
在 IT 行业里,搜寻信息大概占了工作的八成。
人们就花那么多时间搜索啊
- 文档
- 语法结构
- 信息
- 错误解决
- 教程
等等之类的
大多数网站和应用程序都内置了非常强大的搜索引擎功能,让用户在各种类型的信息和数据中进行复杂的甚至是模糊的搜索。
传统上,搜索的实现是使用诸如 Elastic Search 和 Apache Solr 这样的工具来完成的。
世界很愉快。他们创建的搜索引擎相当擅长猜测用户真正想搜索的内容。
但随着时间的推移——事情得变一变了。它们确实在变。
使用 Elastic Search 或 Lucene 的传统方法已经过时了。
Elasticsearch 怎么了?
向量数据库和大型语言模型兴起
在这篇文章中,我将解释如何利用过去一年里最新的人工智能语言模型来构建一个复杂且高效的搜索生态系统。
矢量数据库向量数据库是一种以高维向量形式存储数据的数据库,这些向量是特征或属性的数学表达。这些向量通常是通过将原始数据(如文本、图像、音频、视频等)转换为某种向量生成的。嵌入函数可以基于多种方法,例如基于机器学习的模型、词嵌入、特征提取算法。
向量数据库的主要好处是它能够根据数据的向量距离或相似度快速准确地进行相似搜索和数据检索。这意味着你可以利用向量数据库找到最接近或最相关的数据,它们基于语义或上下文的意义,而不需要传统的精确匹配或预设条件查询数据库的方法。
上述向量数据库描述中的游戏规则改变者是什么?
你可以用矢量数据库来找到最相关的或相似的数据,这些数据是基于它们的语义或上下文。
即使你没看关于向量数据库的介绍,最后一句话可不能错过,因为上下文可是相当重要的,重要性不容忽视。
大型语言模型大型语言模型(LLMs)是在海量数据上被训练的,从而能够理解和生成自然语言以及其他类型的内容,从而完成各种任务。
大型语言模型是用来生成信息的
- 你熟悉的语言
- 你熟悉的领域或话题
- 包含上下文的信息
我们现在明白了,如果我给ChatGPT一个指令和背景,它非常擅长理解我在上下文中真正想寻找的是什么。
又一次地,我们又碰到了这个词
上下文很关键背景
搜索信息时,上下文很重要。如果我想在你的电商网站上搜索裤子,我不必特意指定这些细节。
🔘颜色:
🔘选择类型
🔘设置
而且其他科学的胡扯,用来从我这里榨取所有信息,让我毫无想象空间。
现在不需要再填写冗长的表格,输入搜索词和筛选条件等,而是可以直接说就行了。
“找一些黑色的标准尺码的裤子(pánsī),我可以穿去上班穿的”
这不更简单吗?它提供了足够的上下文供使用向量数据库和大模型的框架来帮你找信息。
如果我不喜欢搜索引擎推荐的东西,我就能直接说
那不行,找其他裤子,不管是什么公司的裤子
如今,这种高级的搜索已经触手可及。我知道,因为设计这种类型的搜索引擎已经成为我最近的主要工作。
下面藏着什么呢?
文档搜索
让我一步步带你实现基于RAG的搜索功能,以便在文档中搜索信息。
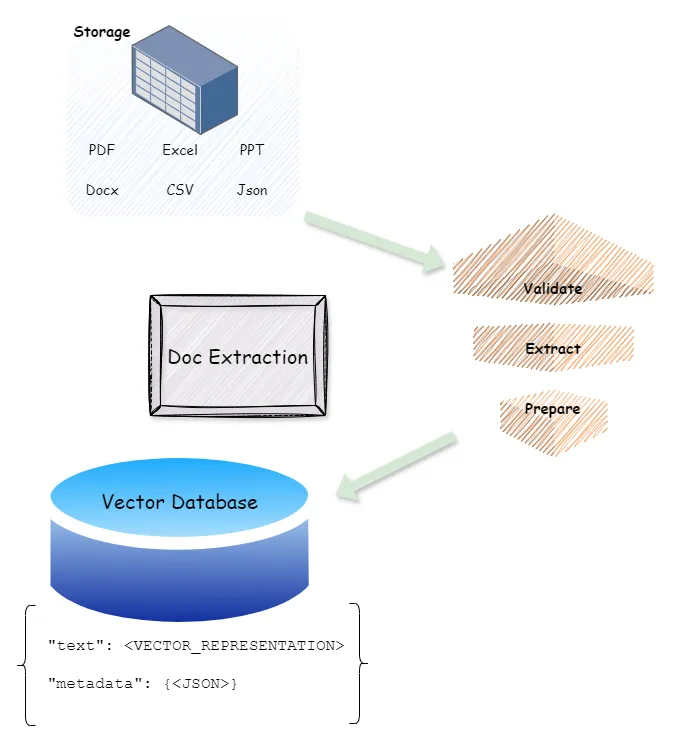
这里有处理几乎所有类型文档或文件的库,比如 Docx、PPT、PDF、CSV、Excel 等等,这些类型的文档都可以用这些库来处理。
如果我能处理一个文档并从中提取文本,我同样可以搜索它。
那你就会问,那文档里的图像怎么办?
那用像Tesseract这样的OCR工具包也很简单。但你不需要这样做,让我解释。
1. 假设部分.- 假设你所有的文档都存储在云存储上。
- 假设你已经有了一个向量数据库。
你需要写一个服务来处理并提取下面的信息
▶️文本: 标题、副标题、段落等,任何提供搜索上下文的内容
▶️元数据: 哪张页?哪张表?哪张幻灯片?等等之类的。
▶️图片: 这些图片可以用来通过OCR读取文字。
▶️图片信息: 哪张图?哪一页?哪张幻灯片?等等类似。
▶️文档网址: 存储网址/网站网址/文档存储网址
你可以通过创建自己的服务实例并将其部署到 K8s 集群上来完成数据提取。
或者编写一个脚本来提取文本。
3.储存:无论你选择哪种中间件,你都需要将我们提取的信息及元数据写入向量数据库中。
这样一来,根据用户提供的上下文,我们在向量库中查找存储的文本。
并且,向量数据库会根据文本内容来查找与元数据相关的信息,尤其是文档的网址。
它看起来就是这样子
检索步骤可以如下所示,
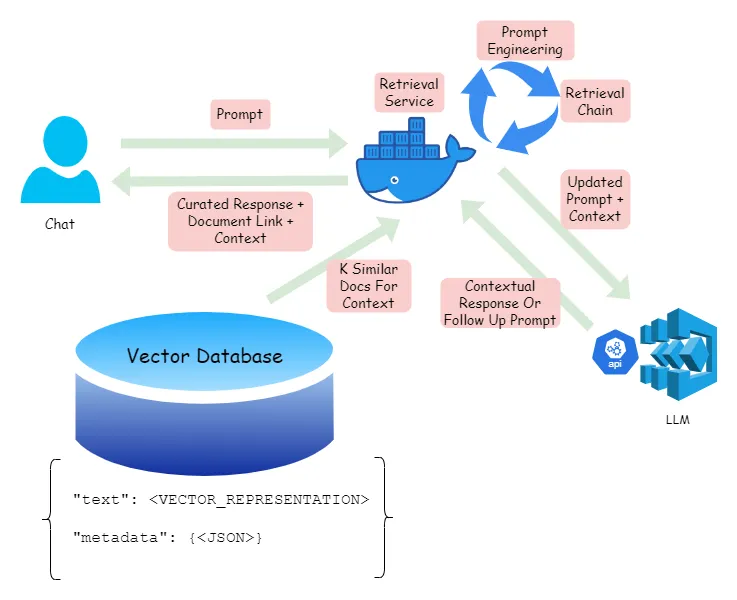
用户将请求交给检索服务,这是一个负责处理请求的应用程序。
从包含上下文文本(Context)和文档链接的向量数据库中的文档元数据获取K个相似条目。
使用提示工程确保从向量数据库检索到的上下文以适当的方式呈现给大语言模型(LLM),从而使生成的回答既相关又易读,与对方相符。
其他非功能需求,例如诸如日志记录、重试策略等。
检索服务当然需要是可扩展的,能够处理大量请求。同样,部署LLM的服务也需要具备可扩展性,但对于使用这些托管服务,比如Azure Open AI和AWS Bedrock等的情况,其扩展则由云平台来管理。
检索服务会向用户提供这些信息
下面的LLM回应——这来自于从最相关文档中检索到的信息摘要。
🟢文档的元数据,如其位置、创建日期、负责它的团队等。
🔵真实的文档链接和从中提取信息的具体位置。这可以让用户直接跳转到实际文档中的具体位置。
那我们来总结一下实现过程——
向量数据库与大语言模型结合可以为用户提供相关的资料,还包括来源和背景信息。那么,为什么这很重要呢?
因为它允许系统从用户那里获取反馈。
随着你不断使用系统,时间久了,你的系统就能返回最新的并且最相关的搜索结果。这真是太棒了!
接下来,我们来谈谈数据库搜索。以前我们常使用Elastic Search或Apache Solr来让搜索更加智能。现在这些都不需要了。让我们来看看具体是怎么回事以及背后的原因。
如何进行数据库查询从一开始就让我说得非常清楚——期待大型语言模型能够发出复杂的SQL查询到数据库是充满了风险的。尤其是当你认为它们会执行CRUD操作时。
别做这事儿
相反,我的建议是在数据库之上添加一个ORM或GraphQL层以形成访问接口。在调用具有明确模式和边界实体的API时,大语言模型表现更好,并且上下文已预先定义好。此外,还有一个保护层,LLM需要通过这一层来访问数据。
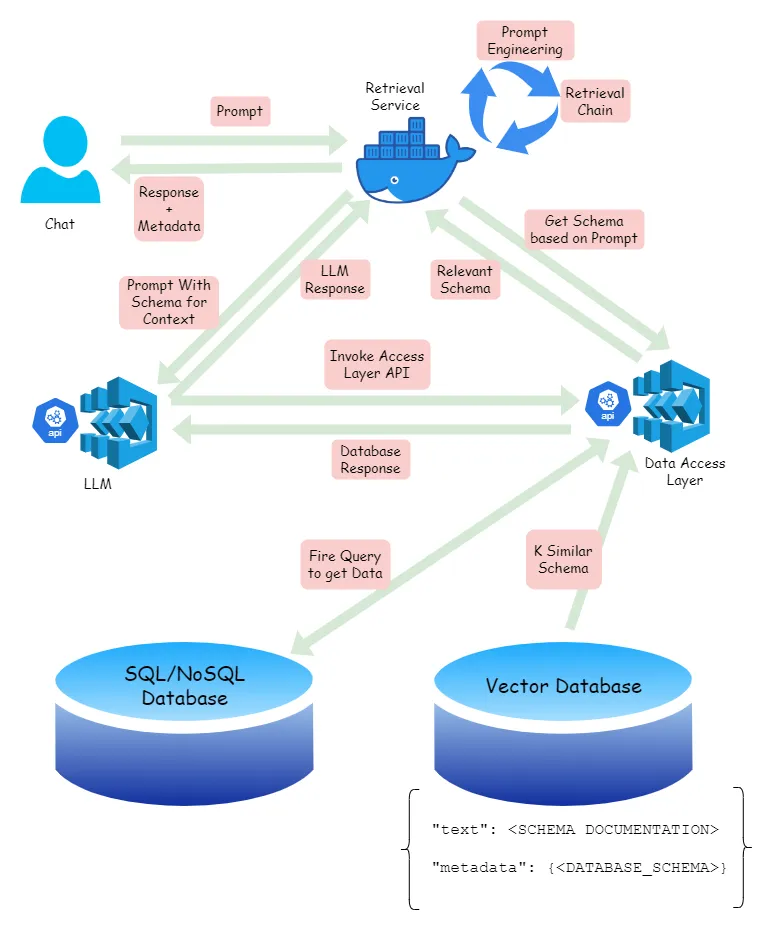
如果你有一个数据访问层,从数据库角度看信息检索就像这样
看起来很混乱?信息量太大了?让我给你讲讲。
1. 查找假设数据检索层已经准备好了,我们将使用相同的服务来查询向量数据库中的数据。步骤如下。
用户提交了一个指令或请求,需要转换成数据库查询。比如,选择所有黑色、腰围为34的裤子,价格介于3000到10000元之间。
检索服务将此提示提交给数据访问层,以从向量数据库中找到相关的模式。
DataTask层从向量数据库提取相关的模式,并返回最相关的那一个模式。
2. 发出查询现在检索过程已经完成,我们将架构提交给大型语言模型(LLM),以便它能够调用相应的API。
注意:要调用的 API,以及 Schema 的使用方式,将成为提示设计的一部分。
LLM 调用带有指定模式的 API,进而向数据库发送实际查询。
数据库的响应结果与由LLM生成的摘要回复、发起的查询请求(用于上下文)以及其他相关信息,例如表名和列名,一起返回给检索服务。这些元数据也会包含在向量数据库中。
回复服务会把这个信息发送给用户,征求他们的反馈。
就这样了。用户可以选择接受这个回复,或者修改提示发起另一个查询。
工具设备你可以使用RAG架构。
🟧朗链
🟨 LlamaIndex
渐变J,这个用户名看起来很酷。
调用大规模语言模型
🟦奥拉玛(Ollama)
🟪GPT4ALL
🟫Dify(智能助手)
另外,如果你想通过API使用这些管理的LLM模型,则。
🟠Open AI
🟡Azure OpenAI(黄色的)
🟢AWS 基石
🔵Cohere (kē huì ěr) (🔵 表示蓝色)
米斯托拉风
当然,你也可以在本地部署自己的大模型,并通过Pipelines工具和检索QA链实现RAG架构。
面临的挑战使用这种搜索方式会遇到一些明显的挑战。
❗️这个方案挺贵的,至少与使用Elastic Search等传统方案相比。
要想从大型语言模型中获得最大收益,你得懂点提示工程技术。
❗️这个解决方案会随着时间变得越来越好。你可能需要试几次才能让它上线。
❗️回复可能并不总是可靠,因为大模型有可能会出现幻觉。但如果你善于确保大模型获得正确的上下文,就可以通过RAG来避免这种情况。因此,RAG可以有效避免这些问题。
❗️延迟会成为一个问题,因为大模型生成回复时需要更多时间。因此,响应时间会比传统设置更长。
但这些挑战还不至于严重到彻底忽略设计这种方案的好处。
科技世界的发展速度比去年快得多。曾经的成熟系统设计现在已不再吸引人,而创新思维变得越来越重要。
由于自动化,大量工作将因AI而消失或改变,但这并不表示AI会取代所有事物。毕竟,有些工作需要人类的创造力和决策能力。
AI应该被当作一个辅助工具来使用,而不是取代人的思维和行为。
构建这种搜索架构虽然充满挑战,但也为自动化数据质量管理提供了空间。这种系统可以自主变得更聪明,而不需要通过人为干预或修复 bug。
跟我来 Ritesh Shergill 更多文章请查看👨💻 科技圈
🎓 求职建议 👩🎓
📲 用户体验
🏆 领导力奖
我也做
✅ 职业规划咨询 — https://topmate.io/ritesh_shergill/149890
✅ 作为初创公司的兼职CTO提供帮助 — https://topmate.io/ritesh_shergill/193786





