
Scrapy is an application framework for crawling web sites and extracting structured data which can be used for a wide range of useful applications, like data mining, information processing or historical archival.
上面这段话取自官方文档。翻译过来就是:
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
Scrapy可以说是目前Python爬虫框架中最成熟最稳定的框架之一,所以我们使用Scrapy框架来做爬虫开发可以说是好钢用在刀刃上。
该系列其它文章:
该篇文章主要讲Scrapy架构、工作流程、优点及开发环境的搭建,接下来我们进入正题。
一.初识Scrapy
Scrapy架构图:
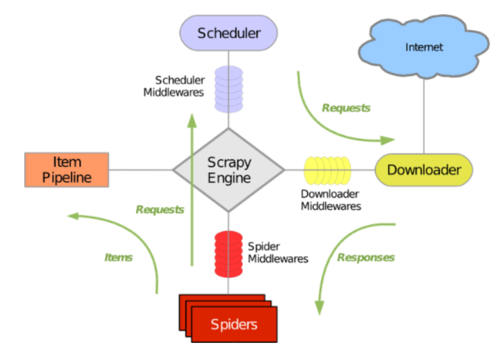
Scrapy架构图
通过清晰的架构图我们可以了解到Scrapy运作的流程。
1.Scrapy的五大模块:
引擎(Scrapy Engine):Scrapy使用Twisted来作为框架的核心,Twisted是一个基于事件驱动的网络引擎框架。所以引擎主要是用来处理整个系统的数据流,触发各个事件。
调度器(Scheduler):调度器接受引擎传来的数据,维护需要爬取的网页URL队列,并通过规定的调度机制将URL创建为下载请求。
管道(Item Pipeline):将爬取到的内容转换为实体对象,并对实体对象做有效性验证、持久化等等自定义的操作。
下载器(Downloader):主要是进行网页的http请求及响应,负责产生数据并返回数据。
爬虫(Spiders):在爬虫中,定义爬取URL的规则和网页信息的提取规则。
2.Scrapy的三个中间件起到串联各个模块的作用:
下载器中间件(Downloader Middlewares):位于Scrapy引擎和下载器之间的中间件,在Scrapy引擎和下载器中间负责传递下载内容的请求和数据。
调度中间件(Scheduler Middewares):位于Scrapy引擎和调度之间的中间件,Scrapy引擎和调度器之间负责传递调度的请求和响应。
爬虫中间件(Spider Middlewares):位于Scrapy引擎和爬虫之间的框架,主要工作是处理爬虫的响应输入和请求输出。
3.Scrapy的工作流程:
引擎打开一个网站,找到处理该网站的Spider并向该spider请求第一个要爬取的URL(s)。
引擎从Spider中获取到第一个要爬取的URL并在调度器(Scheduler)中创建request来进行调度。
引擎向调度器请求下一个要爬取的URL。
调度器返回下一个要爬取的URL给引擎,引擎将URL通过下载中间件(请求(request)方向)转发给下载器(Downloader)。
一旦页面下载完毕,下载器生成一个该页面的Response,并将其通过下载中间件(返回(response)方向)发送给引擎。
引擎从下载器中接收到Response并通过Spider中间件(输入方向)发送给Spider处理。
Spider处理Response并返回爬取到的Item及(跟进的)新的Request给引擎。
引擎将(Spider返回的)爬取到的Item给Item Pipeline,将(Spider返回的)Request给调度器。
(从第二步)重复直到调度器中没有更多地request,引擎关闭该网站。
4.Scrapy的优点:
我们为什么要使用Scrapy,而不使用其他爬虫框架,除了成熟稳定之外,还有很多其他优势。
使用可读性较好的xpath代替正则处理html解析
支持shell方便调试
高扩展,低耦合,方便定制功能
编码自动检测以及健壮的编码支持
有强大的统计功能和log系统
支持多URL异步请求
二.开发环境的搭建
1.安装python环境
目前Scrapy同时支持python2.7版本和python3.3以上,所以可以根据自己需要选择不同的Python版本。本文针对的开发环境使用的是python3.5,如果你是初学者建议使用python3开始学习,不用考虑python的许多历史包袱。
Python各个版本下载地址:https://www.python.org/downloads
2.安装Scrapy
由于官方文档有Scrapy安装教程,这里不做详细说明,安装方法可以参考官方文档。
这里说下Windows下可能会遇到的问题,因为Scrapy依赖部分第三方框架,所以在安装的Scrapy的同时也会一起安装相关的第三方框架。部分第三方框架可能会出现安装失败的情况,如:
Twisted在Windows环境下安装失败,需要手动下载Twisted在下的Windows安装包http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted。根据自己的windows和python版本选择对应下载安装包。

如果下载的安装包是"Twisted-17.1.0-cp35-cp35m-win_amd64.whl",则调用命令
pip install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
Lxml在Windows环境下安装失败,与Twisted情况相似。需要手动下载安装包。http://www.lfd.uci.edu/~gohlke/pythonlibs/#lxml。
如果下载的安装包是"lxml‑3.7.3‑cp35‑cp35m‑win_amd64.whl",则调用命令
pip install lxml‑3.7.3‑cp35‑cp35m‑win_amd64.whl
3.安装MongoDB
这里使用MongoDB来保存爬取到的网页上的信息,如文章的标题、类别、图片保存路径等等。
MongoDB安装相对简单。先下载安装包https://www.mongodb.com/download-center,如果安装过程中有疑问可以参考官方文档。Windows下也可以参考这篇文章MongoDB下载与安装,作者讲的很详细。
MongoDB安装完后还需要安装第三方库pymongo,我们需要pymongo在python代码中操作MongoDB。
安装命令:
pip install pymongo
4.安装Redis
Redis是一个数据结构为key-value键值对的存储系统。在爬虫中使用Redis主要是为了存取缓存,记录自动更新Http代理的时间,对已经爬取的网页URL进行过滤等等。
Redis的安装教程和下载地址在官网链接中https://redis.io/download。
Redis还目前没有Windows版本,所以如果要安装Windows版本,只能使用Microsoft Open Tech group 提供的Redis版本。Github中有下载地址和安装教程https://github.com/ServiceStack/redis-windows。
接着安装第三方库redis
安装命令:
pip install redis
5.安装第三方库
pillow:处理对图片的裁剪、保存
pip install pillow
requests:基于 urllib,采用Apache2 Licensed开源协议的HTTP库
pip install requests
schedule:使用schedule进行定时任务管理
pip install schedule
6.安装IDE
推荐使用PyCharm,可以说是目前做python开发最好的IDE,PyCharm社区版提供的功能就已经足够强大了。
最后
现在我们对Scrapy已经有了基本的认识,开发环境搭建也已经完成,接下来就开始进行代码编写。Python爬虫实战-使用Scrapy框架爬取土巴兔(二)
附:
详细的项目工程在Github中,如果觉得还不错的话记得Star哦。
作者:imflyn
链接:https://www.jianshu.com/p/5355b467d414






