

首先,让我们定义什么是流处理管道。在Java中,流处理管道是一系列处理流数据的操作。它主要包含三个部分:
- 源头:流的源头,比如一个集合、一个数组、一个生成器函数或一个 I/O 通道。这是数据的来源。
- 中间操作:这些操作会转换或过滤流中的数据。例如
filter()、map()和sorted()。中间操作是惰性的,意味着它们不会在调用最终操作之前执行任何处理,直到管道中最后一个操作执行时才会真正处理数据。 - 终端操作:管道中的最后一个操作,它触发流的处理。例如
forEach()、collect()和reduce()。一旦调用了终端操作,流就会被消费完,且不能再应用任何其他操作。
现在,我们来定义一下什么是Java中的流中间操作。在Java中,流的中间操作是对流中的元素进行处理并生成另一个流的操作。这些操作可以转换、过滤、检查或以其他方式修改流中的元素,但不会消耗这个流。关键是中间操作总是返回另一个流,这使得更多的操作可以被链式调用。
中间操作的一些关键特点包括,
- 惰性求值:中间操作是惰性的,这意味着当它们被调用时,并不会实际处理流中的元素。相反,它们构建了一个操作管道,只有在调用终端操作时才会对数据进行处理。
- 链式调用:由于中间操作返回一个流,因此可以将它们链接起来以形成复杂的处理管道。这种链式调用使得代码更加清晰简洁。
- 无状态或有状态:中间操作可以是无状态的,即每个元素是独立处理的,也可以是有状态的,即操作需要记住来自先前元素的信息,例如
distinct()或sorted()。
如果我们像下面的例子那样写代码,由于流没有以终结操作结束,流就不会被处理。
如下所示的代码示例:stream()
.intermediateOperation1()
.intermediateOperation2()
...
.intermediateOperationN()
注意我说的是“不会结束”这一点。正如其名,终端操作会结束流;一旦执行,流就会被消耗掉,以后就无法再用了。
例如,这段代码甚至编译不过去。
stream() // 开始一个数据流
.intermediateOperation1() // 进行第一个中间操作,例如过滤或映射
.terminalOperation1() // 执行第一个终结操作,如收集或转换结果
.intermediateOperation2() // 再进行另一个中间操作,可能进行更多的转换或过滤操作
stream() // 再次开始一个新的数据流
.intermediateOperation1() // 进行第一个中间操作,与前一个流的操作相同
.terminalOperation1() // 执行第一个终结操作,与前一个流的操作相同
.terminalOperation2() // 执行另一个终结操作,例如最终收集结果或打印输出注意:这里的操作是假设的,具体的操作名称可能会根据实际的编程环境有所不同。
这是因为在终端操作结束流并将其转换为比如列表时,一旦流结束,任何后续操作尝试都将失败,因为此时的结果已不再是流。
这段代码会引发异常,因为第一个终端操作关闭了流,导致后续操作无法进行。
Stream<T> stream = Stream.of(element1, element2)
.intermediateOperation1();
stream.terminalOperation(); -- 流被关闭了
stream.intermediateOperation2(); -- IllegalStateException: 这会抛出异常
在大多数情况下,流处理管道通常具有这样的结构:
// 下面的代码展示了如何对一个流进行一系列中间操作,最后执行一个终端操作:
stream() // 流式处理
.intermediateOperation1() // 中间操作1
.intermediateOperation2() // 中间操作2
...
.intermediateOperationN() // 中间操作N
.terminalOperation() // 终端操作
不过,管道也可以像第一个例子那样构建,包含中间步骤,等到调用终端操作时再执行。
## 有状态操作和无状态操作
在Java的Stream API里,操作可以分为两种类型:有状态的和无状态的。理解这两种类型的区别对于有效地利用Java中的流来说至关重要。
* **_无状态的操作_** 在处理流中的新元素时不会保留之前处理的元素的任何状态。每个元素都是独立处理的,这意味着操作不需要知道它之前的元素。因此,它们可以更高效地并行处理,通常表现更佳。
* **_有状态的操作_** 在处理流中的元素时需要维护一些状态信息。处理一个元素的结果可能依赖于之前的元素,或者只有在处理完整个流后操作才能输出结果。
## 限制
`limit` 操作,顾名思义,限制了流管道处理的元素数量。
返回一个最多具有指定数量元素的新流
换句话说,它会截取流,只保留参数指定数量的元素。它既适用于无限的流也适用于有限的流。
List<Integer> example1 = Stream.iterate(1, n -> n + 1)
.limit(3)
.toList(); // 将流转换为列表
// 生成一个包含1, 2, 3的整数列表整数列表 example2 = Stream.of(1, 2, 3, 4, 5)
.limit(3) // 限制前三个元素
.toList(); // 转换为列表
// 生成一个整数列表,包含从1到5中的前三个数字
// [1, 2, 3]
这是一个有状态的操作,因为它需要记录已处理的元素数量。对于有序的并行流来说,它会更昂贵,因为它需要在不同的流部分之间进行协调,以确保正确数量的元素能够被传递。
## 跳过步骤
`skip` 操作,正如名字所暗示的,会跳过流开头的几个元素。
Stream<T> 跳过(long n) 表示跳过前n个元素。
跳过多少元素是由传递给这个方法的参数来决定的。
List<Integer> example3 = Stream.of(1, 2, 3, 4, 5)
.skip(3) // 跳过前3个元素
.toList(); // 将流转换为列表
// [4, 5] // 输出结果为 [4, 5]
`skip` 是一个有状态的操作,因为它需要记住它跳过的元素。这在并行处理中可能会增加额外的开销,特别是在需要保持元素顺序时。
我们可以在同一条管道中结合使用 `skip` 和 `limit` 操作,精确地定义流的长度。
List<Integer> example4 = Stream.iterate(1, n -> n + 1)
.skip(1)
.limit(3)
.toList();
// 输出结果为:[2, 3, 4]// 生成一个从1开始的无限整数流,每个数比前一个数大1
Stream.iterate(1, n -> n + 1)
// 跳过第一个元素
.skip(1)
// 只保留前三个元素
.limit(3)
// 将流转换为列表
.toList();
## 独特的操作
这个操作会去除数据流中的重复项。
Stream<T> distinct(); // 返回一个包含与输入流中元素不同的元素的流
换句话说,它返回一个新的仅包含唯一元素的流,唯一性判断依据是 `Object.equals()` 方法。该操作利用 `Object.hashCode()` 方法高效地追踪和比较元素。因此,需要正确重写 `equals()` 和 `hashCode()` 方法,以保证对象的正确比较。
List<Integer> example5 = Stream.of(1, 1, 2, 2, 3, 3)
.distinct()
.toList();
// 从整数流中去除重复项并转换为列表:[1, 2, 3]
这是一项有状态的操作,因为它需要记录所有之前遇到的元素来确保唯一性。特别是在多线程环境中,它可能会在资源占用方面比较耗资源,因为需要维护状态的额外开销。
## 已整理好的
`sorted` 方法会对流中的元素进行排序,通常是按升序或降序排列。`Stream` 接口有此方法的两个重载版本,它们可能有不同的参数或功能。
Stream<T> 流的排序();
此版本不需要任何参数,并按元素的自然顺序对流进行排序操作。例如,你可以用它来对整数流进行排序操作。
List<Integer> example6 = Stream.of(2, 3, 5, 4, 1)
.sorted()
.toList();
// 生成一个整数列表,包含2, 3, 5, 4, 1,排序后转换为列表。结果为 [1, 2, 3, 4, 5]
第二个版本的实现接受一个 `Comparator` 参数,允许你为流定义自定义排序规则。
Stream<T> 排序(用于比较的比较器<? super T> comparator);
我们可以这样使用它来实现逆序效果:
List<Integer> example7 = Stream.of(2, 3, 5, 4, 1)
.sorted(Comparator.reverseOrder())
.toList();
// 生成一个整数列表,从大到小排序: [5, 4, 3, 2, 1]
想了解更多关于如何在流中使用 `Comparator` 的方法,包括多个示例,请查看我关于该主题的全面教程。
## [Java Comparator 接口Java 提供了 Comparable 和 Comparator 两个接口,可以用来对一组对象进行排序。在之前的教程中,我...medium.com](https://medium.com/javarevisited/java-comparator-interface-1e350c0c706f?source=post_page-----a8fb7be4cac1--------------------------------)
`sorted()` 操作是一个带有状态的操作,意味着它需要先处理所有元素才能输出排序结果。这使其资源消耗较大,特别是在并行流处理中。
## 乱七八糟的操作
`unordered()` 方法是 Java Stream API 中用于取消流中元素顺序的方法。默认情况下,某些流(特别是从列表等有序来源来的流)会保持元素的顺序。这种顺序可能会影响某些操作的效率,尤其是在并行处理时。
對於未排序的S,可以使用未排序的函數。
当你在流上使用 `unordered()` 方法时,这意味着处理或生成元素的顺序不再重要。这可能使处理变得更高效,特别是在使用并行流的情况下。这样就不再需要保持元素的顺序,从而使得实现更加自由,尤其是在并行流处理中更为明显。
需要注意的是,` unordered() `实际上并不会对元素进行重新排序;它仅仅移除了操作需要保持顺序的要求。如果流已经是无序状态,调用此方法没有任何效果。
使用 `unordered()` 可以带来好处,特别是在处理并行流时,当你不在乎流中的元素顺序时,因为它能让元素处理更灵活,从而提高性能。
List<Integer> example8 = List.of(2, 3, 5, 4, 1)
.stream()
.unordered() // 设置流为无序
.parallel() // 可以提升性能
.toList();
这项操作是无状态性的,不依赖于或维护流元素之间的任何状态信息。相反,它只是提示可以忽略元素的顺序。
## 窥视操作:
流式处理API中的`peek`方法是一个有趣的操作。
Stream<T> peek(Consumer<? super T> 操作);
它的主要目的是观察流中的元素而不对其进行任何修改。换句话说,它返回一个具有相同元素的流,并对每个元素执行由参数传递的 `Consumer` 指定的操作。
虽然 `peek()` 对调试很有用,但是通常不建议在生产代码中使用。在下面的例子中,我们使用 `peek` 打印流排序前和排序后的每个元素,这让我们了解流在不同阶段的状态。
List<Integer> example9 = Stream.of(2, 3, 5, 4, 1)
.peek(System.out::println) // 输出每个元素
.sorted(Comparator.reverseOrder())
.peek(System.out::println) // 输出排序后的每个元素
.toList(); // 将流转换为列表// 注释:将数字列表排序并输出
需要注意的是,`peek()` 是一个不改变状态的操作,不会影响流的大小、顺序或元素类型的特性。
## 筛选操作
毫无疑问地,Stream API (流式处理API) 中最强大的操作之一,它改变了我们过滤集合的方法,消除了我们以前常用的繁琐的 `if` 语句,使代码更加简洁清晰。
流<类型T>过滤(一个可以应用于类型T的谓词<? super T>)
此操作的结果是一个流,其中只包含符合所提供谓词的数字元素。例如,`filter()` 操作会从流中移除所有奇数。
List<Integer> example10 = Stream.of(1, 2, 3, 4, 5)
.filter(n -> n % 2 == 0)
.toList();
// [2, 4]
这是一个无状态的流程,它有可能减少数据流中的元素数量,但不会打乱它们的顺序或改变它们的类型。
## 筛选操作
在Java的Stream API中,`takeWhile()`方法是一个强大的工具,用来从流中取出满足条件的元素。只要元素满足某个条件,就可以取出它们,一旦找到不符合条件的元素,操作就会停止,不会再处理其他元素,即使后续的元素可能满足条件。
Stream<T> takeWhile(Predicate<? super T> predicate) {...} // takeWhile(条件为真的情况下一直取元素)
它以短路方式运作,意味着一旦某个元素不符合条件,它就会停止处理,不再检查其他元素。这种方法保持了流中元素的顺序,适合处理序列中的元素,直到某个条件不再满足为止。
这用一个例子来说明更好。
// 示例:从流中取出所有小于4的数字并转换为列表
List<Integer> example11 = Stream.of(1, 2, 3, 4, 5, 1)
.takeWhile(n -> n < 4) // 取出所有小于4的元素
.toList(); // 转换为列表
// 输出: [1, 2, 3]

在本例中,`takeWhile()` 方法使用了“元素小于 4”的条件。因此,一旦遇到不满足条件的元素 `4`,操作就会停止。所有小于 `4` 的元素都会被包含在结果中。需要注意的是,尽管在 `5` 之后的元素 `1`(尽管它满足条件),由于 `takeWhile()` 会立即停止处理,因此该元素不会被包含。
我们再来看一个例子,在这个例子中,谓词在第一个元素上成立。这样的话,我们就会得到一个空的流。
// 下面的代码创建了一个整数流,过滤出小于4的数,然后转换为列表。结果为空列表。
List<Integer> example12 = Stream.of(4, 1, 2, 3, 4, 5)
.takeWhile(n -> n < 4)
.toList();
// 结果为空列表 // 结果: []
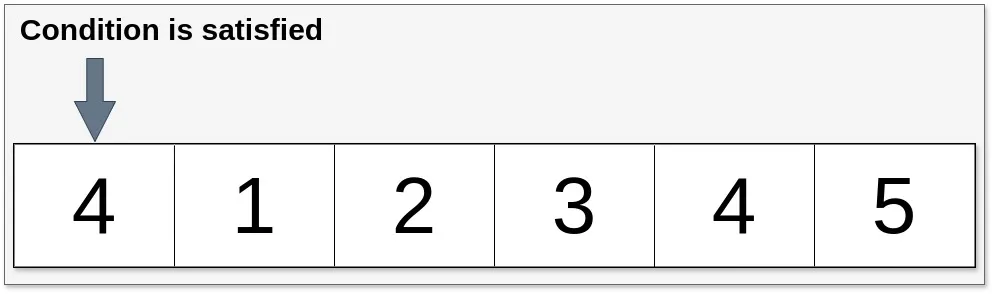
`takeWhile()` 是一个无状态操作,根据谓词处理元素,不保留任何状态。
需要注意的是,如果流没有顺序,`takeWhile()` 方法的返回结果可能是不确定的。如下例:
List<Integer> example13 = Set.of(1, 2, 3, 4, 5)
.stream()
.takeWhile(n -> n < 4)
.toList();
// 第一次运行结果是空列表... 第二次跑出来 [2, 3] ... 第三次跑出来 [1, 2, 3]
## 操作时的数据掉落
`takeWhile()`操作的对应操作是`dropWhile()`。当`takeWhile()`处理满足指定条件的元素时,`dropWhile()`会忽略元素直到条件不再被满足。从这个时候起,所有后续的元素都会被包含在结果中,不管它们是否满足条件。
默认流<T> dropWhile(谓词<? super T> predicate) {...}
理解它最好的方式是通过例子。
List<Integer> 示例列表 = Stream.of(1, 2, 3, 4, 5, 1)
.dropWhile(n -> n < 4)
.toList();
// 输出结果为:[4, 5, 1]

在这个例子中,`dropWhile()` 操作会删除所有满足小于4的条件的元素。一旦遇到不满足条件的第一个元素(即数字4),它就会停止删除元素。需要注意的是,即使在4之后还有满足条件的元素,但这些元素不会被删除,因为操作已经提前终止了。
如果谓词被第一个元素满足,那么就不会丢弃任何元素。
List<Integer> example15 = Stream.of(4, 2, 3, 4, 5, 1)
.dropWhile(n -> n < 4) // 从第一个不小于4的元素开始取值
.toList();
// 结果为:[4, 2, 3, 4, 5, 1]
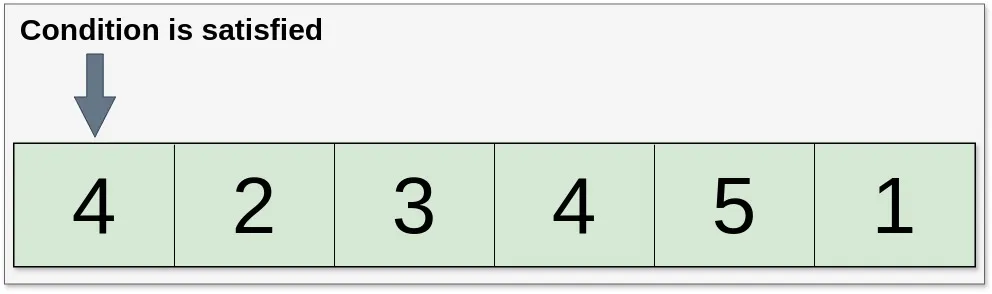
`dropWhile()` 方法是一个无状态操作,它根据谓词对元素位置进行评估,不保留元素之间的任何状态。重要的是要注意,如果流是无序状态,`dropWhile()` 方法的结果可能不确定。下面举个例子:
定义一个整数列表 example16 = 包含 1, 2, 3, 4, 5 的集合
.流()
.从第一个不满足条件的元素开始保留(n -> n < 4)
.转换为列表();
// [5, 4] -- 第一次执行
// [5, 4, 3, 2, 1] -- 第二次执行
// [4, 5] -- 第三次执行
在我的个人看法中,`takeWhile()` 和 `dropWhile()` 分别类似于带有条件的limit和skip操作。这种视角让我更容易理解它们的行为。
## 平行运行
Java中的并行流功能允许你利用多个CPU核心来并发处理数据,让你在处理大规模数据集时更快地完成操作。通过将流分成多个部分并同时处理,Java的并行流可以显著缩短处理数据所需的时间。
S parallel();
这种方法将顺序流转变为并行处理,
List<Integer> example17 = Set.of(1, 2, 3, 4, 5)
.stream()
.parallel()
.toList(); // 从一个整数集合中获取一个整数列表
在Java中,并行流是一种强大的工具,可以用来提升执行效率。然而,使用并行流时需要仔细权衡其对执行顺序的影响、副作用以及任务的特定性质等方面的影响。
## 顺序执行
一个并行方法的对应是顺序版本,即按照顺序执行的过程。
S 序列();
它只是将并行流转换成了顺序流。
List<Integer> example18 = Set.of(1, 2, 3, 4, 5)
.parallelStream()
.sequential()
.toList();
如果你想知道为什么这里没有讨论映射操作,那不是因为我忘记了——我会专门写一个关于映射操作的教程。敬请期待哦!
## 流管道中的操作流程
在使用Java流时,操作的顺序会显著影响性能。这里的几个关键考虑因素包括:
* 过滤操作 (`filter()`,`takeWhile()`,`dropWhile()` ) 应尽可能早地放在流管道中。提前过滤掉元素可以减少后续操作需要处理的元素数量,从而提高性能。
* 如果您知道只需要从流中获取特定数量的元素,那么尽早使用 `limit()` 可以减少后续操作的工作量,尤其是在大数据流或无限流中。
* 有序流中的操作,如 `sorted()`,`distinct()`,`skip()` 和 `limit()`,由于它们是有状态的,可能需要更多的计算,特别是在并行处理过程中。使用它们时应谨慎,并考虑维护状态的成本。
* 如果元素的顺序无关紧要,使用 `unordered()` 方法可以提高并行流的性能,允许更灵活地处理元素,从而实现更高效的并行执行效果。
你可以在这里找到完整的代码哦:
## [GitHub - polovyivan/java-streams-api-intermediate-operations在 GitHub 上为 polovyivan/java-streams-api-intermediate-operations 贡献。](https://github.com/polovyivan/java-streams-api-intermediate-operations?source=post_page-----a8fb7be4cac1--------------------------------)
## 最后
你不能认为自己是熟练的Java程序员而不掌握Streams。Stream API提供了一系列中间操作,可以简化甚至最复杂的任务。在这篇教程中,我详细介绍了这些主要操作。
感谢您的阅读!如果您喜欢这篇帖子,请点个赞并关注一下。如果您有任何问题或建议,欢迎随时留言或在我的LinkedIn页面上与我交流。[我的LinkedIn页面](https://www.linkedin.com/in/ivan-polovyi-5a4082178/)



