
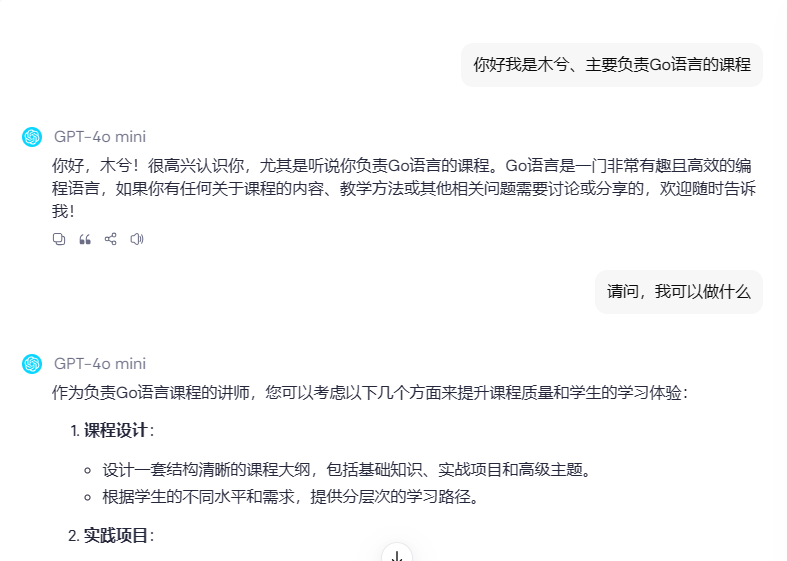
在平常使用ChatGPT相关产品的时候,在聊天的对话过程中ChatGPT记住了我们之前的对话记录,并且从记录中返回出准确的结果,因此我们常认为是ChatGPT具有记忆的功能,然真的是这样嘛?
理解记忆机制
我们可以调用ChatGPT的Api接口来进行验证,通过前后问题的咨询与返回的信息验证对比: 如下两图
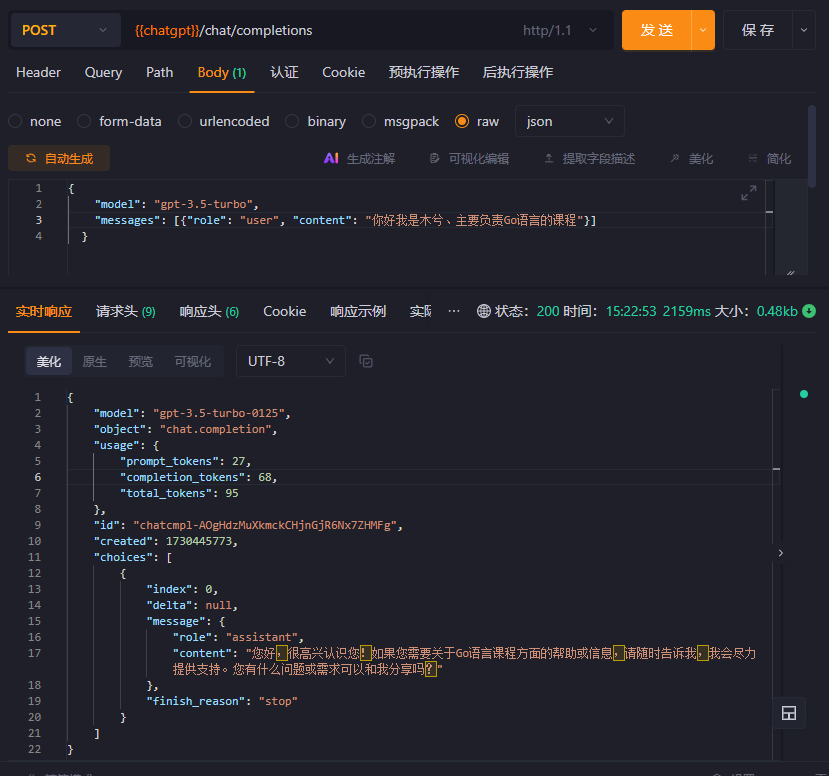
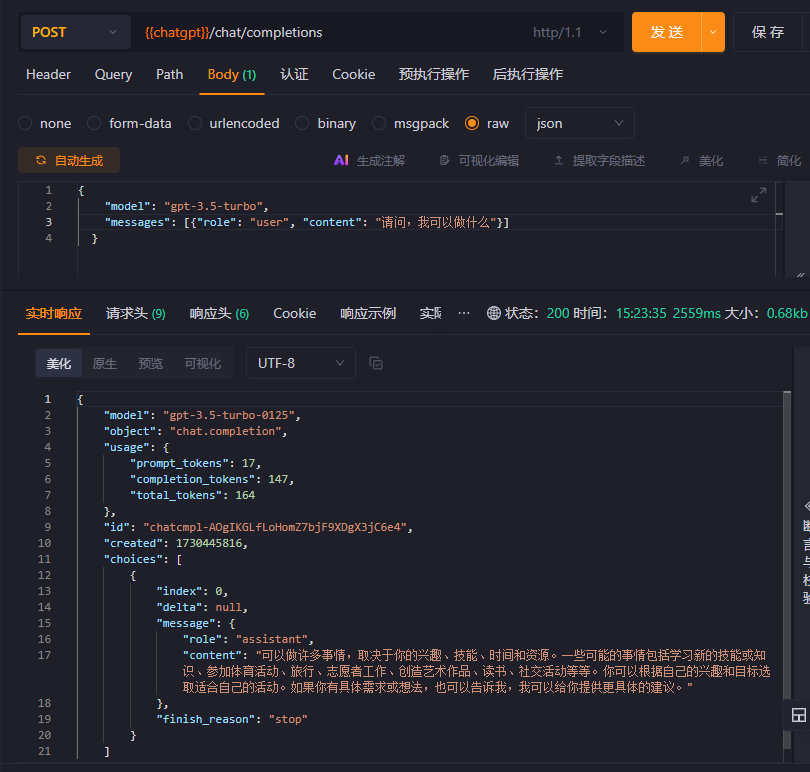
经过执行之后可以发现,ChatGPT并没有和前面一样返回出“我可以做什么”的具体信息,因此显然从这可以看出ChatGPT本身不具备记忆功能,那市面上的哪些软件是如何实现的呢?
在langchain中针对这种场景提供了memory核心机制,该机制可以用于记录用户在聊天过程中的对话信息,在进行大模型调度的时候它会将记忆信息与用户输入信息组合一起发送给大模型,大模型再基于接收到的信息进行处理。 所以实际上我们的第二次信息描述的提示词如果经过langchain中的memory处理后应是如下内容。
历史对话:
user:你好我是木兮、主要负责Go语言的课程
AI:你好,木兮!很高兴认识你,尤其是听说你负责Go语言的课程。Go语言是一门非常有趣且高效的编程语言,如果你有任何关于课程的内容、教学方法或其他相关问题需要讨论或分享的,欢迎随时告诉我!
请问,我可以做什么
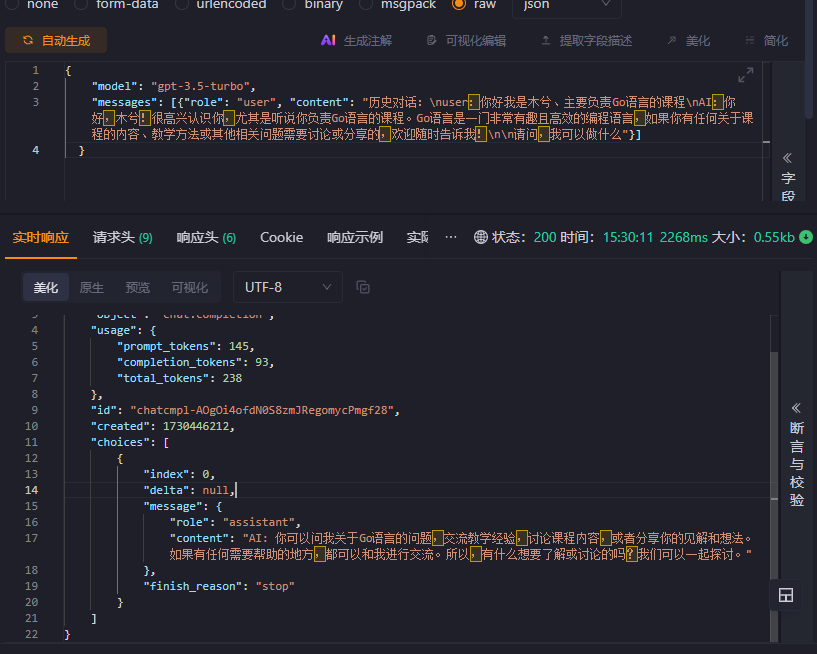
调用模型后可以发现返回与之相关的内容,说明大模型是查阅了我们的历史记录。所以大模型的记忆就是:将以往的对话记录经过处理后与用户当前输入信息组合发送给大模型从而实现ChatGPT的记忆功能,因此本质来看还是对提示词的处理。
langchain中的记忆机制
langchain中有多种记忆机制,我们可以把它们理解为是多种对历史对话处理的策略。
完整对话:就是 人 与 AI 一问一答的对话
- simple:啥也不干,不记录不处理
- buffer:有几次完整对话就的记录几次完整对话,不会修改聊天记录,不会删除记录,只做新增;缺点聊天越多记录也就越多,以后每次问题消耗也就越大。
- token_buffer: 对buffer优化;会设置一个最大token数(简单理解就是聊天中的 文字 最大上限),如果超过就会根据最新消息往后计算将历史多余的记录删除。记录对话方式不会改变
- windows_buffer:对buffer优化;与token_buffer的区别是它判断的条件是,完整聊天对话的次数上限
下面这些是在langchainGo中还未实现的,意味着咋们得自己实现 o(╯□╰)o
- summary:与前token_buffer及windows_buffer的区别在于,它是在用户完成一次完整对话后,就调用大模型将以往记录与最新对话内容进行总结并记录起来,这种方式的优点适合于长对话,缺点token消耗多。
- summary_buffer: summary 与 token_buffer或windows_buffer 的结合版本,定义一个阚值可以是token数量也可以是windows大小,当聊天记录量达到后就就会调用大模型对前面的内容进行总结,然后记录总结内容并将buffer中的对话记录清空。
如下是关于memory机制的使用示例:我们可以让其与Chains结合一起使用
var (
apiKey = ""
url = ""
)
func getLLmOpenaiClient(t *testing.T, opts ...openai.Option) *openai.LLM {
opts = append(opts, openai.WithBaseURL(url), openai.WithToken(apiKey))
llm, err := openai.New(opts...)
if err != nil {
t.Fatal(err)
}
return llm
}
func TestLLM_Chain_Conversation(t *testing.T) {
llm := getLLmOpenaiClient(t)
c := chains.NewConversation(llm, memory.NewConversationBuffer())
c.CallbacksHandler = callbacks.LogHandler{}
res, err := chains.Run(context.Background(), c, "你好!我是木兮")
NoError(t, err)
t.Log(res)
res, err = chains.Run(context.Background(), c, "我是谁?")
NoError(t, err)
t.Log(res)
res, err = chains.Run(context.Background(), c, "你确定我是木兮嘛?")
NoError(t, err)
t.Log(res)
}
func NoError(t *testing.T, err error) {
if err != nil {
t.Fatal(err)
}
}
chains在使用的执行流程是如下过程
- 先从memory中获取到记忆信息
- 把记忆信息设置到input中
- 通过prompts根据提示词模板将input信息传递到大模型中
- 大模型执行完成后再将返回的结果与当次用户的输入记录到memory中
实现summary
summary:是token_buffer与window_buffer的优化版本每次对话都会总结并记录,他们之间在代码的实现上主要是保存的方法区别,如下是memory接口因此实际上区别主要是SaveContext方法的区别
// Memory is the interface for memory in chains.
type Memory interface {
// GetMemoryKey getter for memory key.
GetMemoryKey(ctx context.Context) string
// MemoryVariables Input keys this memory class will load dynamically.
MemoryVariables(ctx context.Context) []string
// LoadMemoryVariables Return key-value pairs given the text input to the chain.
// If None, return all memories
LoadMemoryVariables(ctx context.Context, inputs map[string]any) (map[string]any, error)
// SaveContext Save the context of this model run to memory.
SaveContext(ctx context.Context, inputs map[string]any, outputs map[string]any) error
// Clear memory contents.
Clear(ctx context.Context) error
}
关于基于大模型实现的流程:
- 构思流程
- 先写提示词
- 测试提示词
- 编写代码
summary流程
根据summary的功能是每次对话都会总结,而SaveContext方法是每次chains执行的时候都会进行调度,所以我们的核心点是聚焦于saveContext方法。 而在方法的参数里是传递input输入、outputs输出,因此在方法中我们只需将input与outputs两个信息组合一下放到大模型里面去执行总结,然后吧总结后的内容保存起来即可。
流程:
- 从input、outputs提取信息
- 组合提示词
- 调度大模型总结
- 总结记录
先写提示词
提示词的来源是从Python版本中的langchain中复制过来的
package memoryx
import "github.com/tmc/langchaingo/prompts"
const (
_DEFAULT_SUMMARIZER_TEMPLATE = `Progressively summarize the lines of conversation provided, adding onto the previous summary returning a new summary.
EXAMPLE
Current summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good.
New lines of conversation:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full potential.
New summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential.
END OF EXAMPLE
Current summary:
{{.summary}}
New lines of conversation:
{{.new_lines}}
New summary:`
)
func createSummaryPrompt() prompts.PromptTemplate {
return prompts.NewPromptTemplate(_DEFAULT_SUMMARIZER_TEMPLATE, []string{
"summary", "new_lines",
})
}
我们也可以自己这么写用结构化的方式
# 角色
你是一个助理,你的工作是根据根据用户输入与AI的回答和以前的总结记录逐步总结,并返回一个新的总结内容
## 示例
新的对话:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full potential.
总结内容:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential.
END OF EXAMPLE
## 历史总结
{{.summary}}
## 新的对话
{{.new_lines}}
测试提示词
# 角色
你是一个助理,你的工作是根据根据用户输入与AI的回答和以前的总结记录逐步总结,并返回一个新的总结内容
## 示例
新的对话:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full potential.
总结内容:
The human asks what the AI thinks of artificial intelligence. The AI thinks artificial intelligence is a force for good because it will help humans reach their full potential.
END OF EXAMPLE
## 历史总结
## 新的对话
Human: 你好!我是木兮
AI: 你好,木兮!很高兴认识你!请问有什么我可以帮助你的吗?
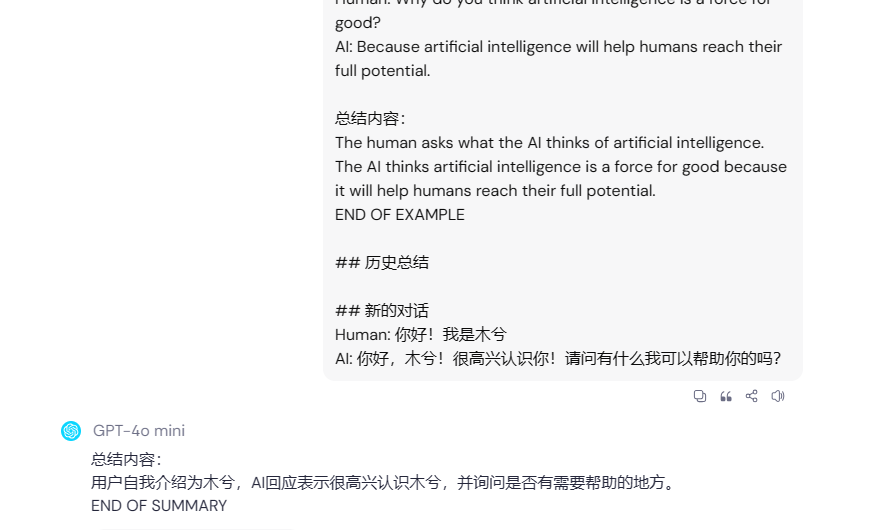
编写代码
go实现buffer的对象是memory.ConversationBuffer里面的机制我们可以直接复用,因此具体代码实现如下
package memoryx
import (
"context"
"fmt"
"github.com/tmc/langchaingo/callbacks"
"github.com/tmc/langchaingo/chains"
"github.com/tmc/langchaingo/llms"
"github.com/tmc/langchaingo/memory"
)
type Summary struct {
*memory.ConversationBuffer
chains.Chain
callbacksHandler callbacks.Handler
}
func NewSummary(llms llms.Model, opts ...Option) *Summary {
opt := applyChatSummaryOptions(opts...)
return &Summary{
Chain: chains.NewLLMChain(llms, createSummaryPrompt(), chains.WithCallback(opt.callbacksHandler)),
ConversationBuffer: opt.ConversationBuffer,
callbacksHandler: opt.callbacksHandler,
}
}
func (s *Summary) GetMemoryKey(ctx context.Context) string {
return s.ConversationBuffer.GetMemoryKey(ctx)
}
func (s *Summary) MemoryVariables(ctx context.Context) []string {
return s.ConversationBuffer.MemoryVariables(ctx)
}
func (s *Summary) LoadMemoryVariables(ctx context.Context, inputs map[string]any) (map[string]any, error) {
return s.ConversationBuffer.LoadMemoryVariables(ctx, inputs)
}
func (s *Summary) SaveContext(ctx context.Context, inputs map[string]any, outputs map[string]any) error {
// get summary
message, err := s.LoadMemoryVariables(ctx, inputs)
if err != nil {
return err
}
summary := message[s.MemoryKey]
// new lines of conversation
userInputValue, err := memory.GetInputValue(inputs, s.InputKey)
if err != nil {
return err
}
aiOutputValue, err := memory.GetInputValue(outputs, s.OutputKey)
if err != nil {
return err
}
newLines := fmt.Sprintf("Homan: %s\nAi: %s", userInputValue, aiOutputValue)
// summary
newSummary, err := chains.Predict(ctx, s.Chain, map[string]any{
"summary": summary,
"new_lines": newLines,
}, chains.WithCallback(s.callbacksHandler))
if err != nil {
return err
}
// save
return s.ChatHistory.AddMessage(ctx, llms.SystemChatMessage{Content: newSummary})
}
func (s *Summary) Clear(ctx context.Context) error {
return s.ConversationBuffer.Clear(ctx)
}
实现summarybuffer
summarybuffer是在summary基础上优化,summary虽然好但是它也存在致命的问题就是token消耗巨多,summarybuffer优化之处在于将summary 与 token_buffer或windows_buffer 的结合取其精华去其糟粕。 我们可以对它进行实现,在阚值的验证上我们基于token数量来实现【自己也可以将其改为windows的方式】,具体实现如下:
package memoryx
import (
"context"
"fmt"
"github.com/tmc/langchaingo/callbacks"
"github.com/tmc/langchaingo/chains"
"github.com/tmc/langchaingo/llms"
"github.com/tmc/langchaingo/memory"
"github.com/tmc/langchaingo/prompts"
)
type SummaryBuffer struct {
*memory.ConversationBuffer
chains.Chain
MaxTokenLimit int
callbacksHandler callbacks.Handler
buffer llms.ChatMessage
messageTypeAi string
messageTypeHuman string
}
func NewSummaryBuffer(llms llms.Model, maxTokenLimit int, opts ...Option) *SummaryBuffer {
opt := applyChatSummaryOptions(opts...)
return &SummaryBuffer{
Chain: chains.NewLLMChain(llms, prompts.NewPromptTemplate(opt.prompt, []string{
"summary", "new_lines",
}), chains.WithCallback(opt.callbacksHandler)),
MaxTokenLimit: maxTokenLimit,
ConversationBuffer: opt.ConversationBuffer,
callbacksHandler: opt.callbacksHandler,
buffer: nil,
messageTypeAi: opt.messageTypeAi,
messageTypeHuman: opt.messageTypeHuman,
}
}
func (s *SummaryBuffer) GetMemoryKey(ctx context.Context) string {
return s.ConversationBuffer.GetMemoryKey(ctx)
}
func (s *SummaryBuffer) MemoryVariables(ctx context.Context) []string {
return s.ConversationBuffer.MemoryVariables(ctx)
}
func (s *SummaryBuffer) LoadMemoryVariables(ctx context.Context, inputs map[string]any) (map[string]any, error) {
var (
res []llms.ChatMessage
err error
)
if s.buffer != nil {
res = append(res, s.buffer)
}
messages, err := s.ChatHistory.Messages(ctx)
if err != nil {
return nil, err
}
res = append(res, messages...)
if s.ReturnMessages {
return map[string]any{
s.MemoryKey: res,
}, nil
}
bufferString, err := llms.GetBufferString(res, s.HumanPrefix, s.AIPrefix)
if err != nil {
return nil, err
}
return map[string]any{
s.MemoryKey: bufferString,
}, nil
}
func (s *SummaryBuffer) SaveContext(ctx context.Context, inputs map[string]any, outputs map[string]any) error {
// save
userInputValue, err := memory.GetInputValue(inputs, s.InputKey)
if err != nil {
return err
}
err = s.ChatHistory.AddUserMessage(ctx, userInputValue)
if err != nil {
return err
}
aiOutputValue, err := memory.GetInputValue(outputs, s.OutputKey)
if err != nil {
return err
}
err = s.ChatHistory.AddAIMessage(ctx, aiOutputValue)
if err != nil {
return err
}
// check
messages, err := s.ChatHistory.Messages(ctx)
if err != nil {
return err
}
bufferString, err := llms.GetBufferString(
messages,
s.ConversationBuffer.HumanPrefix,
s.ConversationBuffer.AIPrefix,
)
if err != nil {
return err
}
if llms.CountTokens("", bufferString) <= s.MaxTokenLimit {
// 未超过上限
return nil
}
var summary string
for _, message := range messages {
switch message.GetType() {
case llms.ChatMessageTypeAI:
summary += fmt.Sprintf("%s: %s\n", s.messageTypeAi, message.GetContent())
case llms.ChatMessageTypeHuman:
summary += fmt.Sprintf("%s: %s\n", s.messageTypeHuman, message.GetContent())
}
}
var newLines string
if s.buffer != nil {
newLines = s.buffer.GetContent()
}
newSummary, err := chains.Predict(ctx, s.Chain, map[string]any{
"summary": summary,
"new_lines": newLines,
}, chains.WithCallback(s.callbacksHandler))
if err != nil {
return err
}
s.buffer = &llms.SystemChatMessage{Content: newSummary}
return s.ChatHistory.SetMessages(ctx, nil)
}
func (s *SummaryBuffer) Clear(ctx context.Context) error {
s.buffer = nil
return s.ConversationBuffer.Clear(ctx)
}
func (s *SummaryBuffer) getNumTokensFromMessages(ctx context.Context) (int, error) {
messages, err := s.ChatHistory.Messages(ctx)
if err != nil {
return 0, err
}
bufferString, err := llms.GetBufferString(
messages,
s.ConversationBuffer.HumanPrefix,
s.ConversationBuffer.AIPrefix,
)
if err != nil {
return 0, err
}
return llms.CountTokens("", bufferString), nil
}





