

在GTC24展示厅展出的NVL-72水冷机架的原型——图片由Adrian摄
从GTC的公告之后,我就一直在尝试写这篇博客文章,原本打算把它发布到The New Stack作为一篇文章,但我总是在一些我不明白的地方卡住,所以我打算原封不动地发布在Medium上,如果有任何反馈指出我的错误或遗漏的地方,我就可以很容易地进行更新。
大多数出版物只是报道了关于基准改进的声明,但如果你仔细思考一下,从一个简单的技术变化的角度来看,这些数字是说不通的。这些基准在《NVIDIA Blackwell 架构技术简报》和 GTC 主题演讲的一些截图中有记录,我将拆解这些内容,并尝试从“基准营销”的角度来看解释真正发生了什么。简而言之:这些基准比较了相隔两代技术发展的大规模配置,部分不明显的加速来自于向内存中心架构的转变,从我个人的角度来看,节能效果不错,但没有声称的那么显著。
在这次比较中相关的有三代GPU。Hopper H100 在2022年发布,是目前主流使用的型号,因此被用作基准进行比较。Grace Hopper GH200 在2023年发布,在GTC期间只有少量可用,这次基准比较中没有引用它。Grace Blackwell GB200 是新发布的型号,与H100进行比较,预计要到2025年才会大规模上市。首先需要了解的是,这次基准测试跳过了一代产品,比较的是大约两年时间跨度内的产品。他们本可以选择将GB200与GH200进行比较,但那样数据就不会那么令人印象深刻了,而且用户对GH200还不太熟悉,所以这样的做法是合理的。
不同世代之间的架构差异在于,HGX H100 是一个配置有八块 H100 GPU 和两块 Intel CPU 的风冷机架服务器。NVIDIA 品牌的这一版本被称为 DGX H100,其他供应商将 HGX H100 系统整合到他们自己的产品中。DGX 和 HGX 的性能应该是相同的,但基准测试指的是更通用的 HGX。它的高度为14英寸,占据8个机架单元的空间,这意味着在一个标准机架里最多可以放置四台这样的设备。NVIDIA 的基准文档中将每台 HGX H100 设备称为“机架”,这给人一种错觉,仿佛每台设备占用的空间更多。
GH200 搭载了 ARM 架构的 Grace CPU 和经过略微升级的 H200 GPU,虽然其计算能力与 H200 相同,但内存更多且更快。各种基准测试表明,根据工作负载的内存密集程度,每 GPU 的性能提升了 1.4 到 1.8 倍的提升。最多可以利用共享内存架构连接 256 个 GH200 模块,而不是通过 Infiniband 连接。在对比八台网络连接的 8xH100+2xCPU 与共享内存的 64xGH200 集群配置中,由于共享内存较低的开销和更高的速度,以及 64 个 Grace CPU 相比 16 个 Intel CPU 的更大容量,共享内存集群有一些速度提升。
下面是Blackwell的规格如下,该表显示的是单个水冷GB200模块的性能,该模块包含两个GPU,这使得情况有些混乱。区分是GB200模块、单个GPU还是风冷的B100/B200非常重要。GB200模块由一个Grace CPU和两个Blackwell GPU组成,而不是GH200中的一个Hopper GPU,这意味着在每个模块的基础上性能有2倍的提升。Blackwell GPU由两个与H200相似的芯片组成,H200是在H100基础上做出的一小步改进。
仅从硅来看,我们估计单个Blackwell GPU的性能约为单个H200的两倍,略高于单个H100的两倍。
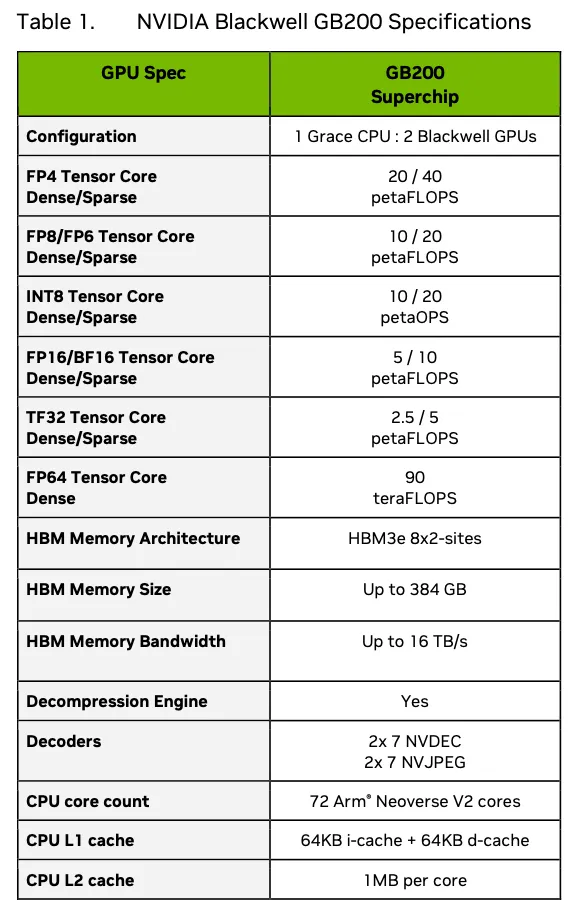
HGX H100 8-GPU 系统是对比的基础款,其性能指标如 数据表 所示。
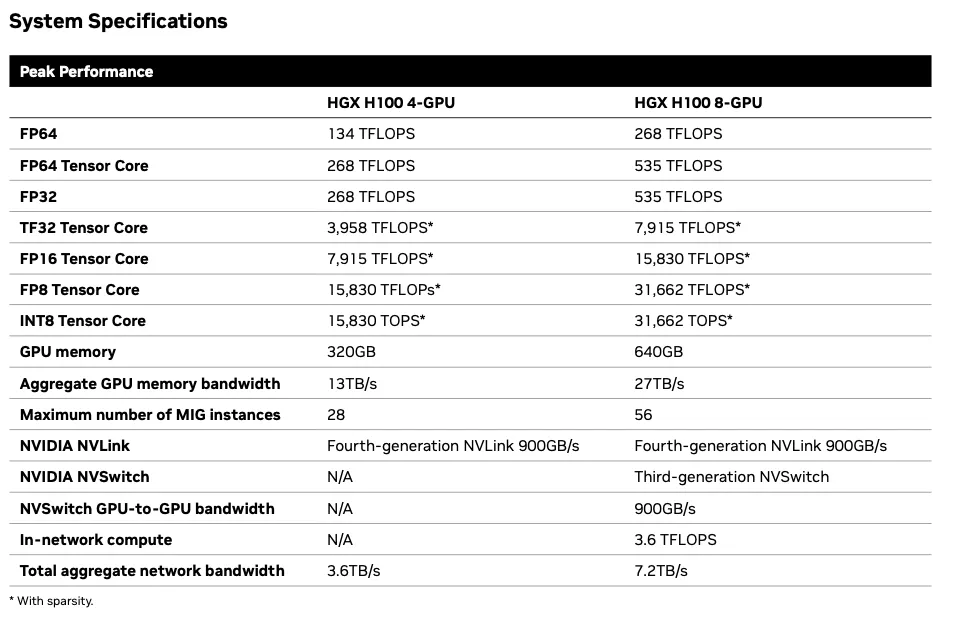
在每GPU FP8稀疏基础上,H100的性能为32/8 = 4拍法拉。Blackwell的性能为20/2 = 10拍法拉,因此计算速度提升为2.5倍速,如预期。H100的内存带宽为27/8 = 3.375TB/s,而Blackwell的内存带宽为16/2 = 8TB/s,因此内存速度提升为2.37倍。这几乎完全符合从H100到H200的工艺和规模改进中所期望的结果,将相当于两个H200芯片的小芯片封装到一个Blackwell中。额外的内存带宽是为了支持增加的计算性能而需要的。
第一个基准性能指标声明为训练性能达到H100的4倍,而非我们预期的2.5倍。该配置详情请见下图。
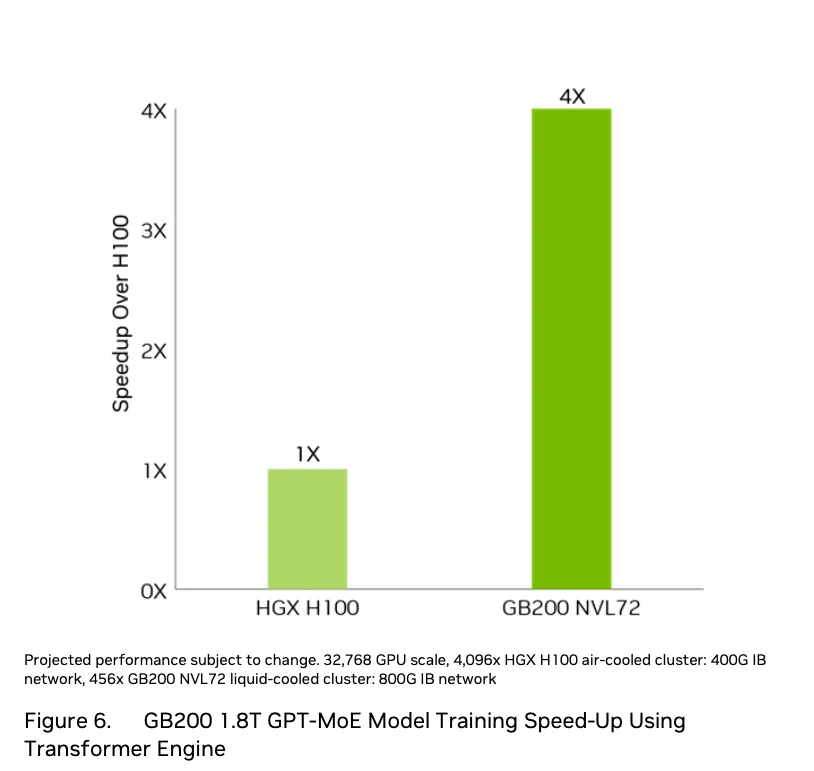
这个基准是为OpenAI或Meta训练其最大模型时所使用的配置类型而设计的。它由32768个H100 GPU组成,配置为4096个HGX H100机器的网络(通常每机柜配置四个,因此是1024个风冷机柜),与456个NVL72水冷机柜中的32832个Blackwell GPU相对比。我们预计加速比为2.5倍,因此互连部分必须额外提供1.6倍的加速。H100的互连是NVlink,这些GPU的8个之间相干共享内存带宽为900GB/s,然后通过400Gbit/s的Infiniband连接4096个节点(实际带宽因8位数据在10位编码传输中的开销和协议开销而小于40GB/s)。NVL72的72个GPU通过NVlink以1800GB/s的速度互连,然后通过800Gbit/s的Infiniband连接456个节点(实际带宽因8位数据在10位编码传输中的开销和协议开销而小于80GB/s)。NVL72上通过NVlink进行GPU到GPU数据传输的概率是H100的九倍,传输速率则是H100的两倍。这是额外1.6倍加速的一个合理解释。无论使用何种精度,这个结论仍然适用,因为Blackwell在FP8、FP16等精度下比H100快2.5倍。
训练提速4倍的说法在大规模配置下似乎可信。然而,对于1到8个GPU的小规模配置而言,训练提速则更接近2.5倍。
该配置是NVL-36,它占据了照片中机架的一半空间,包含9块主板上的18个GB200模块,以及若干未指定数量的NVLink内存切换卡。
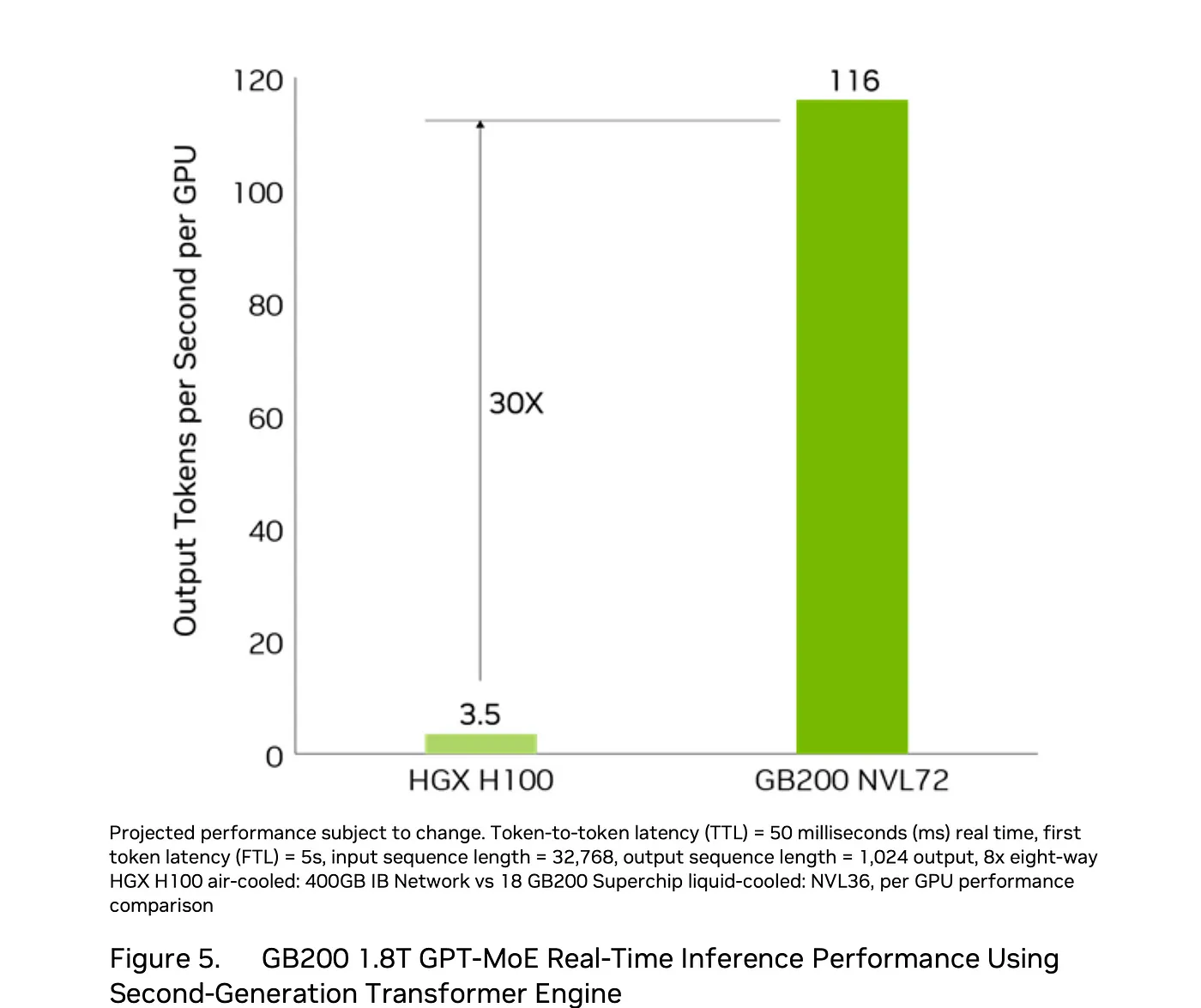
性能基准测试结果取自Blackwell架构设计技术简报文档
在第14页底部的技术简报文档里还有一个脚注。
“Token到Token延迟(TTL)= 50毫秒实时,首个Token延迟(FTL)= 5秒,输入序列长度为32,768,输出序列长度为1,028。64个H100 GPU风冷与18个GB200超级芯片液冷NVL36的性能对比。每GPU性能对比。总拥有成本(TCO),能耗节省:100个机架八路HGX H100风冷与一个机架GB200 NVL72液冷的能耗节省,两者性能等效。”
在Blackwell中,推理时有一个新的FP4格式,其浮点运算能力是H100 FP8的两倍,因此我们预计GB200每GPU的性能指标将比H100高五倍,这是基于每GPU的原始计算能力差异(H100每GPU为4 PFLOPS FP8,而Blackwell每GPU为20 PFLOPS FP4),然而性能宣称达到了30倍,能效宣称达到了25倍。最大的疑问是:他们如何得出这些更高的比较数字?性能和能效分别缺少了6倍和5倍的倍数需要解释。
基准测试是在一个1.8万亿参数的GPT-MoE-1.8T模型上完成的,虽然不清楚该模型是如何调整以使用FP8在H100上运行以及使用FP4在GB200上运行的。需要至少1.8T字节的内存来存储FP8格式的模型权重,还需要900G字节的内存来存储FP4格式的模型权重。NVL-36系统配备了超过6TB的高带宽GPU内存,而八台采用H100的系统总共大约有5TB的GPU内存。推理配置通常首先根据存储模型所需的内存大小来确定,然后复制这些配置来满足所需的服务容量。
有两个差异提升了结果。第一个效果是FP4模型的权重是4位而不是8位,因此大小缩减了一半,这意味着它们的加载速度更快一倍,对于相同数量的模型参数来说,缓存命中率也更好。另一个效果是H100集群由八个通过Infiniband相连的系统组成,而GB200集群则是一个单一的共享内存系统。
我们之前注意到,当内存带宽和容量增加时,单个 H100 和 H200 GPU(它们的原始计算能力相同)之间的速度提高了1.4到1.8倍。
下面的图表来自GTC主题演讲中,似乎就是30倍提速说法的来源。
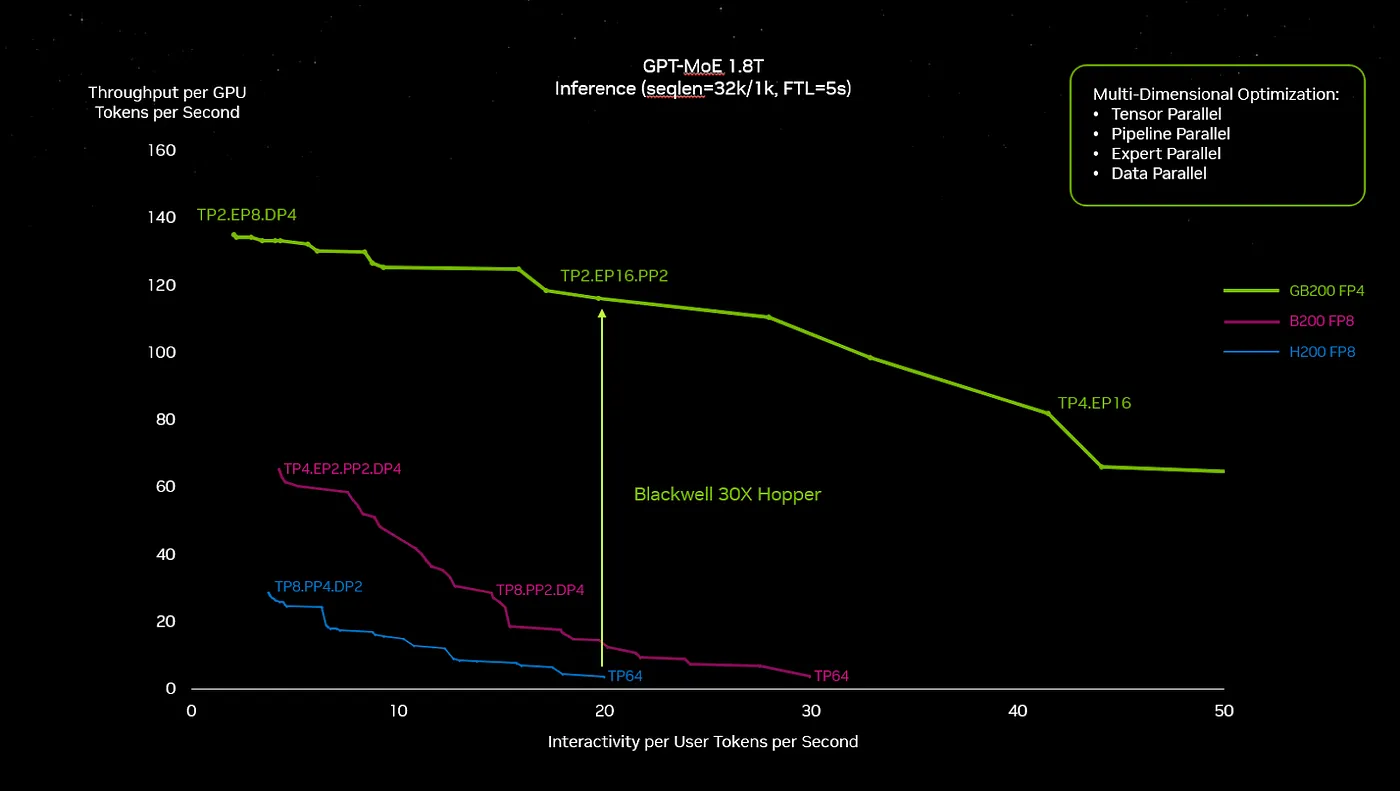
然而,选择两条曲线之间差异的点位对我来说感觉很随意,特别是在H100系统性能明显下滑的那个点。我在图上加了一些辅助线来更方便地估算数值,从而得到了新的差异。
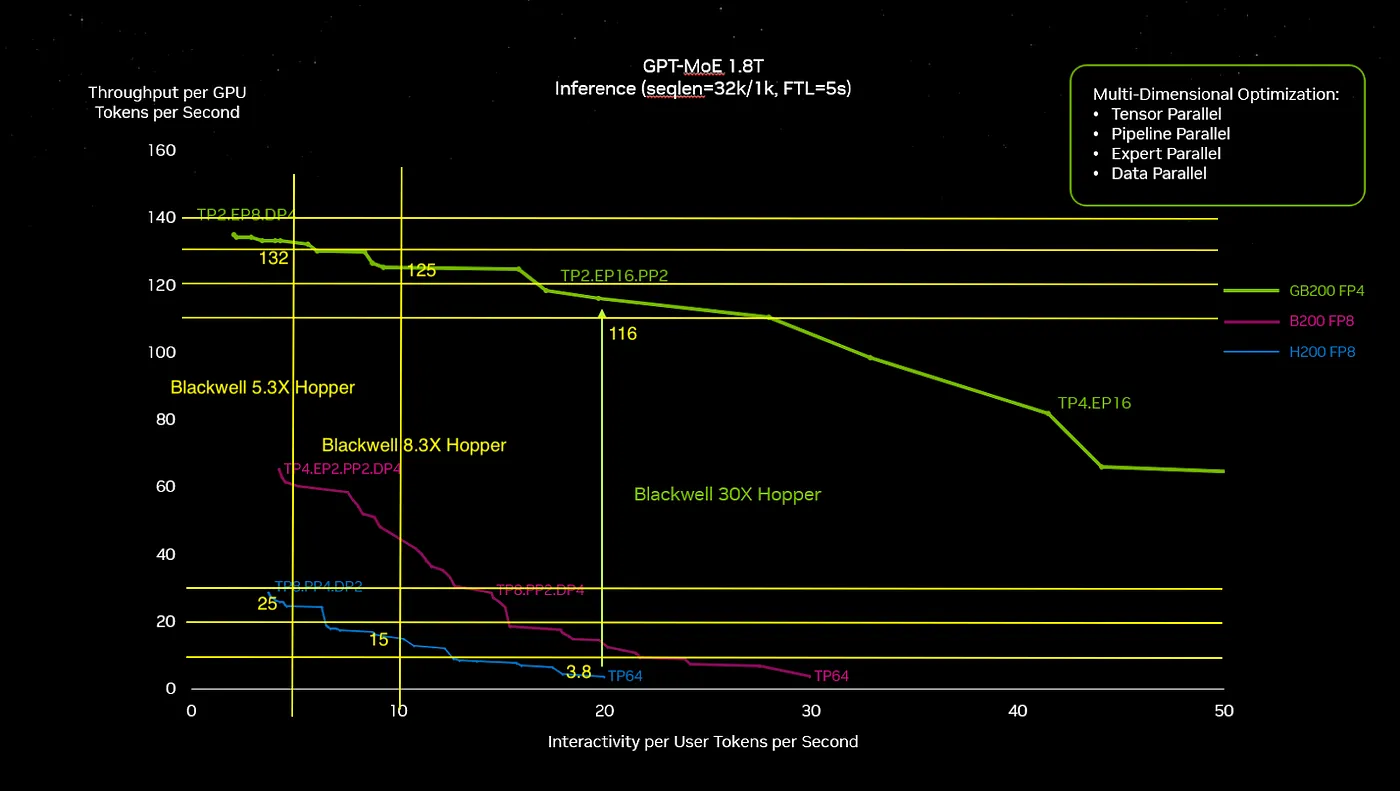
我标注的对比是H100到B200的速度提升,分别是5.3倍和8.3倍。这些数据更符合我对硬件性能的预期。而30倍的数值似乎是在对比运行效率低下的H100。
关于这种模型推理能力提升30倍的宣称是针对OpenAI用于运行ChatGPT的那种推理模型而言的。但我认为,对于这类大型系统,人们应该期望推理能力提升大约8到10倍。
对于目前适合放入单个8-GPU HGX100且能使用FP4的小型推理模型,基于GB200水冷系统的NVL-72封装的加速器预计可以提高大约5倍的速度。然而,也有一种更相似的空冷降频版Blackwell GPU,分为两个8版本,分别称为HGX B100,设计为与HGX H100保持相同的功耗范围,以及功耗更大且GPU速度为原速度90%的HGX B200。
采用空气冷却的8-GPU配置相比旧系统,HGX B100的推理速度加快预计可达4倍,而HGX B200提升可达4.5倍,这主要是因为硅面积翻倍以及从FP8转向FP4。
可持续性的说法是总运营成本(TCO)和能源使用相比提高了25倍。但从这里开始,比较就不再有意义了,。首先,为什么TCO和能源使用之间的关系是相同的?如果能源成本在TCO中占主导地位,那么重复报告同一数值就没有意义了,但似乎不太可能空气冷却系统的TCO与水冷系统的TCO差异只是简单地反映能源使用的差异。
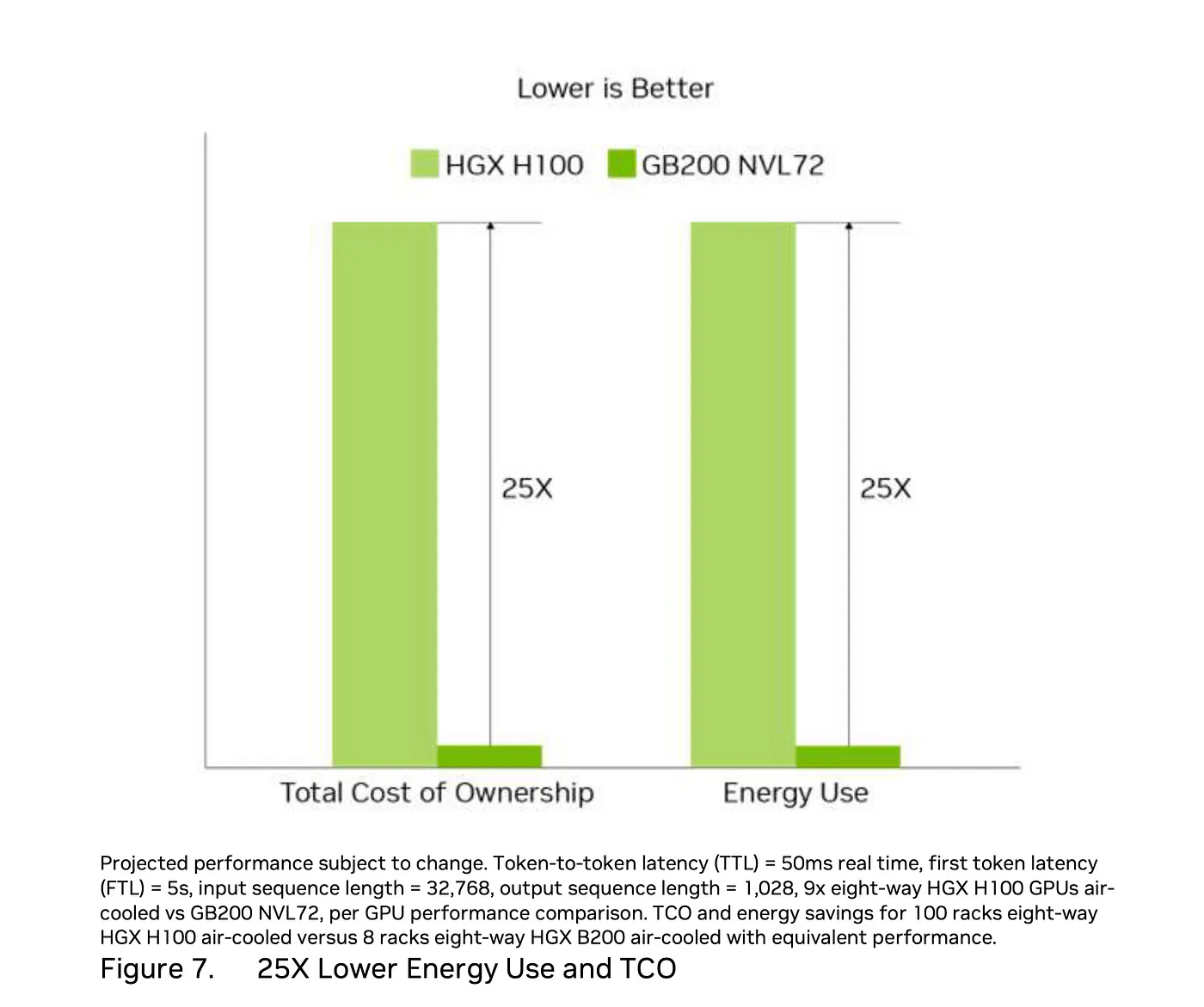
《Blackwell Architecture Technical Brief》中的TCO和能源使用基准数据
该对比是 9x 八路系统 = 72 个 H100 GPU,而 NVL72 则配备了 72 个基于 GB200 的 GPU,NVIDIA 称此配置可带来 30 倍的速度提升,同时总能耗提高了 1.2 倍。NVL72 的功耗为 120 千瓦,这意味着九个 HGX H100 的总功耗为 100 千瓦,每个约为 11 千瓦。而根据他们的规格,每个系统的功耗为 10.2 千瓦,因此这部分对比是合理的。
下面的细节完全讲不通。100 个 HGX H100 相当于 800 个 GPU 和 1100 kW 对比 8 个 HGX B200 相当于 64 个 GPU,性能相同。
我联系了NVIDIA,他们告诉我这是一个打字错误,并给了我更新的对比图表。
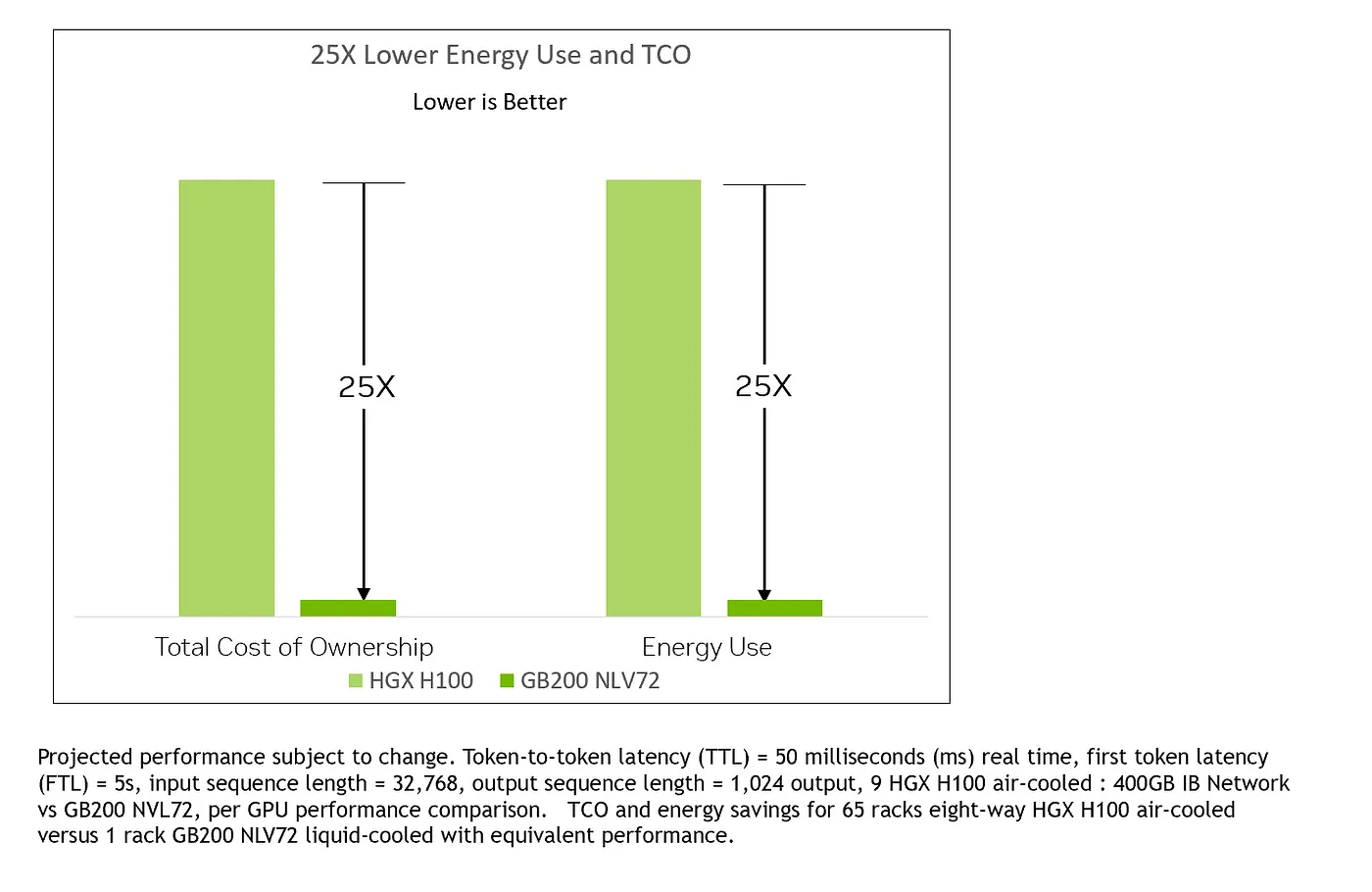
更新的笔记中所做的比较是,65 个 HGX H100 等同于 520 个 GPU 和 700 千瓦,相当于一个 NVL72,后者拥有 72 个 GPU 和 120 千瓦,这样的比较也不符合逻辑。这样的 TCO 计算对我来说也没有任何意义。
总而言之,这种能源比较基准值只有在假设每种类型的72个GPU进行基本比较,并忽略额外的注解的情况下才有意义。然而,如果我们采用更可能的约10倍的加速而不是30倍加速,那么能源效率的比较结果将大约为8倍。这仍然是推理效率的一个很大的改进。
在The Next Platform上对NVIDIA路线图的最新更新总结得很好,其中提到的能源效率提高了25倍的说法仍然存在,即从10焦耳/推断减少到0.4焦耳/推断。他们如何测量这一点尚不清楚,也不清楚他们是否只是根据之前的25倍提升提出了一个新的标准。详情请参阅:https://www.nextplatform.com/2024/06/02/nvidia-unfolds-gpu-interconnect-roadmaps-out-to-2027/
我已经花了很多时间看规格,试图搞清楚这些,但感觉还是有点乱。我怀疑对于单 GPU B200 模块和双 GPU GB200 模块之间可能还有点混淆,因为我看到 NVIDIA 曾说 B200 GPU 的性能是 H100 的 15 倍,这听起来更靠谱,但又跟 GB200 的每 GPU 性能说法对不上。如果你有啥好建议,也可以告诉我哦!
[更新 2024/9/28] David Kanter 指出了一些 MLPerf 推理结果。H200 的性能大约是 H100 的 1.4 倍,这符合预期,但单个 Blackwell GPU 的性能仅为 H100 的 4 倍,而不是之前预测的 30 倍,也不是宣传中的 30 倍加速。https://developer.nvidia.com/blog/nvidia-blackwell-platform-sets-new-llm-inference-records-in-mlperf-inference-v4-1/





