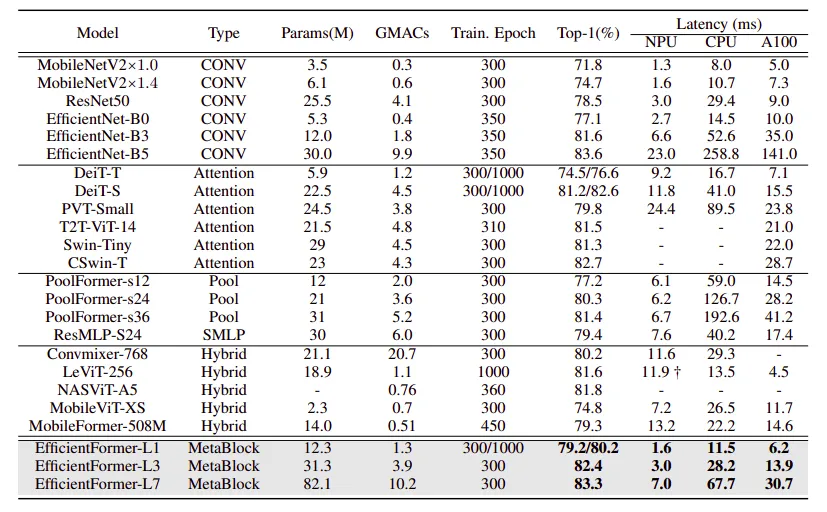
在ImageNet-1K上的比较结果。
- 在ImageNet-1K数据集上从头开始训练的EfficientFormer模型。
- 训练和测试时使用的标准图像尺寸为224 × 224。
- 训练方案遵循DeiT,训练周期为300个。
- 用于知识蒸馏的教师模型为RegNetY-16GF,其最高准确率为82.9%。
来看看性能表现对比:
- 相比CNN,EfficientFormer在精度与延迟之间的权衡上做得更好,适用于各类设备。
- EfficientFormer模型在性能上超越了EfficientNet和MobileNet模型,在不同层和推理速度下表现更佳。
- 在iPhone神经引擎和台式机GPU(A100)上,相比现有模型,在性能上表现更佳。
与ViTs相比:
- EfficientFormer 的表现与 transformer 模型相当,但在推理速度上要快得多。
- EfficientFormer 在准确性和速度上都优于最近的 transformer 变体,如 PoolFormer。
混合模型设计与纯Transformer模型对比:
- 混合设计在延迟方面存在困难,但未能在速度和精度上超越轻量级CNN。
- EfficientFormer是一种纯Transformer模型,在同时实现了超快的推理速度的同时保持了高性能。
- 在各种硬件配置中,EfficientFormer超越了MobileViT模型,具有显著的精度优势。

使用EfficientFormer的比较结果
目标检测和实例分割:
- 使用ImageNet-1K预训练权重初始化的Mask-RCNN和EfficientFormer作为骨干网络,在COCO2017数据集上进行训练和验证,该数据集包含118K张训练图像和5K张验证图像。
- 输入尺寸设置为1333 × 800 像素。
- EfficientFormer在性能上一直优于CNN(如ResNet)和Transformer(如PoolFormer)骨干网络。
- EfficientFormer-L3在box AP上比ResNet50骨干网络高出3.4,在mask AP上高出3.7。
- 在box AP上超过PoolFormer-S24 1.3,在mask AP上超过PoolFormer-S24 1.1,强调了EfficientFormer作为视觉任务中骨干网络的鲁棒性。
语义分割:
- 使用预训练的 ImageNet-1K 权重的 EfficientFormer 和采用语义 FPN 作为分割解码器在 ADE20K 数据集上进行语义分割,该数据集包含 20K 张训练图像和 2K 张验证图像,覆盖 150 个类别。
- 训练时,将输入图像调整并裁剪为 512 × 512,而在测试/验证时,将较短边调整为 512。
- EfficientFormer 与以 CNN 和 transformer 为基础的主干网络相比,在相似的计算预算下表现出了显著的优势。
- EfficientFormer-L3 在 mIoU 指标上超越 PoolFormer-S24 3.2 个百分点,展示了其有效学习长期依赖的能力,这得益于全局注意力机制,这对高分辨率密集预测任务非常有利。
EfficientFormer:达到 MobileNet 的速度的视觉变换器 2206.01191
推荐阅读: [Vision Transformers]
想了解更多吗?
别错过探索该系列中的其他精彩主题。只需点击这里即可,即可发现最新的研究成果!
别忘了订阅,每周获取更新!!





