
上一篇文章Python爬虫实战-使用Scrapy框架爬取土巴兔(三)我们为爬虫工程添加了下载中间件和IP代理池。接下来就要开始着手具体的爬取规则。
该篇文章主要讲如何分析网页并通过Scrapy中Spider来定制爬取规则。
一.分析网页
当你想要爬取某个网站内容时一定是先了解网站网页的翻页URL规则和阅读网页的html源代码。了解翻页规则我们就能确定需要爬取的网页url。阅读html源代码是为了确定能够爬取的内容并且确定数据结构。
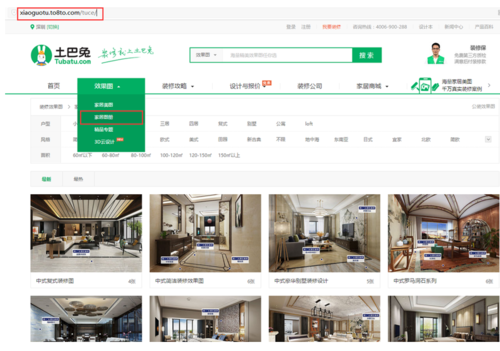
我们要爬取的是土巴兔中家居图册这个模块。那么我们就确定了起始的URL是http://xiaoguotu.to8to.com/tuce/ 。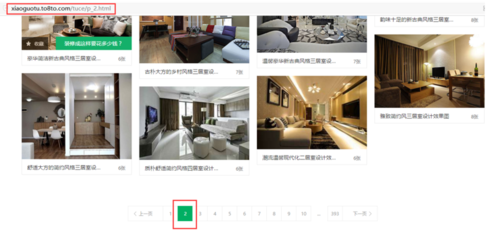 往下拉点击第二页后可以看到,网址变为http://xiaoguotu.to8to.com/tuce/p_2.html 。 那么可以确定翻页规则匹配的正则就是"xiaoguotu.to8to.com/tuce/p_\d+.html"。
往下拉点击第二页后可以看到,网址变为http://xiaoguotu.to8to.com/tuce/p_2.html 。 那么可以确定翻页规则匹配的正则就是"xiaoguotu.to8to.com/tuce/p_\d+.html"。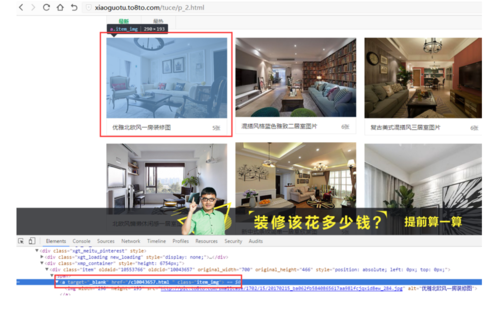 按F12调出开发者工具,通过阅读html代码我们很容易就知道在html中哪个节点位置可以获取进入详情页的url。
按F12调出开发者工具,通过阅读html代码我们很容易就知道在html中哪个节点位置可以获取进入详情页的url。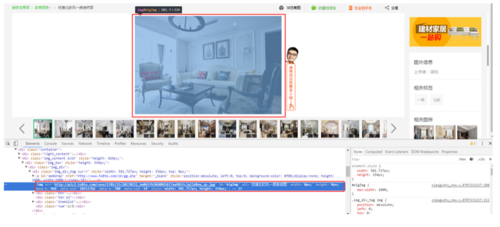 接下来点进某个图册,阅读源码我们很简单就能找出图片的链接。但是一个图册包括了多张图片。html源码中并没有展示所有图片的链接,那我们该怎么办,这是个疑问。
接下来点进某个图册,阅读源码我们很简单就能找出图片的链接。但是一个图册包括了多张图片。html源码中并没有展示所有图片的链接,那我们该怎么办,这是个疑问。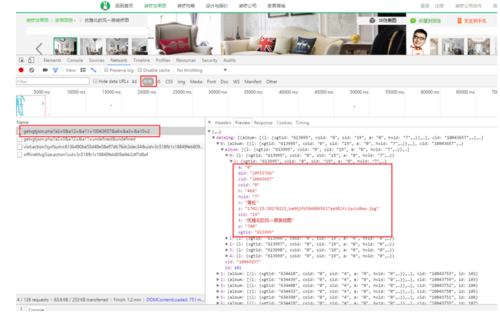 依旧利用开发者工具点击XHR这个选项,接下来一目了然,原来土巴兔是通过AJAX请求的方式来加载数据的。http://xiaoguotu.to8to.com/getxgtjson.php?a2=0&a12=&a11=10043657&a6=&a3=&a10=2 这个url返回了json格式的数据。在json数据中我们可以看到cid为c10043657的图册,id为101,共有5张图片。我们也可以看到图片的url和标题,但是剩下的字段,例如sid:"19"、hxid:"7" ,我们都无法知道它具体代表什么。
依旧利用开发者工具点击XHR这个选项,接下来一目了然,原来土巴兔是通过AJAX请求的方式来加载数据的。http://xiaoguotu.to8to.com/getxgtjson.php?a2=0&a12=&a11=10043657&a6=&a3=&a10=2 这个url返回了json格式的数据。在json数据中我们可以看到cid为c10043657的图册,id为101,共有5张图片。我们也可以看到图片的url和标题,但是剩下的字段,例如sid:"19"、hxid:"7" ,我们都无法知道它具体代表什么。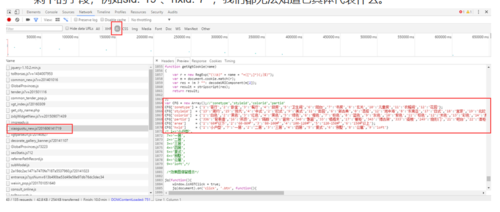 接下来就需要我们的耐心一点一点去寻找蛛丝马迹,终于在xiaoguotu_new.js这个请求中,我们看到了刚才说的sid:"19"、hxid:"7"的含义。
接下来就需要我们的耐心一点一点去寻找蛛丝马迹,终于在xiaoguotu_new.js这个请求中,我们看到了刚才说的sid:"19"、hxid:"7"的含义。
二.数据结构
经过一番周折,我们终于知道了该如何获取到关于图册的所有信息。
确定数据结构,并编写继承scrapy.Item的Item实体和一些常量
import scrapyclass DesignPictureItem(scrapy.Item): fid = scrapy.Field() # 唯一标识 title = scrapy.Field() # 标题 sub_title = scrapy.Field() # 副标题 html_url = scrapy.Field() # 所爬取的网页链接 tags = scrapy.Field() # 标签 description = scrapy.Field() # 描述 img_url = scrapy.Field() # 图片URL img_width = scrapy.Field() # 图片宽度 img_height = scrapy.Field() # 图片高度 img_name = scrapy.Field() # 图片名称
ZONE_TYPE = {'1': '客厅', '2': '卧室', '3': '餐厅', '4': '厨房', '5': '卫生间', '6': '阳台', '7': '书房', '8': '玄关', '10': '儿童房', '11': '衣帽间', '12': '花园'}
STYLE_ID = {'13': '简约', '15': '现代', '4': '中式', '2': '欧式', '9': '美式', '11': '田园', '6': '新古典', '0': '混搭', '12': '地中海', '8': '东南亚', '17': '日式', '18': '宜家', '19': '北欧', '20': '简欧'}
COLOR_ID = {'1': '白色', '2': '黑色', '3': '红色', '4': '黑色', '5': '绿色', '6': '橙色', '7': '粉色', '8': '蓝色', '9': '灰色', '10': '紫色', '11': '棕色', '12': '米色', '13': '彩色', '14': '原木色'}
PART_ID = {'336': '背景墙', '16': '吊顶', '14': '隔断', '9': '窗帘', '340': '飘窗', '33': '榻榻米', '17': '橱柜', '343': '博古架', '333': '阁楼', '249': '隐形门', '21': '吧台', '22': '酒柜', '23': '鞋柜', '24': '衣柜', '19': '窗户', '20': '相片墙', '18': '楼梯', '359': '其他'}
AREA = {'1': '60㎡以下', '2': '60-80㎡', '3': '80-100㎡', '4': '100-120㎡', '5': '120-150㎡', '6': '150㎡以上'}
HX_ID = {'1': '小户型', '7': '一居', '2': '二居', '3': '三居', '4': '四居', '5': '复式', '6': '别墅', '8': '公寓', '9': 'loft'}三.爬取规则
Spider类定义了如何爬取、网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。更详细的Spider说明请阅读官方文档。
Scrapy也在框架中定义不同用途的Spider,如:
CrawlSpider:定义了一些规则(rule)来提供跟进link的方便的机制
XMLFeedSpider:被设计用于通过迭代各个节点来分析XML源
CSVFeedSpider:该spider除了其按行遍历而不是节点之外其他和XMLFeedSpider十分类似
SitemapSpider:使您爬取网站时可以通过 Sitemaps 来发现爬取的URL
这里显然CrawlSpider更适合我们来定义爬虫规则。
下面是爬虫的完整代码:
class DesignPictureSpider(CrawlSpider):
#定义爬虫名称
name = 'design_picture'
#定义起始域名
start_url_domain = 'xiaoguotu.to8to.com'
#定义允许的域名
allowed_domains = ['to8to.com'] #定义起始的URL
start_urls = ['http://xiaoguotu.to8to.com/tuce/'] #定义翻页规则,及回调方法
rules = (
Rule(LinkExtractor(allow="/tuce/p_\d+.html"), follow=True, callback='parse_list'),
) #定义数据处理完后,处理Item的管道
custom_settings = { 'ITEM_PIPELINES': { 'tubatu.pipelines.DesignPicturePipeline': 302,
}
} #Service封装具体的数据处理逻辑
design_picture_service = DesignPictureService()
#获取到网页数据后的回调方法
def parse_list(self, response):
selector = Selector(response) #利用xpath提取元素
items_selector = selector.xpath('//div[@class="xmp_container"]//div[@class="item"]') for item_selector in items_selector: #拼接详情页URL,格式为:http://xiaoguotu.to8to.com/c10037052.html
cid = item_selector.xpath('div//a/@href').extract()[0][2:-6]
title = item_selector.xpath('div//a/@title').extract()[0] #拼接获取数据的URL,格式: http://xiaoguotu.to8to.com/getxgtjson.php?a2=0&a12=&a11=10037052&a1=0
next_url = (constant.PROTOCOL_HTTP + self.start_url_domain + '/getxgtjson.php?a2=0&a12=&a11={cid}&a1=0').format(cid=cid) #创建一个请求,反给Scrapy引擎
yield scrapy.Request(next_url, self.parse_content, meta={'cid': cid, 'title': title})#通过meta来传递数据
#解析详情方法
def parse_content(self, response):
uuid = utils.get_uuid()
cid = response.meta['cid']
title = response.meta['title'] try: #解析json数据
data = json.loads(response.text) except:
print("-----------------------获取到json:" + response.text + "------------------------------") return
data_img_list = data['dataImg']
data_album_list = None
for _data_img in data_img_list: if _data_img['cid'] == cid:
data_album_list = _data_img['album'] break
for data_album in data_album_list:
data_img = data_album['l'] #取得单张图片URL http://pic.to8to.com/case/1605/05/20160505_f0af86a239d0b02e9635a47ih5l1riuq_sp.jpg
img_url = 'http://pic.to8to.com/case/{short_name}'.format(short_name=data_img['s']) #过滤重复URL
if self.design_picture_service.is_duplicate_url(img_url): break
sub_title = data_img['t']
original_width = data_img['w']
original_height = data_img['h']
tags = [] try:
zoom_type = ZONE_TYPE[data_img['zid']] if zoom_type is not None or not zoom_type.strip() == '':
tags.append(zoom_type) except KeyError: pass
try:
style_id = STYLE_ID[data_img['sid']] if style_id is not None or not style_id.strip() == '':
tags.append(style_id) except KeyError: pass
try:
area = AREA[data_img['a']] if area is not None or not area.strip() == '':
tags.append(area) except KeyError: pass
try:
color_id = COLOR_ID[data_img['coid']] if color_id is not None or not color_id.strip() == '':
tags.append(color_id) except KeyError: pass
try:
house_type = HX_ID[data_img['hxid']] if house_type is not None or not house_type.strip() == '':
tags.append(house_type) except KeyError: pass
try:
part = PART_ID[data_img['pid']] if part is not None or not part.strip() == '':
tags.append(part) except KeyError: pass
#创建Item对象并返回
try:
design_picture_item = DesignPictureItem() # type: DesignPictureItem
design_picture_item['fid'] = uuid
design_picture_item['html_url'] = response.url
design_picture_item['img_url'] = img_url
design_picture_item['tags'] = tags
design_picture_item['title'] = title
design_picture_item['sub_title'] = sub_title
design_picture_item['img_width'] = original_width
design_picture_item['img_height'] = original_height
design_picture_item['description'] = design_picture_item['title'] yield design_picture_item except Exception as e:
print("-----------------------获取到json:" + response.text + "------------------------------")
log.warn("%s ( refer: %s )" % (e, response.url)) if config.USE_PROXY:
proxy_pool.add_failed_time(response.meta['proxy'].replace('http://', ''))当然这里还有一个重要的知识点是关于如何使用XPath 。XPath可以用来在XML文档中对元素和属性进行遍历,从而从网页中提取出我们需要的信息。更多XPath的语法知识可以参考http://www.w3school.com.cn/xpath/index.asp。
四.布隆过滤
好奇的同学可能会有疑问,如果我们爬到重复的URL时怎么办呢?
接下来就要引入布隆过滤。我们将爬取过的URL通过布隆算法存入Redis中,每次爬取一个新的URL时再通过布隆算法来识别是否是重复的URL,如果是重复的就不处理这个URL了。
布隆过滤的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
在URL去重上牺牲一定的准确性来降低Redis存储开销和提高爬虫整体效率也是值得的。
from redis import StrictRedisclass SimpleHash(object): def __init__(self, cap, seed): self.cap = cap self.seed = seed def hash(self, value): ret = 0 for i in range(value.__len__()): ret += self.seed * ret + ord(value[i]) return (self.cap - 1) & retclass RedisBloomFilter(object): def __init__(self, redis_client: StrictRedis): self.bit_size = 1 << 25 self.seeds = [5, 7, 11, 13, 31, 37, 61] self.redis = redis_client self.hash_dict = [] for i in range(self.seeds.__len__()): self.hash_dict.append(SimpleHash(self.bit_size, self.seeds[i])) def is_contains(self, value, key): if value is None: return False if value.__len__() == 0: return False ret = True for f in self.hash_dict: loc = f.hash(value) ret = ret & self.redis.getbit(key, loc) return ret def insert(self, value, key): for f in self.hash_dict: loc = f.hash(value) self.redis.setbit(key, loc, 1)
最后
爬取规则也完成了,接下来就是我们的收尾工作, Python爬虫实战-使用Scrapy框架爬取土巴兔(五)通过Item Pipeline处理Item实体。
附:
详细的项目工程在Github中,如果觉得还不错的话记得Star哦。
作者:imflyn
链接:https://www.jianshu.com/p/8c5bc23f4fec





