

大型语言模型(LLM)是随处可见的工具,用于处理并生成自然语言文本。自2018年以来,几代大型语言模型不断推动了LLM的能力边界。如今的大型语言模型,例如LLaMA 2和GPT-4,可以应用于几乎所有经典自然语言处理(NLP)任务,而2018年的早期模型则做不到这一点。这些第一代LLM的参数量大约为1.5亿,通常在多伦多书籍语料库(Toronto Book Corpus)和维基百科文本上进行训练,目的是优化给定上下文的单词预测。尽管模型架构有所差异,例如注意力头的数量和隐藏维度,但这些模型需要为任何下游NLP任务进行微调。
但是,究竟什么是微调(tune)模型呢?这篇文章将解释如何微调第一代大规模语言模型的一些基本概念和技术。文章首先介绍了常用的自然语言处理基准测试和数据集,然后详细说明了微调的具体技术,最后还展示了如何保存微调后的模型以便进行推理。
本文最初发布在我的博客[admantium.com]。暑假期间我会暂停更新文章,直到九月,文章将每隔一周更新一次。
预训练的语言模型(LLM):Transformer架构的组件变压器是一种特定类型的神经网络模型。它是不断涌现的科学创新的结果,从而形成了一种可扩展机制,能够为文本中的每一个单独词汇单元(token)提供绝对意义和相对意义。这种注意力机制是在著名的论文《注意力就是你所需要的》(Attention is All You Need)中提出的。如今,变压器已成为大规模语言模型事实上的标准架构。
一个变压器模型由几个相互关联的模块组成。整个架构如下图所示。
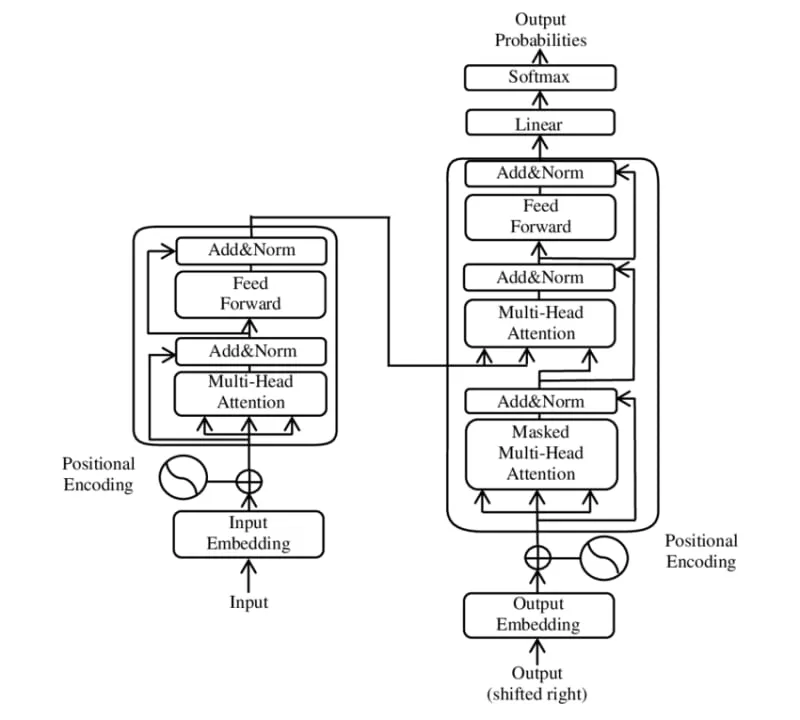
来源:维基百科,Transformer(机器学习模型),https://zh.wikipedia.org/wiki/Transformer(机器学习模型)_(点击链接查看) _
这些部分是怎么运作的呢?
- 输入转换:每个标记都使用字节对编码转换为数值表示,并增加相对位置信息。
- 编码器:通过所有层迭代处理每个标记。自注意力层既考虑了标记本身的绝对位置,也考虑了与其他标记的相对位置。
- 解码器:迭代处理编码器的输出和解码器生成的标记。跨注意力层消耗编码器输出,自注意力层以与编码器自注意力层相同的方式处理解码器输出标记。
- 前向网络:每个编码器和解码器层都包含一个前向神经网络,在此网络中信息仅向前流动,但残差连接允许跳过某些层。该网络的任务是学习有效的位置编码,以帮助模型理解序列中的位置信息。
- 注意头:在注意头中,学习三个不同的权重矩阵:查询、键和值。每个标记在通过头部处理时,与每个矩阵相乘以生成该标记的输出表示。通常每一层有多个注意头,这些头学习不同类型的单词之间的相关性,例如预测下一个单词或识别动词适用的主题等。
基于Transformer的模型使用的是要么同时具备编码器和解码器(如BART),要么仅具编码器(如BERT),要么仅有解码器(如XLNet)。自2021年起,仅解码器的模型成为主导的Transformer架构类型,因为交叉注意力层能够独立完成整个编码器模块的功能。
微调任务、基准和数据集为了对特定任务进行微调,需要微调一个大语言模型(LLM),选择合适的数据集,创建性能比较的基准,并进行微调训练。有趣的是,随着LLM变得越来越复杂并且研究关注度的增加,这三方面逐渐融合,产生了多个常用的基准和配套数据集,这些基准和数据集被用于训练和测试模型。
以下表格列出了最重要的基准。
缩写 名称 描述 指标
cola Corpus of Linguistic Acceptability Matthew’s Corr
sst2 Stanford Sentiment Treebank 准确率
mrpr Microsoft Research Paraphrase Corpus F1 / 准确率
stsb Semantic Textual Similarity Benchmark 皮尔逊-斯皮尔曼相关系数
qqp Quora Question Pairs F1 / 准确率
mnli MultiNLI 准确率
qnli QNLI 准确率
rte Recognizing Textual Entailment 准确率
wnli WNLI 准确率
— 诊断 主要指标 Matthew’s Corr
所有这些不同的基准都被汇总到GLUE——通用语言理解测试中。具体任务是用来测量和计算检测语言上是否可以接受的句子、两个文本段落之间的蕴含关系,或者问答题目的得分。
这种预训练的Transformer模型的自我反省要明白微调过程是如何改变模型的,先得了解预训练模型是个什么,我们拿纯解码器的BERT模型做个例子。
BERT模型是通过掩码语言建模和下一句预测任务进行训练的。在掩码语言建模中,给定一组词,计算出缺失词的概率。在下一句预测任务中,模型会从一组可能的下一句中,选择概率最高的实际下一句。
这里是一个非常技术性的描述,说明输入数据是如何通过Transformer进行处理的。输入数据通过每一层进行处理,在每一层中,token 首先通过跨注意力机制处理,然后是自注意力机制,最后通过前向网络进行处理。输入 token 的表示形式被转换为单独编码的字对及其位置编码,然后在所有先前生成的 token 的上下文中被进一步调整,最后通过前向网络进行调整,以规范化信息。然后这种表示形式会传递到下一层。当解码器生成第一个 token 时,这个 token 的表示形式将被所有后续的自注意力头处理,作为第一个输出 token,而在处理第二个新的输入 token 时同样如此。
变换器模型的训练过程本质上就是不断地进行梯度反向传播。解码器的输出是一个多维矩阵,为模型词汇表中的每个标记分配一个概率。以期望的标记作为训练的目标,模型的权重和偏差在每个训练周期后都会被更新,以优化模型的准确度。
BERT模型包含1.1亿个参数。这是每一层的输入维度与连接全连接层的输入维度相乘,再乘以层数得到的。完成预训练后,这1.1亿个参数代表了基于其掩码语言建模和下一句预测任务所学的最终状态。
微调Transformer模型微调就是让大语言模型适应特定的任务。调整可以采取不同的形式,并且根据任务的不同,改变大语言模型的各个方面。
通常,模型的词汇表和嵌入层不会被修改。分词过程需要考虑这些词是否都在大语言模型(LLM)的词汇表中,如果没有,则需要删除这些词或将其替换为“未知”标记(而不是“掩码”类型)。此外,输入标记的总数不能超过LLM允许的最大长度。输入处理过程也不会改变:标记转换为字元对编码,然后添加位置编码并将这些标记通过LLM的层传递,生成输出标记的概率矩阵。从这个矩阵中逐步生成输出单词或文本。
通常改变的是模型架构、训练目标和具体的训练指标,用于确定反向传播变化。在问答任务中,解码层生成的输出标记(token)会一直累积,直到产生一个结束标记(end-of-message token)。生成的句子随后会与特定指标(如交叉熵损失)进行比较,以确定性能得分。基于Transformer的大规模语言模型是通过反向传播进行梯度更新训练的。反向传播也是用于微调的方法。
从原则上来说,大型语言模型(LLM)的权重和偏差是可以修改的,但需要考虑实际的限制和限制因素。训练是一个计算密集型的过程,而完整的重新训练会彻底地改变模型,这可能导致其在之前的测试基准上表现变差。相反,要么修改LLM的最后几层,要么添加新的层,这些层可以在微调训练中完全调整。
以下是一些可以采用的模型修改策略:
- 全面重新训练:所有模型参数(注意力权重矩阵、前向网络权重)都开放进行值更新。这些更新可以通过反向传播或其他方法实现。
- 逐步解冻:模型参数更新仅限于单个层。在开始微调时,仅更新最后一层的参数,然后在经过一定数量的更新后,倒数第二层的参数也被包括在内,依此类推。
- 层特定解冻:不对所有层参数进行梯度更新,而是只修改某些参数,例如仅修改自注意力头或仅修改前向网络的参数。
- 层修改:在每一层内部增加额外的块,从而改变Transformer架构。通常在前向网络之后,添加一个新的神经网络块(如ReLU)。此块与前向网络具有相同的维度。仅更新这些新块的权重。
- 层添加:添加额外的层到编码器或解码器中。这些层可以是独立的解码器,也可以是其他类型的组合。仅更新添加层的权重。
据我所知,微调流程并不是完全的重新训练,而通常是逐步解锁并增加层级的组合等等。
微调步骤机器学习项目通常遵循一系列固定的步骤。首先加载并探索数据集,接着定义模型并配置训练参数,最后进行模型的训练并评估其表现。
通常,大型语言模型的微调也通常遵循这些步骤,但侧重点不同。为了更便于理解这个解释,下面将在微调BERT模型用于问答的背景下讨论这些阶段。
- 基础模型选择:第一步是确定将使用哪个具体的大型语言模型,这会设置一些约束条件,最重要的是分词方案。例如,使用BERT时,所有的句子都需要以
CLS标记开头,两个连续的句子需要用SEP分隔,所有序列都需要添加PAD标记以达到规定的序列长度。 - 微调目标和方法:确定具体的任务目标,并创建一个具体的训练方法,该方法会引导后续所有阶段的决策。同样重要的是,必须充分理解基础模型的所有限制,这些限制将影响微调过程。
- 数据集选择:训练和评估数据集都必须以纯文本格式的提供,因为其他编码或分词方案可能无法与预期模型兼容。
- 数据集探索与预处理:与所有机器学习项目一样,数据集应检查任何类型的异常,例如未知编码、其他语言的文本异常以及在目标模型中未定义的标记。此外,还可以计算输入材料的一般质量,然后例如删除所有低于阈值的输入。
- 训练和测试数据集分词:这一关键阶段将原始文本输入转换为LLM所需的格式。如果原始文本包含未包含在模型原始输入数据中的标记,则需要对其进行屏蔽或删除。此阶段还包括根据训练目标生成合适的分词输出。在BERT模型示例中,一个典型策略是创建结合问题和包含答案段落中的标记的序列。
- 模型修改:加载并根据一个或多个修改策略来定制模型。例如,对于用于问答的微调BERT模型,添加一个新的输出层以计算答案段落中令牌的起始和结束位置。
- 训练参数:根据训练目标定义合适的训练度量,例如对于生成文本,准确度为度量,对于分类,交叉熵为度量。同时,确定所有训练超参数,如批次大小、学习率和优化器。
- 训练与评估:模型按定义的轮次进行训练,计算并比较各轮的指标,确定最优模型。训练过程的手动定义程度很大程度取决于所使用的库,因为每个库支持不同的抽象和功能,例如在多个服务器或GPU上进行并行训练。
训练库提供了有助于微调的有用抽象概念。transformers库明确支持使用BertForSequenceClassification和BertForQuestionAnswering管道来添加层和逐步解冻,还支持使用BertForPreTraining、BertForMaskedLM和BertForNextSentencePrediction进行完整的重新训练。具体的代码示例超出了本文的讨论范围,但如果您感兴趣,可以参考BERT微调教程与PyTorch。Collab笔记本Fine-tuning BART双语摘要。
2018年发布的大型语言模型是基于Transformer架构,并通过掩码语言建模或下一句预测进行训练。这些模型展现了令人着迷的文本生成能力,并可以从训练数据中获取信息。为了将这些模型应用于如分类、摘要和问答等自然语言处理任务,需要进行微调。本文详细解释了所有必要的微调方面。第一部分介绍了基准测试和数据集。第二部分详细介绍了基于Transformer的模型的技术方面,并阐明了微调实质上涉及调整权重和偏差参数。第三部分则将这种方法推广到模型调整策略,并具体描述了微调过程的步骤。





